
Few-Shot Prompting, Learning und Fine-Tuning für LLMs - AI&YOU #67 Few-Shot Prompting, Learning und Fine-Tuning für LLMs - AI&YOU #67



Few-Shot Prompting, Learning, and Fine-Tuning for LLMs – AI&YOU #67 Few-Shot Prompting, Learning, and Fine-Tuning for LLMs – AI&YOU #67
Statistik der Woche: Research by MobiDev on few-shot learning for coin image classification found that using just 4 image examples per coin denomination, they could achieve ~70% accuracy.
In AI, the ability to learn efficiently from limited data has become crucial. That’s why it’s important for enterprises to understand few-shot learning, few-shot prompting, and fine-tuning LLMs.
In dieser Ausgabe von AI&YOU befassen wir uns mit den Erkenntnissen aus drei Blogs, die wir zu diesen Themen veröffentlicht haben:
Few-Shot Prompting, Learning, and Fine-Tuning for LLMs – AI&YOU #67
Few Shot Learning is an innovative machine learning paradigm that enables AI models to learn new concepts or tasks from only a few examples. Unlike traditional supervised learning methods that require vast amounts of labeled training data, Few Shot Learning techniques allow models to generalize effectively using just a small number of samples. This approach mimics the human ability to quickly grasp new ideas without the need for extensive repetition.
Das Wesen des Few Shot Learning liegt in seiner Fähigkeit, Vorwissen zu nutzen und sich schnell an neue Szenarien anzupassen. Durch den Einsatz von Techniken wie dem Meta-Lernen, bei dem das Modell "lernt, wie man lernt", können Few Shot Learning-Algorithmen eine breite Palette von Aufgaben mit minimalem zusätzlichem Training bewältigen. Diese Flexibilität macht sie zu einem unschätzbaren Werkzeug in Szenarien, in denen Daten knapp, teuer zu beschaffen sind oder sich ständig weiterentwickeln.

Die Herausforderung der Datenknappheit in der KI
Nicht alle Daten sind gleich, und qualitativ hochwertige, markierte Daten können ein seltenes und kostbares Gut sein. Diese Knappheit stellt eine große Herausforderung für herkömmliche überwachte Lernansätze dar, die in der Regel Tausende oder sogar Millionen von markierten Beispielen benötigen, um eine zufriedenstellende Leistung zu erzielen.
Das Problem der Datenknappheit ist besonders akut in spezialisierten Bereichen wie dem Gesundheitswesen, wo es für seltene Krankheiten nur wenige dokumentierte Fälle gibt, oder in sich schnell verändernden Umgebungen, in denen häufig neue Datenkategorien auftauchen. In diesen Szenarien können die Zeit und die Ressourcen, die für die Sammlung und Kennzeichnung großer Datensätze erforderlich sind, unerschwinglich sein, was zu einem Engpass bei der Entwicklung und dem Einsatz von KI führt.
Few Shot Learning vs. traditionelles überwachtes Lernen
Understanding the distinction between Few Shot Learning and traditional supervised learning is crucial to grasp its real-world impact.
Traditionell überwachtes Lernen, while powerful, has drawbacks:
Daten-Abhängigkeit: Struggles with limited training data.
Unflexibilität: Performs well only on specific trained tasks.
Intensität der Ressourcen: Requires large, expensive datasets.
Kontinuierliche Aktualisierung: Needs frequent retraining in dynamic environments.
Few Shot Learning offers a paradigm shift:
Beispielhafte Effizienz: Generalizes from few examples using meta-learning.
Schnelle Anpassung: Quickly adapts to new tasks with minimal examples.
Optimierung der Ressourcen: Reduces data collection and labeling needs.
Kontinuierliches Lernen: Suitable for incorporating new knowledge without forgetting.
Vielseitigkeit: Applicable across various domains, from computer vision to NLP.
By tackling these challenges, Few Shot Learning enables more adaptable and efficient AI models, opening new possibilities in AI development.
Das Spektrum des probeneffizienten Lernens
A fascinating spectrum of approaches aims to minimize required training data, including Zero Shot, One Shot, and Few Shot Learning.
Zero Shot Learning: Lernen ohne Beispiele
Recognizes unseen classes using auxiliary information like textual descriptions
Valuable when labeled examples for all classes are impractical or impossible
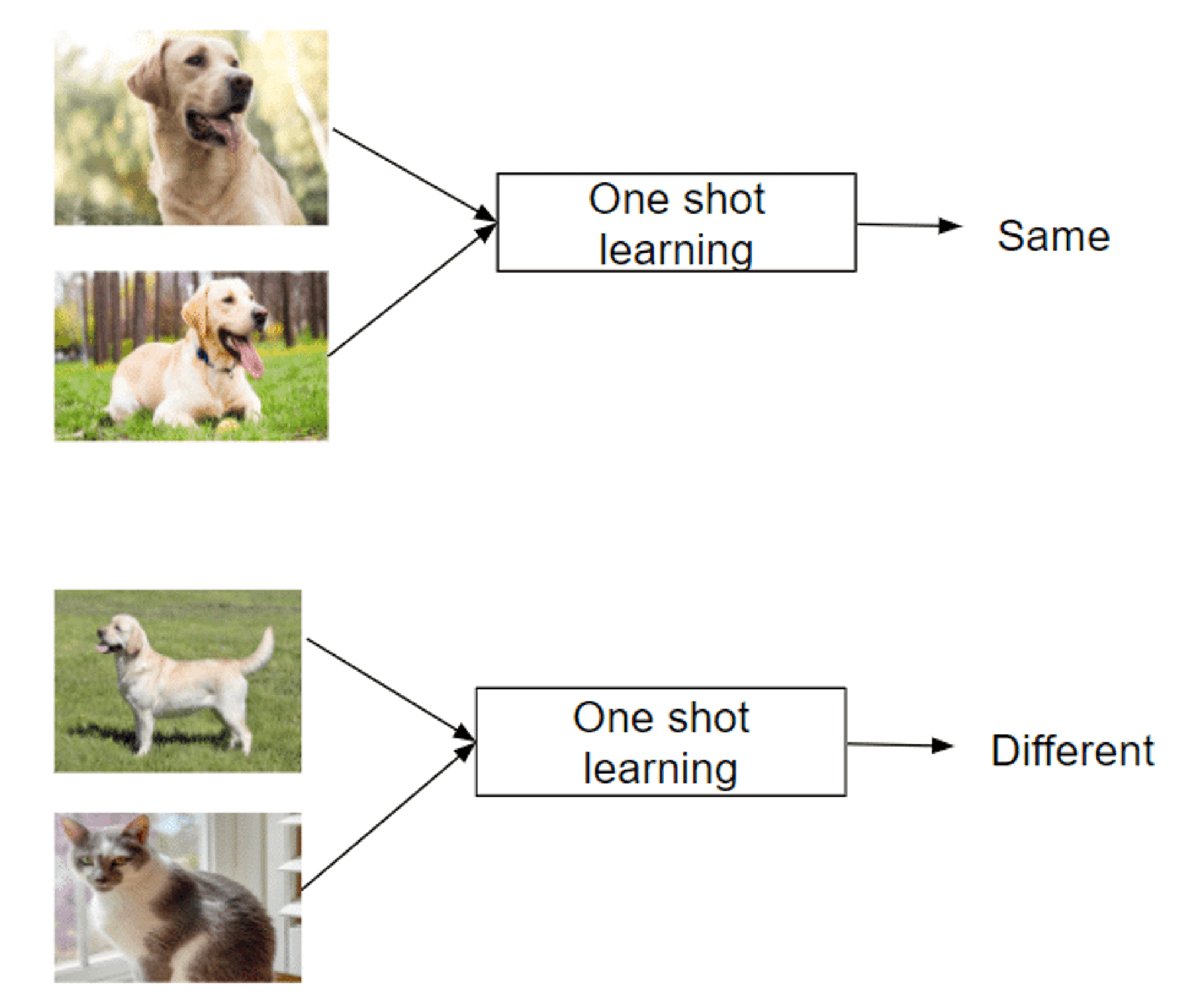
One Shot Learning: Lernen von einer einzigen Instanz
Recognizes new classes from just one example
Mimics human ability to grasp concepts quickly
Successful in areas like facial recognition
Few Shot Learning: Aufgaben mit minimalen Daten bewältigen
Uses 2-5 labeled examples per new class
Balances extreme data efficiency and traditional methods
Enables rapid adaptation to new tasks or classes
Leverages meta-learning strategies to learn how to learn
This spectrum of approaches offers unique capabilities in tackling the challenge of learning from limited examples, making them invaluable in data-scarce domains.
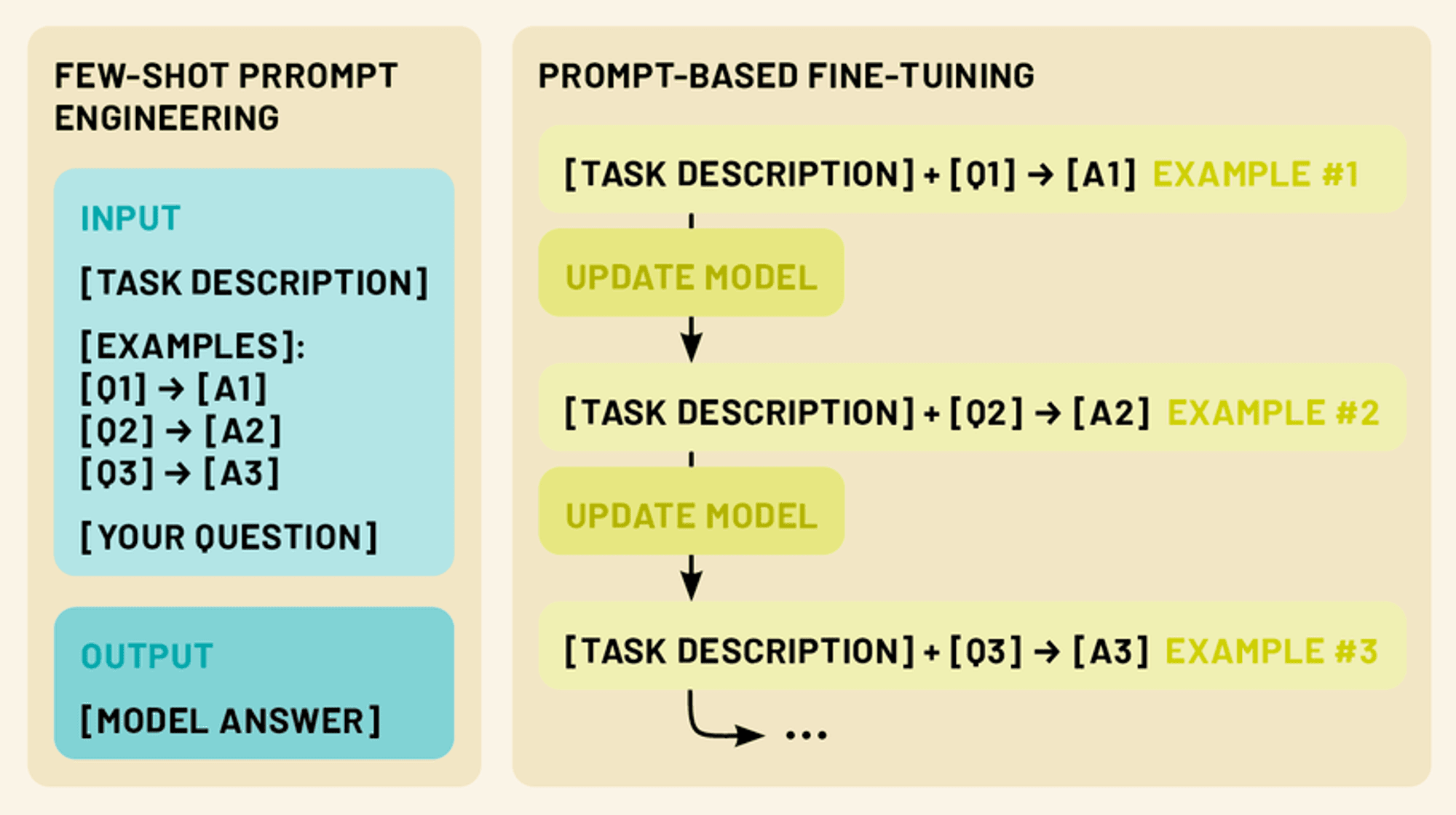
Few Shot Prompting vs Fine Tuning LLM
Two more powerful techniques exist in this realm: few-shot prompting and fine-tuning. Few-shot prompting involves crafting clever input prompts that include a small number of examples, guiding the model to perform a specific task without any additional training. Fine-tuning, on the other hand, involves updating the model’s parameters using a limited amount of task-specific data, allowing it to adapt its vast knowledge to a particular domain or application.
Both approaches fall under the umbrella of few-shot learning. By leveraging these techniques, we can dramatically enhance the performance and versatility of LLMs, making them more practical and effective tools for a wide range of applications in natural language processing and beyond.
Few-Shot Prompting: Das LLM-Potenzial freisetzen
Few-shot prompting capitalizes on the model’s ability to understand instructions, effectively “programming” the LLM through crafted prompts.
Few-shot prompting provides 1-5 examples demonstrating the desired task, leveraging the model’s pattern recognition and adaptability. This enables performance of tasks not explicitly trained for, tapping into the LLM’s capacity for in-context learning.
By presenting clear input-output patterns, few-shot prompting guides the LLM to apply similar reasoning to new inputs, allowing quick adaptation to new tasks without parameter updates.
Arten von "few-shot"-Aufforderungen (zero-shot, one-shot, few-shot)
Few-shot prompting encompasses a spectrum of approaches, each defined by the number of examples provided. (Just like few-shot learning):
Null-Schuss-Eingabeaufforderung: In diesem Szenario werden keine Beispiele gegeben. Stattdessen wird dem Modell eine klare Anweisung oder Beschreibung der Aufgabe gegeben. Zum Beispiel: "Übersetzen Sie den folgenden englischen Text ins Französische: [Eingabetext]".
Einmalige Eingabeaufforderung: Hier wird der eigentlichen Eingabe ein einziges Beispiel vorangestellt. Dadurch erhält das Modell ein konkretes Beispiel für die erwartete Input-Output-Beziehung. Ein Beispiel: "Klassifizieren Sie die Stimmung der folgenden Rezension als positiv oder negativ. Beispiel: 'Dieser Film war fantastisch!' - Positive Eingabe: 'Ich konnte die Handlung nicht ertragen.' - [Modell generiert Antwort]"
Wenige Schüsse Souffleuse: Bei diesem Ansatz werden mehrere Beispiele (in der Regel 2-5) vor der eigentlichen Eingabe gegeben. Dies ermöglicht es dem Modell, komplexere Muster und Nuancen in der Aufgabe zu erkennen. Zum Beispiel: "Klassifizieren Sie die folgenden Sätze als Fragen oder Aussagen: 'Der Himmel ist blau.' - Aussage: 'Wie spät ist es?' - Frage: 'Ich liebe Eiscreme.' - Aussage Eingabe: 'Wo finde ich das nächste Restaurant?' - [Modell erzeugt Antwort]"
Gestaltung von effektiven Aufforderungen in wenigen Augenblicken
Das Verfassen von effektiven "few-shot prompts" ist sowohl eine Kunst als auch eine Wissenschaft. Hier sind einige wichtige Grundsätze zu beachten:
Klarheit und Kohärenz: Achten Sie darauf, dass Ihre Beispiele und Anweisungen klar sind und einem einheitlichen Format folgen. Dadurch kann das Modell das Muster leichter erkennen.
Vielfältigkeit: Wenn Sie mehrere Beispiele verwenden, versuchen Sie, eine Reihe möglicher Eingaben und Ausgaben abzudecken, um dem Modell ein breiteres Verständnis der Aufgabe zu vermitteln.
Relevanz: Wählen Sie Beispiele, die in engem Zusammenhang mit der spezifischen Aufgabe oder dem Bereich stehen, auf den Sie abzielen. So kann sich das Modell auf die wichtigsten Aspekte seines Wissens konzentrieren.
Prägnanz: Es ist zwar wichtig, genügend Kontext zu liefern, aber vermeiden Sie übermäßig lange oder komplexe Aufforderungen, die das Modell verwirren oder die Schlüsselinformationen verwässern könnten.
Experimentieren: Don’t be afraid to iterate and experiment with different prompt structures and examples to find what works best for your specific use case.
Durch die Beherrschung der Kunst des "few-shot prompting" können wir das volle Potenzial von LLMs freisetzen und sie in die Lage versetzen, ein breites Spektrum von Aufgaben mit minimalem zusätzlichem Input oder Training zu bewältigen.
Feinabstimmung von LLMs: Anpassung von Modellen mit begrenzten Daten
Während das "few-shot prompting" eine leistungsstarke Technik ist, um LLMs an neue Aufgaben anzupassen, ohne das Modell selbst zu verändern, bietet das "fine-tuning" eine Möglichkeit, die Parameter des Modells zu aktualisieren, um eine noch bessere Leistung bei spezifischen Aufgaben oder Domänen zu erzielen. Die Feinabstimmung ermöglicht es uns, das umfangreiche Wissen, das in vortrainierten LLMs kodiert ist, zu nutzen und sie gleichzeitig auf unsere spezifischen Bedürfnisse zuzuschneiden, indem wir nur eine kleine Menge aufgabenspezifischer Daten verwenden.
Verständnis der Feinabstimmung im Kontext der LLMs
Fine-tuning an LLM involves further training a pre-trained model on a smaller, task-specific dataset. This process adapts the model to the target task while building upon existing knowledge, requiring less data and resources than training from scratch.
In LLMs, fine-tuning typically adjusts weights in upper layers for task-specific features, while lower layers remain largely unchanged. This “transfer learning” approach retains broad language understanding while developing specialized capabilities.
Feintuning-Techniken mit wenigen Aufnahmen
Few-shot fine-tuning adapts the model using only 10 to 100 samples per class or task, valuable when labeled data is scarce. Key techniques include:
Prompt-basierte Feinabstimmung: Combines few-shot prompting with parameter updates.
Ansätze des Meta-Lernens: Methods like MAML aim to find good initialization points for quick adaptation.
Adapter-based fine-tuning: Introduces small “adapter” modules between pre-trained model layers, reducing trainable parameters.
Kontextbezogenes Lernen: Fine-tunes LLMs to better perform adaptation through prompts alone.
These techniques enable LLMs to adapt to new tasks with minimal data, enhancing their versatility and efficiency.
Few-Shot Prompting vs. Fine-Tuning: Die Wahl des richtigen Ansatzes
Bei der Anpassung von LLMs an spezifische Aufgaben bieten sowohl das "few-shot prompting" als auch das "fine-tuning" leistungsfähige Lösungen. Jede Methode hat jedoch ihre eigenen Stärken und Grenzen, und die Wahl des richtigen Ansatzes hängt von verschiedenen Faktoren ab.
Few-Shot Prompting Strengths:
Erfordert keine Aktualisierung der Modellparameter, so dass das ursprüngliche Modell erhalten bleibt
Hochflexibel und fliegend anpassbar
Keine zusätzliche Schulungszeit oder Rechenressourcen erforderlich
Nützlich für schnelles Prototyping und Experimentieren
Beschränkungen:
Die Leistung kann weniger konsistent sein, insbesondere bei komplexen Aufgaben.
Begrenzt durch die ursprünglichen Fähigkeiten und Kenntnisse des Modells
Kann sich mit hochspezialisierten Bereichen oder Aufgaben schwer tun
Fine-Tuning Strengths:
Erzielt oft eine bessere Leistung bei bestimmten Aufgaben
Kann das Modell an neue Bereiche und Fachvokabular anpassen
Einheitlichere Ergebnisse bei ähnlichen Eingaben
Potenzial für kontinuierliches Lernen und Verbesserung
Beschränkungen:
Erfordert zusätzliche Ausbildungszeit und Rechenressourcen
Gefahr des katastrophalen Vergessens, wenn nicht sorgfältig gehandelt wird
Kann bei kleinen Datensätzen zu stark angepasst werden
Weniger flexibel; erfordert Umschulung bei wesentlichen Aufgabenänderungen
Top 5 Research Papers for Few-Shot Learning
This week, we also explore the following five papers that have significantly advanced this field, introducing innovative approaches that are reshaping AI capabilities.

1️⃣ Matching Networks for One Shot Learning” (Vinyals et al., 2016)
Introduced a groundbreaking approach using memory and attention mechanisms. The matching function compares query examples to labeled support examples, setting a new standard for few-shot learning methods.
2️⃣ Prototypical Networks for Few-shot Learning” (Snell et al., 2017)
Presented a simpler yet effective approach, learning a metric space where classes are represented by a single prototype. Its simplicity and effectiveness made it a popular baseline for subsequent research.
3️⃣ Learning to Compare: Relation Network for Few-Shot Learning” (Sung et al., 2018)
Introduced a learnable relation module, allowing the model to learn a comparison metric tailored to specific tasks and data distributions. Demonstrated strong performance across various benchmarks.
4️⃣ A Closer Look at Few-shot Classification” (Chen et al., 2019)
Provided a comprehensive analysis of existing methods, challenging common assumptions. Proposed simple baseline models that matched or exceeded more complex approaches, emphasizing the importance of feature backbones and training strategies.
5️⃣ Meta-Baseline: Exploring Simple Meta-Learning for Few-Shot Learning” (Chen et al., 2021)
Combined standard pre-training with a meta-learning stage, achieving state-of-the-art performance. Highlighted the trade-offs between standard training and meta-learning objectives.
These papers have not only advanced academic research but also paved the way for practical applications in enterprise AI. They represent a progression towards more efficient, adaptable AI systems capable of learning from limited data – a crucial capability in many business contexts.
Die Quintessenz
Few-shot learning, prompting, and fine-tuning represent groundbreaking approaches, enabling LLMs to adapt swiftly to specialized tasks with minimal data. As we’ve explored, these techniques offer unprecedented flexibility and efficiency in tailoring LLMs to diverse applications across industries, from enhancing natural language processing tasks to enabling domain-specific adaptations in fields like healthcare, law, and technology.
Danke, dass Sie sich die Zeit genommen haben, AI & YOU zu lesen!
Für noch mehr Inhalte zum Thema KI für Unternehmen, einschließlich Infografiken, Statistiken, Anleitungen, Artikeln und Videos, folgen Sie Skim AI auf LinkedIn
Sie sind Gründer, CEO, Risikokapitalgeber oder Investor und suchen KI-Beratung, fraktionierte KI-Entwicklung oder Due-Diligence-Dienstleistungen? Holen Sie sich die Beratung, die Sie brauchen, um fundierte Entscheidungen über die KI-Produktstrategie Ihres Unternehmens und Investitionsmöglichkeiten zu treffen.
Wir entwickeln maßgeschneiderte KI-Lösungen für von Venture Capital und Private Equity unterstützte Unternehmen in den folgenden Branchen: Medizintechnik, Nachrichten/Content-Aggregation, Film- und Fotoproduktion, Bildungstechnologie, Rechtstechnologie, Fintech und Kryptowährungen.


