
Compreender as estruturas de preços LLM: Entradas, saídas e janelas de contexto



Para as estratégias de IA das empresas, compreender as estruturas de preços dos modelos de linguagem de grande dimensão (LLM) é crucial para uma gestão eficaz dos custos. Os custos operacionais associados aos LLMs podem aumentar rapidamente sem uma supervisão adequada, conduzindo potencialmente a picos de custos inesperados que podem fazer descarrilar os orçamentos e impedir a adoção generalizada. T
sta publicação do blogue analisa os principais componentes das estruturas de preços dos contratos de LLM, fornecendo informações que o ajudarão a otimizar a utilização dos contratos de LLM e a controlar as despesas.
O preço do LLM gira normalmente em torno de três componentes principais: tokens de entrada, tokens de saída e janelas de contexto. Cada um destes elementos desempenha um papel significativo na determinação do custo global da utilização de LLMs nas suas aplicações. Ao obter uma compreensão completa destes componentes, estará mais bem equipado para tomar decisões informadas sobre a seleção de modelos, padrões de utilização e estratégias de otimização.
Componentes básicos da formação de preços LLM
Tokens de entrada
Os tokens de entrada representam o texto introduzido no LLM para processamento. Isto inclui os seus avisos, instruções e qualquer contexto adicional fornecido ao modelo. O número de tokens de entrada afecta diretamente o custo de cada chamada à API, uma vez que mais tokens requerem mais recursos computacionais para serem processados.
Tokens de saída
Os tokens de saída são o texto gerado pelo LLM em resposta à sua entrada. O preço dos tokens de saída é muitas vezes diferente dos tokens de entrada, reflectindo o esforço computacional adicional necessário para a geração de texto. Gerir a utilização de tokens de saída é crucial para controlar os custos, especialmente em aplicações que geram grandes volumes de texto.
Janelas de contexto
As janelas de contexto referem-se à quantidade de texto anterior que o modelo pode considerar ao gerar respostas. Janelas de contexto maiores permitem uma compreensão mais abrangente, mas têm um custo mais elevado devido ao aumento da utilização de tokens e dos requisitos computacionais.
Tokens de entrada: O que são e como são cobrados
Os tokens de entrada são as unidades fundamentais do texto processado por um LLM. Correspondem tipicamente a partes de palavras, com palavras comuns frequentemente representadas por um único token e palavras menos comuns divididas em múltiplos tokens. Por exemplo, a frase "The quick brown fox" pode ser tokenizada como ["The", "quick", "bro", "wn", "fox"], resultando em 5 tokens de entrada.
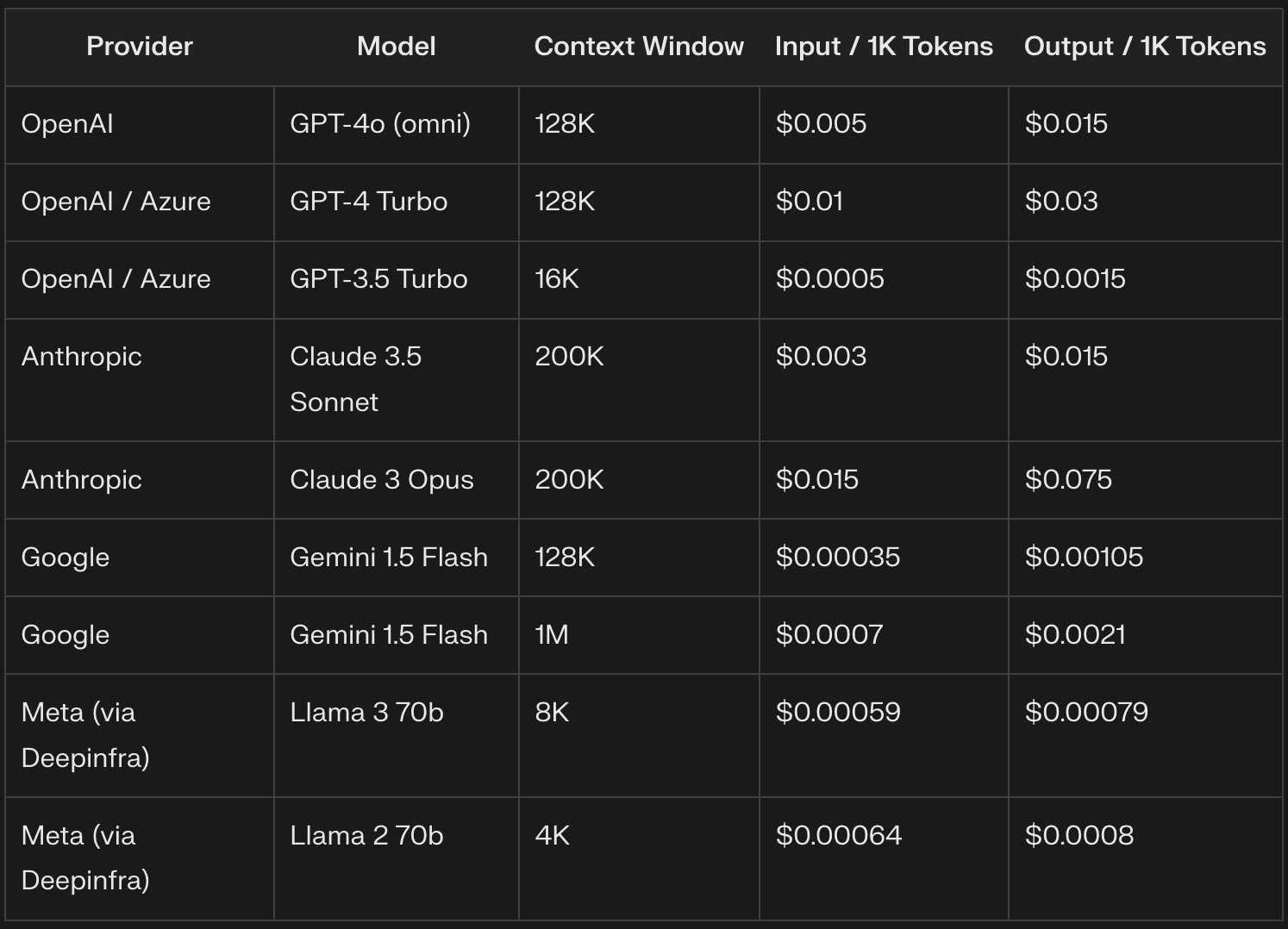
Os fornecedores de LLM cobram frequentemente por tokens de entrada com base numa taxa por mil tokens. Por exemplo, o GPT-4o cobra $5 por 1 milhão de tokens de entrada, o que equivale a $0,005 por 1.000 tokens de entrada. O preço exato pode variar significativamente entre fornecedores e versões de modelos, sendo que os modelos mais avançados geralmente cobram taxas mais elevadas.
Para gerir os custos de LLM de forma eficaz, considere estas estratégias para otimizar a utilização de tokens de entrada:
Elaborar instruções concisas: Elimine as palavras desnecessárias e concentre-se em instruções claras e directas.
Utilizar uma codificação eficiente: Escolha um método de codificação que represente o seu texto com menos tokens.
Implementar modelos de avisos: Desenvolver e reutilizar estruturas de prompt optimizadas para tarefas comuns.
Ao gerir cuidadosamente os seus tokens de entrada, pode reduzir significativamente os custos associados à utilização de LLM, mantendo a qualidade e a eficácia das suas aplicações de IA.
Tokens de saída: Compreender os custos
Os tokens de saída representam o texto gerado pelo LLM em resposta à sua entrada. Semelhante aos tokens de entrada, os tokens de saída são calculados com base no processo de tokenização do modelo. No entanto, o número de tokens de saída pode variar significativamente, dependendo da tarefa e da configuração do modelo. Por exemplo, uma pergunta simples pode gerar uma resposta breve com poucos tokens, enquanto um pedido de explicação detalhada pode resultar em centenas de tokens.
Os fornecedores de LLM costumam cobrar preços diferentes para os tokens de saída e para os tokens de entrada, normalmente a uma taxa mais elevada devido à complexidade computacional da geração de texto. Por exemplo, a OpenAI cobra $15 por 1 milhão de tokens ($0,015 por 1.000 tokens) para o GPT-4o.
Para otimizar a utilização de fichas de saída e controlar os custos:
Defina limites claros de comprimento de saída nos seus prompts ou chamadas de API.
Utilizar técnicas como a "aprendizagem de poucos disparos" para orientar o modelo para respostas mais concisas.
Implementar o pós-processamento para eliminar o conteúdo desnecessário dos resultados do LLM.
Considerar a possibilidade de armazenar em cache informações frequentemente solicitadas para reduzir as chamadas LLM redundantes.
Janelas de contexto: O fator de custo oculto
As janelas de contexto determinam a quantidade de texto anterior que o LLM pode considerar ao gerar uma resposta. Esta caraterística é crucial para manter a coerência nas conversas e permitir que o modelo faça referência a informações anteriores. O tamanho da janela de contexto pode ter um impacto significativo no desempenho do modelo, especialmente em tarefas que exigem memória de longo prazo ou raciocínio complexo.
Janelas de contexto maiores aumentam diretamente o número de tokens de entrada processados pelo modelo, levando a custos mais elevados. Por exemplo:
Um modelo com uma janela de contexto de 4000 tokens a processar uma conversa de 3000 tokens cobrará todos os 3000 tokens.
A mesma conversa com uma janela de contexto de 8.000 tokens pode ser cobrada por 7.000 tokens, incluindo partes anteriores da conversa.
Este escalonamento pode levar a aumentos substanciais de custos, especialmente para aplicações que lidam com diálogos longos ou análise de documentos.
Para otimizar a utilização da janela de contexto:
Implementar o dimensionamento dinâmico do contexto com base nos requisitos da tarefa.
Utilizar técnicas de resumo para condensar informações relevantes de conversas mais longas.
Utilizar abordagens de janela deslizante para processar documentos longos, concentrando-se nas secções mais relevantes.
Considere a utilização de modelos mais pequenos e especializados para tarefas que não requerem um contexto alargado.
Ao gerir cuidadosamente as janelas de contexto, pode encontrar um equilíbrio entre a manutenção de resultados de alta qualidade e o controlo dos custos de LLM. Lembre-se, o objetivo é fornecer contexto suficiente para a tarefa em questão sem aumentar desnecessariamente a utilização de tokens e as despesas associadas.
Tendências futuras em matéria de preços de LLM
À medida que o panorama dos LLM evolui, é possível que se verifiquem alterações nas estruturas de preços:
Preços baseados em tarefas: Os modelos são cobrados com base na complexidade da tarefa e não no número de fichas.
Modelos de subscrição: Acesso a LLMs a uma taxa fixa com limites de utilização ou preços diferenciados.
Preços baseados no desempenho: Custos ligados à qualidade ou exatidão dos resultados e não apenas à quantidade.
Impacto dos avanços tecnológicos nos custos
A investigação e o desenvolvimento em curso no domínio da IA podem conduzir a:
Modelos mais eficientes: Requisitos computacionais reduzidos que conduzem a custos operacionais mais baixos.
Técnicas de compressão melhoradas: Métodos melhorados para reduzir a contagem de tokens de entrada e saída.
Integração da computação periférica: Processamento local de tarefas LLM, reduzindo potencialmente os custos de computação em nuvem.
A linha de fundo
Compreender as estruturas de preços do LLM é essencial para uma gestão eficaz dos custos nas aplicações de IA das empresas. Ao compreender as nuances dos tokens de entrada, tokens de saída e janelas de contexto, as organizações podem tomar decisões informadas sobre a seleção de modelos e padrões de utilização. A implementação de técnicas estratégicas de gerenciamento de custos, como a otimização do uso de tokens e o aproveitamento do cache, pode levar a economias significativas.
À medida que a tecnologia LLM continua a evoluir, manter-se informado sobre as tendências de preços e as estratégias de otimização emergentes será crucial para manter operações de IA rentáveis. Lembre-se, uma gestão de custos de LLM bem sucedida é um processo contínuo que requer monitorização, análise e adaptação contínuas para garantir o máximo valor dos seus investimentos em IA.
Se quiser saber como a sua empresa pode aproveitar melhor as estruturas de preços do LLM, não hesite em contactar-nos!


