
Precisamos de repensar a cadeia de pensamento (CoT) que leva a IA&YOU #68



Estatísticas da semana: O desempenho do CoT de disparo zero foi de apenas 5,55% para o GPT-4-Turbo, 8,51% para o Claude-3-Opus e 4,44% para o GPT-4. (artigo "Chain of Thoughtlessness?")
O estímulo da Cadeia de Pensamento (CoT) tem sido aclamado como um avanço na revelação das capacidades de raciocínio dos modelos de linguagem de grande porte (LLMs). No entanto, a investigação recente pôs em causa estas afirmações e levou-nos a rever esta técnica.
Na edição desta semana de AI&YOU, exploramos as ideias de três blogues que publicámos sobre o tema:
Análise de documentos de investigação sobre IA: "Cadeia de irreflexão?"
10 melhores técnicas de apresentação de propostas para os LLM
Precisamos de repensar a cadeia de pensamento (CoT) que induz a IA&YOU #68
Os LLM demonstram capacidades notáveis no processamento e geração de linguagem natural (NLP). No entanto, quando confrontados com tarefas de raciocínio complexas, estes modelos podem ter dificuldade em produzir resultados exactos e fiáveis. É aqui que entra em jogo o estímulo da Cadeia de Pensamento (CoT), uma técnica que visa melhorar as capacidades de resolução de problemas dos LLMs.
Um avançado engenharia rápida A técnica CoT foi concebida para guiar os LLM através de um processo de raciocínio passo a passo. Ao contrário dos métodos de incitação normais que visam respostas diretas, a incitação CoT incentiva o modelo a gerar passos de raciocínio intermédios antes de chegar a uma resposta final.
No seu cerne, a CoT consiste em estruturar os pedidos de entrada de forma a obter uma sequência lógica de pensamentos do modelo. Ao dividir problemas complexos em passos mais pequenos e manejáveis, a CoT tenta permitir que os LLMs naveguem por caminhos de raciocínio intrincados de forma mais eficaz.
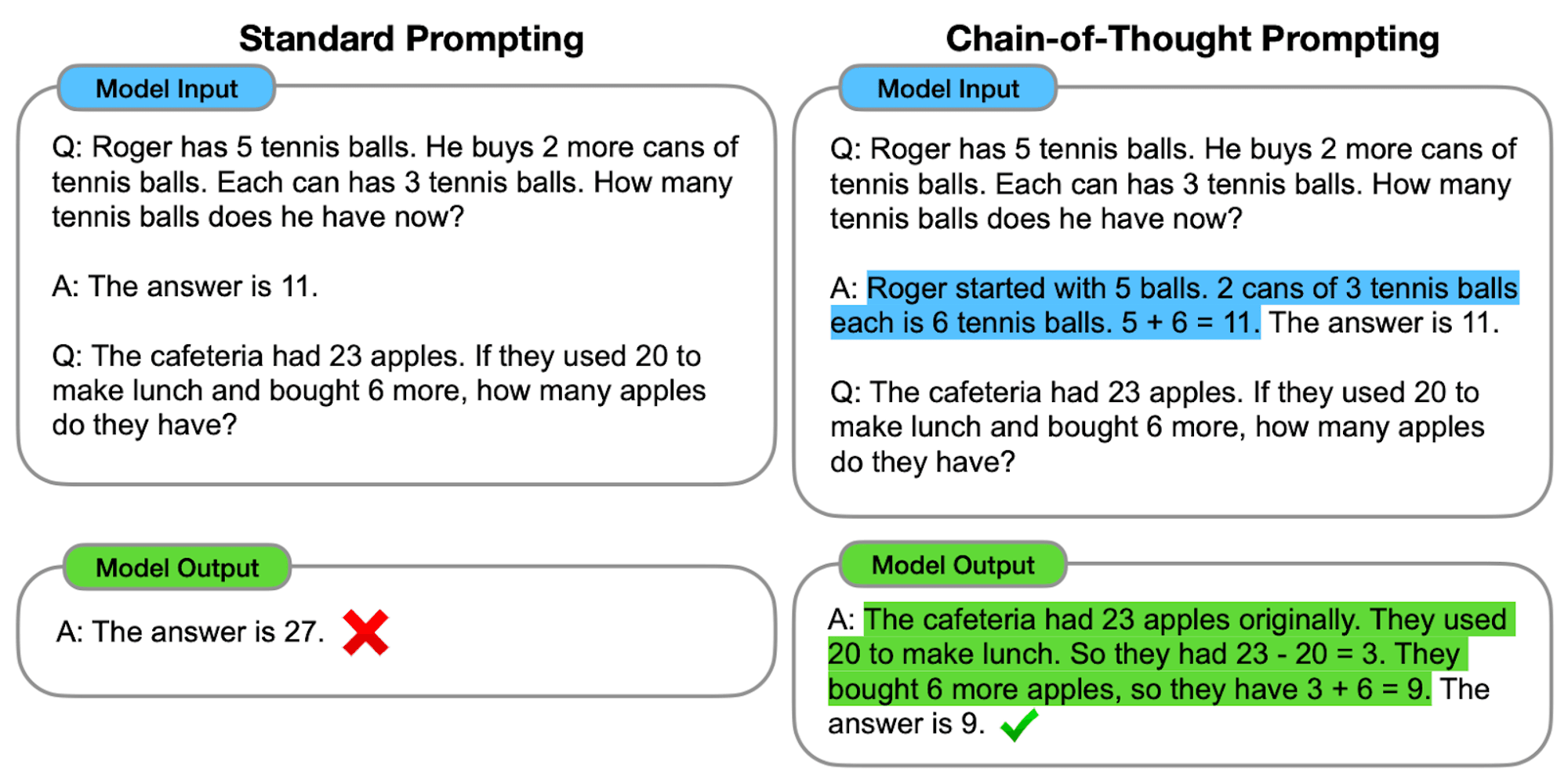
Como funciona o CoT
Na sua essência, a solicitação de CoT orienta os modelos linguísticos através de uma série de passos de raciocínio intermédios antes de chegar a uma resposta final. Este processo envolve normalmente:
Decomposição de problemas: A tarefa complexa é dividida em etapas mais pequenas e fáceis de gerir.
Raciocínio passo a passo: O modelo é convidado a refletir explicitamente sobre cada etapa.
Progressão lógica: Cada passo baseia-se no anterior, criando uma cadeia de pensamentos.
Desenho de conclusão: A resposta final é obtida a partir das etapas de raciocínio acumuladas.
Tipos de CoT Prompting
O estímulo da cadeia de pensamento pode ser implementado de várias formas, destacando-se dois tipos principais:
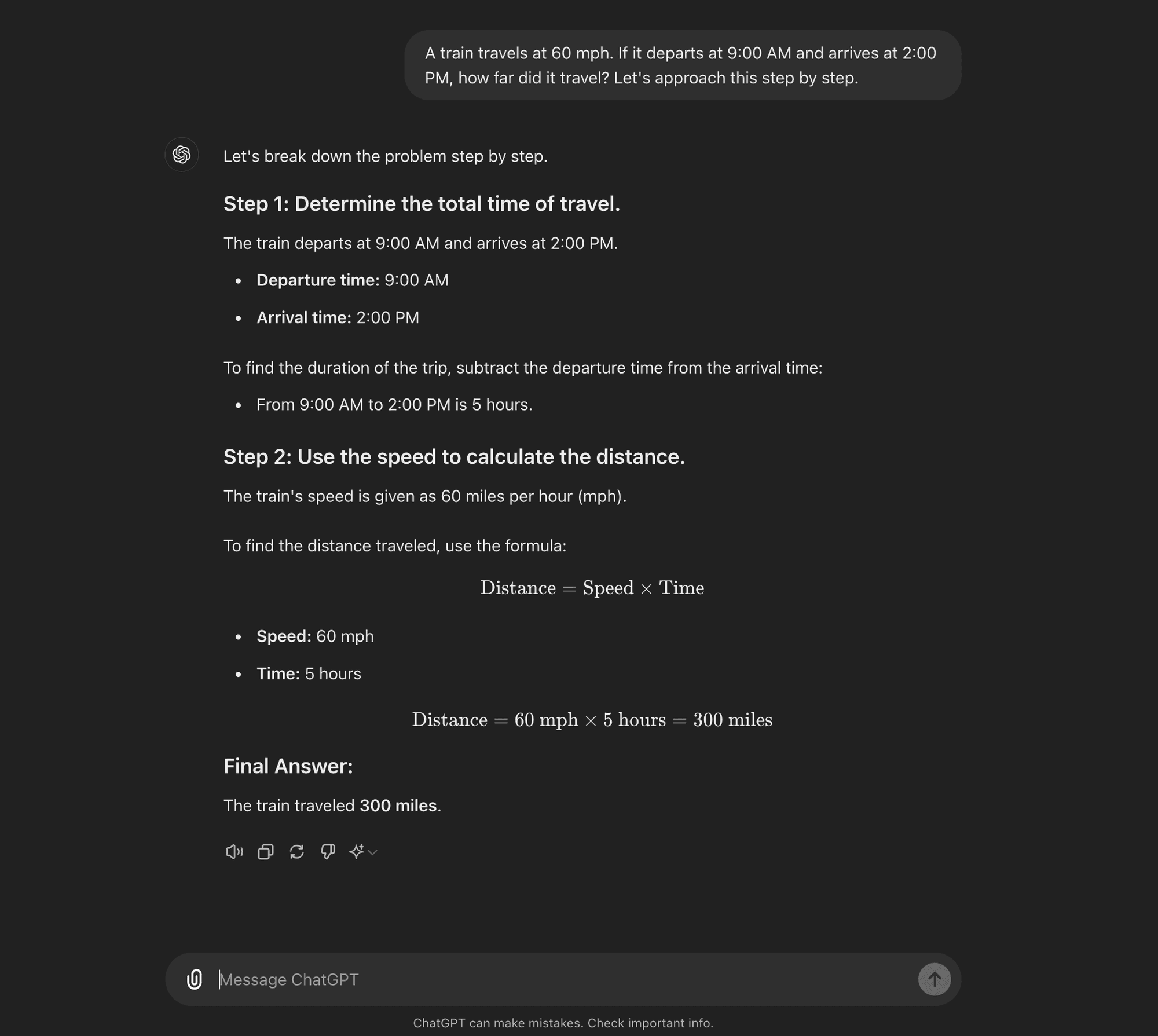
CoT de tiro zero: A CoT de disparo zero não requer exemplos específicos de tarefas. Em vez disso, utiliza um simples aviso como "Vamos abordar isto passo a passo" para encorajar o modelo a decompor o seu processo de raciocínio. ****
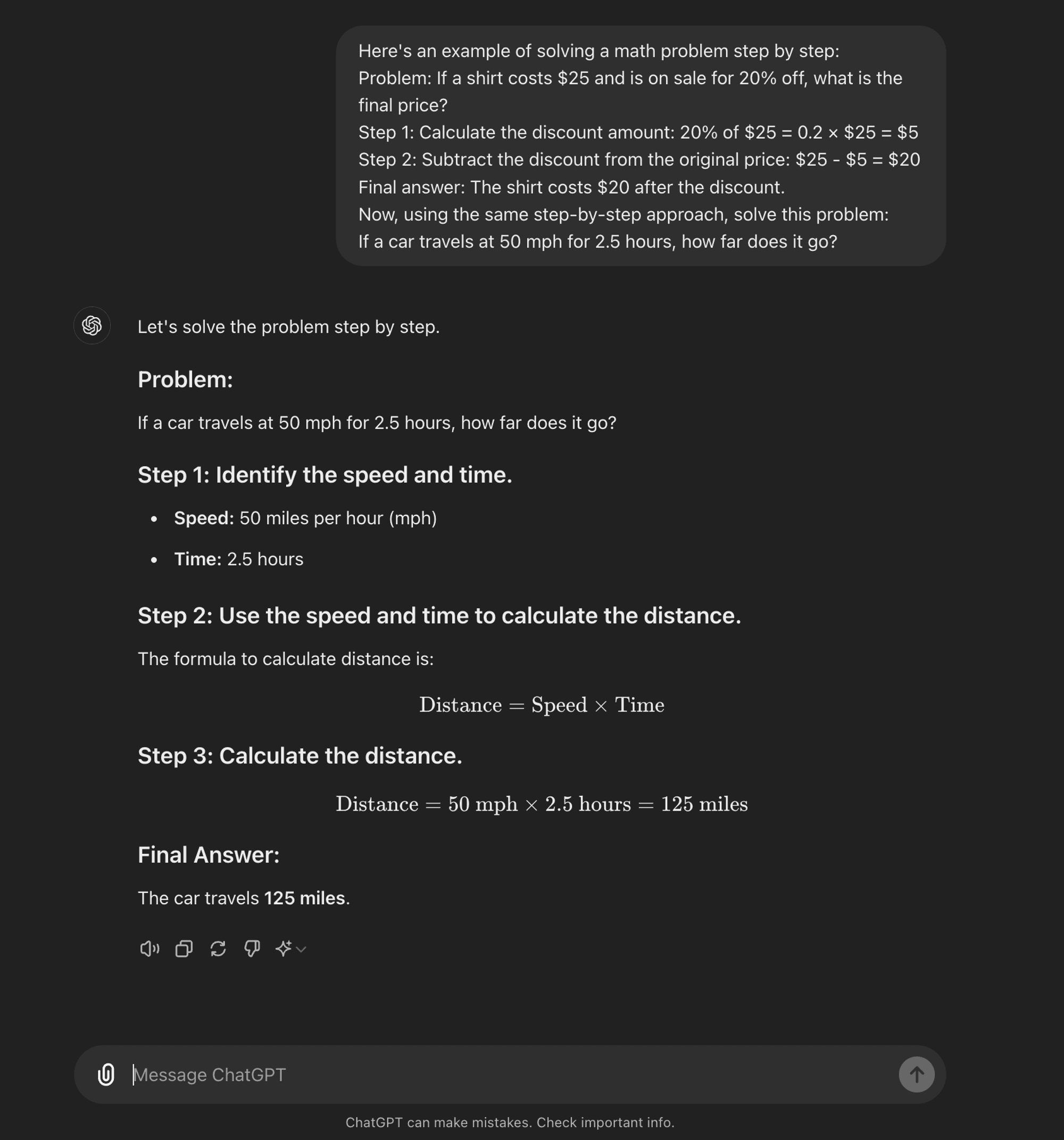
CoT de poucos tiros: A CoT de poucas oportunidades envolve fornecer ao modelo um pequeno número de exemplos que demonstram o processo de raciocínio desejado. Estes exemplos servem de modelo para o modelo seguir quando estiver a lidar com problemas novos e inéditos.
CoT de tiro zero
CoT de poucos disparos
Análise de documentos de investigação sobre IA: "Cadeia de irreflexão?"
Agora que já sabe o que é o CoT prompting, podemos mergulhar em alguns estudos recentes que põem em causa alguns dos seus benefícios e oferecem algumas ideias sobre quando é realmente útil.
O documento de investigação, intitulado "Cadeia de irreflexão? Uma análise da CoT no planeamento," fornece uma análise crítica da eficácia e da generalização do CoT prompting. Enquanto profissionais de IA, é crucial compreender estas conclusões e as suas implicações para o desenvolvimento de aplicações de IA que exijam capacidades de raciocínio sofisticadas.

Os investigadores escolheram um domínio de planeamento clássico chamado Blocksworld como principal campo de ensaio. No Blocksworld, a tarefa é reorganizar um conjunto de blocos de uma configuração inicial para uma configuração de objetivo, utilizando uma série de acções de movimento. Este domínio é ideal para testar as capacidades de raciocínio e planeamento porque:
Permite a criação de problemas de complexidade variável
Tem soluções claras e verificáveis por algoritmos
É pouco provável que esteja fortemente representado nos dados de formação do LLM
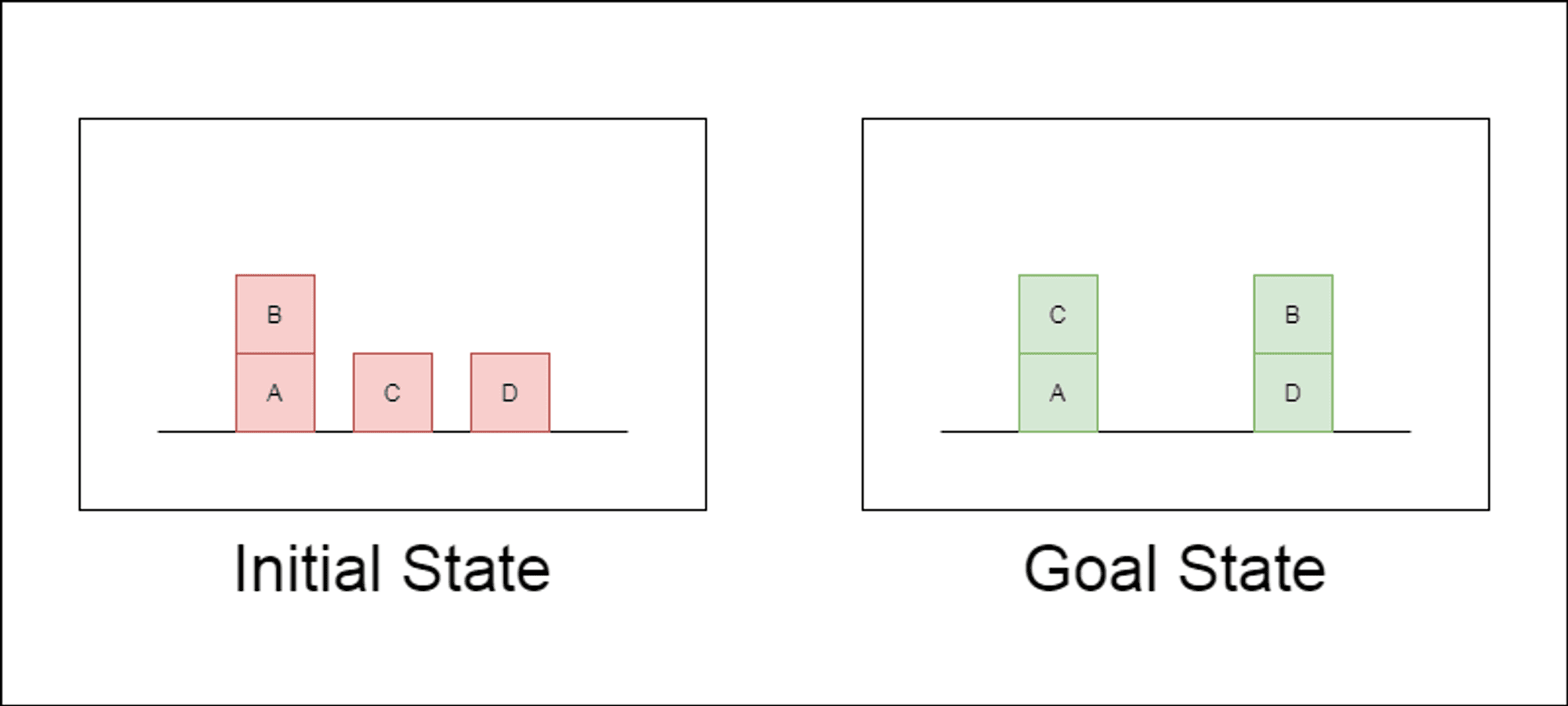
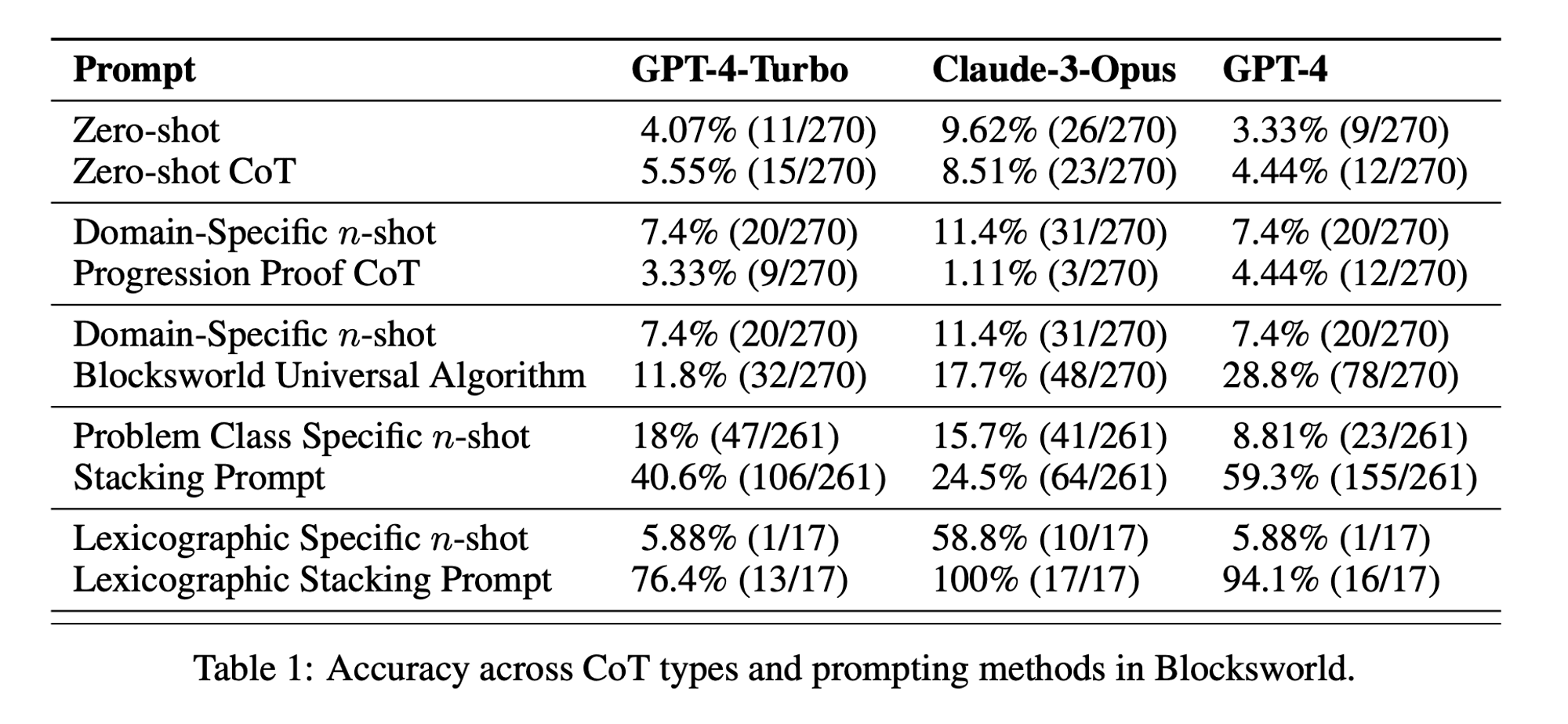
O estudo examinou três LLMs de última geração: GPT-4, Claude-3-Opus e GPT-4-Turbo. Estes modelos foram testados com mensagens de especificidade variável:
Cadeia de pensamento de tiro zero (Universal): Basta acrescentar "vamos pensar passo a passo" ao prompt.
Prova de progressão (específica da PDDL): Fornecer uma explicação geral da correção do plano com exemplos.
Algoritmo universal Blocksworld: Demonstração de um algoritmo geral para resolver qualquer problema Blocksworld.
Sugestão de empilhamento: Centrar-se numa subclasse específica de problemas Blocksworld (table-to-stack).
Empilhamento lexicográfico: Redução adicional a uma forma sintáctica específica do estado do objetivo.
Ao testar estas sugestões em problemas de complexidade crescente, os investigadores pretendiam avaliar até que ponto os LLMs conseguiam generalizar o raciocínio demonstrado nos exemplos.
Principais conclusões reveladas
Os resultados deste estudo desafiam muitos dos pressupostos prevalecentes sobre a solicitação de CoT:
Eficácia limitada do CoT: Contrariamente às afirmações anteriores, a solicitação CoT só apresentou melhorias significativas de desempenho quando os exemplos fornecidos eram extremamente semelhantes ao problema de consulta. Assim que os problemas se desviaram do formato exato apresentado nos exemplos, o desempenho caiu drasticamente.
Degradação rápida do desempenho: À medida que a complexidade dos problemas aumentava (medida pelo número de blocos envolvidos), a precisão de todos os modelos diminuía drasticamente, independentemente do estímulo de CoT utilizado. Este facto sugere que os LLM têm dificuldade em alargar o raciocínio demonstrado em exemplos simples a cenários mais complexos.
Ineficácia das instruções gerais: Surpreendentemente, as instruções de CoT mais gerais tiveram um desempenho pior do que as instruções normais sem quaisquer exemplos de raciocínio. Este facto contradiz a ideia de que a CoT ajuda os LLM a aprender estratégias generalizáveis de resolução de problemas.
Compensação da especificidade: O estudo concluiu que as instruções altamente específicas podem atingir uma elevada precisão, mas apenas num subconjunto muito restrito de problemas. Este facto evidencia um forte compromisso entre os ganhos de desempenho e a aplicabilidade da mensagem.
Falta de uma verdadeira aprendizagem algorítmica: Os resultados sugerem fortemente que os LLM não estão a aprender a aplicar procedimentos algorítmicos gerais a partir dos exemplos de CoT. Em vez disso, parecem basear-se na correspondência de padrões, que se desintegra rapidamente quando confrontados com problemas novos ou mais complexos.
Estas conclusões têm implicações significativas para os profissionais de IA e para as empresas que pretendem tirar partido das solicitações de CoT nas suas aplicações. Sugerem que, embora a CoT possa melhorar o desempenho em determinados cenários restritos, pode não ser a panaceia para tarefas de raciocínio complexas que muitos esperavam.
Implicações para o desenvolvimento da IA
As conclusões deste estudo têm implicações significativas para o desenvolvimento da IA, em particular para as empresas que trabalham em aplicações que exigem capacidades complexas de raciocínio ou planeamento:
Reavaliação da eficácia da CdT: Os criadores de IA devem ser cautelosos quanto a confiar na CoT para tarefas que exijam um verdadeiro pensamento algorítmico ou a generalização para cenários novos.
Limitações dos actuais LLM: Podem ser necessárias abordagens alternativas para aplicações que exijam um planeamento robusto ou a resolução de problemas em várias etapas.
O custo da engenharia rápida: Embora os pedidos de CoT altamente específicos possam produzir bons resultados para conjuntos de problemas restritos, o esforço humano necessário para elaborar esses pedidos pode superar os benefícios, especialmente devido à sua limitada generalização.
Repensar as métricas de avaliação: Confiar apenas em conjuntos de testes estáticos pode sobrestimar as verdadeiras capacidades de raciocínio de um modelo.
O fosso entre a perceção e a realidade: Existe uma discrepância significativa entre a perceção das capacidades de raciocínio dos LLM (frequentemente antropomorfizadas no discurso popular) e as suas capacidades reais, tal como demonstrado neste estudo.
Recomendações para os profissionais de IA:
Avaliação: Implementar diversas estruturas de teste para avaliar a verdadeira generalização entre complexidades de problemas.
Utilização do CoT: Aplicar judiciosamente o estímulo da Cadeia de Pensamento, reconhecendo as suas limitações em termos de generalização.
Soluções híbridas: Considerar a combinação de LLMs com algoritmos tradicionais para tarefas de raciocínio complexas.
Transparência: Comunicar claramente as limitações do sistema de IA, especialmente no que diz respeito a tarefas de raciocínio ou planeamento.
I&D em foco: Investir na investigação para melhorar as verdadeiras capacidades de raciocínio dos sistemas de IA.
Afinação: Considere o ajuste fino específico do domínio, mas tenha em atenção os potenciais limites de generalização.
Para os profissionais de IA e para as empresas, estas conclusões sublinham a importância de combinar os pontos fortes do LLM com abordagens de raciocínio especializadas, investindo em soluções específicas do domínio sempre que necessário e mantendo a transparência sobre as limitações do sistema de IA. À medida que avançamos, a comunidade de IA deve concentrar-se no desenvolvimento de novas arquitecturas e métodos de formação que possam colmatar a lacuna entre a correspondência de padrões e o verdadeiro raciocínio algorítmico.
10 melhores técnicas de apresentação de propostas para os LLM
Esta semana, também exploramos dez das técnicas de solicitação mais poderosas e comuns, oferecendo informações sobre as suas aplicações e melhores práticas.

Os avisos bem concebidos podem melhorar significativamente o desempenho de um LLM, permitindo resultados mais exactos, relevantes e criativos. Quer seja um programador de IA experiente ou esteja apenas a começar com LLMs, estas técnicas ajudá-lo-ão a desbloquear todo o potencial dos modelos de IA.
Não deixe de consultar o blogue completo para saber mais sobre cada um deles.
Obrigado por ler AI & YOU!
Para obter ainda mais conteúdos sobre IA empresarial, incluindo infográficos, estatísticas, guias de instruções, artigos e vídeos, siga o Skim AI em LinkedIn
É um Fundador, CEO, Capitalista de Risco ou Investidor que procura serviços de Consultoria de IA, Desenvolvimento de IA fraccionada ou Due Diligence? Obtenha a orientação necessária para tomar decisões informadas sobre a estratégia de produtos de IA da sua empresa e oportunidades de investimento.
Criamos soluções de IA personalizadas para empresas apoiadas por capital de risco e capital privado nos seguintes sectores: Tecnologia Médica, Agregação de Notícias/Conteúdo, Produção de Filmes e Fotos, Tecnologia Educacional, Tecnologia Jurídica, Fintech e Criptomoeda.


