
튜토리얼: 추출 요약에 맞게 BERT를 미세 조정하는 방법



튜토리얼: 추출 요약에 맞게 BERT를 미세 조정하는 방법
Skim AI의 머신러닝 연구원 크리스 트란이 작성한 글입니다.![]()
1. 소개
요약은 자연어 처리 분야에서 오랫동안 해결해야 할 과제였습니다. 문서의 가장 중요한 정보를 유지하면서 짧은 버전의 문서를 생성하려면 반복되는 정보를 피하면서 핵심을 정확하게 추출할 수 있는 모델이 필요합니다. 다행히도 Transformer 모델 및 언어 모델 사전 학습과 같은 최근의 NLP 작업은 요약의 최첨단 기술을 발전시켰습니다.
이 문서에서는 다음에서 추출 요약하기 위해 BERT의 간단한 변형인 BERTSUM을 살펴봅니다. 사전 학습된 인코더를 사용한 텍스트 요약 (Liu et al., 2019). 그런 다음, 리소스가 적은 장치에서 추출 요약을 더 빠르고 더 작게 만들기 위해 DistilBERT를 미세 조정합니다(Sanh 외, 2019) 및 모바일버트(Sun et al., 2019), 두 가지 최신 라이트 버전의 BERT를 살펴보고 그 결과에 대해 논의합니다.
2. 추출 요약
요약에는 두 가지 유형이 있습니다: 추상적 및 추출 요약. 추상적 요약은 기본적으로 요점을 다시 작성하는 것을 의미하지만, 추출적 요약은 문서에서 가장 중요한 범위/문장을 직접 복사하여 요약을 생성합니다.
추상적인 요약은 사람에게는 더 어렵고 기계에게는 계산 비용이 더 많이 듭니다. 그러나 어떤 요약이 더 나은지는 최종 사용자의 목적에 따라 달라집니다. 에세이를 작성하는 경우 추상적 요약이 더 나은 선택일 수 있습니다. 반면에 조사를 하면서 읽은 내용을 빠르게 요약해야 하는 경우에는 추출 요약이 작업에 더 도움이 될 수 있습니다.
이 섹션에서는 추출 요약 모델의 아키텍처를 살펴보겠습니다. BERT 요약기는 BERT 인코더와 요약 분류기의 두 부분으로 구성됩니다.
BERT 인코더

BERTSUM의 개요 아키텍처
당사의 BERT 인코더는 마스크 언어 모델링 작업에서 사전 학습된 BERT 기반 인코더입니다(Devlin 외, 2018). 추출 요약 작업은 문장 수준에서 이진 분류 문제입니다. 각 문장에 최종 요약에 해당 문장이 포함될지 여부를 나타내는 $y_i \in {0, 1}$ 레이블을 할당하려고 합니다. 따라서 토큰을 추가해야 합니다. [CLS] 를 각 문장 앞에 추가합니다. 인코더를 통해 포워드 패스를 실행한 후, 마지막 숨겨진 레이어는 다음과 같습니다. [CLS] 토큰을 문장의 표현으로 사용할 것입니다.
요약 분류기
각 문장의 벡터 표현을 얻은 후, 간단한 피드 포워드 레이어를 분류기로 사용하여 각 문장에 대한 점수를 반환할 수 있습니다. 이 논문에서 저자는 간단한 선형 분류기, 순환 신경망, 3개의 레이어로 구성된 작은 트랜스포머 모델을 실험했습니다. 트랜스포머 분류기가 가장 좋은 결과를 얻었으며, 이는 자기 주의 메커니즘을 통한 문장 간 상호 작용이 가장 중요한 문장을 선택하는 데 중요하다는 것을 보여줍니다.
따라서 인코더에서는 문서 내 토큰 간의 상호작용을 학습하고 요약 분류기에서는 문장 간의 상호작용을 학습합니다.
3. 더 빠르게 요약하기
트랜스포머 모델은 대부분의 NLP 벤치마크에서 최첨단 성능을 달성하지만, 이를 학습하고 예측하는 데는 계산 비용이 많이 듭니다. 요약 기능을 더 가볍고 빠르게 리소스가 적은 디바이스에 배포할 수 있도록 하기 위해 다음과 같이 수정했습니다. 소스 코드 를 사용하여 BERT 인코더를 DistilBERT 및 MobileBERT로 대체할 수 있도록 BERTSUM 작성자가 제공했습니다. 요약 레이어는 변경되지 않은 상태로 유지됩니다.
다음은 이 세 가지 변형의 교육 손실입니다: 텐서보드

DistilBERT는 BERT 기반보다 40% 더 작지만, 훈련 손실은 BERT 기반과 동일하지만 MobileBERT의 성능은 약간 더 나쁩니다. 아래 표는 CNN/DailyMail 데이터 세트에서의 성능, 포워드 패스의 크기 및 실행 시간을 보여줍니다:
| 모델 | ROUGE-1 | ROUGE-2 | ROUGE-L | 추론 시간* | 크기 | 매개변수 |
|---|---|---|---|---|---|---|
| bert-base | 43.23 | 20.24 | 39.63 | 1.65 s | 475 MB | 120.5 M |
| distilbert | 42.84 | 20.04 | 39.31 | 925ms | 310 MB | 77.4 M |
| 모바일버트 | 40.59 | 17.98 | 36.99 | 609ms | 128MB | 30.8 M |
*표준 Google Colab 노트북에서 단일 GPU의 포워드 패스 평균 실행 시간
45% 더 빠른 DistilBERT는 BERT 베이스와 거의 동일한 성능을 제공합니다. MobileBERT는 BERT-base의 94% 성능을 유지하면서도 BERT-base보다 4배, DistilBERT보다 2.5배 더 작습니다. MobileBERT 논문에서는 MobileBERT가 SQuAD v1.1에서 DistilBERT를 훨씬 능가하는 것으로 나타났습니다. 그러나 추출 요약의 경우에는 그렇지 않습니다. 하지만 디스크 크기가 128MB에 불과한 MobileBERT로서는 여전히 인상적인 결과입니다.
4. 요약하기
사전 교육된 모든 체크포인트, 교육 세부 정보 및 설정 지침은 다음에서 확인할 수 있습니다. 이 깃허브 리포지토리. 또한 모바일버트 인코더와 함께 BERTSUM 데모를 배포했습니다.
웹 앱: https://extractive-summarization.herokuapp.com/
![]()
Code:
![]()
토치 가져오기
from models.model_builder import ExtSummarizer
에서 ext_sum import summarize
# 모델 로드
model_type = 'mobilebert' #@param ['bertbase', 'distilbert', 'mobilebert']
checkpoint = torch.load(f'checkpoints/{model_type}_ext.pt', map_location='cpu')
model = ExtSummarizer(checkpoint=checkpoint, bert_type=model_type, device='cpu')
# 실행 요약
input_fp = 'raw_data/input.txt'
result_fp = 'results/summary.txt'
summary = summarize(input_fp, result_fp, model, max_length=3)
print(summary)
요약 샘플
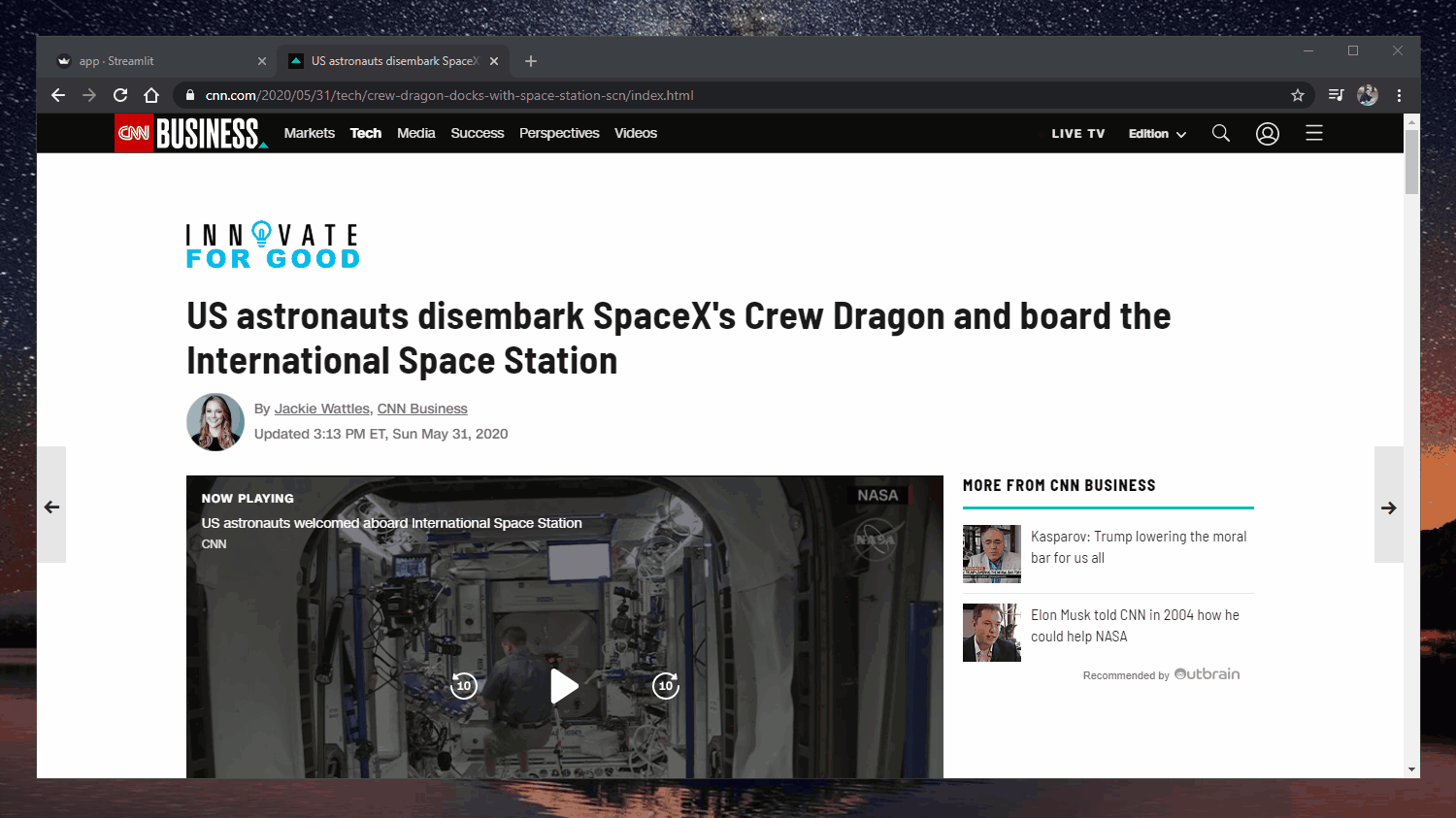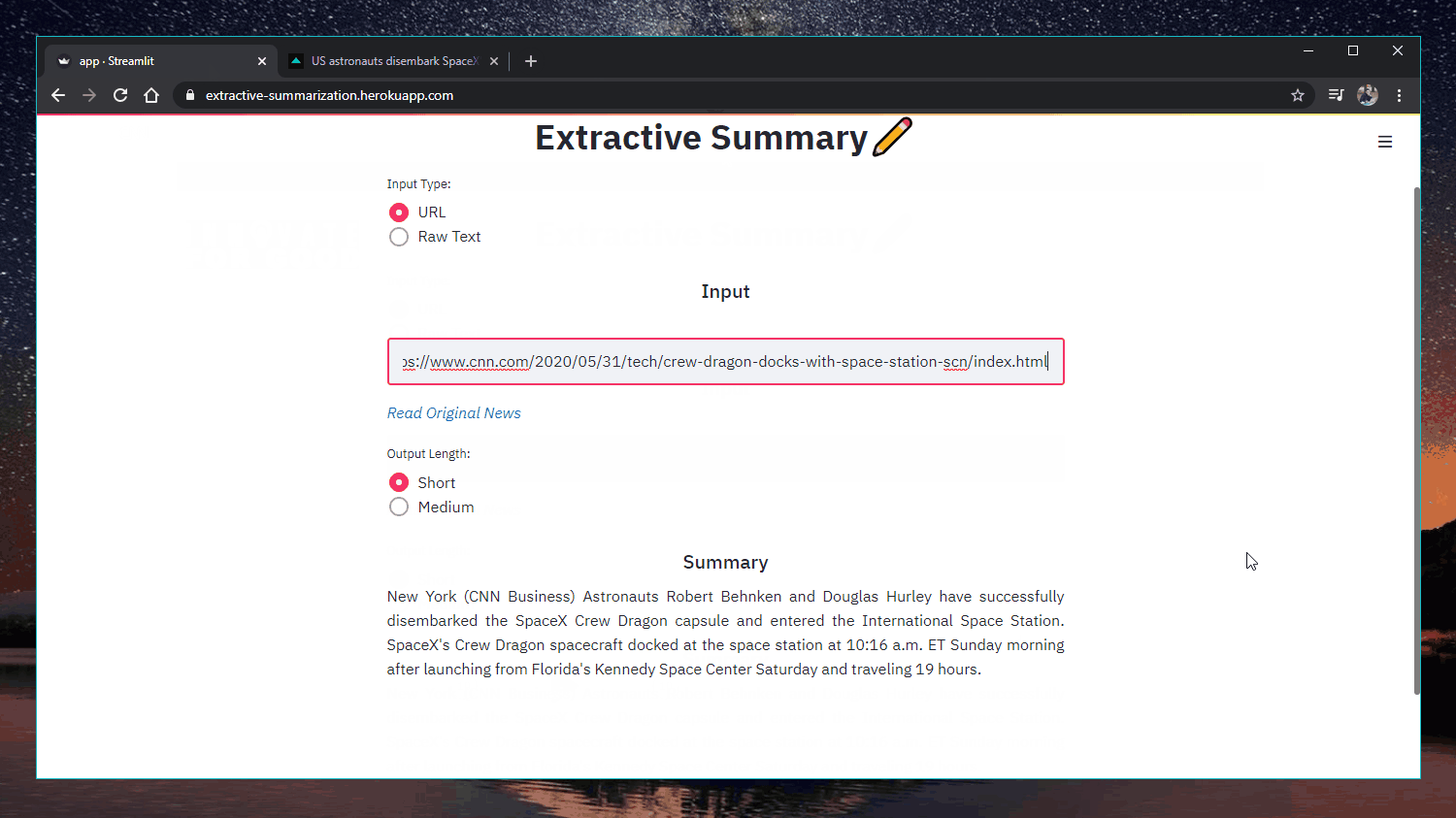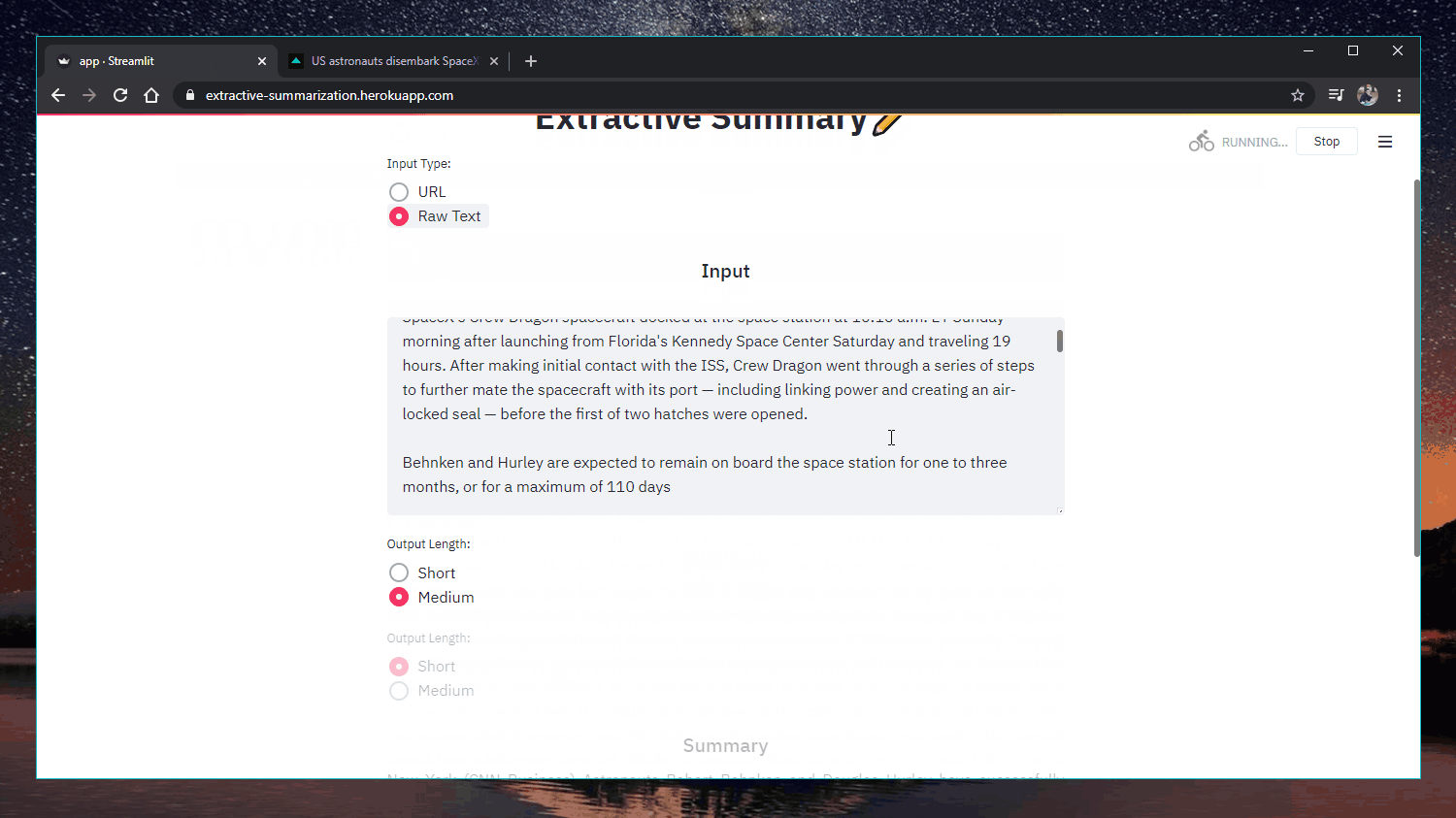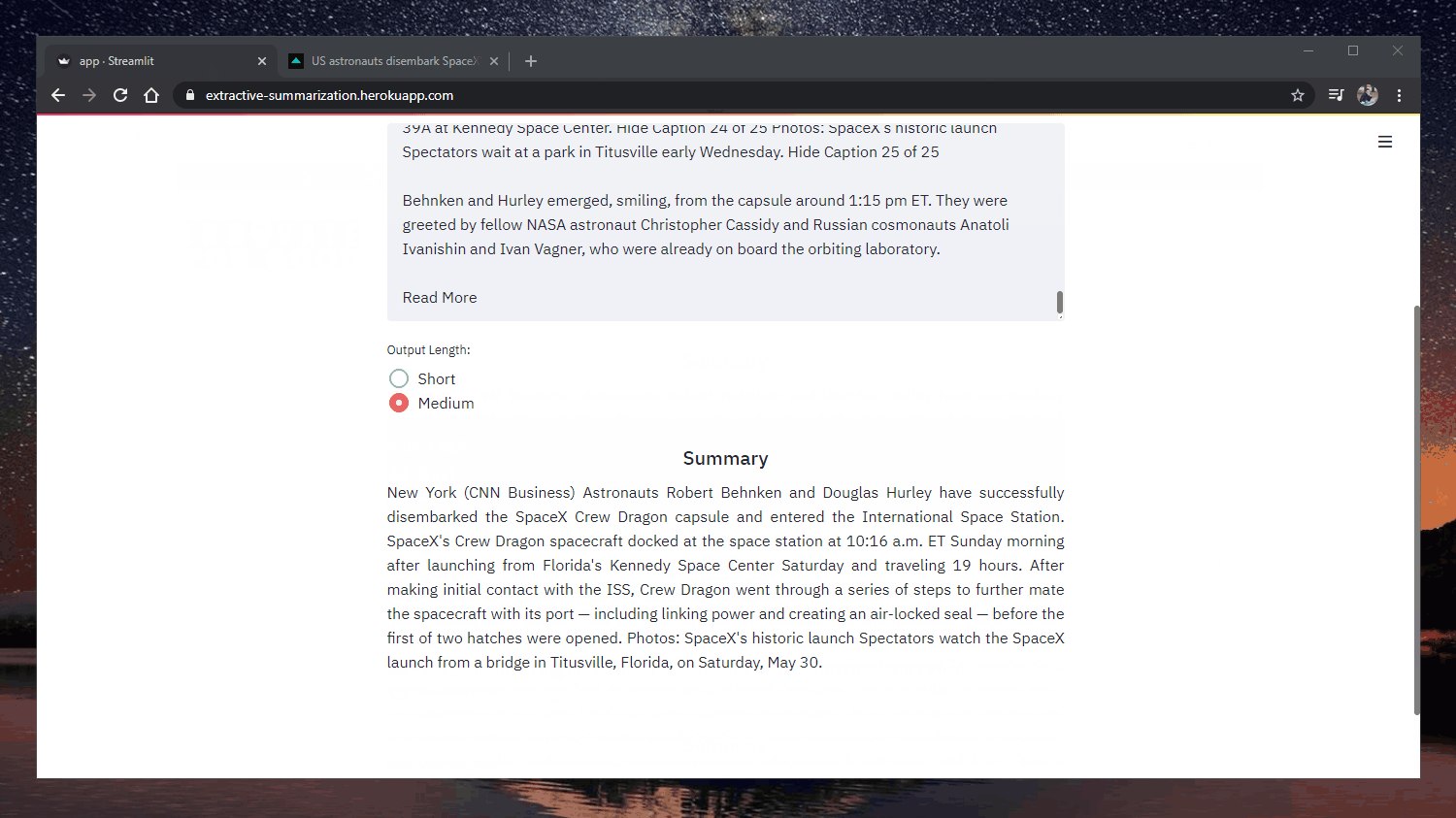
원본: https://www.cnn.com/2020/05/22/business/hertz-bankruptcy/index.html
허츠는 파산을 선언함으로써 부채를 재조정하고 재정적으로 더 건강한 회사로 거듭나면서 사업을 계속할 계획이라고 밝혔습니다.
재정적으로 더 건강한 회사로 거듭나겠다고 밝혔습니다. 이 회사는 1918년 12대의 포드 모델 T로 영업을 시작한 이래로 자동차를 대여해 왔으며
대공황, 제2차 세계대전 중 미국 자동차 생산이 사실상 중단된 대공황과
그리고 수많은 유가 쇼크에서도 살아남았습니다. "코로나19가 여행 수요에 미치는 영향은 갑작스럽고 극적이었으며, 이로 인해
회사의 수익과 향후 예약이 급격히 감소했습니다."라고 회사의 성명을 통해 밝혔습니다.
5. 결론
이 문서에서는 논문에서 추출 요약을 위해 BERT의 간단한 변형인 BERTSUM을 살펴봤습니다. 사전 학습된 인코더를 사용한 텍스트 요약 (Liu et al., 2019). 그런 다음, 저자원 장치에서 추출 요약을 더 빠르고 더 작게 만들기 위해 CNN/DailyMail 데이터 세트에 대해 DistilBERT(Sanh et al., 2019)와 MobileBERT(Sun et al., 2019)를 미세 조정했습니다.
DistilBERT는 추출 요약에서 BERT-base의 성능을 유지하면서도 크기는 45% 더 작습니다. MobileBERT는 BERT-base보다 4배 더 작고 2.7배 빠르지만 성능은 94%를 유지합니다.
마지막으로, 추출 요약에 대한 MobileBERT의 웹 앱 데모를 다음 사이트에 배포했습니다. https://extractive-summarization.herokuapp.com/.


