
від Григорій Еліас | Гру 29, 2020 | Корпоративний штучний інтелект, Як зробити, Магістр права / НЛП
Tutorial: How to pre-train ELECTRA for Spanish from Scratch Originally published by Skim AI's Machine Learning Researcher, Chris Tran. Introduction This article is on how pre-train ELECTRA, another member of the Transformer pre-training method family, for Spanish to...

від Григорій Еліас | Гру 28, 2020 | Корпоративний штучний інтелект, Як зробити, Магістр права / НЛП
Tutorial: How to Fine-tune BERT for NER Originally published by Skim AI's Machine Learning Researcher, Chris Tran. Introduction This article is on how to fine-tune BERT for Named Entity Recognition (NER). Specifically, how to train a BERT variation, SpanBERTa, for...

від Григорій Еліас | Гру 28, 2020 | Корпоративний штучний інтелект, Як зробити, Магістр права / НЛП
Tutorial: How to Fine-Tune BERT for Extractive Summarization Originally published by Skim AI's Machine Learning Researcher, Chris Tran 1. Introduction Summarization has long been a challenge in Natural Language Processing. To generate a short version of a document...

від Григорій Еліас | Гру 11, 2020 | Корпоративний штучний інтелект, Магістр права / НЛП, Управління проектами
8 Ways News & Content Companies use A.I. to Save Money and Improve UX The best way to understand the impact of technology is to understand the specifics, examples of how to actually apply technology to solve current problems. The following are 8 common AI...

від Григорій Еліас | Лип 27, 2020 | Магістр права / НЛП, Управління проектами
Natural Language Generation and Its Business Applications Natural Language Generation (NLG) As a continued exploration of AI Authors and Robot-Generated news, it is worthwhile to explore some of the technology driving these algorithms. AI designed to generate...
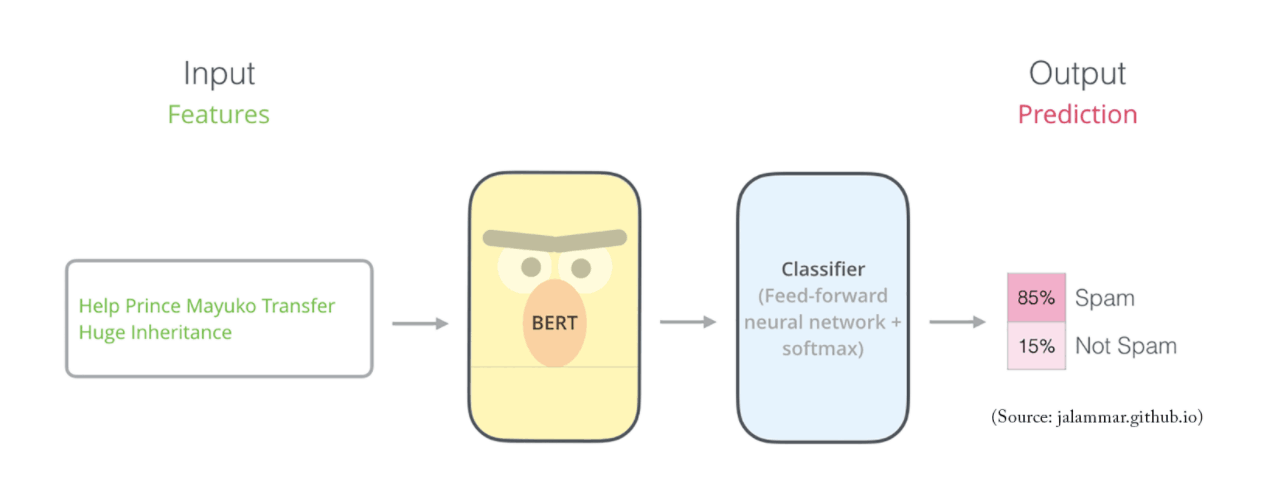
від Григорій Еліас | Кві 29, 2020 | Як зробити, Магістр права / НЛП
SpanBERTa: How We Trained RoBERTa Language Model for Spanish from Scratch Originally published by Skim AI's Machine Learning Research Intern, Chris Tran. spanberta_pretraining_bert_from_scratch Introduction¶ Self-training methods with transformer models have...
від Григорій Еліас | Кві 15, 2020 | Як зробити, Магістр права / НЛП
Tutorial: Fine tuning BERT for Sentiment Analysis Originally published by Skim AI's Machine Learning Researcher, Chris Tran. BERT_for_Sentiment_Analysis A - Introduction¶ In recent years the NLP community has seen many breakthoughs in Natural Language Processing,...
від Григорій Еліас | Бер 20, 2020 | Корпоративний штучний інтелект, Магістр права / НЛП, Управління проектами
10 Questions to Ask Before Starting a Machine Learning Project Over 80% of data science projects fail to go beyond testing and into production. If everyone is starting a machine learning project, where is it going wrong? Undoubtedly, ML solutions increase efficiencies...

від Григорій Еліас | Гру 5, 2019 | Корпоративний штучний інтелект, Магістр права / НЛП, Управління проектами
Topic Modeling for Product Managers What is Topic Modeling? Topic modeling is a type of natural language processing (NLP) used to find “topics,” or commonly occurring words or groups of words, within a set of documents. Topic models are critical to product managers...

від Григорій Еліас | Лис 6, 2019 | Магістр права / НЛП, Управління проектами
What You Should Know Before You Select aSentiment Analysis Dataset Why do you need a sentiment analysis dataset for training?Sentiment models are a type of natural language processing (NLP) algorithm that determines the polarity of a piece of text. That is, a...









Останні коментарі