
AI研究論文まとめ:「思考の連鎖?プロンプティング



Chain-of-Thought(CoT)プロンプトは、大規模言語モデル(LLM)の推論能力を引き出す画期的な手法として注目されている。この技術は、LLMを導くために段階的な推論例を提供するもので、AIコミュニティで大きな注目を集めている。多くの研究者や実務家は、CoTプロンプトによってLLMが複雑な推論タスクにより効果的に取り組めるようになり、機械計算と人間のような問題解決のギャップを埋められる可能性があると主張している。
しかし、最近発表された論文"思考停止の連鎖?プランニングにおけるCoTの分析「という楽観的な主張がある。この研究論文は、計画タスクに焦点を当て、CoTプロンプトの有効性と一般化可能性を批判的に検証している。AIの実践者として、高度な推論能力を必要とするAIアプリケーションの開発において、これらの知見とその意味を理解することは極めて重要である。
研究を理解する
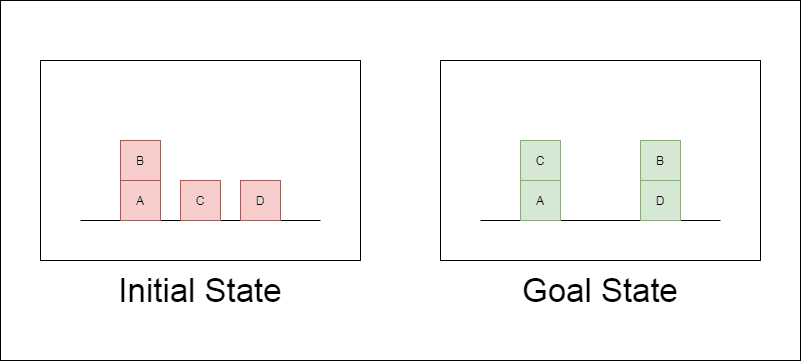
研究者たちは、ブロックワールドと呼ばれる古典的なプランニング領域を主なテスト対象として選んだ。ブロックワールドでは、一連の移動アクションを使って、ブロックの集合を初期配置からゴール配置に再配置することがタスクとなる。この領域は、推論能力と計画能力をテストするのに理想的である:
様々な複雑さの問題を生成することができる。
明確で、アルゴリズム的に検証可能な解決策がある。
LLMのトレーニング・データにはあまり含まれていないと思われる。
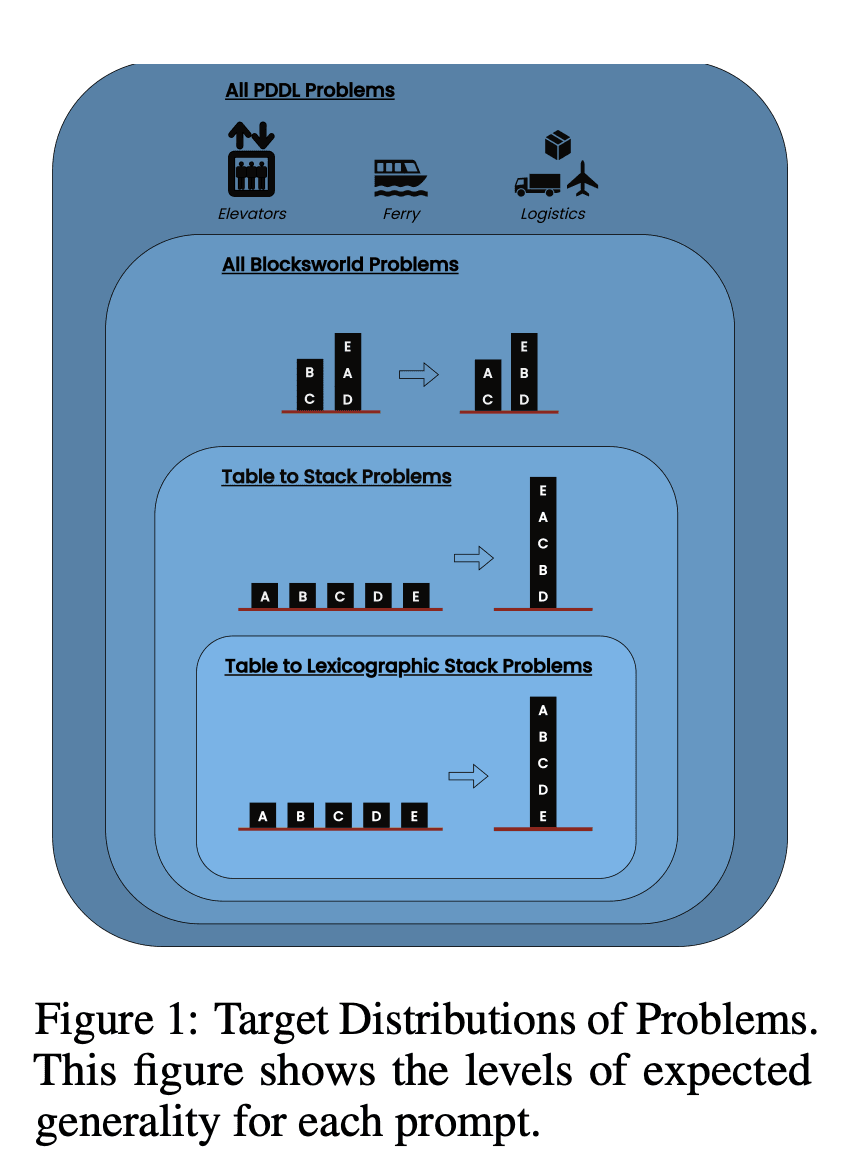
この研究では、3つの最新型LLMを検証した:GPT-4、Claude-3-Opus、GPT-4-Turboである。これらのモデルは様々な特異性のプロンプトを用いてテストされた:
ゼロショット連鎖思考(ユニバーサル): プロンプトに「ステップ・バイ・ステップで考えよう」と付け加えるだけでいい。
進行の証明(PDDLに特有): プランの正しさについて、例を挙げて一般的な説明を行う。
Blocksworldユニバーサル・アルゴリズム: あらゆるBlocksworld問題を解くための一般的なアルゴリズムを示す。
スタッキング・プロンプト ブロックワールド問題の特定のサブクラス(テーブル対スタック)に焦点を当てる。
語彙の積み重ね: ゴール状態の特定の構文形式にさらに絞り込む。
研究者たちは、これらのプロンプトを複雑さを増していく問題でテストすることで、LLMが例題で示された推論をどの程度一般化できるかを評価することを目指した。
主な調査結果を発表
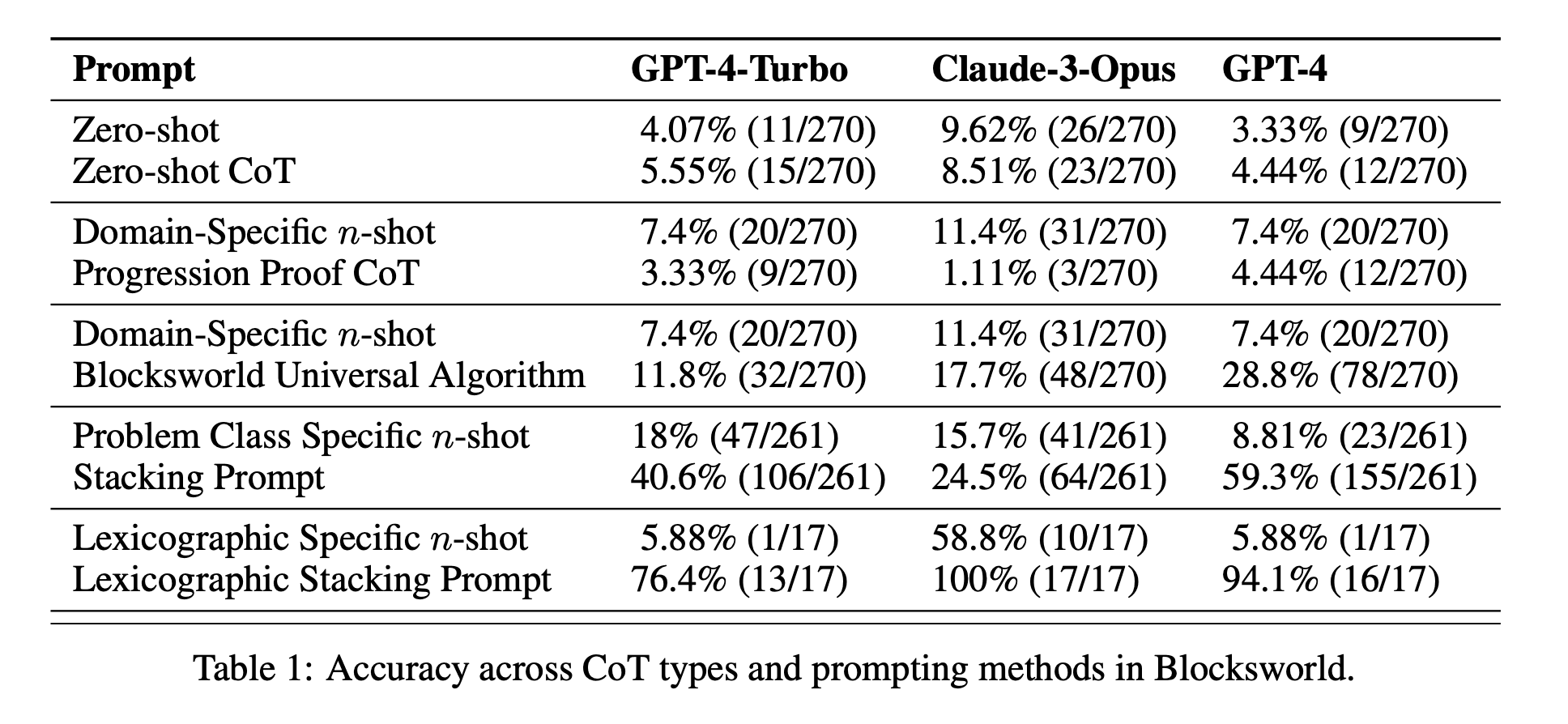
本研究の結果は、CoTプロンプトに関する多くの一般的な仮定を覆すものである:
CoTの効果は限定的: これまでの主張とは異なり、CoTプロンプトは、提供された例がクエリ問題と極めて類似している場合にのみ、大幅なパフォーマンス向上を示した。問題が例題に示された正確な形式から外れると、パフォーマンスは急激に低下した。
急速なパフォーマンス低下: 問題の複雑さが増すにつれて(関係するブロックの数で測定)、使用されたCoTプロンプトに関係なく、すべてのモデルの精度が劇的に低下した。これは、LLMが単純な例で示された推論を、より複雑なシナリオに拡張するのに苦労していることを示唆している。
一般的なプロンプトの無効性: 意外なことに、より一般的なCoTプロンプトは、推論例のない標準的なプロンプトよりも成績が悪いことが多かった。これは、CoTがLLMの一般化可能な問題解決ストラテジーの学習に役立つという考えと矛盾する。
特異性のトレードオフ: この研究では、非常に具体的なプロンプトが高い精度を達成できることがわかったが、それは非常に狭い問題のサブセットにおいてのみであった。このことは、パフォーマンスの向上とプロンプトの適用可能性との間に鋭いトレードオフがあることを浮き彫りにしている。
真のアルゴリズム学習の欠如: この結果は、LLMがCoTの例題から一般的なアルゴリズムの適用方法を学んでいないことを強く示唆している。その代わりに、LLMはパターンマッチングに頼っているようだが、これは新しい問題やより複雑な問題に直面するとすぐに破綻してしまう。
これらの知見は、CoTプロンプトをアプリケーションに活用しようとしているAIの専門家や企業にとって重要な意味を持つ。CoTは特定の狭いシナリオではパフォーマンスを向上させることができるが、多くの人が期待していた複雑な推論タスクの万能薬にはならない可能性があることを示唆している。
ブロックワールドを越えて調査を拡張する
研究者たちは、発見がBlocksworldのドメインに限定されないことを確認するため、これまでのCoT研究でよく使われてきたいくつかの合成問題ドメインに調査を拡大した:
コインフリップ コインを何度もひっくり返して、その状態を予測する課題。
LastLetterConcatenation: 与えられた単語の最後の文字の連結を必要とするテキスト処理タスク。
多段階算術: 複雑な算術式の簡略化を含む問題。
これらのドメインが選ばれたのは、Blocksworldと同様に、複雑さを増していく問題の生成が可能だからである。これらの追加実験の結果は、Blocksworldの結果と驚くほど一致した:
一般化の欠如: CoTプロンプトは、提供された例に非常に類似した問題でのみ改善を示した。問題の複雑さが増すにつれて、成績は急速に低下し、標準的なプロンプトと同等かそれ以下のレベルになった。
構文パターンマッチング: LastLetterConcatenationタスクでは、CoTプロンプトは解答の特定の構文的側面(正しい文字の使用など)を改善したが、単語数が増えるにつれて精度を維持できなかった。
完璧な中間ステップにもかかわらず失敗: 算数の課題では、モデルが1桁の演算をすべて完璧に解くことができても、より長い演算の列に汎化することはできなかった。
これらの結果は、現在のLLMはCoT例から真に一般化可能な推論戦略を学習していないという結論をさらに補強している。その代わりに、表面的なパターンマッチングに大きく依存しているように見えるが、これは実証例から逸脱した問題に直面したときに破綻する。
AI開発への示唆
この研究結果は、AI開発、特に複雑な推論や計画能力を必要とするアプリケーションに取り組む企業にとって重要な意味を持つ:
CoTの効果の再評価: この研究は、CoTプロンプトがLLMの一般的な推論能力を「解き放つ」という概念に疑問を投げかけている。AI開発者は、真のアルゴリズム思考や新しいシナリオへの汎化を必要とするタスクでCoTに頼ることには慎重であるべきである。
現在のLLMの限界: 多くの分野で優れた能力を発揮しているにもかかわらず、最先端のLLMは一貫性のある汎化可能な推論に苦戦している。このことは、ロバストな計画や多段階の問題解決を必要とするアプリケーションには、別のアプローチが必要であることを示唆している。
迅速なエンジニアリングのコスト: 特異性の高いCoTプロンプトは、狭い範囲の問題セットに対しては良い結果をもたらすが、特に一般化可能性が限られていることを考えると、このようなプロンプトを作成するために必要な人的労力は、その利点を上回る可能性がある。
評価指標の再考: この研究は、様々な複雑さと構造を持つ問題でAIモデルをテストすることの重要性を強調している。静的なテストセットだけに頼ると、モデルの真の推論能力を過大評価する可能性がある。
認識と現実のギャップ 一般的な言説ではしばしば擬人化される)LLMの推論能力の認識と、この研究で実証された実際の能力との間には大きな食い違いがある。
AI実務者への提言
このような洞察に基づき、LLMと協働するAIの実務家や企業に対する主な提言を以下に示す:
厳格な評価の実践:
さまざまな複雑さの問題を生成できるテストフレームワークを実装する。
静的なテストセットや、トレーニングデータに含まれる可能性のあるベンチマークだけに頼らないこと。
真の汎化を評価するために、さまざまな問題のバリエーションにわたってパフォーマンスを評価する。
CoTへの現実的な期待:
CoTプロンプティングは、一般化の限界を理解した上で、慎重に使用する。
CoTによるパフォーマンスの向上は、狭い問題セットに限られる可能性があることに注意してください。
迅速なエンジニアリングの労力と潜在的なパフォーマンスの向上とのトレードオフを考慮する。
ハイブリッド・アプローチ:
複雑な推論タスクについては、LLMを従来のアルゴリズム的アプローチや特化した推論モジュールと組み合わせることを検討する。
LLMの弱点であるアルゴリズム推論を補いつつ、LLMの長所(自然言語理解など)を活用できる方法を探る。
AIアプリケーションにおける透明性:
特に推論や計画作業を伴う場合には、AIシステムの限界を明確に伝える。
特にセーフティ・クリティカルなアプリケーションや、大きなリスクを伴うアプリケーションでは、LLMの能力を過大評価しないようにする。
研究開発の継続:
AIシステムの真の推論能力を向上させることを目的とした研究に投資する。
複雑なタスクにおいて、よりロバストな汎化をもたらす可能性のある代替アーキテクチャやトレーニング方法を探求する。
ドメイン固有の微調整:
狭くて明確に定義された問題領域については、領域固有のデータと推論パターンに基づいてモデルを微調整することを検討する。
このような微調整は、ドメイン内ではパフォーマンスを向上させるかもしれないが、ドメイン外では一般化しない可能性があることに注意しよう。
これらの提言に従うことで、AI実務者は、現在のLLMの推論能力を過大評価することに伴う潜在的な落とし穴を回避しながら、より堅牢で信頼性の高いAIアプリケーションを開発することができる。本研究から得られた知見は、急速に発展するAI分野において、批判的評価と現実的評価の重要性を再認識させる貴重なものとなった。
結論
計画タスクにおける思考連鎖型プロンプトに関するこの画期的な研究は、LLM能力に対する我々の理解に挑戦し、現在のAI開発手法の再評価を促すものである。複雑な問題への一般化におけるCoTの限界を明らかにすることで、AIアプリケーションにおけるより厳密なテストと現実的な期待の必要性を強調している。
AI実務者や企業にとって、これらの知見は、LLMの強みを特化した推論アプローチと組み合わせること、必要に応じてドメイン固有のソリューションに投資すること、AIシステムの限界について透明性を維持することの重要性を浮き彫りにしている。今後、AIコミュニティは、パターンマッチングと真のアルゴリズム推論のギャップを埋めることができる新しいアーキテクチャとトレーニング方法の開発に注力しなければならない。この研究は、LLMが目覚ましい進歩を遂げた一方で、人間のような推論能力を達成することは、AIの研究開発において現在進行中の課題であることを思い起こさせるものである。


