
執筆者 グレゴリー・エリアス | 12月 28, 2020 | エンタープライズAI, どのように, LLM / NLP
チュートリアルNERのためにBERTを微調整する方法 原文:Skim AIの機械学習研究者、Chris Tran.はじめに この記事では、名前付き固有表現認識(NER)のためにBERTを微調整する方法について説明します。具体的には、BERTのバリエーションであるSpanBERTaを訓練する方法です。
執筆者 グレゴリー・エリアス | 12月 28, 2020 | エンタープライズAI, どのように, LLM / NLP
チュートリアル抽出的要約のためにBERTを微調整する方法 原文:Skim AIの機械学習研究者、クリス・トラン 1.はじめに 要約は、自然言語処理における長年の課題である。要約の短いバージョンを生成するには...
執筆者 グレゴリー・エリアス | 12月 28, 2020 | エンタープライズAI, どのように, LLM / NLP
トランスフォーマーによる名前付き固有表現認識 はじめにパーマーリンク Part I: スペイン語のRoBERTa言語モデルをゼロから学習した方法 前回のブログポストでは、スペイン語のトランスフォーマー言語モデルであるSpanBERTaを、...
執筆者 グレゴリー・エリアス | 12月 11, 2020 | エンタープライズAI, LLM / NLP, プロジェクト管理
ニュース&コンテンツ企業がA.I.を使ってコストを節約し、UXを改善する8つの方法 テクノロジーの影響を理解する最善の方法は、現在の問題を解決するために実際にテクノロジーを適用する方法の具体例、事例を理解することである。以下は、一般的な8つのAI...
執筆者 グレゴリー・エリアス | 12月 9, 2020 | エンタープライズAI, LLM / NLP, プロジェクト管理
AIが解決する6つの問題 85%を超えるデータサイエンス・プロジェクトが、テストから本番へと移行できずにいる。誰もが機械学習/人工知能プロジェクトを始めているとしたら、どこで失敗しているのだろうか? この記事を読めば、AIが解決すべき6つの問題に焦点を絞ることができるだろう。
執筆者 グレゴリー・エリアス | 7月 27, 2020 | LLM / NLP, プロジェクト管理
自然言語生成とそのビジネス応用 自然言語生成(NLG) AI著者とロボットが生成したニュースの継続的な探求として、これらのアルゴリズムを駆動する技術のいくつかを探求することは価値がある。自然言語生成のために設計されたAI...
執筆者 グレゴリー・エリアス | 4月 29, 2020 | どのように, LLM / NLP
SpanBERTa:How We Trained RoBERTa Language Model for Spanish from Scratch 原文:Skim AIの機械学習研究インターン、クリス・トラン。 spanberta_pretraining_bert_from_scratch はじめに¶ トランスフォーマーモデルによる自己学習法...
執筆者 グレゴリー・エリアス | 4月 15, 2020 | どのように, LLM / NLP
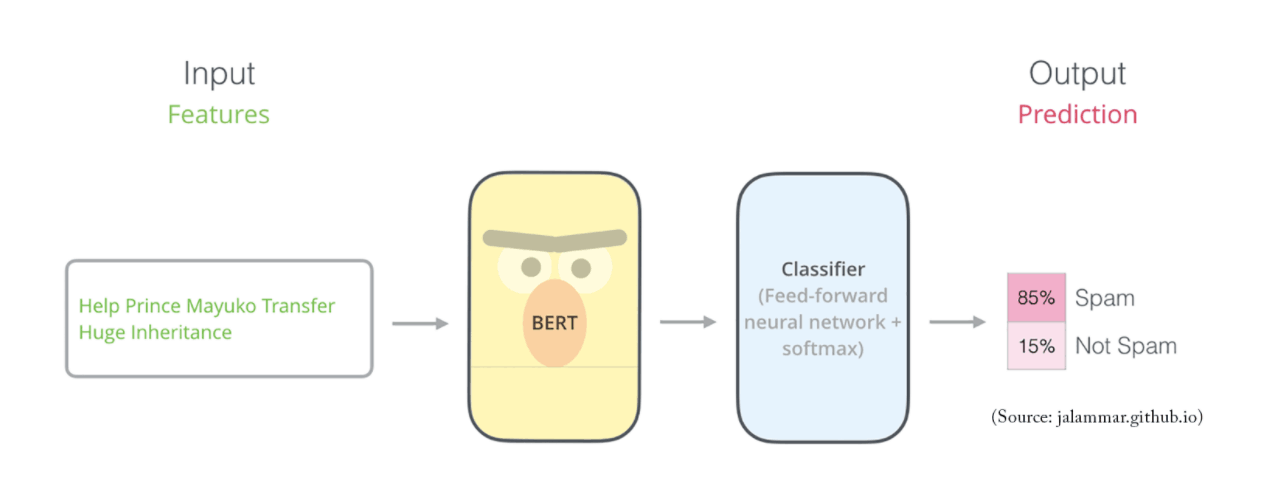
チュートリアルセンチメント分析のためのBERTの微調整 原文:Skim AIの機械学習研究者、クリス・トラン。BERT_for_Sentiment_Analysis A - はじめに¶ 近年、NLPコミュニティは自然言語処理において多くのブレークスルーを見てきました。
執筆者 グレゴリー・エリアス | 3月 20, 2020 | エンタープライズAI, LLM / NLP, プロジェクト管理
機械学習プロジェクトを始める前にすべき10の質問 データサイエンス・プロジェクトの80%以上が、テストから本番への移行に失敗している。誰もが機械学習プロジェクトを始めているとしたら、どこで失敗しているのだろうか?間違いなく、MLソリューションは効率を高める...
執筆者 グレゴリー・エリアス | 2月 10, 2020 | どのように
リサーチ・プロセスにおけるSkim AIの活用法 リサーチ・プロセス、そこから収集されるデータ、そしてその結果として生み出されるコンテンツを管理するための、あなたの組織の現在の方法が不足している可能性は非常に高い。グーグルドライブ、エバーノート、...
執筆者 グレゴリー・エリアス | 1月 30, 2020 | エンタープライズAI, LLM / NLP
ジャーナリズムの新潮流、ロボット記者?では、ロボット記者はどの程度普及しているのか?ロボット記者にはどんな危険があるのか?あなたが読んでいる記事が人間によって書かれたものでない可能性は?2015年の報告によれば、AP通信は約3,000...
執筆者 グレゴリー・エリアス | 1月 6, 2020 | 未分類
私たちのユーザーコミュニティが成長するにつれ、私たちのチームは、あなたの努力の最適化を支援し続けるために必要なものに耳を傾けるために時間を割いてきました。スキムAIのv3.0では、デザインを改善し、検索機能を拡張し、さらに簡単に独自のファイルをスキミングできるようになりました。
執筆者 グレゴリー・エリアス | 12月 5, 2019 | エンタープライズAI, LLM / NLP, プロジェクト管理
プロダクト・マネージャーのためのトピック・モデリング トピック・モデリングとは?トピック・モデリングとは、自然言語処理(NLP)の一種で、文書集合の中から「トピック」、つまりよく出現する単語や単語のグループを見つけるために使用される。トピック・モデルは、プロダクト・マネージャーにとって非常に重要です...
執筆者 グレゴリー・エリアス | 11月 11, 2019 | LLM / NLP, プロジェクト管理
ラベル付けされたデータを保存するための10のベストプラクティス あなたは大きなアイデアを思いついた。あなたはよく本を読むので、話し手の口調をラベル付けし、その政治的所属を決定する分類器があれば面白いと考えた。この問題をどのように解決しますか?
執筆者 グレゴリー・エリアス | 11月 6, 2019 | LLM / NLP, プロジェクト管理
センチメント分析データセットを選択する前に知っておくべきこと なぜトレーニングにセンチメント分析データセットが必要なのか? センチメントモデルは、テキストの極性を決定する自然言語処理(NLP)アルゴリズムの一種です。つまり、...
執筆者 グレゴリー・エリアス | 10月 23, 2019 | LLM / NLP
我々は本当にニューラル・レコメンデーション・アプローチを進歩させているのか?Maurizio Ferrari Dacrema氏らのRecSys 2019での最新論文の要約ニューラル・レコメンデーション・アルゴリズムレコメンデーション・アルゴリズムは、アマゾンから、商業的な分野にわたってユビキタスになっている。
執筆者 グレゴリー・エリアス | 9月 18, 2019 | 未分類
すべての)研究者のための1つのツール 概念や問題を単純化するために、物事を異なるカテゴリーに分類するのは一般的なやり方である。しかし、その分類によって、あるカテゴリーに対する先入観を全体の概念に当てはめてしまうことがよくあるのではないだろうか?例えば...
執筆者 グレゴリー・エリアス | 9月 10, 2019 | LLM / NLP
トップ20%のファクトを検索する 私たちは皆、基本的にどんなトピックについても、インターネット上に無限のデータがあることを知っています。信じられない?試してみよう。Googleが "multi-label text classification "で4億6000万件の検索結果を出すのに0.46秒かかった。おわかりだろうか? 
















最近のコメント