
Die 5 wichtigsten multimodalen KI-Tools und -Plattformen



Die Landschaft der künstlichen Intelligenz entwickelt sich ständig weiter, mit multimodale KI Tools und Plattformen, die zu wichtigen Akteuren werden. Diese innovativen Lösungen gehen über die herkömmliche Single-Mode-KI hinaus, indem sie verschiedene Arten von Daten - wie Text, Bilder, Sprache und Video - integrieren, um intelligentere, effizientere und intuitivere Systeme zu schaffen. Diese Integration ermöglicht ein umfassenderes Verständnis und eine umfassendere Interaktion mit Daten und spiegelt die vielschichtige Art und Weise wider, wie Menschen Informationen wahrnehmen und verarbeiten.
In diesem Blog werden wir einige der wichtigsten multimodalen KI-Tools und -Plattformen vorstellen, die in der Tech-Welt für Furore sorgen. Diese Plattformen revolutionieren nicht nur die Art und Weise, wie Maschinen lernen und mit Daten interagieren, sondern auch, wie Unternehmen und Privatpersonen KI für komplexere und genauere Anwendungen nutzen.
1. Startbahn Gen-2
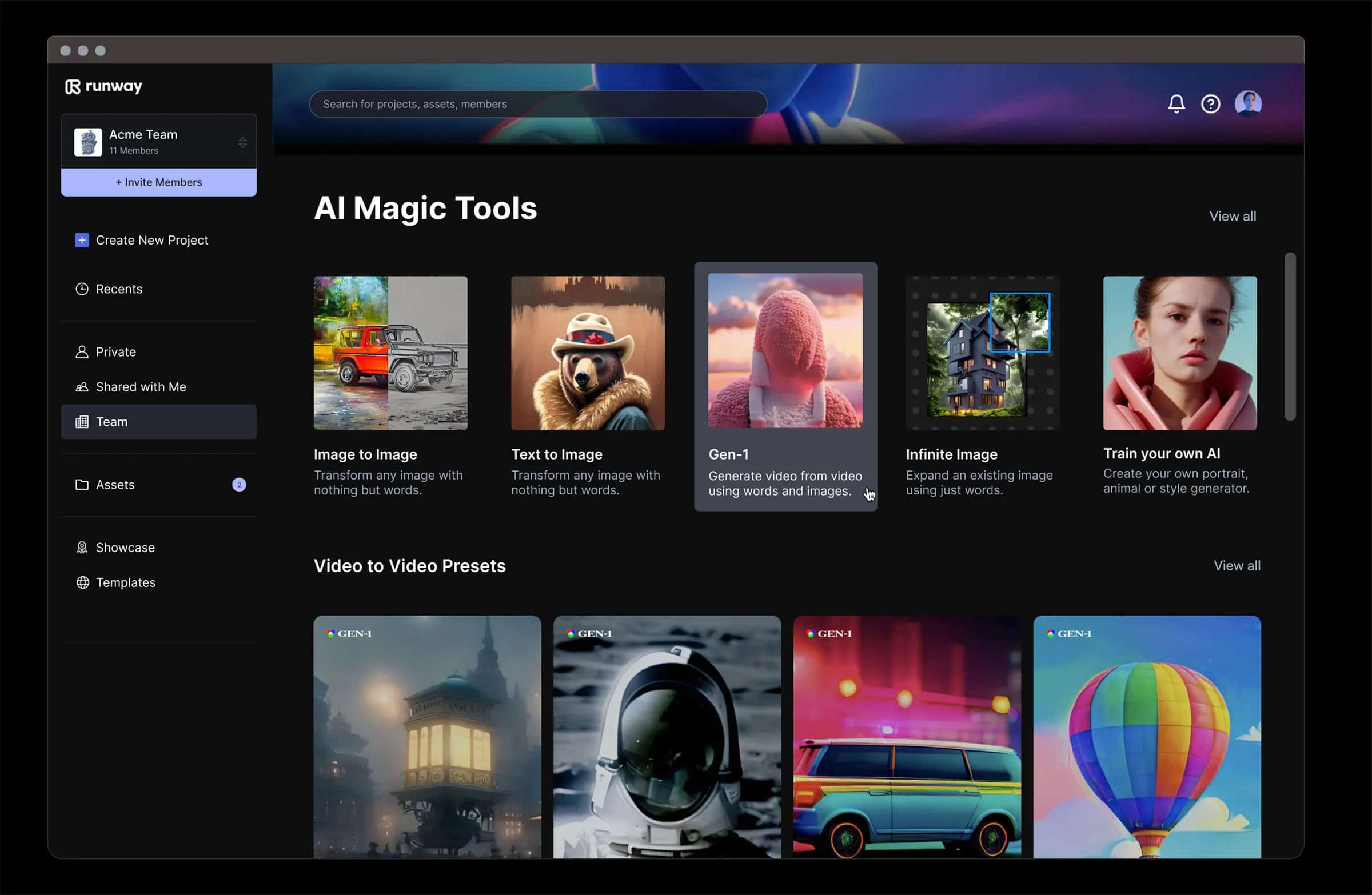
Startbahn Runway Gen-2, entwickelt von Runway, stellt eine bedeutende Entwicklung im Bereich der generative KIinsbesondere bei der Video- und Bildsynthese. Dieses Tool demonstriert die Leistungsfähigkeit der multimodalen KI, indem es den Nutzern erlaubt, neuartige Videos mit einer Mischung aus Text, Bildern oder Videoclips zu erstellen. Runway Gen-2 ermöglicht es Ihnen, präzise, realistische und kontrollierbare Multimedia-Ausgaben zu erstellen, die die Grenzen der digitalen Kreativität verschieben.
Die neuesten Gen-2-Updates sind besonders bemerkenswert, weil sie die Wiedergabetreue und Konsistenz der produzierten Videos erheblich verbessern. Dieser Qualitätssprung hat in der KI-Gemeinschaft Aufsehen erregt und wird von den Nutzern als ein entscheidender Moment in der Entwicklung der generativen KI bezeichnet. Die Fähigkeit des Tools, aus einfachen Textanweisungen, Bildern oder vorhandenen Videos vollständige Videos zu erzeugen, ist eine bahnbrechende Funktion, die neue Möglichkeiten für das Geschichtenerzählen und die digitalen Medien bietet. Solche Fähigkeiten haben zu Vergleichen mit der Erfindung der Kamera geführt, was darauf hindeutet, dass die KI zu einem neuen Medium für die Erfassung und Erstellung visueller Erzählungen wird.
Die wichtigsten Merkmale von Runway Gen-2 sind:
Die Möglichkeit, maßgeschneiderte Video- und Bildkreationen zu erstellen.
Einfaches Herunterladen der erstellten Inhalte für verschiedene Zwecke.
Die Zugänglichkeit sowohl auf der Web- als auch auf der mobilen Plattform von Runway bietet Vielseitigkeit und Komfort.
Ein Design, das die Nutzer in den Mittelpunkt stellt Entwicklungen in der generativen KIund sorgt für ständige Innovation.
Runway Gen-2 läutet eine neue Ära der digitalen Medien ein, in der Storytelling, Kreativität und künstliche Intelligenz zusammenkommen und ungeahnte Möglichkeiten der Inhaltserstellung eröffnen.
2. ImageBind von Meta AI
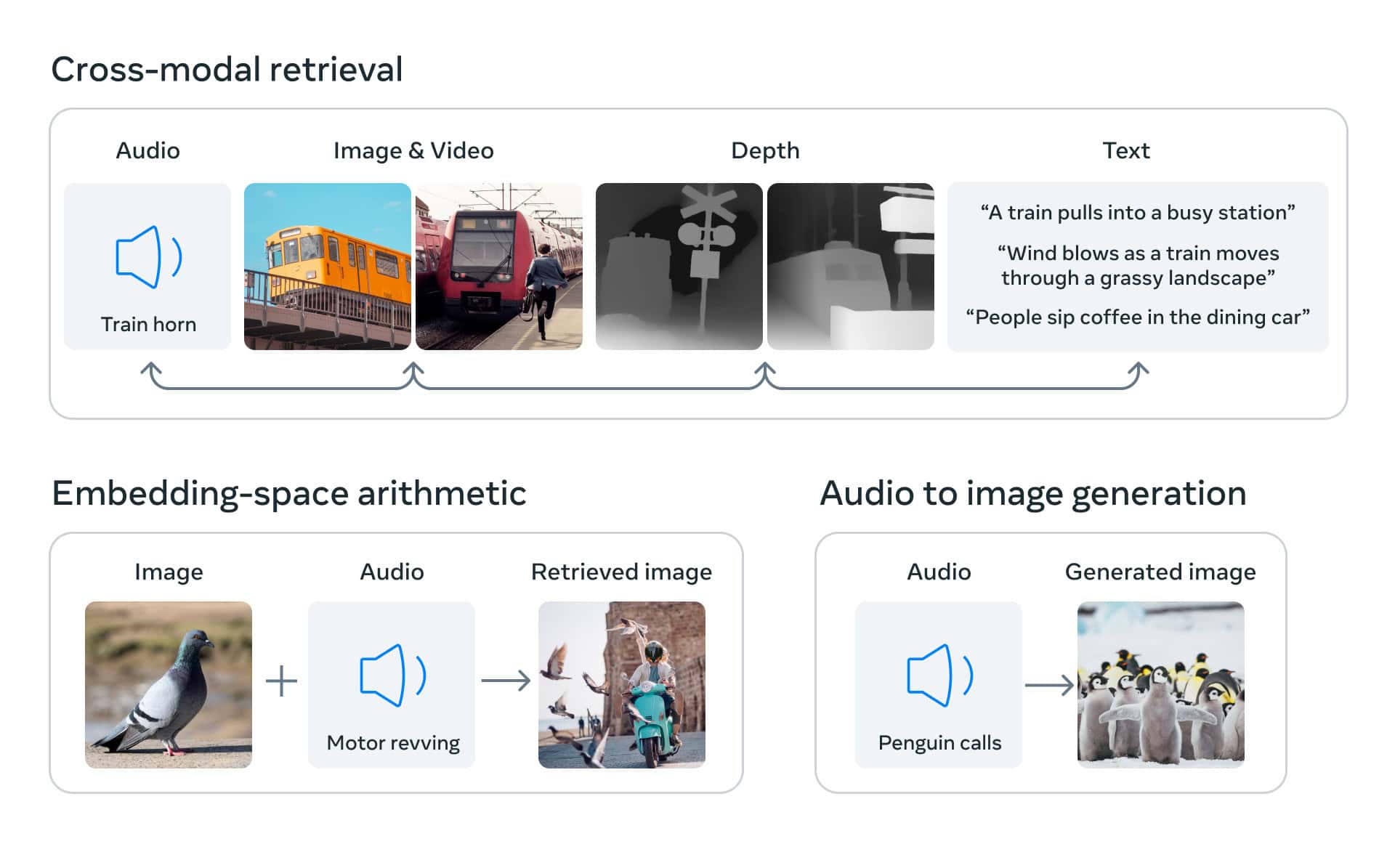
ImageBind, entwickelt von Meta AI, steht an der Spitze der multimodalen KI-Innovation und stellt einen bedeutenden Sprung bei der Integration und Interpretation verschiedener Datentypen dar. Dieses bahnbrechende Modell kombiniert auf einzigartige Weise Informationen aus sechs verschiedenen Modalitäten: Bilder, Text, Audio, Tiefen-, Wärme- und IMU-Daten. Diese Integration ermöglicht eine gemeinsame Einbettung dieser unterschiedlichen Datentypen und schafft so nie dagewesene Möglichkeiten für die modalitätsübergreifende Suche, die arithmetische Komposition von Modalitäten, die Erkennung und die Erzeugung.
Der Kern der ImageBind-Innovation liegt in der Erweiterung groß angelegter Modelle für die Bildsprache. Es verbessert die Zero-Shot-Fähigkeiten dieser Modelle, so dass sie sich nahtlos an neue Modalitäten anpassen können. Diese Funktion ermöglicht die Entwicklung neuartiger Anwendungen und erweitert die potenziellen Einsatzmöglichkeiten für KI-Systeme erheblich. ImageBind hat eine überragende Leistung bei neuartigen Zero-Shot-Erkennungsaufgaben in diesen Modalitäten gezeigt und neue Maßstäbe im Bereich der Erkennung von wenigen Aufnahmen gesetzt.
Die Entwicklung von ImageBind ist Teil der umfassenderen Bemühungen von Meta, multimodale KI-Systeme zu schaffen, die aus einer Vielzahl von Datentypen lernen. Die Fähigkeit von ImageBind, sechs verschiedene Formen von Daten in einem einzigen Einbettungsraum zu kombinieren, ist beispiellos. Diese Fähigkeit ahmt nicht nur die menschliche Wahrnehmung besser nach, sondern ermöglicht es Maschinen auch, verschiedene Formen von Informationen gemeinsam effektiver zu analysieren.
Zu den wichtigsten Funktionen von ImageBind gehören:
Integration von sechs Modalitäten (Bilder, Text, Audio, Tiefe, Wärme, IMU) in ein einziges Modell.
Verbesserte Zero-Shot-Fähigkeiten, die die Funktionalität von Bildsprachmodellen erweitern.
Hervorragende Leistung bei der Erkennung von Nullschüssen und wenigen Schüssen.
Open-Source-Verfügbarkeit, die zu Fortschritten auf dem Gebiet der multimodalen KI beiträgt.
Mit seinem bahnbrechenden Ansatz hat ImageBind das Potenzial, die künstliche Intelligenz zu revolutionieren und zu innovativen Anwendungen im Bild und Videogenerierung, Audiosynthese und immersive virtuelle Erfahrungen. Es ist ein Beweis für die sich entwickelnden Fähigkeiten der KI bei der Nachahmung menschlicher kognitiver Prozesse und der Interpretation der Welt um uns herum.
3. ChatGPT
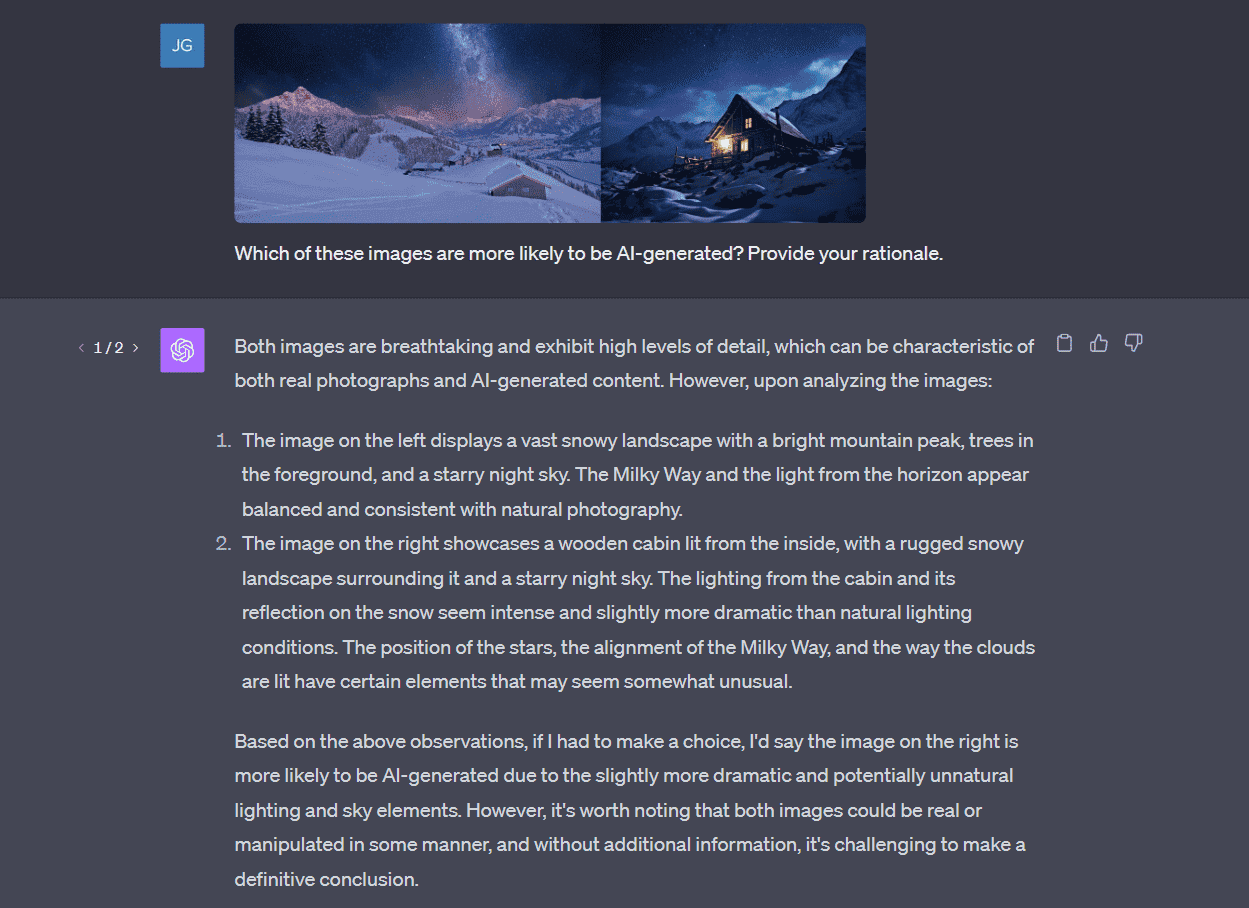
ChatGPT machte einen großen Schritt nach vorn, indem es multimodale Funktionen einbezog und seine Interaktionsmöglichkeiten über Text hinaus auf Sprach- und Bilderkennung ausdehnte. Diese Erweiterung stellt eine bedeutende Entwicklung in der Chatbot-Technologie dar.
Eine der bemerkenswertesten Erweiterungen ist die Bilderkennung von ChatGPT. ChatGPT kann jetzt Bilder verstehen und interpretieren, einschließlich handgeschriebenem Text. Benutzer können ein Bild hochladen und mit dem Chatbot über dessen Inhalt sprechen, sei es, um Objekte im Bild zu identifizieren, wie z. B. eine Wolke, oder um einen Essensplan aus einem Foto des Inhalts ihres Kühlschranks zu erstellen. Diese Funktion macht ChatGPT zu einem unglaublich vielseitigen Tool, das in der Lage ist, kontextbezogene und relevante Antworten auf der Grundlage visueller Eingaben zu geben.
Neben der Bilderkennung hat sich ChatGPT auch an die Sprachinteraktion herangewagt. Ausgestattet mit einem Text-to-Speech-Modell, bietet es den Nutzern die Wahl zwischen fünf verschiedenen Sprachoptionen, was dem Chat-Erlebnis eine neue Dimension verleiht. Durch die Integration des OpenAI-Spracherkennungssystems Whisper wird diese Fähigkeit noch weiter verbessert. Whisper kann gesprochene Worte in Text umwandeln und ermöglicht so einen nahtlosen und intuitiven Dialog zwischen dem Benutzer und ChatGPT. Dieser multimodale Ansatz ermöglicht eine natürlichere und ansprechendere Konversationserfahrung.
Zu den wichtigsten Merkmalen des multimodalen ChatGPT gehören:
Multimodale Fähigkeiten, die nicht nur Text, sondern auch Bilder und Sprache verarbeiten.
Bilderkennung, die es ermöglicht, Bilder und handgeschriebenen Text zu interpretieren.
Die Spracherkennung wird durch ein Text-to-Speech-Modell und fünf verschiedene Sprachoptionen unterstützt.
Integration mit Whisper von OpenAI für eine effiziente Sprache-zu-Text-Transkription.
Der Vorstoß von ChatGPT in multimodale Funktionalitäten ist ein wichtiger Meilenstein in der KI-Entwicklung. Er zeigt das Potenzial großer Modelle zur Verarbeitung und Interpretation einer Vielzahl von Datentypen und ebnet den Weg für anspruchsvollere und interaktive KI-Anwendungen.
4. Inworld AI
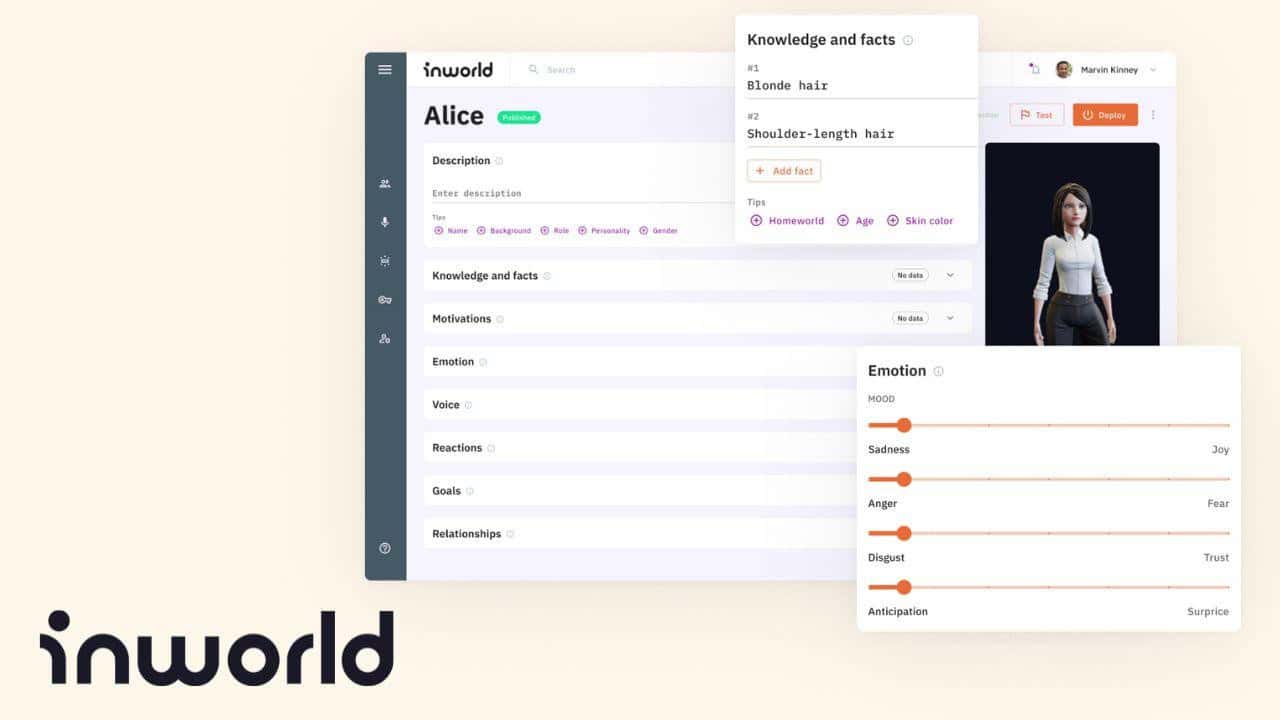
Inworld stellt einen bedeutenden Fortschritt im Bereich der künstlichen Intelligenz dar, insbesondere für nicht spielbare Charaktere (NPCs) in Spielen und interaktiven Umgebungen. Entwickelt von dem Team, das hinter Googles Dialogflow steht, geht diese Charakter-Engine über herkömmliche große Sprachmodelle (LLMs) hinaus und führt eine Reihe von Funktionen ein, die KI-NPCs zu neuen Höhen in Bezug auf Realismus und Interaktion führen.
Was Inworld auszeichnet, ist sein umfassender Ansatz zur Charakterentwicklung. Er ermöglicht es den Nutzern, KI-NPCs mit ausgeprägten Persönlichkeiten zu erstellen, die durch ein tiefes Verständnis für den Kontext und die Erzählung verbessert werden. Dadurch wird sichergestellt, dass die Charaktere ihrer Rolle innerhalb der Spielwelt treu bleiben und den Spielern ein intensiveres Erlebnis bieten. Die Konfigurierbarkeit des Tools erstreckt sich auf Aspekte wie Sicherheit, Wissen, Gedächtnis und narrative Kontrolle und macht es zu einer vielseitigen Lösung für verschiedene Anwendungen.
Inworld ist nicht nur ein Durchbruch für Spiele. Es wird auch in anderen Bereichen eingesetzt, z. B. zur Schaffung einfühlsamer Markenbotschafter und Kundendienstmitarbeiter, zur Erleichterung personalisierter Lernerfahrungen und zur Verbesserung interaktiver Simulationen und gamifizierten Lernens. Durch die Verwendung von generativer Echtzeit-KI kann das Tool Charaktere erstellen, die reichhaltig, nuanciert und einnehmend sind und einen neuen Standard für KI-gestützte Persönlichkeiten, Dialoge und Reaktionen bieten.
Zu den wichtigsten Merkmalen von Inworld gehören:
Konfigurierbare Sicherheits-, Wissens- und Speicherparameter für eine maßgeschneiderte Charakterentwicklung.
Produktionsfähiges und skalierbares Design, das bei Wachstum keine zusätzliche Konfiguration erfordert.
Optimierung für Echtzeit-Erlebnisse, wodurch es sich ideal für die Integration in dynamische Anwendungen eignet.
Vielseitige Anwendungsmöglichkeiten, von Spielen bis hin zu Kundendienst und Lehrmitteln.
Mit seinem innovativen Ansatz für KI-NPCs setzt Inworld neue Maßstäbe für Charakter-Engines und bietet unvergleichliche Möglichkeiten für die Erstellung einnehmender, realistischer Charaktere in einer Vielzahl von Umgebungen.
5. Zielsetzung (Ehemals Kailua Labs)
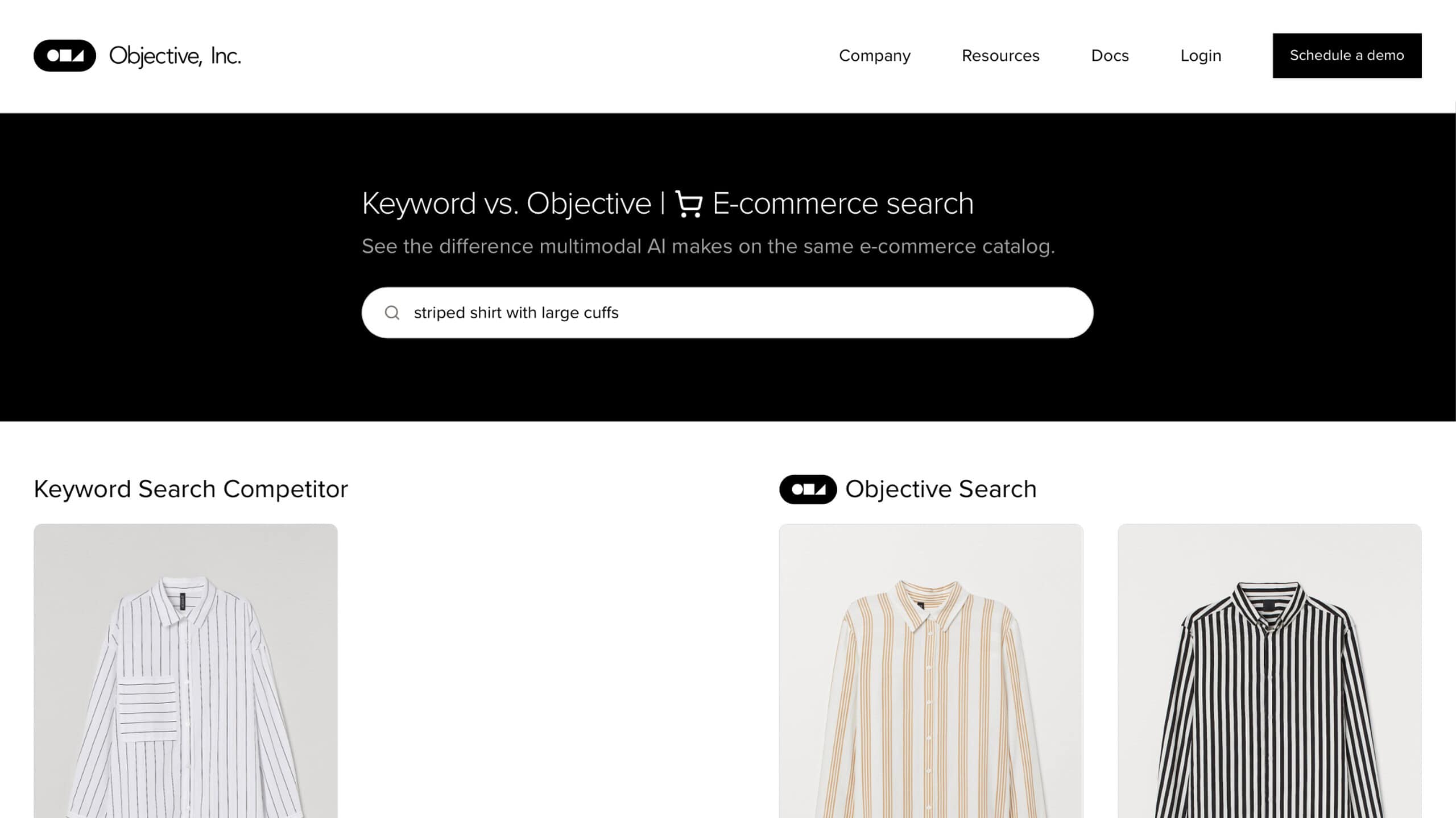
Objective (ehemals Kailua Labs) revolutioniert den Suchprozess mit seinen fortschrittlichen KI-Funktionen. Dieses Tool nutzt die Verarbeitung natürlicher Sprache (NLP), um Benutzern eine intuitive Suche nach einer Vielzahl von Datentypen, einschließlich Bildern, Videos und Audiodaten, zu ermöglichen. Das Besondere an Objective ist seine Fähigkeit, den Suchprozess zu demokratisieren, indem es die Hürden von Spezialwissen oder fortgeschrittenen technischen Kenntnissen beseitigt.
Zielsetzung benutzerfreundliche Schnittstelle Die benutzerfreundliche Oberfläche von Objective ermöglicht es, Suchanfragen in natürlicher Sprache zu stellen, so dass es für Benutzer aller Kenntnisstufen zugänglich und effizient ist. Die Stärke des Tools liegt in der Unterstützung der multimodalen Suche, die es den Nutzern ermöglicht, Inhalte in verschiedenen Anwendungen mit einer Mischung aus natürlicher Sprache und verschiedenen Datentypen zu finden. Dieser Ansatz erhöht die Genauigkeit und Relevanz der Suchergebnisse erheblich.
Zu den wichtigsten Merkmalen von Objective gehören:
Benutzerfreundliches und zugängliches Design, das sich an Benutzer mit unterschiedlichen technischen Kenntnissen richtet.
Multimodale Suchfunktionen, die umfassendere und relevantere Suchergebnisse ermöglichen.
Die Nutzung der Verarbeitung natürlicher Sprache zur Vereinfachung und Verbesserung des Sucherlebnisses.
Das Engagement von Objective für die Bereitstellung benutzerfreundlicher, innovativer KI-Tools ist ein Beispiel für das Engagement des Unternehmens, das Sucherlebnis zu verbessern. Durch die Vereinfachung des Prozesses und die Gewährleistung präziser Ergebnisse macht Objective die erweiterte KI-Suche einem breiteren Publikum zugänglich und verändert die Art und Weise, wie wir mit Daten umgehen.
Transformation der digitalen Interaktion durch multimodale KI-Systeme
Wie wir in diesem Blog erörtert haben, wird die Landschaft der KI durch das Aufkommen multimodaler Tools und Plattformen neu gestaltet. Von der bahnbrechenden Videosynthese von Runway Gen-2 bis hin zur innovativen Charakter-Engine von Inworld AI bringt jedes Tool einzigartige Fähigkeiten mit, die die Grenzen dessen, was KI leisten kann, verschieben. Objective hat die Art und Weise, wie wir die Datensuche angehen, revolutioniert, während ImageBind neue Maßstäbe bei der Datenintegration und -interpretation gesetzt hat. Die Ausweitung von ChatGPT auf die Bild- und Spracherkennung schließlich ist ein Beweis für die Weiterentwicklung der KI, die sie noch vielseitiger und benutzerfreundlicher macht.
Diese Tools stellen nicht nur technologische Fortschritte dar, sondern einen Paradigmenwechsel in der Art und Weise, wie wir mit KI interagieren und sie nutzen. Sie zeigen das immense Potenzial der Integration verschiedener Datentypen, das zu reichhaltigeren, intuitiveren und kontextbezogenen KI-Systemen führt. In dem Maße, in dem diese Tools weiterentwickelt werden und neue Innovationen auftauchen, können wir noch mehr spannende Entwicklungen erwarten, die die Kluft zwischen menschlicher und maschineller Intelligenz weiter überbrücken werden.
Die Zukunft der KI ist zweifellos multimodal, und diese Tools sind nur der Anfang einer Reise zu ganzheitlicheren, interaktiven und intelligenten Systemen. Die Möglichkeiten sind endlos, und das Potenzial für transformative Anwendungen in verschiedenen Branchen ist immens. Die Ära der multimodalen KI ist angebrochen, und sie verspricht, unsere digitale Welt neu zu gestalten.


