
Llama 3.1 vs. LLMs Proprietários: Uma Análise de Custo-Benefício para Empresas



O panorama dos modelos de linguagem de grande dimensão (LLM) tornou-se um campo de batalha entre modelos de peso aberto como Lhama da Meta 3.1 e ofertas proprietárias de gigantes tecnológicos como a OpenAI. À medida que as empresas navegam neste terreno complexo, a decisão entre adotar um modelo aberto ou investir numa solução de fonte fechada tem implicações significativas para a inovação, o custo e a estratégia de IA a longo prazo.
O Llama 3.1, particularmente a sua formidável versão de parâmetros 405B, surgiu como um forte concorrente contra os principais modelos de código fechado, como o GPT-4o e o Claude 3.5. Esta mudança obrigou as empresas a reavaliarem a sua abordagem à implementação da IA, considerando factores que vão para além da mera métrica de desempenho.
Nesta análise, vamos aprofundar as compensações de custo-benefício entre a Llama 3.1 e os LLMs proprietários, fornecendo aos decisores empresariais uma estrutura abrangente para fazerem escolhas informadas sobre os seus investimentos em IA.
Comparação de custos
Taxas de licenciamento: Modelos proprietários vs. abertos
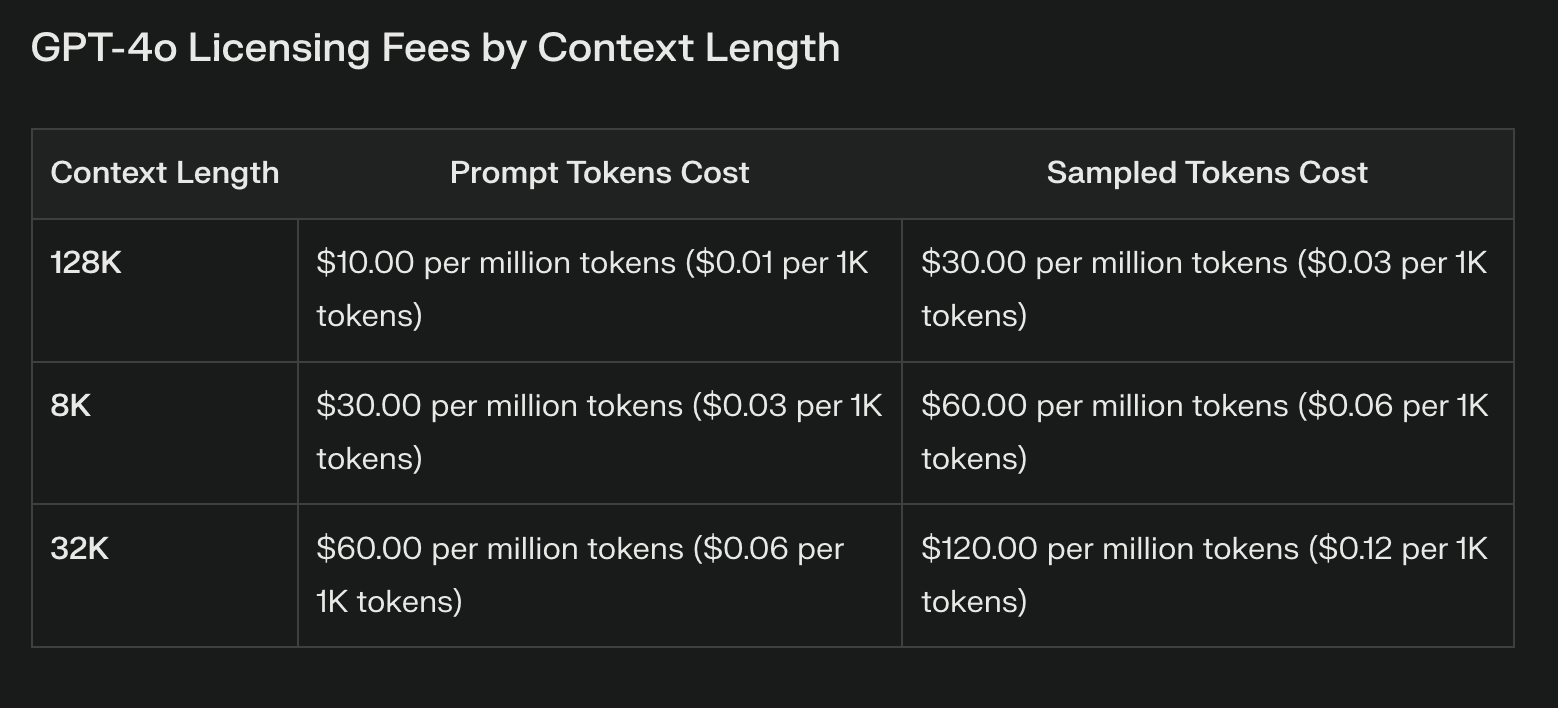
A diferença de custo mais aparente entre a Llama 3.1 e os modelos proprietários está nas taxas de licenciamento. Os LLMs proprietários geralmente vêm com custos recorrentes substanciais, que podem aumentar significativamente com o uso. Estas taxas, embora forneçam acesso a tecnologia de ponta, podem sobrecarregar os orçamentos e limitar a experimentação.
A Llama 3.1, com os seus pesos abertos, elimina totalmente as taxas de licenciamento. Essa economia de custos pode ser substancial, especialmente para empresas que planejam implantações extensas de IA. No entanto, é crucial notar que a ausência de taxas de licenciamento não equivale a custos zero.
Custos de infraestrutura e de implantação
Embora o Llama 3.1 possa poupar no licenciamento, exige recursos computacionais significativos, particularmente para o modelo de parâmetros 405B. As empresas têm de investir numa infraestrutura de hardware robusta, incluindo frequentemente clusters de GPUs topo de gama ou recursos de computação em nuvem. Por exemplo, a execução eficiente do modelo 405B completo pode exigir várias GPUs NVIDIA H100, o que representa uma despesa de capital substancial.
Os modelos proprietários, normalmente acedidos através de APIs, transferem estes custos de infraestrutura para o fornecedor. Isto pode ser vantajoso para as empresas que não dispõem dos recursos ou da experiência necessários para gerir infra-estruturas de IA complexas. No entanto, as chamadas de API de elevado volume também podem acumular rapidamente custos, potencialmente ultrapassando as poupanças iniciais de infraestrutura.

Manutenção e actualizações contínuas
A manutenção de um modelo de peso aberto como o Llama 3.1 exige um investimento contínuo em conhecimentos e recursos. As empresas devem afetar orçamento para:
Actualizações regulares do modelo e afinação
Patches de segurança e gestão de vulnerabilidades
Otimização do desempenho e melhorias de eficiência
Os modelos proprietários incluem frequentemente estas actualizações como parte do seu serviço, reduzindo potencialmente a carga sobre as equipas internas. No entanto, esta conveniência tem o custo de um controlo reduzido sobre o processo de atualização e de potenciais perturbações nos modelos aperfeiçoados.
Comparação de desempenho
Resultados de benchmark em várias tarefas
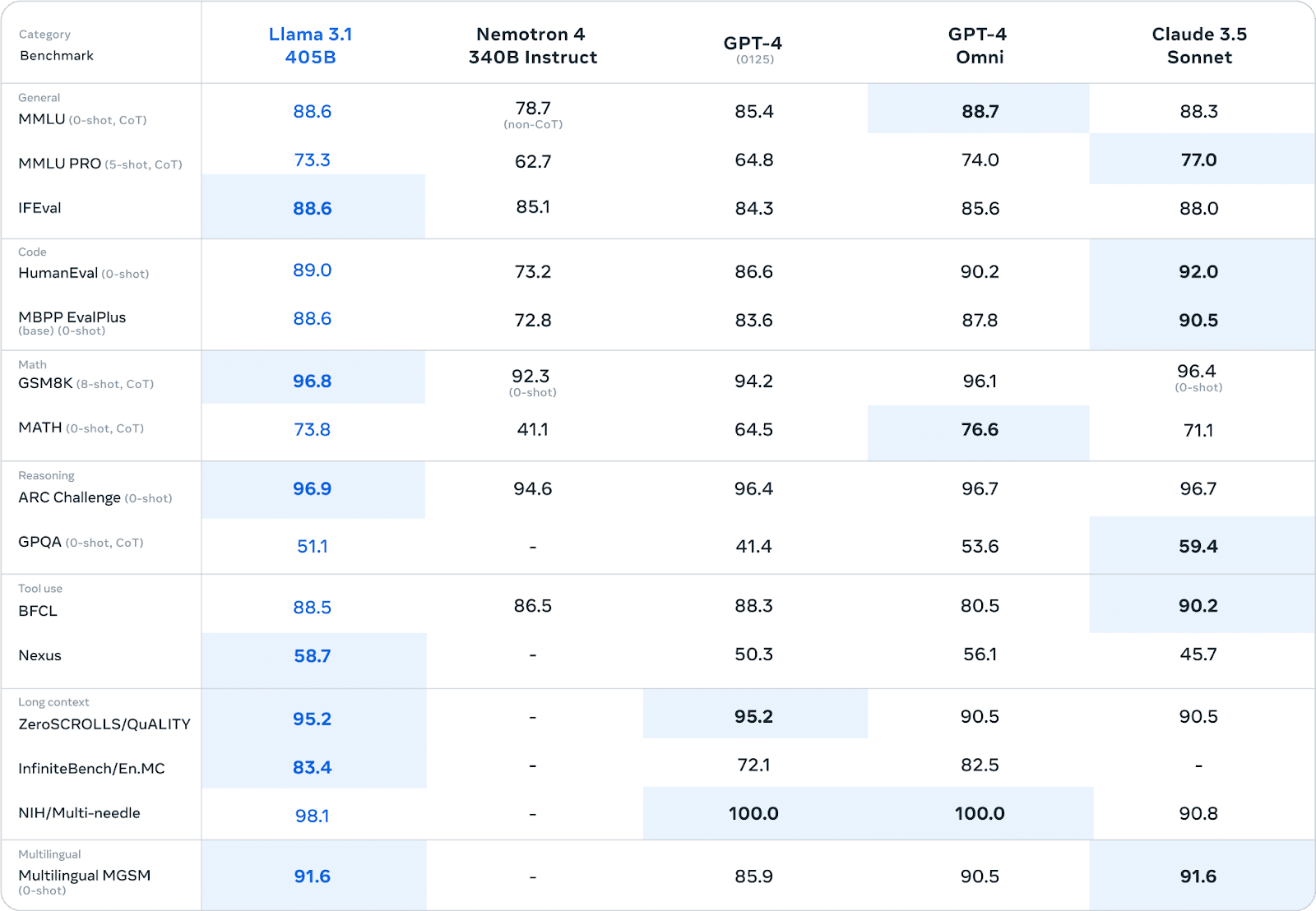
O Llama 3.1 demonstrou um desempenho impressionante em vários testes de referência, muitas vezes rivalizando ou ultrapassando os modelos proprietários. Em extensas avaliações humanas e testes automatizados, a versão de parâmetros 405B demonstrou um desempenho comparável ao dos principais modelos de código fechado em áreas como:
Conhecimentos gerais e raciocínio
Geração e depuração de código
Resolução de problemas matemáticos
Proficiência multilingue
Por exemplo, no benchmark MMLU (Massive Multitask Language Understanding), o Llama 3.1 405B obteve uma pontuação de 86,4%, colocando-o em concorrência direta com modelos como o GPT-4.
Desempenho no mundo real em ambientes empresariais
Embora os benchmarks forneçam informações valiosas, o desempenho no mundo real em ambientes empresariais é o verdadeiro teste das capacidades de um LLM.
Aqui, o quadro torna-se mais matizado:
Vantagem de personalização: As empresas que usam o Llama 3.1 relatam benefícios significativos do ajuste fino do modelo em dados específicos do domínio. Esta personalização resulta frequentemente num desempenho que excede os modelos proprietários disponíveis no mercado para tarefas especializadas.
Geração de dados sintéticos: A capacidade da Llama 3.1 para gerar dados sintéticos revelou-se valiosa para as empresas que procuram aumentar os seus conjuntos de dados de formação ou simular cenários complexos.
Compensações de eficiência: Algumas empresas descobriram que, embora os modelos proprietários possam ter uma ligeira vantagem no desempenho imediato, a capacidade de criar modelos especializados e eficientes através de técnicas como a destilação de modelos com o Llama 3.1 conduz a melhores resultados globais em ambientes de produção.
Considerações sobre a latência: Os modelos proprietários acedidos através da API podem oferecer uma latência mais baixa para consultas individuais, o que pode ser crucial para aplicações em tempo real. No entanto, as empresas que executam a Llama 3.1 em hardware dedicado registam um desempenho mais consistente sob cargas elevadas.
É importante notar que as comparações de desempenho dependem muito de casos de utilização específicos e de pormenores de implementação. As empresas devem efetuar testes minuciosos nos seus ambientes específicos para fazerem avaliações de desempenho precisas.
Considerações a longo prazo
O desenvolvimento futuro dos LLMs é um fator crítico na tomada de decisões. A Llama 3.1 beneficia de uma iteração rápida, impulsionada por uma comunidade de investigação global, que pode conduzir a melhorias revolucionárias. Os modelos proprietários, apoiados por empresas bem financiadas, oferecem actualizações consistentes e a possibilidade de integração de tecnologia proprietária.
O Mercado LLM é suscetível de sofrer perturbações. À medida que os modelos abertos, como o Llama 3.1, se aproximam ou ultrapassam o desempenho das alternativas proprietárias, podemos assistir a uma tendência para a comoditização dos modelos de base e a uma maior especialização. As regulamentações emergentes em matéria de IA também podem afetar a viabilidade de diferentes abordagens de LLM.
O alinhamento com as estratégias mais alargadas de IA da empresa é crucial. A adoção da Llama 3.1 pode promover o desenvolvimento de competências internas em matéria de IA, enquanto o compromisso com modelos proprietários pode conduzir a parcerias estratégicas com gigantes da tecnologia.
Quadro de decisão
Os cenários que favorecem a Llama 3.1 incluem:
Aplicações industriais altamente especializadas que requerem uma personalização extensiva
Empresas com fortes equipas internas de IA capazes de gerir modelos
Empresas que dão prioridade à soberania dos dados e ao controlo total dos processos de IA
Os cenários que favorecem os modelos proprietários incluem:
Necessidade de implementação imediata com uma configuração mínima da infraestrutura
Necessidade de suporte extensivo do fornecedor e SLAs garantidos
Integração com os ecossistemas de IA proprietários existentes
A linha de fundo
A escolha entre a Llama 3.1 e os LLMs proprietários representa um ponto de decisão crítico para as empresas que navegam no cenário da IA. Embora a Llama 3.1 ofereça flexibilidade sem precedentes, potencial de personalização e economia de custos em taxas de licenciamento, ela exige um investimento significativo em infraestrutura e conhecimento. Os modelos proprietários proporcionam facilidade de utilização, suporte robusto e actualizações consistentes, mas à custa de um controlo reduzido e de um potencial bloqueio do fornecedor. Em última análise, a decisão depende das necessidades específicas, dos recursos e da estratégia de IA a longo prazo de uma empresa. Ao ponderar cuidadosamente os factores descritos nesta análise, os decisores podem traçar um percurso que melhor se alinhe com os objectivos e capacidades da sua organização.


