
マルチモーダルAIツール・プラットフォーム トップ5



人工知能の状況は常に進化している。 マルチモーダルAI ツールやプラットフォームが重要なプレーヤーとして台頭してきている。これらの革新的なソリューションは、テキスト、画像、音声、動画など、さまざまな種類のデータを統合することで、従来の単一モードのAIを超え、よりインテリジェントで効率的、かつ直感的なシステムを構築する。この統合により、より包括的な理解とデータとの相互作用が可能になり、人間が情報を知覚し処理する多面的な方法を忠実に反映することができる。
このブログでは、技術界で波紋を広げているマルチモーダルAIのトップ・ツールやプラットフォームをいくつか紹介する。これらのプラットフォームは、機械がどのように学習し、データと相互作用するかに革命を起こしているだけでなく、企業や個人がより複雑で正確なアプリケーションのためにAIを活用する方法にも革命を起こしている。
1. 滑走路 Gen-2
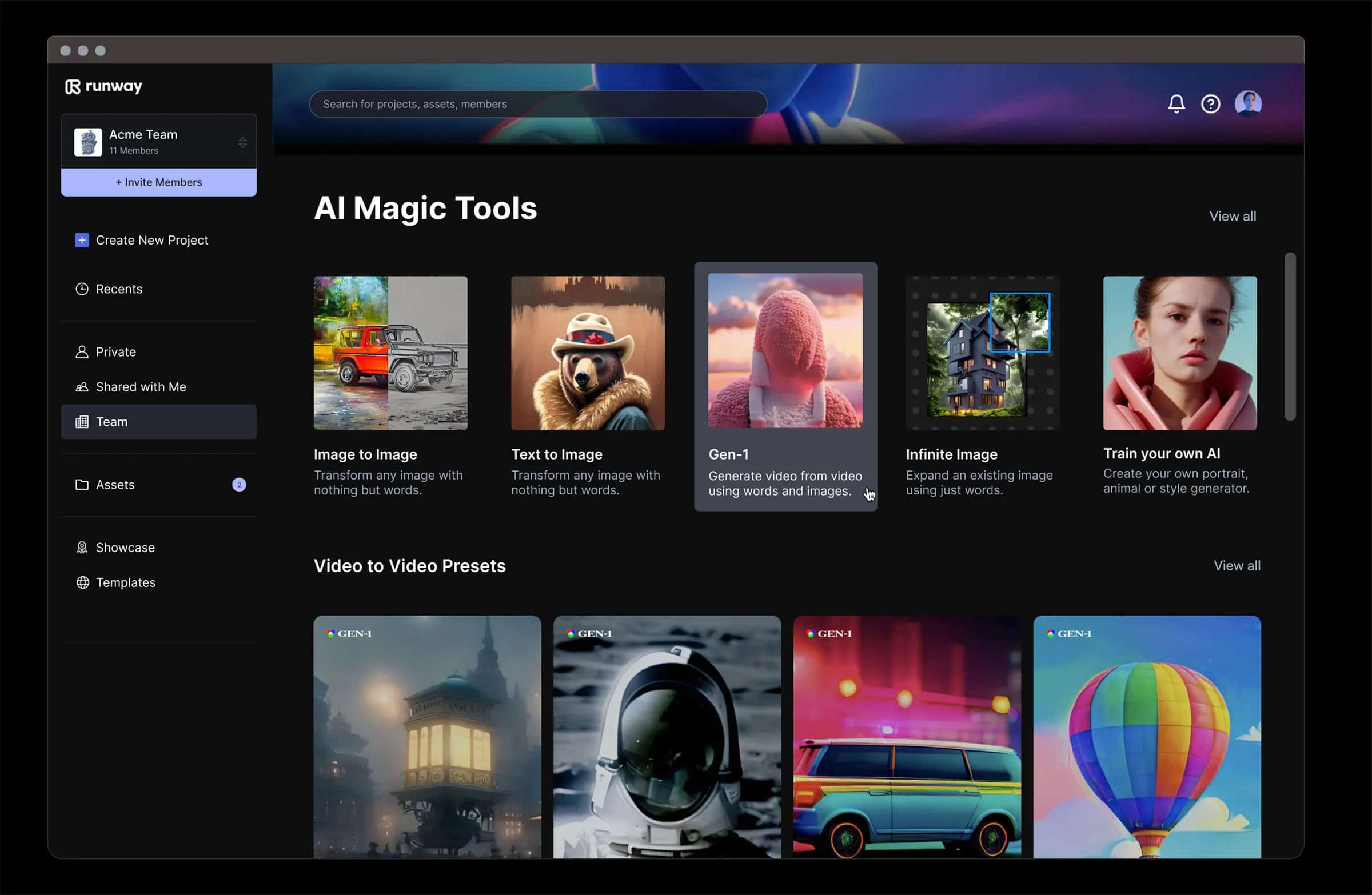
ランウェイ ランウェイが開発したGen-2は、次のような領域で大きな進化を遂げている。 ジェネレーティブAI特にビデオと画像の合成において。このツールは、ユーザーがテキスト、画像、ビデオクリップをミックスして斬新なビデオを生成できるようにすることで、マルチモーダルAIのパワーを実証します。Runway Gen-2は、デジタル・クリエイティビティの限界を押し広げる、正確で、リアルで、制御可能なマルチメディア出力を作成することを可能にします。
最新のGen-2アップデートは、生成される動画の忠実さと一貫性が大きく進化したことで特に注目されている。このクオリティの飛躍は、AIコミュニティで注目を集め、ユーザーからはジェネレーティブAIの進化における極めて重要な瞬間とのレッテルを貼られている。シンプルなテキストプロンプト、画像、または既存の動画から本格的な動画を生成するツールの機能は画期的で、ストーリーテリングとデジタルメディアに新たな可能性を提供している。このような機能は、カメラの発明と比較され、AIが視覚的な物語を捉え、創造するための新しいメディアになりつつあることを示唆している。
ランウェイGen-2の主な特徴は以下の通り:
オーダーメイドのビデオや画像を作成する機能。
様々な用途のために生成されたコンテンツを簡単にダウンロードできる。
ランウェイのウェブとモバイルの両プラットフォームでアクセス可能で、多様性と利便性を提供。
ユーザーを前面に押し出したデザイン 生成AIの発展絶え間ないイノベーションを保証する。
Runway Gen-2は、ストーリーテリング、クリエイティビティ、AIが融合し、コンテンツ制作において想像を絶する道を切り開く、デジタルメディアの新時代の到来を告げるものである。
2. Meta AIによるImageBind
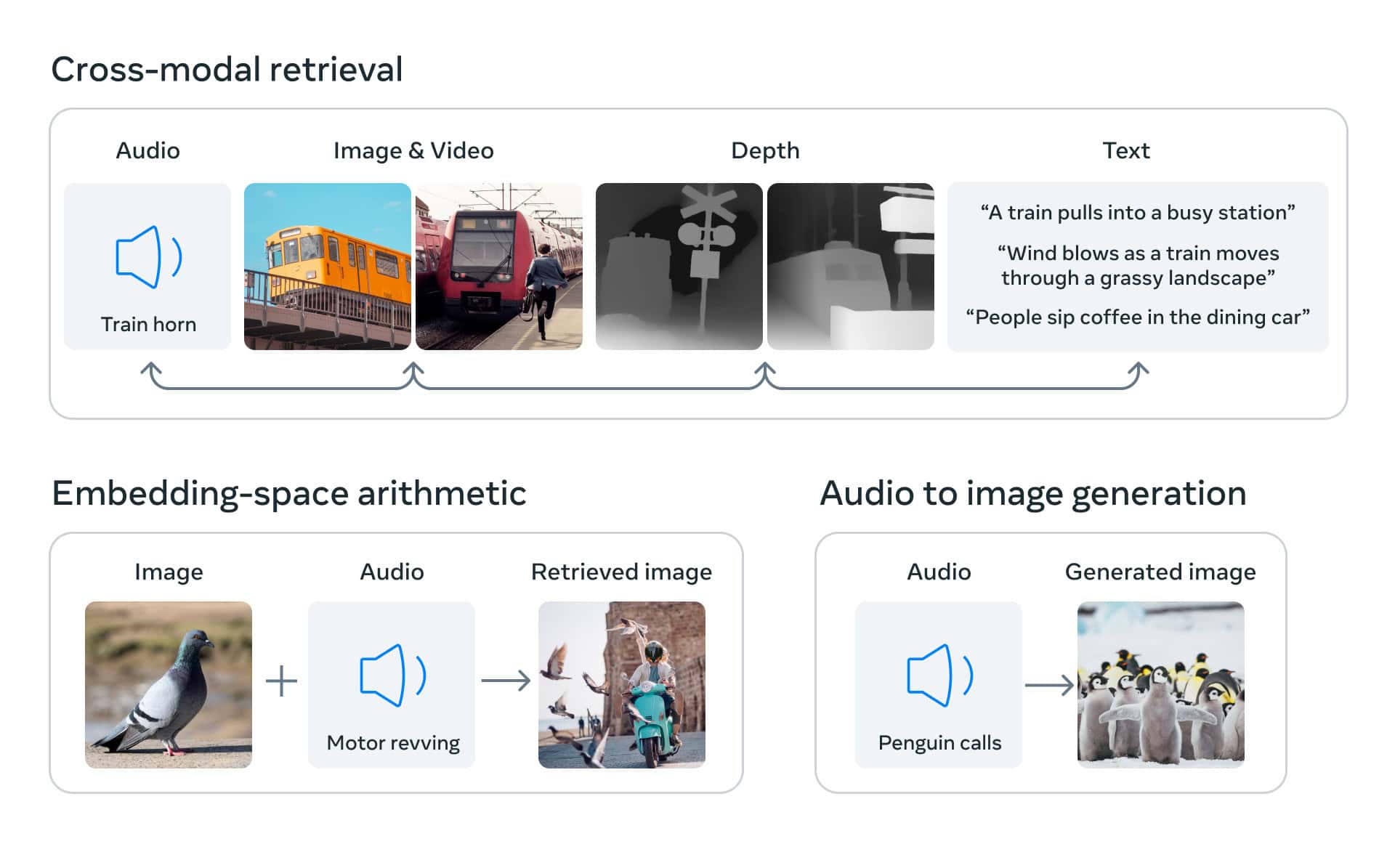
Meta AIが開発したImageBindは、マルチモーダルAIイノベーションの最前線に位置し、多様なデータタイプの統合と解釈における大きな飛躍を象徴している。この先駆的なモデルは、画像、テキスト、音声、深度、熱、IMUデータという6つの異なるモダリティからの情報を独自に統合する。この統合により、これらの多様なデータタイプの共同埋め込みが容易になり、クロスモーダル検索、モダリティの算術合成、検出、生成の前例のない機会が生まれる。
ImageBindの革新の本質は、大規模な視覚言語モデルの拡張にある。ImageBindは、これらのモデルのゼロショット能力を強化し、新しいモダリティにシームレスに適応できるようにする。この機能により、すぐに新しいアプリケーションを開発することが可能になり、AIシステムの潜在的なユースケースが大幅に拡大します。ImageBindは、これらのモダリティにまたがる新たなゼロショット認識タスクで優れた性能を示し、少数ショット認識の領域で新たなベンチマークを確立しました。
ImageBindの開発は、様々な種類のデータから学習するマルチモーダルAIシステムを構築するメタ社の広範な取り組みの一環である。6つの異なる形式のデータを1つの埋め込み空間に結合するその能力は、前例がない。この能力は、人間の知覚をより忠実に模倣するだけでなく、機械が異なる形態の情報をより効果的に一緒に分析することを可能にする。
ImageBindの主な特徴は以下の通りです:
6つのモダリティ(画像、テキスト、音声、深度、熱、IMU)を1つのモデルに統合。
ゼロショット機能を強化し、視覚言語モデルの機能を拡張。
ゼロショットおよび少数ショットの認識タスクで優れた性能を発揮。
オープンソースで提供され、マルチモーダルAI分野の発展に貢献。
その画期的なアプローチにより、ImageBindはAIに革命を起こし、革新的な製品を生み出す可能性を秘めている。 画像アプリケーション と映像の生成、音声合成、没入型バーチャル体験。これは、人間の認知プロセスを模倣し、私たちを取り巻く世界を解釈するAIの能力が進化していることの証である。
3. チャットGPT
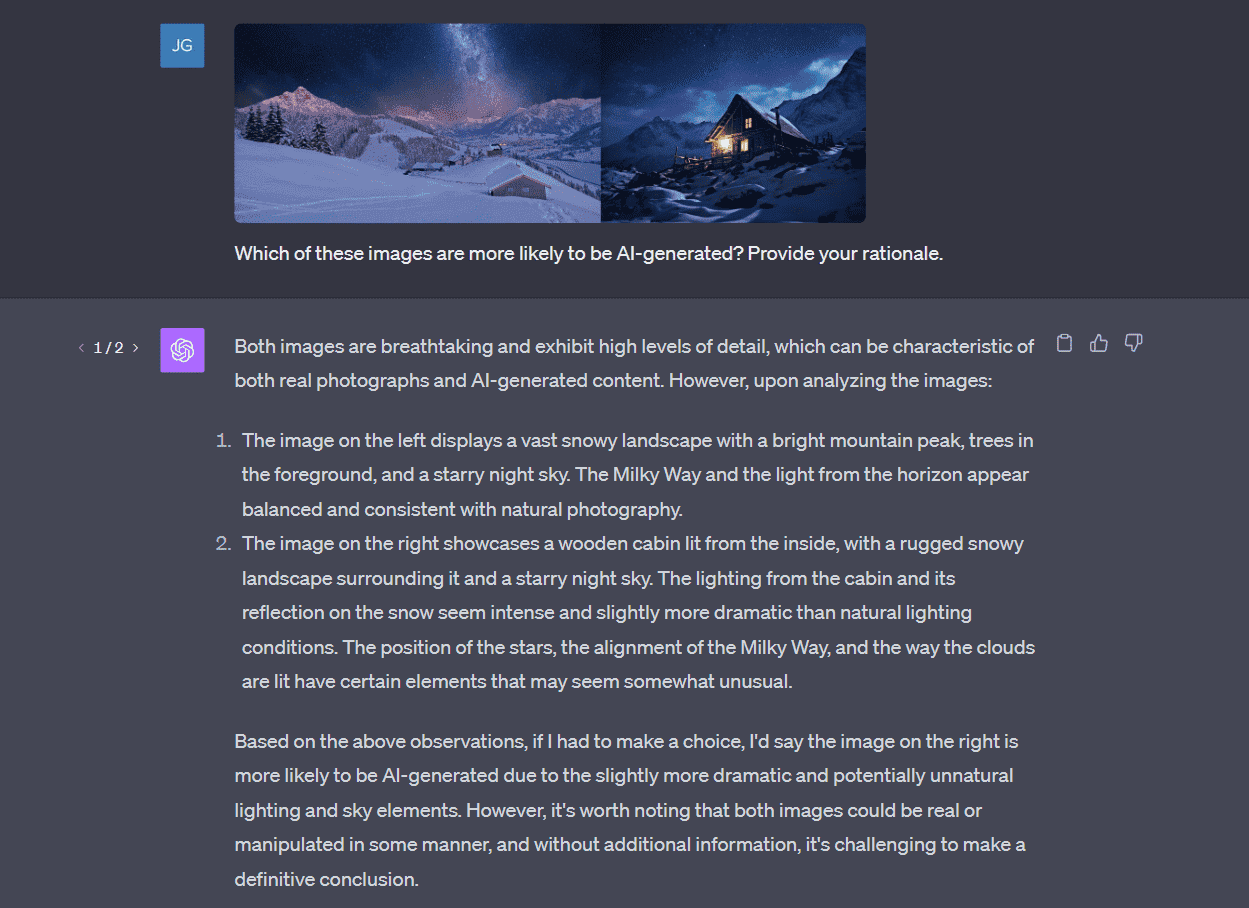
チャットGPT は、マルチモーダル機能を取り入れることで、テキストだけでなく、音声認識や画像認識などのインタラクション機能を強化し、大きな飛躍を遂げた。この拡張は、チャットボット技術の重要な進化を意味する。
最も注目すべき機能強化の一つは、ChatGPTの画像認識機能です。ChatGPTは、手書きのテキストを含む画像を理解・解釈できるようになりました。ユーザーは画像をアップロードし、雲のように画像内のオブジェクトを識別したり、冷蔵庫の中身の写真から食事プランを作成したりと、その内容についてチャットボットと対話することができます。この機能により、ChatGPTは、視覚的な入力に基づいて、より文脈に沿った適切な応答を提供できる、非常に汎用性の高いツールとなります。
画像認識に加え、ChatGPTは音声対話にも進出した。音声合成モデルを搭載し、ユーザーに5つの異なる音声オプションの選択肢を提供し、チャット体験に新たな次元を加えています。OpenAIのWhisper音声認識システムを組み込むことで、この機能はさらに強化されます。Whisperは話し言葉をテキストに書き起こすことができ、ユーザーとChatGPTの間のシームレスで直感的な対話を促進します。このマルチモーダルなアプローチにより、より自然で魅力的な会話体験が可能になります。
マルチモーダルChatGPTの主な特徴は以下の通り:
テキストだけでなく、画像や音声も処理するマルチモーダル機能。
画像認識により、画像や手書きのテキストを解釈できる。
音声認識には音声合成モデルと5種類の音声オプションが用意されている。
OpenAIのWhisperとの統合により、効率的な音声からテキストへの書き起こしが可能。
ChatGPTのマルチモーダル機能への進出は、AI開発における重要なマイルストーンとなる。これは、大規模なモデルが多様な種類のデータを処理し解釈する可能性を示すもので、より洗練されたインタラクティブなAIアプリケーションへの道を開くものです。
4. インワールドAI
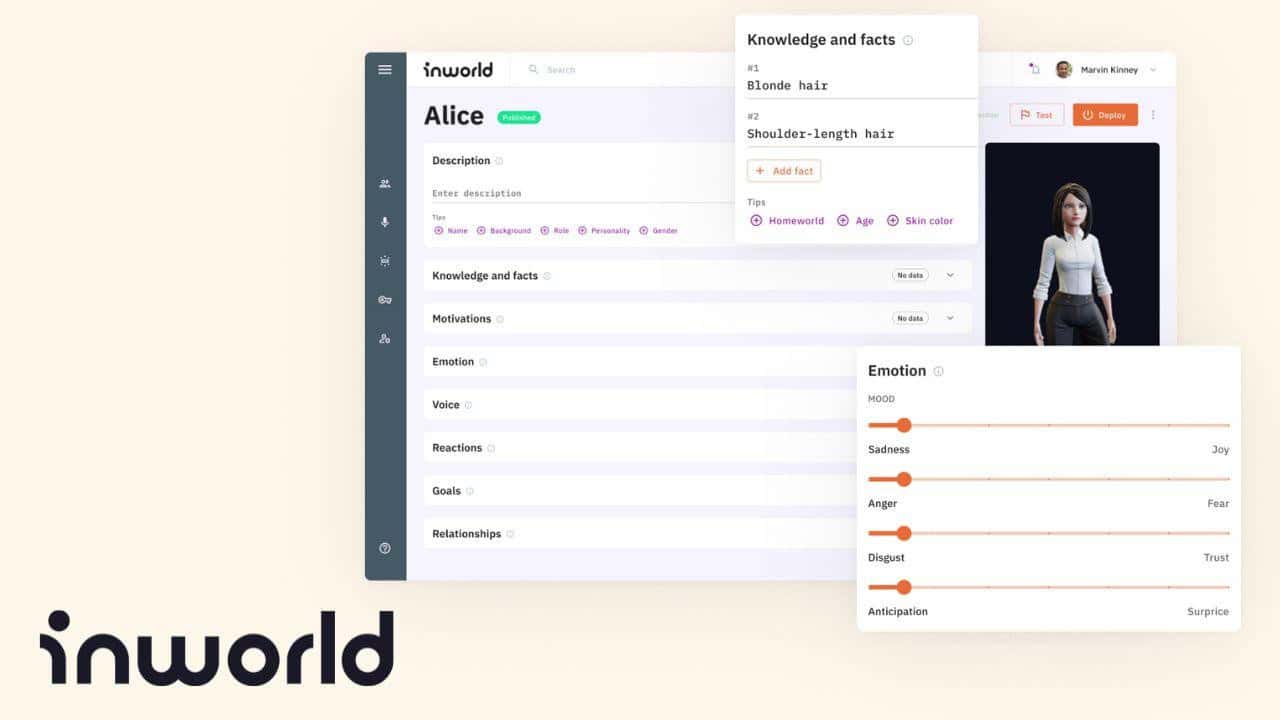
Inworldは、人工知能の領域、特にゲームやインタラクティブ環境における非プレイアブルキャラクター(NPC)の領域において大きな進歩をもたらします。GoogleのDialogflowを開発したチームによって開発されたこのキャラクターエンジンは、従来の大規模言語モデル(LLM)を超えて、AI NPCをリアリズムとインタラクションの新たな高みへと引き上げる一連の機能を導入しています。
Inworldの特徴は、キャラクター開発への包括的なアプローチにある。ユーザーは、文脈と物語を深く理解することで、明確な個性を持つAI NPCを作成することができます。これにより、キャラクターはゲーム世界の中で設計された役割に忠実であることが保証され、プレイヤーにより没入感のある体験を提供します。このツールの設定可能性は、安全性、知識、記憶、物語コントロールなどの側面にまで及び、さまざまな用途に対応する汎用性の高いソリューションとなっています。
インワールドは、ゲームの画期的な進歩にとどまらない。共感的なブランド大使やカスタマーサービス担当者の作成、パーソナライズされた学習体験の促進、インタラクティブなシミュレーションやゲーム化された学習の強化など、他の領域でも活用されている。このツールはリアルタイム生成AIを使用しているため、豊かでニュアンスがあり、魅力的なキャラクターを作成することができ、AIを利用したパーソナリティ、対話、リアクションの新しい基準を提供します。
インワールドの主な特徴は以下の通り:
設定可能な安全性、知識、記憶のパラメータにより、キャラクターの成長に合わせた育成が可能。
生産に対応したスケーラブルな設計で、成長のための追加設定は不要。
リアルタイム体験のための最適化により、ダイナミック・アプリケーションへの統合に最適です。
ゲームからカスタマーサービス、教育ツールまで、用途は多彩。
AI NPCへの革新的なアプローチにより、Inworldはキャラクタエンジンの新たなベンチマークを打ち立て、様々な場面で魅力的でリアルなキャラクタを作成する比類なき機会を提供します。
5. 目的 (旧 カイルア・ラボ)
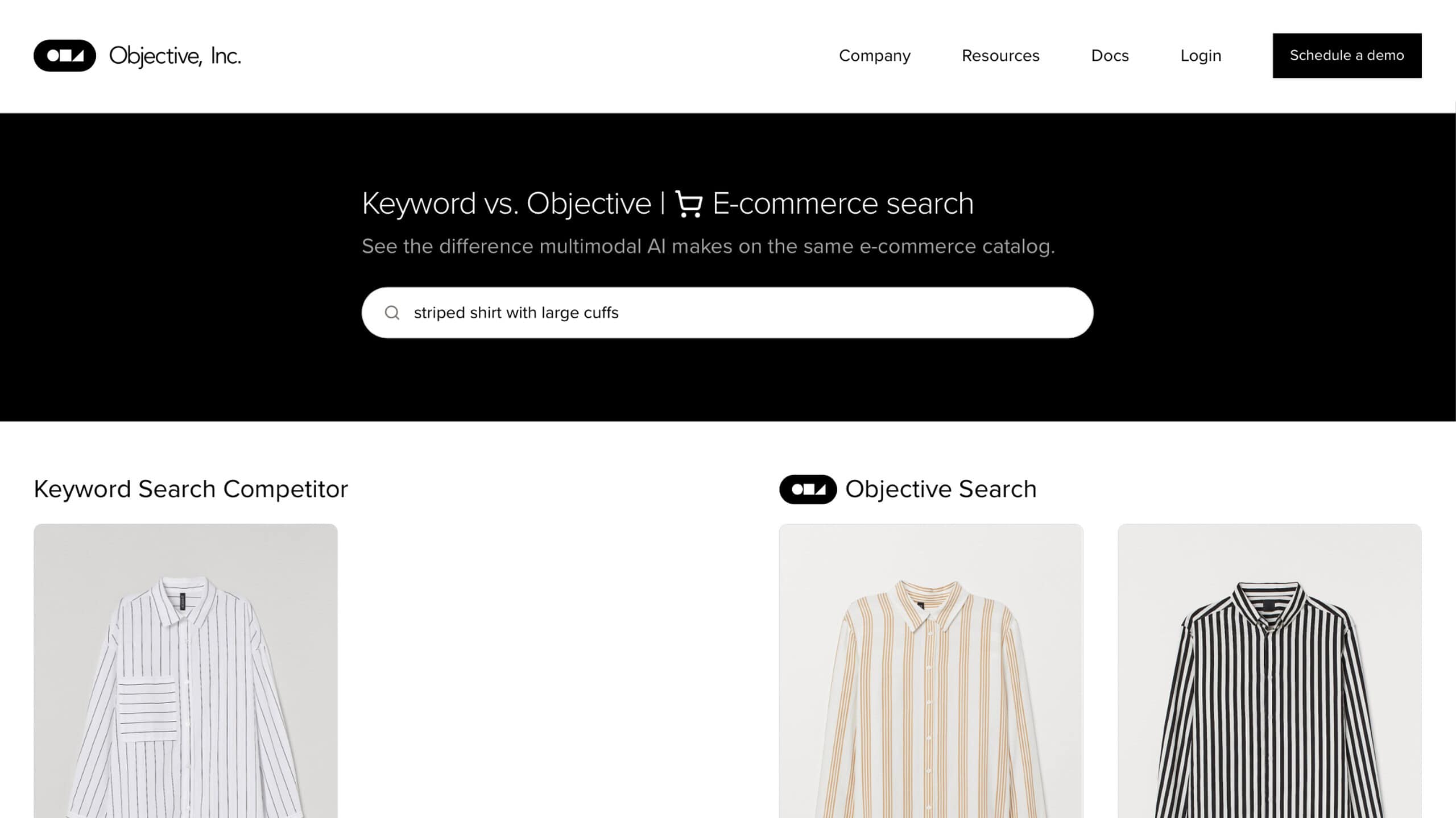
Objective(旧Kailua Labs)は、その高度なAI機能で検索プロセスに革命を起こしている。このツールは自然言語処理(NLP)を活用し、画像、動画、音声など様々な種類のデータを直感的に検索できる。Objectiveの特徴は、検索プロセスを民主化し、専門知識や高度な技術的専門知識の障壁を取り除く能力にある。
目的 ユーザーフレンドリーなインターフェース Objectiveのユーザーフレンドリーなインターフェースは、自然言語による検索を可能にし、あらゆるレベルのユーザーにとってアクセスしやすく、効率的な検索を可能にする。このツールの強みは、マルチモーダル検索のサポートにあり、ユーザーは自然言語と異なるデータタイプを組み合わせて使用することで、さまざまなアプリケーションのコンテンツを見つけることができます。このアプローチにより、検索結果の精度と関連性が大幅に向上する。
オブジェクティブの主な特徴は以下の通り:
ユーザーフレンドリーでアクセシブルなデザインで、さまざまな技術的専門知識を持つユーザーに対応。
より包括的で関連性の高い検索結果を可能にするマルチモーダル検索機能。
検索体験を簡素化し、強化するための自然言語処理の活用。
使いやすく革新的なAIツールを提供するというオブジェクティブのコミットメントは、検索エクスペリエンスを向上させるという同社の献身を体現している。プロセスを簡素化し、正確な結果を保証することで、Objectiveは高度なAI検索をより多くの人々が利用できるようにし、データとの関わり方を変えています。
マルチモーダルAIシステムによるデジタル・インタラクションの変革
このブログで探求してきたように、AIの展望はマルチモーダルなツールやプラットフォームの出現によって再形成されつつある。Runway Gen-2の画期的なビデオ合成からInworld AIの革新的なキャラクターエンジンまで、各ツールはAIが達成できることの限界を押し広げるユニークな機能をもたらしている。Objectiveはデータ検索へのアプローチに革命をもたらし、ImageBindはデータ統合と解釈における新たなベンチマークを打ち立てた。最後に、ChatGPTの画像認識と音声認識への拡大は、会話型AIの進化を証明するものであり、より汎用的でユーザーフレンドリーなものとなっている。
これらのツールは、単なる技術的進歩ではなく、AIとの関わり方や活用方法におけるパラダイムシフトを象徴している。これらのツールは、複数のデータタイプを統合することで、よりリッチで直感的、そして文脈を意識したAIシステムを実現する、計り知れない可能性を示している。これらのツールが進化を続け、新たなイノベーションが登場すれば、人間と機械知能のギャップをさらに埋める、さらなるエキサイティングな発展が期待できるだろう。
AIの未来は間違いなくマルチモーダルであり、これらのツールは、より全体的で、インタラクティブで、インテリジェントなシステムへの旅の始まりに過ぎない。私たちが前進するにつれ、可能性は無限に広がり、様々な業界を変革するアプリケーションの可能性は計り知れない。マルチモーダルAIの時代が到来し、我々のデジタル世界を再構築することを約束する。


