
에 의해 그레고리 엘리아스 | 12월 29, 2020 | 엔터프라이즈 AI, 방법, LLM / NLP
튜토리얼: 처음부터 스페인어로 ELECTRA를 사전 훈련하는 방법 Skim AI의 머신러닝 연구원 크리스 트란이 처음 게시했습니다. 소개 이 글에서는 Transformer 사전 학습 방법 제품군의 또 다른 구성원인 ELECTRA를 사전 학습하는 방법에 대해 설명합니다.
에 의해 그레고리 엘리아스 | 12월 28, 2020 | 엔터프라이즈 AI, 방법, LLM / NLP
튜토리얼: NER을 위해 BERT를 미세 조정하는 방법 Skim AI의 머신 러닝 연구원 Chris Tran이 처음 게시했습니다. 소개 이 문서에서는 네임드 엔티티 인식(NER)을 위해 BERT를 미세 조정하는 방법에 대해 설명합니다. 특히, BERT 변형인 SpanBERTa를 훈련하는 방법에 대해 설명합니다.
에 의해 그레고리 엘리아스 | 12월 28, 2020 | 엔터프라이즈 AI, 방법, LLM / NLP
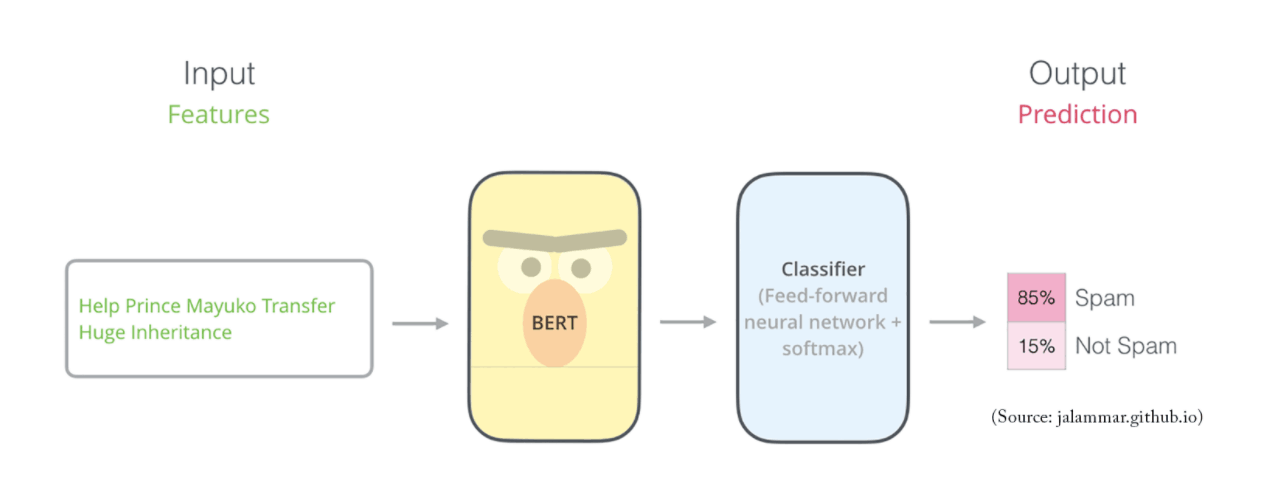
튜토리얼: 추출 요약화를 위해 BERT를 미세 조정하는 방법 작성자: Skim AI의 머신러닝 연구원 Chris Tran 1. 서론 요약화는 자연어 처리 분야에서 오랫동안 어려운 과제였습니다. 짧은 버전을 생성하려면 ...
에 의해 그레고리 엘리아스 | 12월 28, 2020 | 엔터프라이즈 AI, 방법, LLM / NLP
트랜스포머를 사용한 명명된 엔티티 인식 소개퍼머넌트 1부: 스페인어용 RoBERTa 언어 모델을 처음부터 훈련한 방법 이전 블로그 게시물에서는 스페인어용 트랜스포머 언어 모델인 SpanBERTa를 대규모 말뭉치로 사전 훈련한 방법에 대해 설명했습니다....
에 의해 그레고리 엘리아스 | 12월 11, 2020 | 엔터프라이즈 AI, LLM / NLP, 프로젝트 관리
뉴스 및 콘텐츠 기업이 인공지능을 사용하여 비용을 절감하고 UX를 개선하는 8가지 방법 기술의 영향을 이해하는 가장 좋은 방법은 현재 문제를 해결하기 위해 실제로 기술을 적용하는 구체적인 사례를 이해하는 것입니다. 다음은 8가지 일반적인 AI 활용 사례입니다.
에 의해 그레고리 엘리아스 | 12월 9, 2020 | 엔터프라이즈 AI, LLM / NLP, 프로젝트 관리
AI가 잘 해결하는 6가지 문제 851TP3조 이상의 데이터 과학 프로젝트가 테스트를 넘어 프로덕션으로 이어지지 못합니다. 모두가 머신러닝/인공지능 프로젝트를 시작하고 있다면 어디에서 문제가 발생하고 있을까요? 이 포스팅을 통해 다음 사항에 집중하는 데 도움이 될 것입니다.





최근 댓글