
Підбито підсумки дослідження штучного інтелекту: "Ланцюжок думок (меншовартості)?" Спонукання



Підказки за принципом "ланцюжка думок" (Chain-of-Thought, CoT) були визнані проривом у розкритті можливостей міркувань у великих мовних моделях (ВММ). Ця методика, яка передбачає надання покрокових прикладів міркувань для керування БММ, привернула значну увагу спільноти ШІ. Багато дослідників і практиків стверджують, що підказки CoT дозволяють БММ ефективніше вирішувати складні міркування, потенційно долаючи розрив між машинними обчисленнями і вирішенням проблем, подібних до людських.
Однак нещодавня стаття під назвою "Ланцюг бездумності? Аналіз CoT у плануванні" ставить під сумнів ці оптимістичні твердження. У цьому дослідженні, присвяченому завданням планування, критично розглядається ефективність і узагальнюваність підказок CoT. Для фахівців-практиків у галузі ШІ дуже важливо розуміти ці висновки та їхні наслідки для розробки додатків ШІ, які потребують складних можливостей міркування.
Розуміння дослідження
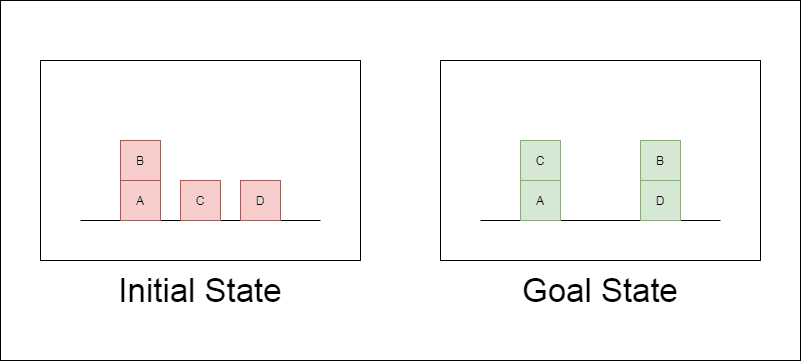
Дослідники обрали класичний домен планування під назвою Blocksworld як основний полігон для тестування. У Blocksworld завдання полягає в тому, щоб переставити набір блоків з початкової конфігурації в цільову за допомогою серії дій переміщення. Цей домен ідеально підходить для тестування міркувань та можливостей планування, тому що:
Дозволяє генерувати завдання різної складності
Вона має чіткі, алгоритмічно верифіковані рішення
Навряд чи він буде широко представлений у навчальних даних LLM
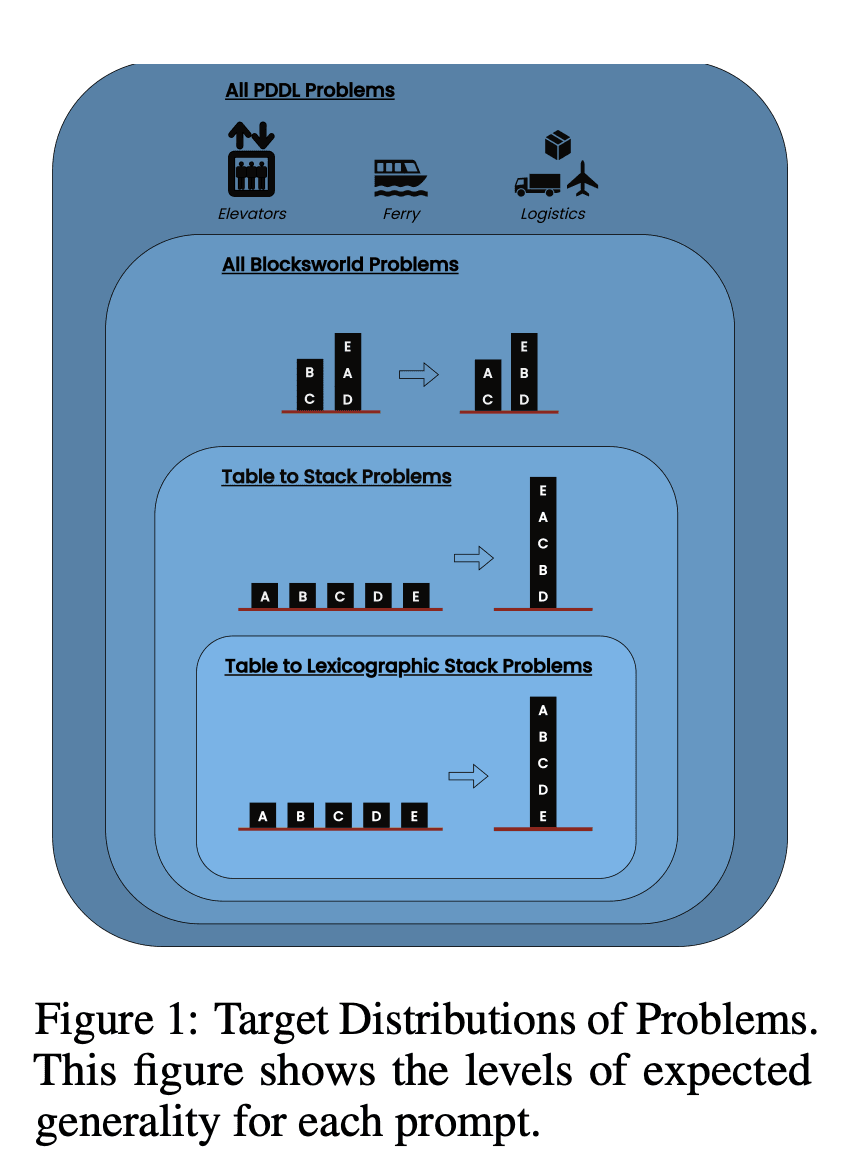
У дослідженні розглядалися три найсучасніші LLM: GPT-4, Claude-3-Opus та GPT-4-Turbo. Ці моделі були протестовані з використанням підказок різної специфічності:
Ланцюг думок з нульовим пострілом (універсальний): Просто додайте до підказки "давайте поміркуємо крок за кроком".
Доказ прогресування (специфічний для PDDL): Надання загального пояснення правильності плану з прикладами.
Універсальний алгоритм Blocksworld: Демонстрація загального алгоритму розв'язання будь-якої задачі на Blocksworld.
Підказка по укладанню: Зосередження на конкретному підкласі проблем Blocksworld (table-to-stack).
Лексикографічне укладання: Подальше звуження до конкретної синтаксичної форми стану мети.
Тестуючи ці підказки на проблемах зростаючої складності, дослідники мали на меті оцінити, наскільки добре магістри права можуть узагальнювати міркування, продемонстровані в прикладах.
Оприлюднено ключові висновки
Результати цього дослідження ставлять під сумнів багато поширених припущень щодо спонукання до застосування ЗПТ:
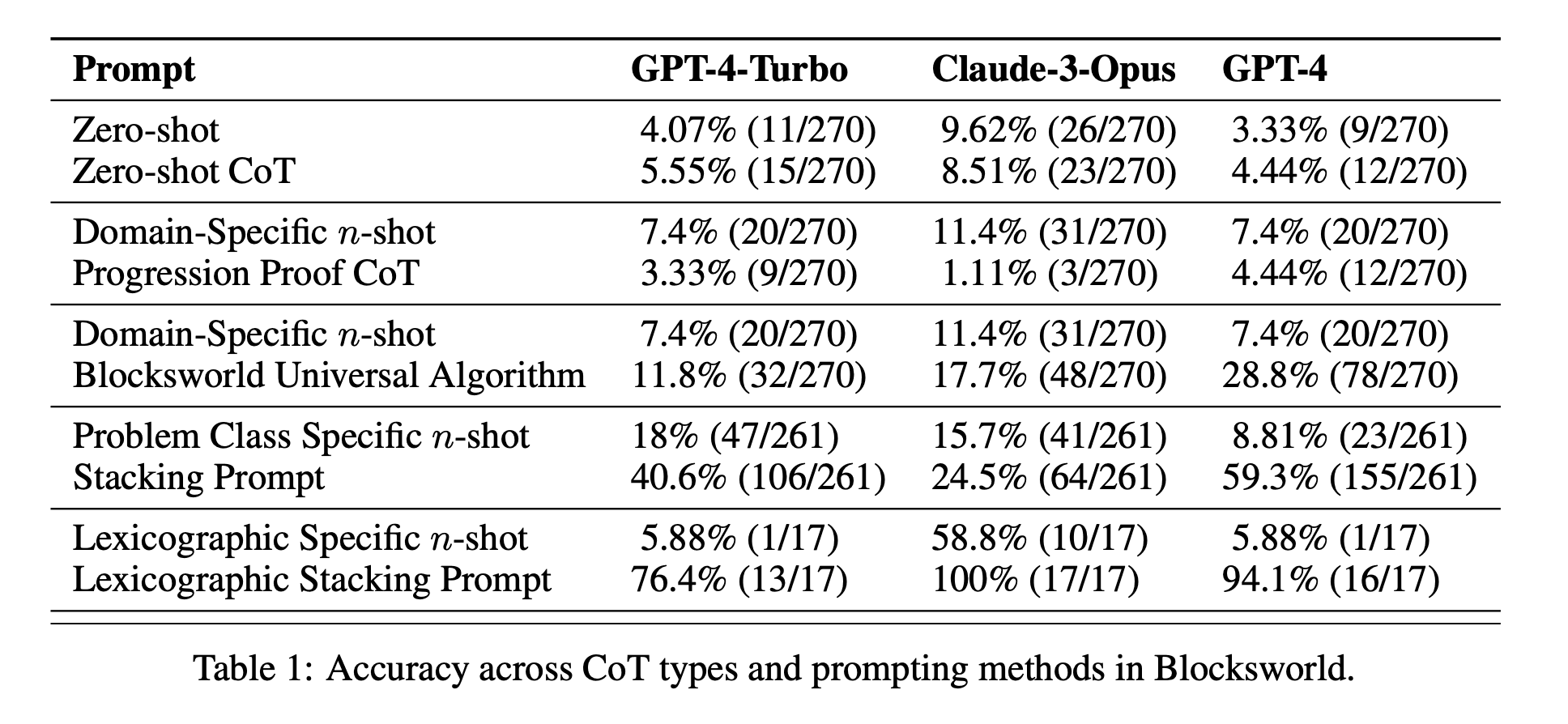
Обмежена ефективність ЗПТ: Всупереч попереднім заявам, підказки CoT показали значне покращення продуктивності лише тоді, коли наведені приклади були надзвичайно схожими на проблему запиту. Як тільки проблеми відхилялися від точного формату, показаного в прикладах, продуктивність різко падала.
Швидка деградація продуктивності: Зі збільшенням складності завдань (вимірюваної кількістю задіяних блоків) точність усіх моделей різко знижувалася, незалежно від використовуваної підказки CoT. Це свідчить про те, що LLMs намагаються поширити міркування, продемонстровані в простих прикладах, на більш складні сценарії.
Неефективність загальних підказок: Дивно, але більш загальні підказки CoT часто показували гірші результати, ніж стандартні підказки без прикладів міркувань. Це суперечить ідеї, що CoT допомагає магістрам вивчити узагальнені стратегії розв'язання проблем.
Компроміс специфічності: Дослідження показало, що вузькоспецифічні підказки можуть забезпечити високу точність, але лише для дуже вузької підгрупи проблем. Це підкреслює гострий компроміс між підвищенням продуктивності та застосовністю підказки.
Відсутність справжнього алгоритмічного навчання: Результати переконливо свідчать про те, що LLMs не вчаться застосовувати загальні алгоритмічні процедури на прикладах CoT. Замість цього вони, здається, покладаються на зіставлення шаблонів, яке швидко ламається, коли стикаються з новими або більш складними проблемами.
Ці висновки мають важливе значення для фахівців у галузі ШІ та підприємств, які прагнуть використовувати підказки CoT у своїх додатках. Вони свідчать про те, що хоча CoT може підвищити продуктивність у певних вузьких сценаріях, він не може бути панацеєю для складних завдань, пов'язаних з міркуваннями, на яку багато хто сподівався.
За межами Blocksworld: Розширення дослідження
Щоб переконатися, що їхні висновки не обмежуються доменом Blocksworld, дослідники розширили своє дослідження на кілька синтетичних проблемних доменів, які зазвичай використовувалися в попередніх дослідженнях CoT:
CoinFlip: Завдання, що передбачає передбачення стану монети після серії підкидань.
LastLetterConcatenation: Задача обробки тексту, що вимагає конкатенації останніх літер заданих слів.
Багатокрокова арифметика: Задачі на спрощення складних арифметичних виразів.
Ці домени були обрані тому, що вони дозволяють генерувати задачі зі зростаючою складністю, подібно до Blocksworld. Результати цих додаткових експериментів вражаюче узгоджувалися з результатами Blocksworld:
Відсутність узагальнення: Підказки CoT показали покращення лише на завданнях, дуже схожих на наведені приклади. Зі збільшенням складності завдання продуктивність швидко погіршувалася до рівня, порівнянного зі стандартними підказками або навіть гіршого.
Синтаксична відповідність шаблонів: У завданні LastLetterConcatenation підказки CoT покращили певні синтаксичні аспекти відповідей (наприклад, використання правильних літер), але не змогли зберегти точність зі збільшенням кількості слів.
Невдача, незважаючи на ідеальні проміжні кроки: В арифметичних задачах, навіть коли моделі могли досконало розв'язувати всі можливі одноцифрові операції, вони все одно не змогли узагальнити їх на довші послідовності операцій.
Ці результати ще більше підтверджують висновок про те, що нинішні магістри не засвоюють узагальнюючих стратегій міркувань на прикладах CoT. Натомість вони, схоже, значною мірою покладаються на поверхневе співставлення шаблонів, яке руйнується, коли вони стикаються з проблемами, що відрізняються від продемонстрованих прикладів.
Наслідки для розвитку штучного інтелекту
Висновки цього дослідження мають важливе значення для розвитку ШІ, особливо для підприємств, які працюють над додатками, що вимагають складних міркувань або можливостей планування:
Переоцінка ефективності CoT: Дослідження ставить під сумнів уявлення про те, що підказки CoT "розблоковують" загальні здібності до міркувань у LLM. Розробникам ШІ слід з обережністю покладатися на CoT у завданнях, які вимагають справжнього алгоритмічного мислення або узагальнення нових сценаріїв.
Обмеження нинішніх магістерських програм: Незважаючи на свої вражаючі можливості в багатьох сферах, сучасні магістри все ще мають проблеми з послідовними, узагальнюючими міркуваннями. Це свідчить про те, що для додатків, які потребують надійного планування або багатокрокового розв'язання проблем, можуть знадобитися альтернативні підходи.
Вартість оперативного інжинірингу: Хоча вузькоспецифічні підказки CoT можуть давати хороші результати для вузького кола проблем, людські зусилля, необхідні для створення цих підказок, можуть переважати переваги, особливо з огляду на їхню обмежену узагальнюваність.
Переосмислення оціночних показників: Дослідження підкреслює важливість тестування моделей ШІ на завданнях різної складності та структури. Покладаючись лише на статичні тестові набори, можна переоцінити реальні можливості моделі.
Розрив між сприйняттям і реальністю: Існує значна розбіжність між уявленнями про розумові здібності магістрів права (які часто антропоморфізуються в популярному дискурсі) та їхніми реальними можливостями, як продемонстровано в цьому дослідженні.
Рекомендації для практиків штучного інтелекту
Враховуючи ці висновки, ми пропонуємо кілька ключових рекомендацій для практиків у галузі штучного інтелекту та підприємств, які працюють з магістрами права:
Суворі практики оцінювання:
Впроваджуйте фреймворки для тестування, які можуть генерувати проблеми різної складності.
Не покладайтеся лише на статичні тестові набори або бенчмарки, які можуть бути представлені в навчальних даних.
Оцініть продуктивність по всьому спектру варіацій проблеми, щоб оцінити справжнє узагальнення.
Реалістичні очікування від CoT:
Використовуйте підказки CoT з розумом, розуміючи їхню обмеженість в узагальненні.
Майте на увазі, що покращення продуктивності за допомогою CoT може бути обмежене вузькими наборами проблем.
Подумайте про компроміс між швидкими інженерними зусиллями та потенційним підвищенням продуктивності.
Гібридні підходи:
Для складних завдань з міркування розгляньте можливість поєднання LLM з традиційними алгоритмічними підходами або спеціалізованими модулями міркування.
Вивчіть методи, які можуть використовувати сильні сторони LLM (наприклад, розуміння природної мови), одночасно компенсуючи їх слабкі сторони в алгоритмічних міркуваннях.
Прозорість у застосунках штучного інтелекту:
Чітко повідомляйте про обмеження систем штучного інтелекту, особливо коли вони пов'язані із завданнями міркування або планування.
Уникайте перебільшення можливостей LLM, особливо в критично важливих для безпеки або з високими ставками додатках.
Продовження досліджень і розробок:
Інвестуйте в дослідження, спрямовані на покращення здатності систем штучного інтелекту до істинного мислення.
Вивчіть альтернативні архітектури або методи навчання, які можуть призвести до більш надійного узагальнення у складних завданнях.
Налаштування для конкретного домену:
Для вузьких, чітко визначених проблемних областей розгляньте можливість точного налаштування моделей на основі специфічних для цієї області даних і моделей міркувань.
Майте на увазі, що така тонка настройка може покращити продуктивність в межах домену, але не може бути узагальнена за його межами.
Дотримуючись цих рекомендацій, фахівці-практики в галузі ШІ можуть розробляти більш надійні та надійні додатки ШІ, уникаючи потенційних пасток, пов'язаних з переоцінкою розумових здібностей нинішніх LLMs. Висновки цього дослідження слугують цінним нагадуванням про важливість критичної та реалістичної оцінки у сфері ШІ, що стрімко розвивається.
Підсумок
Це новаторське дослідження про підказки ланцюжка думок у завданнях планування кидає виклик нашому розумінню можливостей LLM і спонукає до переоцінки поточних практик розробки ШІ. Виявляючи обмеження ШПМ в узагальненні на складні проблеми, воно підкреслює необхідність більш ретельного тестування та реалістичних очікувань у застосуванні ШІ.
Для практиків і підприємств, що займаються ШІ, ці висновки підкреслюють важливість поєднання сильних сторін LLM зі спеціалізованими підходами до міркувань, інвестування в рішення для конкретних доменів, де це необхідно, і збереження прозорості щодо обмежень систем ШІ. У міру того, як ми рухаємося вперед, спільнота ШІ повинна зосередитися на розробці нових архітектур і методів навчання, які можуть подолати розрив між зіставленням шаблонів і справжнім алгоритмічним мисленням. Це дослідження слугує важливим нагадуванням про те, що, незважаючи на значний прогрес, досягнутий у галузі ШІ, досягнення здатності мислити, подібної до людської, залишається постійним викликом у дослідженнях і розробках ШІ.


