
Como criar aplicações LLM poderosas com bases de dados vectoriais + RAG - AI&YOU#55



Estatística/Fato da Semana: 30% das empresas utilizarão bases de dados vectoriais para fundamentar os seus modelos de IA generativa até 2026, contra 2% em 2023. (Gartner)
Os LLM como o GPT-4, o Claude e o Llama 3 surgiram como ferramentas poderosas para as empresas que implementam a PNL, demonstrando capacidades notáveis na compreensão e geração de texto semelhante ao humano. No entanto, têm muitas vezes dificuldades com a perceção do contexto e a precisão, especialmente quando lidam com informações específicas de um domínio.
É por isso que, na edição desta semana da AI&YOU, estamos a explorar a forma como estes desafios são abordados através de três blogues que publicámos:
Combinação de bases de dados vectoriais e RAG para aplicações LLM poderosas
As 10 principais vantagens de utilizar uma base de dados vetorial de fonte aberta
As 5 principais bases de dados de vectores para a sua empresa
Combinação de bases de dados vectoriais e RAG para aplicações LLM poderosas - AI&YOU #55
Para responder a estes desafios, os investigadores e os criadores recorreram a técnicas inovadoras como a Retrieval Augmented Generation (RAG) e bases de dados vectoriais. O RAG melhora os LLM, permitindo-lhes aceder e recuperar informações relevantes de bases de conhecimento externas, enquanto as bases de dados vectoriais fornecem uma solução eficiente e escalável para armazenar e consultar representações de dados de elevada dimensão.
A sinergia entre as bases de dados vectoriais e as RAG
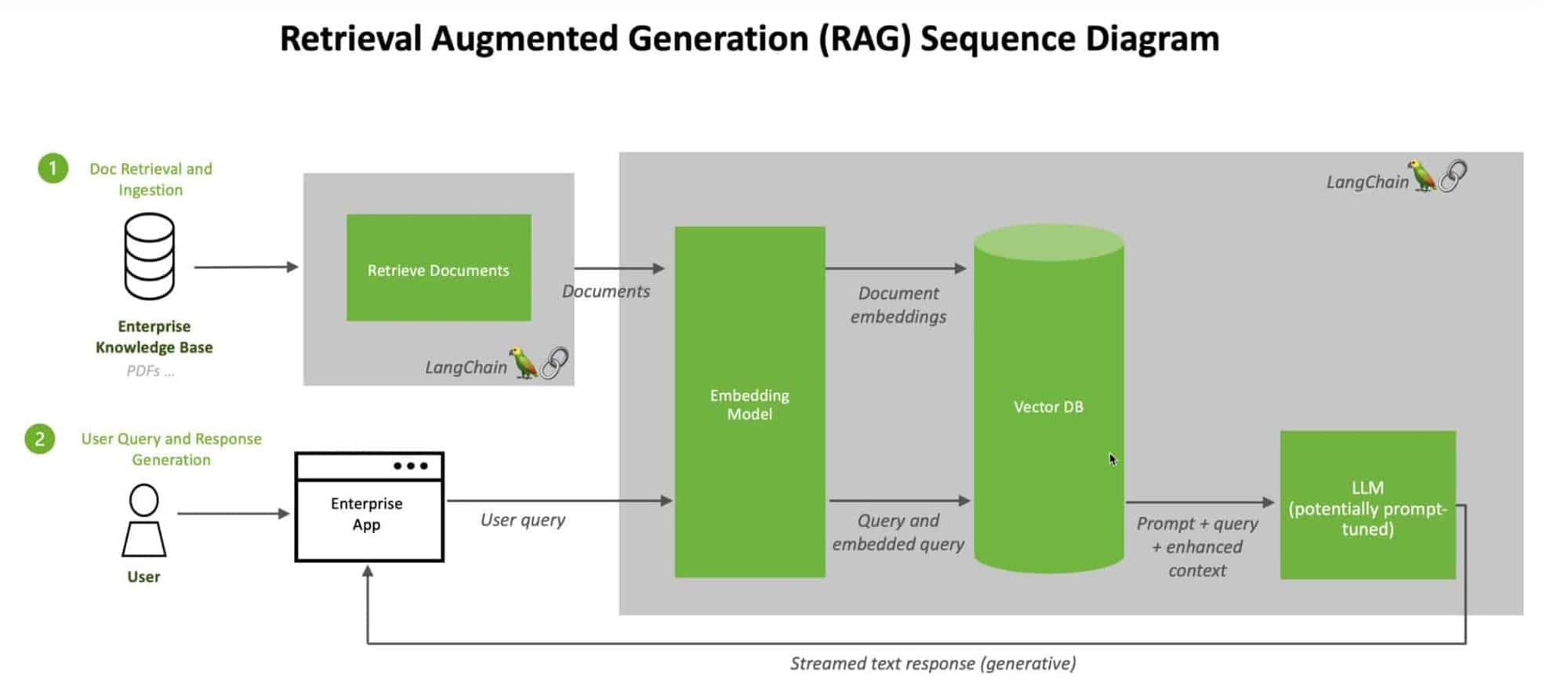
As bases de dados vectoriais e as RAG formam uma sinergia poderosa que melhora as capacidades dos modelos linguísticos de grande dimensão. No centro desta sinergia está o armazenamento e a recuperação eficientes das incorporações de bases de conhecimentos. As bases de dados vectoriais são concebidas para lidar com representações vectoriais de dados de elevada dimensão. Permitem uma pesquisa de semelhanças rápida e precisa, permitindo que os LLM recuperem rapidamente informações relevantes de vastas bases de conhecimentos.
Ao integrar as bases de dados vectoriais com o RAG, podemos criar um pipeline contínuo para aumentar as respostas dos LLM com conhecimento externo. Quando uma LLM recebe uma consulta, o RAG pode pesquisar eficientemente a base de dados vetorial para encontrar as informações mais relevantes com base na incorporação da consulta. Esta informação recuperada é então utilizada para enriquecer o contexto da LLM, permitindo-lhe gerar respostas mais exactas e informativas em tempo real.
Vantagens da combinação de bases de dados vectoriais e RAG
A combinação de bases de dados vectoriais e RAG oferece várias vantagens significativas para aplicações de modelos linguísticos de grande dimensão:
Melhoria da precisão e redução das alucinações
Um dos principais benefícios da combinação de bases de dados vectoriais e RAG é a melhoria significativa da precisão das respostas dos LLM. Ao fornecer aos LLMs acesso a conhecimentos externos relevantes, as RAG ajudam a reduzir a ocorrência de "alucinações" - casos em que o modelo gera informações inconsistentes ou factualmente incorrectas. Com a capacidade de recuperar e incorporar informações específicas do domínio a partir de fontes fiáveis, os LLMs podem produzir resultados mais precisos e fiáveis.
Escalabilidade e desempenho
As bases de dados vectoriais são concebidas para serem escaláveis de forma eficiente, permitindo-lhes tratar grandes volumes de dados de elevada dimensão. Esta escalabilidade é crucial quando se lida com bases de conhecimento extensas que precisam de ser pesquisadas e recuperadas em tempo real. Aproveitando o poder das bases de dados vectoriais, o RAG pode efetuar pesquisas de semelhança rápidas e eficientes, permitindo que os LLM gerem respostas rapidamente sem comprometer a qualidade da informação recuperada.
Permitir aplicações específicas de um domínio
A combinação de bases de dados vectoriais e RAG abre novas possibilidades para a criação de aplicações LLM específicas de um domínio. Através da curadoria de bases de conhecimentos específicas de vários domínios, os LLM podem ser adaptados para fornecer informações exactas e relevantes nesses contextos. Isto permite o desenvolvimento de assistentes de IA especializados, chatbots e sistemas de gestão do conhecimento que podem satisfazer as necessidades específicas de diferentes sectores e casos de utilização.

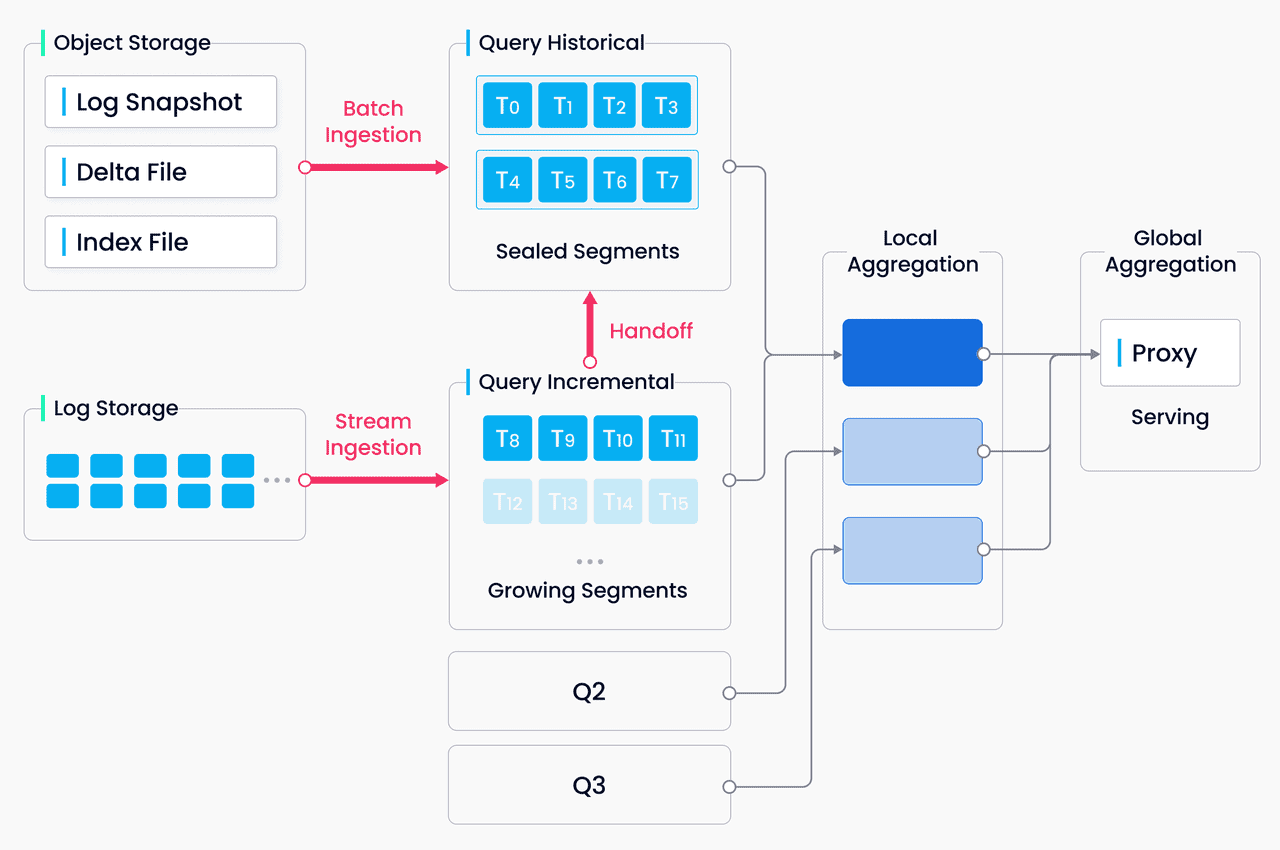
Implementação do RAG com bases de dados vectoriais
Para aproveitar o poder da combinação de bases de dados vectoriais e RAG, é essencial compreender o processo de implementação.
Vamos explorar as principais etapas envolvidas na configuração de um sistema RAG com uma base de dados vetorial:
Indexação e armazenamento de embeddings de bases de conhecimento: A primeira etapa consiste em converter os dados de texto da base de conhecimentos em vectores de elevada dimensão utilizando modelos de incorporação como o BERT e, em seguida, indexar e armazenar estas incorporações na base de dados de vectores para uma pesquisa e recuperação eficientes de semelhanças.
Consulta da base de dados de vectores para obter informações relevantes: Quando um LLM recebe uma consulta, o sistema RAG transforma a consulta numa representação vetorial utilizando o mesmo modelo de incorporação, e a base de dados vetorial efectua uma pesquisa de similaridade para recuperar as incorporações de bases de conhecimento mais relevantes com base numa métrica de similaridade escolhida.
Integrar a informação recuperada nas respostas do LLM: A informação relevante recuperada da base de dados vetorial é integrada no processo de geração de respostas do LLM, quer concatenando-a com a consulta original, quer utilizando técnicas como mecanismos de atenção, permitindo ao LLM gerar respostas mais precisas e informativas com base no contexto aumentado.
Escolher a base de dados vetorial certa para a sua aplicação: A seleção da base de dados vetorial adequada é crucial, tendo em conta factores como a escalabilidade, o desempenho, a facilidade de utilização e a compatibilidade com o conjunto de tecnologias existente, bem como os seus requisitos específicos, como o tamanho da base de conhecimentos, o volume de consultas e a latência de resposta pretendida.
Melhores práticas e considerações
Para garantir o sucesso da implementação do RAG com bases de dados vectoriais, há várias práticas recomendadas e considerações a ter em conta.
Otimização da incorporação de bases de dados de conhecimento para recuperação:
A qualidade das incorporações da base de conhecimentos é crucial, exigindo a experimentação de diferentes modelos e técnicas de incorporação, o aperfeiçoamento em dados específicos do domínio e a atualização e expansão regulares das incorporações à medida que novas informações ficam disponíveis para manter a relevância e a precisão.
Equilíbrio entre a velocidade e a precisão da recuperação:
Há um compromisso entre a velocidade de recuperação e a precisão, o que exige técnicas como a pesquisa aproximada do vizinho mais próximo para acelerar a recuperação, mantendo uma precisão aceitável, bem como o armazenamento em cache dos embeddings frequentemente acedidos e a implementação de estratégias de equilíbrio de carga para otimizar o desempenho.
Garantir a segurança e a privacidade dos dados:
É essencial estabelecer um armazenamento de dados seguro, controlos de acesso e técnicas de encriptação, como a encriptação homomórfica, para impedir o acesso não autorizado e proteger os dados sensíveis nas incorporações da base de conhecimentos, respeitando os regulamentos de proteção de dados relevantes.
Acompanhamento e manutenção do sistema:
A monitorização contínua de métricas como a latência das consultas, a precisão das recuperações e a utilização dos recursos, a implementação de mecanismos automatizados de monitorização e alerta e o estabelecimento de um calendário de manutenção sólido, incluindo cópias de segurança, actualizações e afinação do desempenho, são vitais para garantir o desempenho e a fiabilidade a longo prazo do sistema RAG.
Aproveitar o poder das bases de dados vectoriais e do RAG na sua empresa
À medida que a IA continua a moldar o nosso futuro, é crucial para a sua empresa manter-se na vanguarda destes avanços tecnológicos. Ao explorar e implementar técnicas de ponta, como bases de dados vectoriais e RAG, pode desbloquear todo o potencial de grandes modelos linguísticos e criar sistemas de IA mais inteligentes, adaptáveis e que proporcionam um maior ROI.
As 10 principais vantagens de utilizar uma base de dados vetorial de fonte aberta
Entre as soluções de bases de dados vectoriais, as bases de dados vectoriais de código aberto oferecem uma combinação atraente de flexibilidade, escalabilidade e rentabilidade. Ao aproveitar o poder coletivo da comunidade de código aberto, estas bases de dados vectoriais especializadas estão a redefinir a forma como as organizações abordam a gestão e análise de dados.
Esta semana, o nosso blogue também explorou as 10 principais vantagens de utilizar uma base de dados vetorial de código aberto:
A escalabilidade e a rentabilidade permitem um crescimento contínuo sem custos elevados, eliminando a dependência do fornecedor e proporcionando uma solução económica.
A flexibilidade e a personalização permitem adaptar a base de dados a necessidades específicas, modificar a funcionalidade e integrar-se em sistemas existentes.
O tratamento eficiente de dados não estruturados tira partido de técnicas como a PNL e a incorporação de vectores para um armazenamento, pesquisa e análise eficazes.
A poderosa pesquisa de semelhança de vectores facilita a recuperação precisa com base na semelhança semântica, permitindo aplicações como recomendações personalizadas e descoberta inteligente de conteúdos.
A integração com ecossistemas de código aberto garante a interoperabilidade com ferramentas e estruturas complementares, aumentando a produtividade e promovendo a colaboração.
As medidas robustas de segurança e privacidade dos dados dão prioridade à transparência, encriptação, controlo de acesso e cumprimento das normas de conformidade.
A gestão de dados eficiente e de elevado desempenho proporciona uma execução de consultas extremamente rápida e versatilidade para diversas cargas de trabalho.
A compatibilidade com a análise avançada e a aprendizagem automática permite uma integração perfeita com técnicas e estruturas de ponta.
A arquitetura escalável e preparada para o futuro permite um crescimento e adaptação contínuos às tecnologias emergentes e à evolução dos requisitos de dados.
A inovação e o apoio orientados para a comunidade promovem a melhoria contínua, a partilha de conhecimentos e recursos inestimáveis para tirar partido destas ferramentas poderosas.
As 5 principais bases de dados de vectores para a sua empresa
Para além das principais vantagens, esta semana também publicámos um blogue sobre as 5 principais bases de dados vectoriais para a sua empresa:
1. Croma
O Chroma foi concebido para uma integração perfeita com modelos e estruturas de aprendizagem automática, simplificando o processo de criação de aplicações baseadas em IA. Oferece armazenamento vetorial eficiente, recuperação, pesquisa por semelhança, indexação em tempo real e armazenamento de metadados. Suporta várias métricas de distância e algoritmos de indexação para um desempenho ótimo em casos de utilização como a pesquisa semântica, recomendações e deteção de anomalias.

2. Pinha
A Pinecone é uma base de dados vetorial sem servidor, totalmente gerida, que dá prioridade ao elevado desempenho e à facilidade de utilização. Combina algoritmos avançados de pesquisa vetorial com filtragem e infraestrutura distribuída para uma pesquisa vetorial rápida e fiável em escala. Integra-se perfeitamente com estruturas de aprendizagem automática e fontes de dados para aplicações como pesquisa semântica, recomendações, deteção de anomalias e resposta a perguntas.
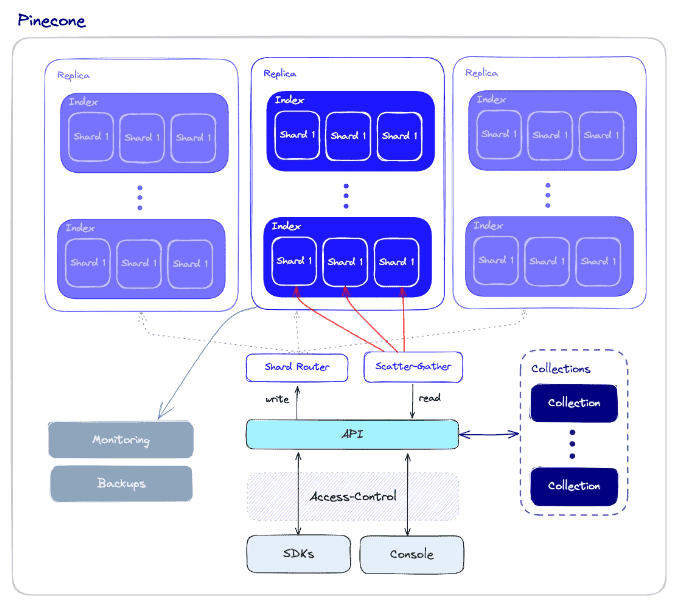
3. Qdrant
O Qdrant é um motor de pesquisa de similaridade de vectores de código aberto, de alta velocidade e escalável, escrito em Rust. Ele fornece uma API conveniente para armazenar, pesquisar e gerenciar vetores com metadados, permitindo aplicativos prontos para produção para correspondência, pesquisa, recomendação e muito mais. Os recursos incluem atualizações em tempo real, filtragem avançada, índices distribuídos e opções de implantação nativas da nuvem.
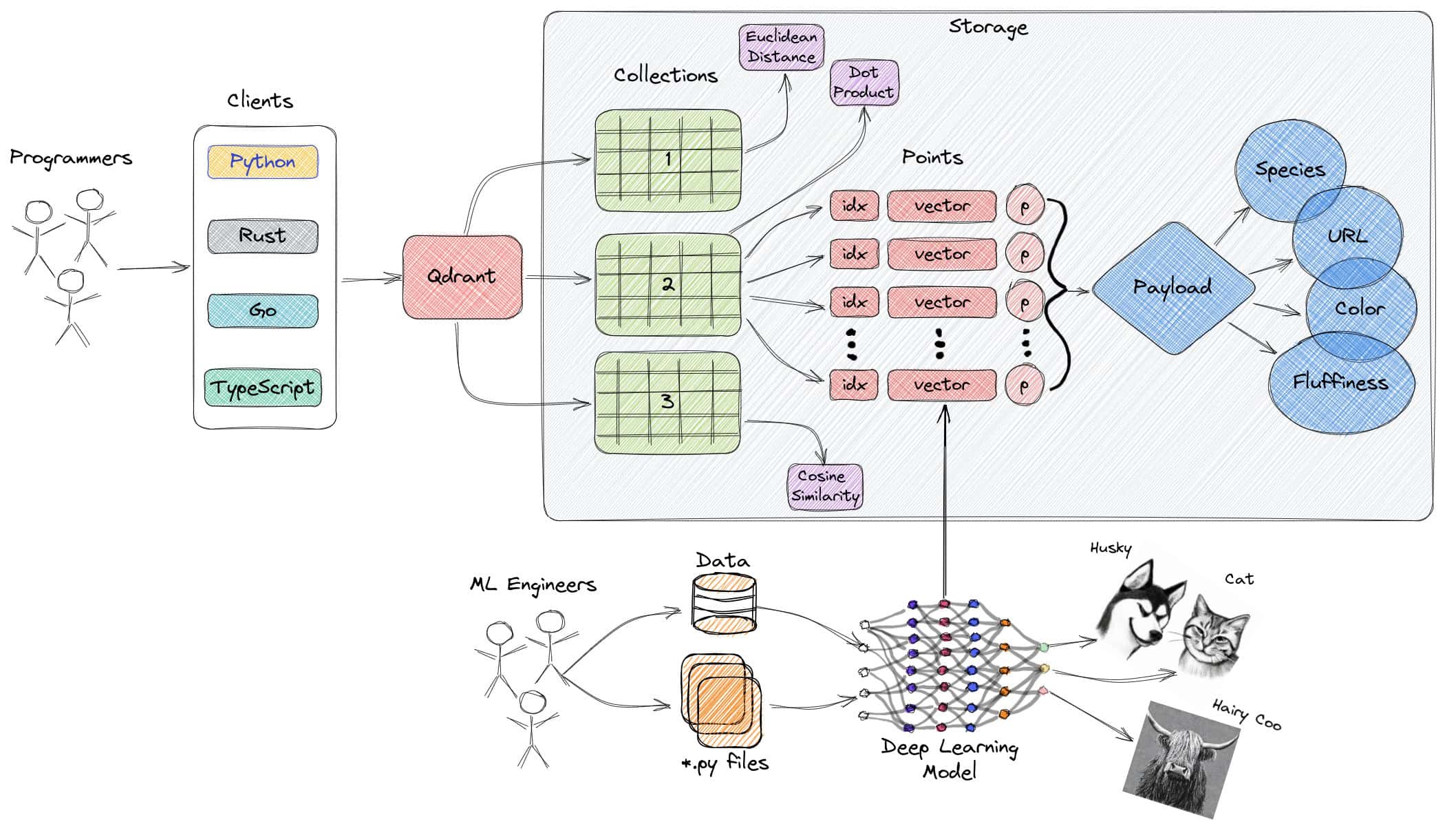
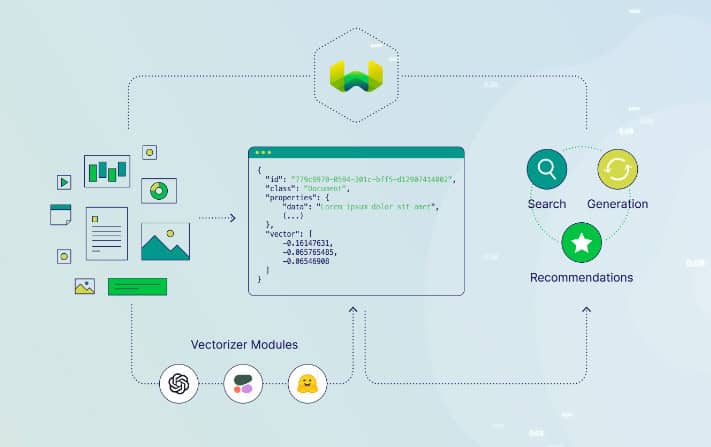
4. Weaviate
O Weaviate é uma base de dados vetorial de código aberto que dá prioridade à velocidade, à escalabilidade e à facilidade de utilização. Permite armazenar tanto objectos como vectores, combinando a pesquisa de vectores com filtragem estruturada. Oferece uma API baseada em GraphQL, operações CRUD, escalonamento horizontal e implantação nativa na nuvem. Incorpora módulos para tarefas de PNL, configuração automática de esquemas e vectorização personalizada.
5. Milvus
O Milvus é uma base de dados vetorial de código aberto concebida para gestão de incorporação, pesquisa de semelhanças e aplicações de IA escaláveis. Oferece suporte de computação heterogénea, fiabilidade de armazenamento, métricas abrangentes e uma arquitetura nativa da nuvem. Fornece uma API flexível para índices, métricas de distância e tipos de consulta, e pode ser dimensionada para milhares de milhões de vectores com plug-ins personalizados.
Escolher a base de dados vetorial certa para a sua empresa
Quer esteja a construir um motor de pesquisa semântico, um sistema de recomendação ou qualquer outra aplicação alimentada por IA, as bases de dados vectoriais fornecem a base para desbloquear todo o potencial dos modelos de aprendizagem automática. Ao permitir a pesquisa rápida de semelhanças, a filtragem avançada e a integração perfeita com estruturas populares, estas bases de dados permitem que os programadores se concentrem na criação de soluções inovadoras sem se preocuparem com as complexidades subjacentes à gestão de dados vectoriais.
Para obter ainda mais conteúdos sobre IA empresarial, incluindo infográficos, estatísticas, guias de instruções, artigos e vídeos, siga o Skim AI em LinkedIn
É um fundador, diretor executivo, capitalista de risco ou investidor que procura serviços especializados de consultoria ou diligência devida em matéria de IA? Obtenha a orientação de que necessita para tomar decisões informadas sobre a estratégia de produtos de IA da sua empresa ou oportunidades de investimento.
Construímos Soluções de IA para empresas apoiadas por capital de risco e capital privado nos seguintes sectores: Tecnologia médica, agregação de notícias/conteúdo, produção de filmes e fotografias, tecnologia educacional, tecnologia jurídica, fintech e criptomoeda.


