
10 estratégias comprovadas para reduzir os custos do seu LLM - AI&YOU #65



Estatísticas da semana: A utilização de LLMs mais pequenos, como o GPT-J, numa cascata pode reduzir o custo global em 80% e melhorar a precisão em 1,5% em comparação com o GPT-4. (Dataiku)
À medida que as organizações dependem cada vez mais de grandes modelos de linguagem (LLMs) para várias aplicações, os custos operacionais associados à sua implementação e manutenção podem rapidamente ficar fora de controlo sem uma supervisão adequada e estratégias de otimização.
A Meta também lançou o Llama 3.1, que tem sido muito falado ultimamente por ser o LLM de código aberto mais avançado até à data.
Na edição desta semana de AI&YOU, exploramos as ideias de três blogues que publicámos sobre estes temas:
10 Estratégias comprovadas para reduzir os custos do seu LLM
Compreender as estruturas de preços LLM: Entradas, saídas e janelas de contexto
Meta's Llama 3.1: Ultrapassar os limites da IA de código aberto
10 estratégias comprovadas para reduzir os custos do seu LLM - AI&YOU #65
Esta publicação do blogue explora dez estratégias comprovadas para ajudar a sua empresa a gerir eficazmente os custos de LLM, garantindo que pode aproveitar todo o potencial destes modelos, mantendo a eficiência de custos e o controlo das despesas.
1. Seleção inteligente de modelos
Optimize os seus custos de LLM fazendo corresponder cuidadosamente a complexidade do modelo aos requisitos da tarefa. Nem todas as aplicações precisam do modelo mais recente e maior. Para tarefas mais simples, como classificação básica ou P&R simples, considere usar modelos pré-treinados menores e mais eficientes. Essa abordagem pode levar a economias substanciais sem comprometer o desempenho.
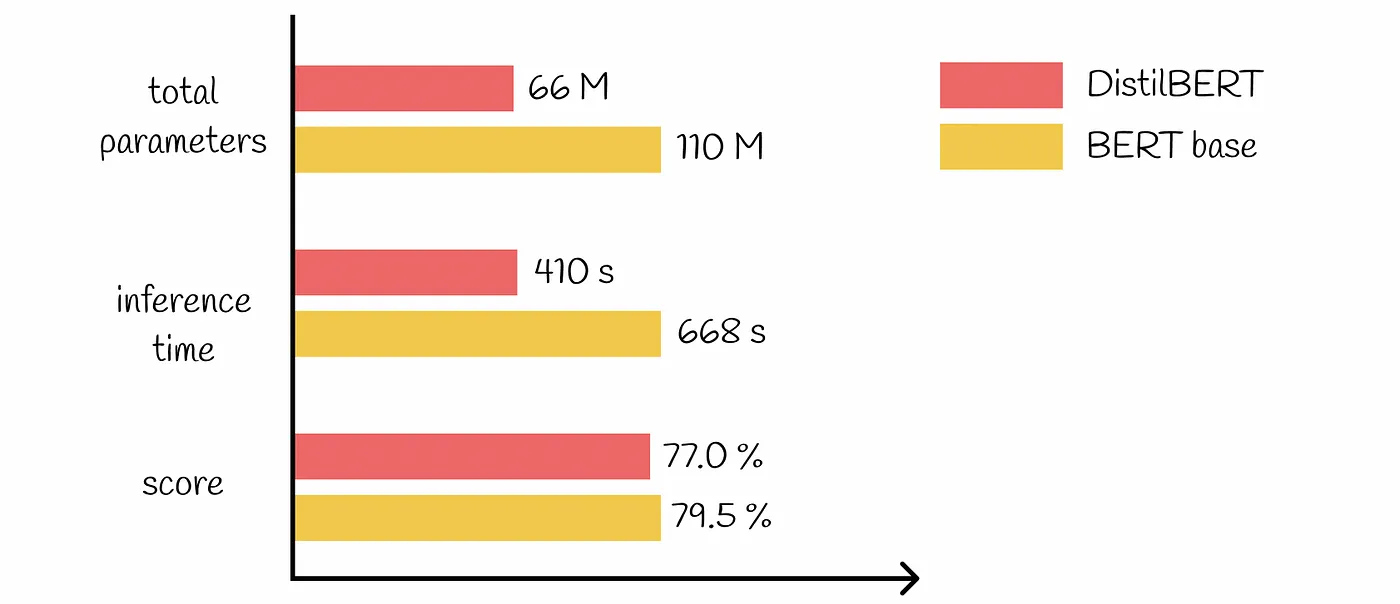
Por exemplo, a utilização do DistilBERT para a análise de sentimentos em vez do BERT-Large pode reduzir significativamente a sobrecarga computacional e as despesas associadas, mantendo uma elevada precisão para a tarefa específica em causa.
2. Implementar um controlo robusto da utilização
Obter uma visão global do seu Utilização do LLM através da implementação de mecanismos de rastreio a vários níveis. Monitorize a utilização de tokens, os tempos de resposta e as chamadas de modelo ao nível da conversação, do utilizador e da empresa. Aproveite os painéis de análise incorporados dos fornecedores de LLM ou implemente soluções de rastreamento personalizadas integradas à sua infraestrutura.
Este conhecimento granular permite-lhe identificar ineficiências, tais como departamentos que utilizam excessivamente modelos dispendiosos para tarefas simples ou padrões de consultas redundantes. Ao analisar esses dados, é possível descobrir estratégias valiosas de redução de custos e otimizar o consumo geral de LLM.
3. Otimizar o Prompt Engineering
Aperfeiçoe suas técnicas de engenharia de prompts para reduzir significativamente o uso de tokens e melhorar a eficiência do LLM. Crie instruções claras e concisas nos seus prompts, implemente o tratamento de erros para resolver problemas comuns sem consultas adicionais e utilize modelos de prompts comprovados para tarefas específicas. Estruture os seus prompts de forma eficiente, evitando contextos desnecessários, utilizando técnicas de formatação como marcadores e tirando partido das funções incorporadas para controlar o comprimento da saída.
Estas optimizações podem reduzir substancialmente o consumo de tokens e os custos associados, mantendo ou mesmo melhorando a qualidade dos seus resultados LLM.
4. Aproveitar o ajuste fino para a especialização
Utilize o poder do ajuste fino para criar modelos mais pequenos e mais eficientes, adaptados às suas necessidades específicas. Embora exija um investimento inicial, esta abordagem pode levar a poupanças significativas a longo prazo. Os modelos ajustados geralmente requerem menos tokens para obter resultados iguais ou melhores, reduzindo os custos de inferência e a necessidade de novas tentativas ou correcções.
Comece com um modelo pré-treinado mais pequeno, utilize dados específicos do domínio de alta qualidade para afinação e avalie regularmente o desempenho e a relação custo-eficácia. Esta otimização contínua garante que os seus modelos continuam a fornecer valor, mantendo os custos operacionais sob controlo.
5. Explorar opções gratuitas e de baixo custo
Aproveite as opções de LLM gratuitas ou de baixo custo, especialmente durante as fases de desenvolvimento e teste, para reduzir significativamente as despesas sem comprometer a qualidade. Estas alternativas são particularmente valiosas para a criação de protótipos, formação de programadores e serviços não críticos ou internos.
No entanto, avalie cuidadosamente as contrapartidas, considerando a privacidade dos dados, as implicações de segurança e as potenciais limitações nas capacidades ou na personalização. Avalie a escalabilidade a longo prazo e as trajectórias de migração para garantir que as suas medidas de redução de custos se alinham com os planos de crescimento futuros e não se tornam obstáculos no futuro.
6. Otimizar a gestão da janela de contexto
Gerir eficazmente as janelas de contexto para controlar os custos e manter a qualidade dos resultados. Implementar o dimensionamento dinâmico do contexto com base na complexidade da tarefa, utilizar técnicas de resumo para condensar informações relevantes e utilizar abordagens de janela deslizante para documentos ou conversas longas. Analisar regularmente a relação entre o tamanho do contexto e a qualidade do resultado, ajustando as janelas com base nos requisitos específicos da tarefa.
Considere uma abordagem em camadas, usando contextos maiores apenas quando necessário. Esta gestão estratégica das janelas de contexto pode reduzir significativamente a utilização de tokens e os custos associados, sem sacrificar as capacidades de compreensão das suas aplicações LLM.
7. Implementar sistemas multiagentes
Melhorar a eficiência e a relação custo-eficácia através da implementação de arquitecturas LLM multi-agente. Esta abordagem envolve a colaboração de vários agentes de IA para resolver problemas complexos, permitindo uma atribuição optimizada de recursos e uma menor dependência de modelos dispendiosos e de grande escala.
Os sistemas multiagentes permitem a implementação de modelos direcionados, melhorando a eficiência geral do sistema e os tempos de resposta, reduzindo a utilização de tokens. Para manter a relação custo-eficácia, implemente mecanismos de depuração robustos, incluindo o registo de comunicações entre agentes e a análise de padrões de utilização de tokens.
Ao otimizar a divisão do trabalho entre agentes, pode minimizar o consumo desnecessário de tokens e maximizar os benefícios do tratamento distribuído de tarefas.
8. Utilizar ferramentas de formatação de saída
Utilizar ferramentas de formatação de saída para garantir uma utilização eficiente dos tokens e minimizar as necessidades de processamento adicionais. Implemente saídas de funções forçadas para especificar formatos de resposta exactos, reduzindo a variabilidade e o desperdício de tokens. Essa abordagem diminui a probabilidade de saídas malformadas e a necessidade de chamadas de API de esclarecimento.
Considere a utilização de resultados JSON pela sua representação compacta de dados estruturados, fácil análise e utilização reduzida de tokens em comparação com respostas em linguagem natural. Ao simplificar os seus fluxos de trabalho LLM com estas ferramentas de formatação, pode otimizar significativamente a utilização de tokens e reduzir os custos operacionais, mantendo resultados de elevada qualidade.
9. Integrar ferramentas não-LLM
Complemente as suas aplicações LLM com ferramentas não-LLM para otimizar os custos e a eficiência. Incorpore scripts Python ou abordagens de programação tradicionais para tarefas que não requerem todas as capacidades de um LLM, como processamento de dados simples ou tomada de decisões baseadas em regras.
Ao conceber fluxos de trabalho, equilibrar cuidadosamente a LLM e as ferramentas convencionais com base na complexidade da tarefa, na precisão necessária e na potencial poupança de custos. Realizar análises custo-benefício completas, considerando factores como custos de desenvolvimento, tempo de processamento, precisão e escalabilidade a longo prazo. Esta abordagem híbrida produz frequentemente os melhores resultados em termos de desempenho e eficiência de custos.
10. Auditoria e otimização regulares
Implementar um sistema robusto de auditoria e otimização regulares para garantir uma gestão contínua dos custos de LLM. Monitorize e analise consistentemente a utilização do LLM para identificar ineficiências, tais como consultas redundantes ou janelas de contexto excessivas. Utilize ferramentas de rastreio e análise para aperfeiçoar as suas estratégias de LLM e eliminar o consumo desnecessário de tokens.
Promova uma cultura de consciência de custos na sua organização, incentivando as equipas a considerar ativamente as implicações de custos da sua utilização do LLM e a procurar oportunidades de otimização. Ao tornar a eficiência de custos uma responsabilidade partilhada, pode maximizar o valor dos seus investimentos em IA, mantendo as despesas sob controlo a longo prazo.
Compreender as estruturas de preços LLM: Entradas, saídas e janelas de contexto
Para as estratégias de IA das empresas, compreender as estruturas de preços dos LLM é crucial para uma gestão eficaz dos custos. Os custos operacionais associados aos LLMs podem aumentar rapidamente sem uma supervisão adequada, levando potencialmente a picos de custos inesperados que podem fazer descarrilar os orçamentos e impedir a adoção generalizada.
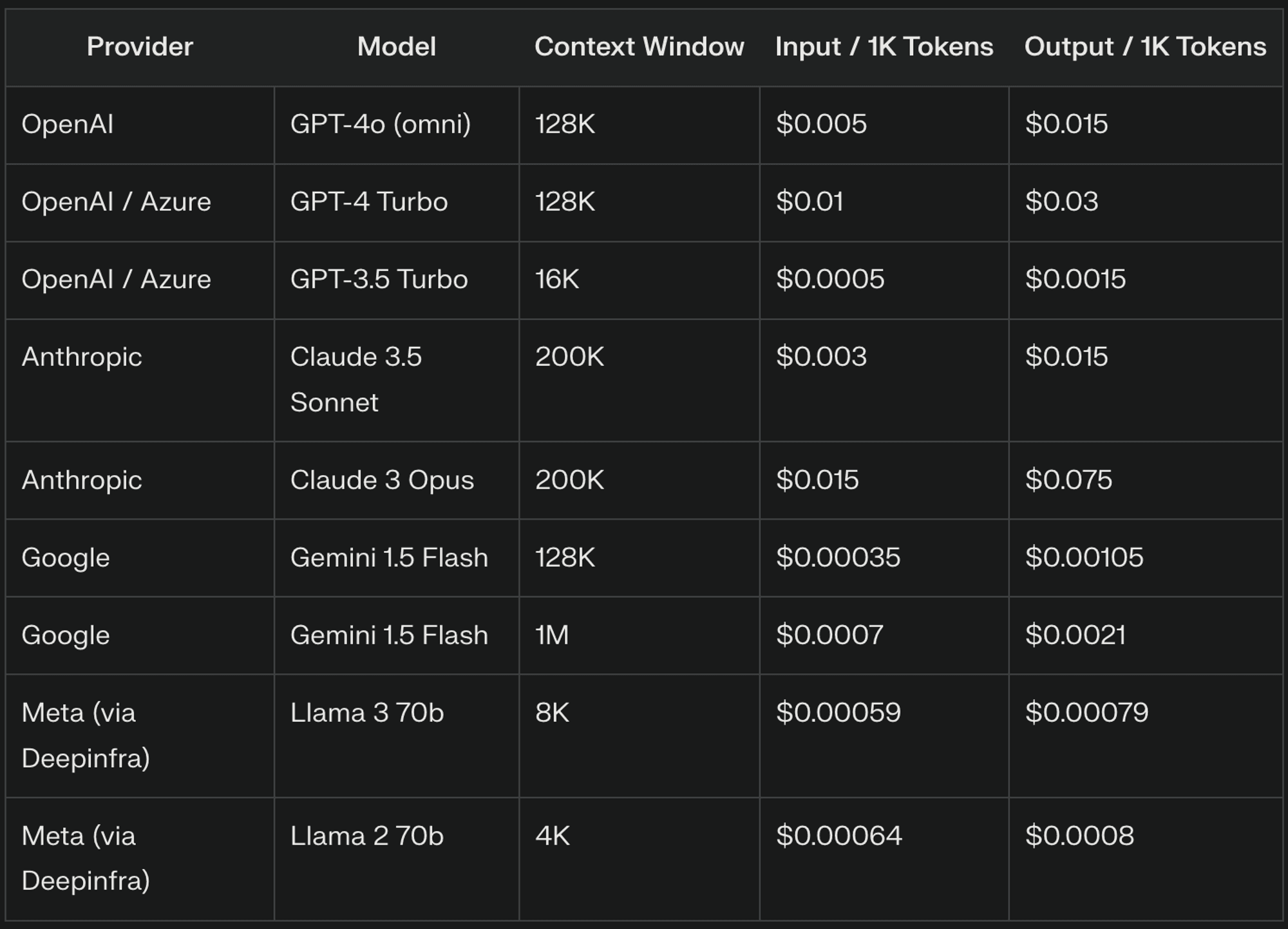
O preço do LLM gira normalmente em torno de três componentes principais: tokens de entrada, tokens de saída e janelas de contexto. Cada um destes elementos desempenha um papel significativo na determinação do custo global da utilização de LLMs nas suas aplicações
Tokens de entrada: O que são e como são cobrados
Os tokens de entrada são as unidades fundamentais do texto processado pelos LLMs, correspondendo normalmente a partes de palavras. Por exemplo, "The quick brown fox" pode ser tokenizado como ["The", "quick", "bro", "wn", "fox"], resultando em 5 tokens de entrada. Os fornecedores de LLM cobram geralmente os tokens de entrada com base numa taxa por mil tokens, variando o preço significativamente entre fornecedores e versões de modelos.
Para otimizar a utilização de tokens de entrada e reduzir os custos, considere estas estratégias:
Elaborar avisos concisos: Concentre-se em instruções claras e diretas.
Utilizar uma codificação eficiente: Escolha métodos que representem o texto com menos tokens.
Implementar modelos de avisos: Desenvolver estruturas optimizadas para tarefas comuns.
Tirar partido das técnicas de compressão: Reduzir o tamanho da entrada sem perder informação crítica.
Tokens de saída: Compreender os custos
Os tokens de saída representam o texto gerado pelo LLM em resposta à sua entrada. O número de tokens de saída pode variar significativamente, dependendo da tarefa e da configuração do modelo. Os fornecedores de LLM costumam cobrar mais caro pelos tokens de saída do que pelos tokens de entrada, devido à complexidade computacional da geração de texto.
Para otimizar a utilização de fichas de saída e controlar os custos:
Defina limites claros de comprimento de saída nos seus prompts ou chamadas de API.
Utilizar a "aprendizagem de poucos disparos" para orientar o modelo para respostas concisas.
Implementar o pós-processamento para eliminar conteúdos desnecessários.
Considere a possibilidade de armazenar em cache as informações frequentemente solicitadas.
Utilizar ferramentas de formatação de saída para garantir uma utilização eficiente dos tokens.
Janelas de contexto: O fator de custo oculto
As janelas de contexto determinam a quantidade de texto anterior que o LLM considera ao gerar uma resposta, crucial para manter a coerência e fazer referência a informações anteriores. Janelas de contexto maiores aumentam o número de tokens de entrada processados, levando a custos mais altos. Por exemplo, uma janela de contexto de 8.000 tokens pode cobrar por 7.000 tokens numa conversa, enquanto uma janela de 4.000 tokens pode cobrar apenas por 3.000.
Para otimizar a utilização da janela de contexto:
Implementar o dimensionamento dinâmico do contexto com base nos requisitos da tarefa.
Utilizar técnicas de resumo para condensar informações relevantes.
Utilizar abordagens de janela deslizante para documentos longos.
Considere modelos mais pequenos e especializados para tarefas com necessidades de contexto limitadas.
Analisar regularmente a relação entre a dimensão do contexto e a qualidade dos resultados.
Ao gerir cuidadosamente estes componentes das estruturas de preços do LLM, as empresas podem reduzir os custos operacionais, mantendo a qualidade das suas aplicações de IA.
A linha de fundo
Compreender as estruturas de preços do LLM é essencial para uma gestão eficaz dos custos nas aplicações de IA das empresas. Ao compreender as nuances dos tokens de entrada, tokens de saída e janelas de contexto, as organizações podem tomar decisões informadas sobre a seleção de modelos e padrões de utilização. A implementação de técnicas estratégicas de gerenciamento de custos, como a otimização do uso de tokens e o aproveitamento do cache, pode levar a economias significativas.
Meta's Llama 3.1: Ultrapassar os limites da IA de código aberto
Recentemente, a Meta anunciou Lhama 3.1O software de inteligência artificial da Microsoft, o seu modelo de linguagem de grande porte de código aberto mais avançado até à data. Este lançamento representa um marco significativo na democratização da tecnologia de IA, potencialmente colmatando o fosso entre modelos de código aberto e modelos proprietários.
O Llama 3.1 baseia-se nos seus antecessores com vários avanços importantes:
Aumento do tamanho do modelo: A introdução do modelo de parâmetros 405B alarga os limites do que é possível na IA de código aberto.
Comprimento do contexto alargado: De 4K tokens no Llama 2 para 128K no Llama 3.1, permitindo uma compreensão mais complexa e matizada de textos mais longos.
Capacidades multilingues: O suporte linguístico alargado permite aplicações mais diversificadas em diferentes regiões e casos de utilização.
Melhoria do raciocínio e das tarefas especializadas: Desempenho melhorado em áreas como o raciocínio matemático e a geração de código.
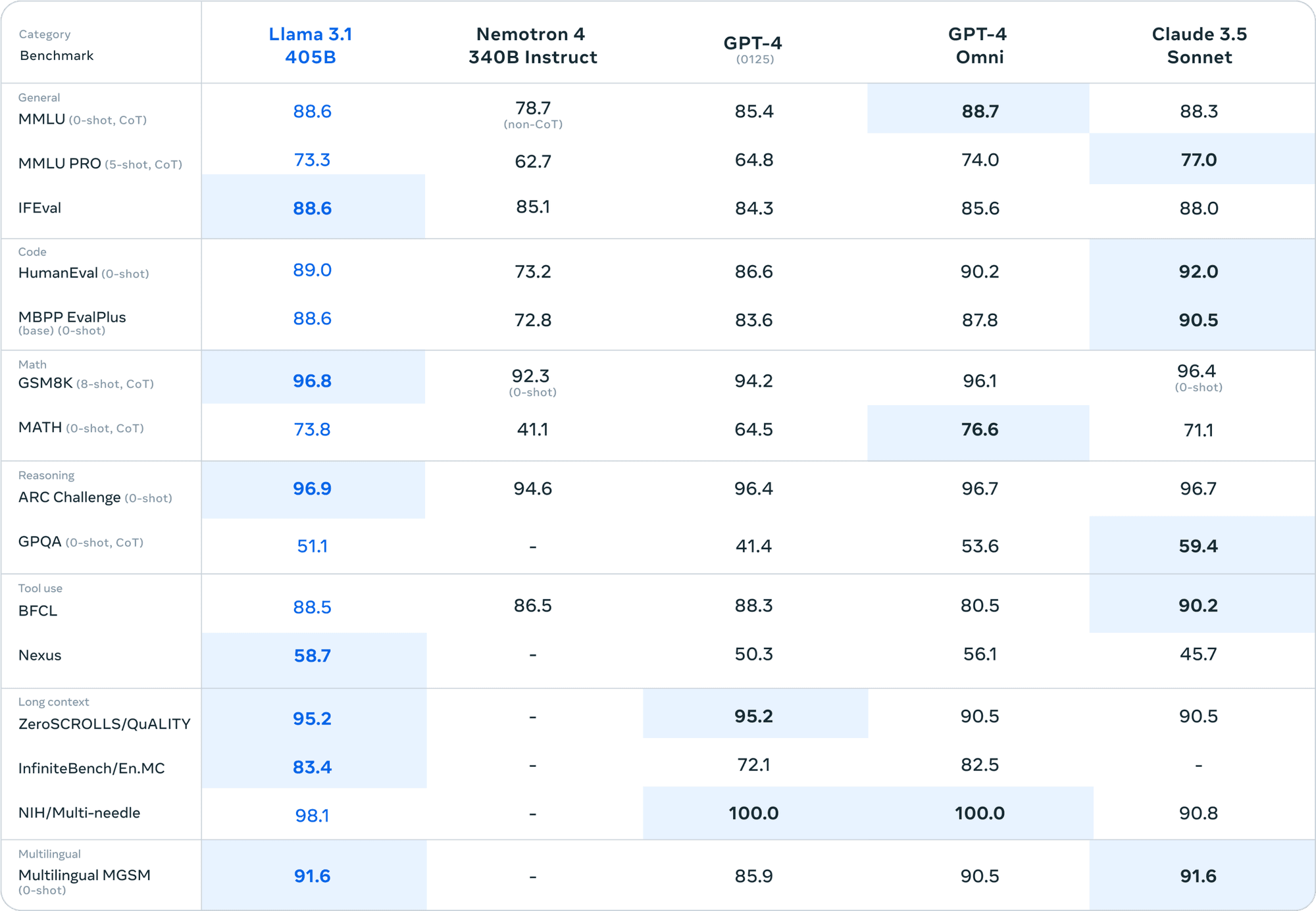
Quando comparado com modelos de código fechado, como o GPT-4 e o Claude 3.5 Sonnet, o Llama 3.1 405B mantém-se firme em vários benchmarks. Este nível de desempenho num modelo de código aberto não tem precedentes.
Especificações técnicas do Llama 3.1
Quanto aos pormenores técnicos, o Llama 3.1 oferece uma gama de tamanhos de modelos para se adaptar a diferentes necessidades e recursos computacionais:
Modelo de parâmetros 8B: Adequado para aplicações ligeiras e dispositivos de ponta.
Modelo de parâmetros 70B: Um equilíbrio entre os requisitos de desempenho e de recursos.
Modelo de parâmetros 405B: O modelo emblemático, que ultrapassa os limites das capacidades de IA de fonte aberta.
A metodologia de treino para a Llama 3.1 envolveu um conjunto de dados maciço de mais de 15 triliões de fichas, significativamente maior do que os seus antecessores.
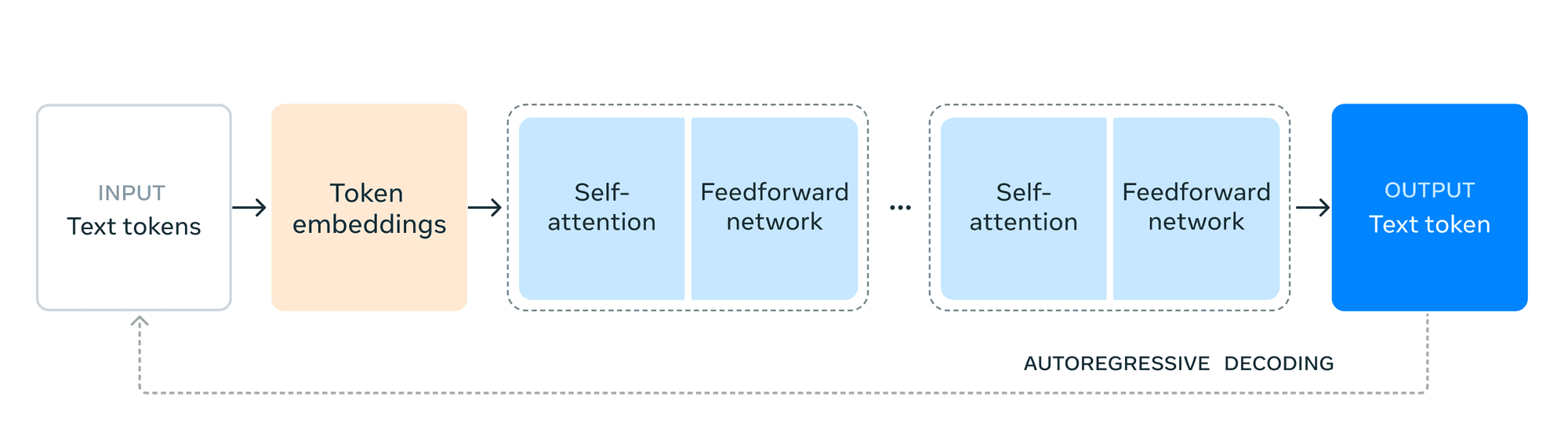
Arquitetonicamente, a Llama 3.1 mantém um modelo de transformador apenas de descodificador, dando prioridade à estabilidade do treino em detrimento de abordagens mais experimentais como a mistura de especialistas.
No entanto, o Meta implementou várias optimizações para permitir uma formação e inferência eficientes a esta escala sem precedentes:
Infraestrutura de formação escalável: Utilizando mais de 16.000 GPUs H100 para treinar o modelo 405B.
Procedimento iterativo de pós-treino: Utilizar a afinação supervisionada e a otimização direta das preferências para melhorar capacidades específicas.
Técnicas de quantização: Reduzir o modelo de 16 bits para 8 bits numéricos para uma inferência mais eficiente, permitindo a implementação em nós de servidor único.
Capacidades inovadoras
O Llama 3.1 apresenta várias capacidades inovadoras que o distinguem no panorama da IA:
Comprimento do contexto expandido: O salto para uma janela de contexto de token de 128K é um divisor de águas. Esta capacidade alargada permite à Llama 3.1 processar e compreender textos muito mais longos, permitindo:
Suporte multilingue: O suporte da Llama 3.1 para oito línguas alarga significativamente a sua aplicabilidade global.
Raciocínio avançado e utilização de ferramentas: O modelo demonstra capacidades de raciocínio sofisticadas e a capacidade de utilizar eficazmente ferramentas externas.
Geração de código e capacidades matemáticas: O Llama 3.1 apresenta capacidades notáveis em domínios técnicos:
Geração de código funcional de alta qualidade em várias linguagens de programação
Resolver problemas matemáticos complexos com exatidão
Assistência na conceção e otimização de algoritmos
Promessas e potencialidades da Llama 3.1
O lançamento do Llama 3.1 pela Meta marca um momento crucial no panorama da IA, democratizando o acesso a capacidades de IA de nível avançado. Ao oferecer um modelo de parâmetros 405B com desempenho de ponta, suporte multilingue e comprimento de contexto alargado, tudo numa estrutura de código aberto, a Meta estabeleceu um novo padrão para uma IA acessível e poderosa. Este passo não só desafia o domínio dos modelos de código fechado, como também abre caminho a uma inovação e colaboração sem precedentes na comunidade de IA.
Obrigado por ler AI & YOU!
Para obter ainda mais conteúdos sobre IA empresarial, incluindo infográficos, estatísticas, guias de instruções, artigos e vídeos, siga o Skim AI em LinkedIn
É um Fundador, CEO, Capitalista de Risco ou Investidor que procura serviços de Consultoria de IA, Desenvolvimento de IA fraccionada ou Due Diligence? Obtenha a orientação necessária para tomar decisões informadas sobre a estratégia de produtos de IA da sua empresa e oportunidades de investimento.
Criamos soluções de IA personalizadas para empresas apoiadas por capital de risco e capital privado nos seguintes sectores: Tecnologia Médica, Agregação de Notícias/Conteúdo, Produção de Filmes e Fotos, Tecnologia Educacional, Tecnologia Jurídica, Fintech e Criptomoeda.


