
チュートリアル抽出的要約のためのBERTの微調整方法



チュートリアル抽出的要約のためのBERTの微調整方法
原文:Skim AIの機械学習研究者、クリス・トラン![]()
1.はじめに
要約は自然言語処理における長年の課題である。文書の最も重要な情報を保持したまま、短い文書を生成するためには、重複する情報を避けながら、重要なポイントを正確に抽出できるモデルが必要である。幸いなことに、Transformerモデルや言語モデルのプリトレーニングなど、自然言語処理における最近の研究が要約の最先端を進んでいる。
この記事では、BERTの単純な変種であるBERTSUMについて、次のようなものから抽出的要約を行う。 事前訓練されたエンコーダによるテキスト要約 (Liuら、2019)。次に、低リソースデバイス向けに抽出的要約をさらに高速化、小型化するために、DistilBERTを微調整する(サンら、2019)とMobileBERT(孫ら、2019)、BERT の最近の 2 つのライトバージョン、および調査結果について議論する。
2.抽出的要約
要約には2種類ある: 抽象的 そして 抽出的要約.抽象的要約は基本的にキーポイントを書き換えることを意味するが、抽出的要約は文書から最も重要なスパン/センテンスを直接コピーすることによって要約を生成する。
抽象的な要約は、人間にとって難易度が高く、機械にとっても計算コストが高い。しかし、どちらの要約が良いかは、エンドユーザーの目的次第である。小論文を書くのであれば、抽象的要約の方がよい選択かもしれない。一方、研究をしていて、読んだ本の要約を素早く得る必要がある場合は、抽出的要約の方が役に立つだろう。
このセクションでは、抽出要約モデルのアーキテクチャについて説明する。BERT要約器には、BERTエンコーダーと要約分類器の2つの部分がある。
BERTエンコーダ

BERTSUMの概要アーキテクチャ
我々の BERT エンコーダは、マスクされた言語モデリングタスク(デブリンら、2018).抽出要約のタスクは文レベルでの2値分類問題である。各文に、その文を最終要約に含めるべきかどうかを示すラベル $y_i ⦅{0, 1}$ ⦆を割り当てたい。したがって、トークン [CLS] 各文の前にエンコーダーをフォワードパスした後、最後の隠れレイヤーの [CLS] トークンは文の表現として使われる。
要約分類器
各文章のベクトル表現を得た後、単純なフィードフォワード層を分類器として使い、各文章のスコアを返すことができる。この論文で著者は、単純な線形分類器、リカレント・ニューラル・ネットワーク、3層の小さなTransformerモデルを実験した。Transformer分類器が最も良い結果をもたらし、自己注意メカニズムによる文間の相互作用が最も重要な文を選択する上で重要であることを示している。
つまり、エンコーダーでは文書内のトークン間の相互作用を学習し、要約分類器では文間の相互作用を学習する。
3.要約をさらに速くする
トランスフォーマ・モデルは、ほとんどのNLPベンチマークで最先端の性能を達成しているが、その学習と予測には計算コストがかかる。要約をより軽量に、より高速に、低リソースデバイスで展開できるようにするために、私は、Transformerモデルを修正した。 ソースコード BERTエンコーダーをDistilBERTとMobileBERTに置き換えるために、BERTSUMの作者によって提供された。要約レイヤーはパッケージ化されていない。
以下は、これら3つのバリアントのトレーニング・ロスである: テンソルボード

BERT-baseより40%小さいにもかかわらず、DistilBERTの訓練損失はBERT-baseと同じである。以下の表は、CNN/DailyMailデータセットに対する性能、サイズ、およびフォワードパスの実行時間を示している:
| モデル | ルージュ1 | ルージュ2 | ルージュ・エル | 推論時間 | サイズ | パラメータ |
|---|---|---|---|---|---|---|
| バート・ベース | 43.23 | 20.24 | 39.63 | 1.65 s | 475 MB | 120.5 M |
| ディスティルベール | 42.84 | 20.04 | 39.31 | 925ミリ秒 | 310 MB | 77.4 M |
| モバイルベール | 40.59 | 17.98 | 36.99 | 609ミリ秒 | 128 MB | 30.8 M |
*標準的なGoogle Colabノートブック上のシングルGPUでのフォワードパスの平均実行時間
45%高速なDistilBERTは、BERT-baseとほぼ同じ性能である。MobileBERTは、BERT-baseの94%の性能を維持しながら、BERT-baseより4倍小さく、DistilBERTより2.5倍小さい。MobileBERTの論文では、SQuAD v1.1においてMobileBERTがDistilBERTを大幅に上回ることが示されている。しかし、ディスクサイズがわずか128MBのMobileBERTにとって、これは依然として印象的な結果である。
4.まとめよう
事前に訓練されたチェックポイント、トレーニングの詳細、セットアップの手順はすべて、以下のページでご覧いただけます。 このGitHubリポジトリ.さらに、MobileBERTエンコーダーを使用したBERTSUMのデモを展開した。
ウェブアプリ: https://extractive-summarization.herokuapp.com/
![]()
コード
![]()
インポートトーチ
from models.model_builder import ExtSummarizer
from ext_sum import summarize
# ロードモデル
model_type = 'mobilebert' #@param ['bertbase', 'distilbert', 'mobilebert'].
checkpoint = torch.load(f'checkpoints/{model_type}_ext.pt', map_location='cpu')
model = ExtSummarizer(checkpoint=checkpoint, bert_type=model_type, device='cpu')
# サマライズの実行
input_fp = 'raw_data/input.txt'
result_fp = '結果/summary.txt'
summary = summarize(input_fp, result_fp, model, max_length=3)
print(summary)
要約サンプル
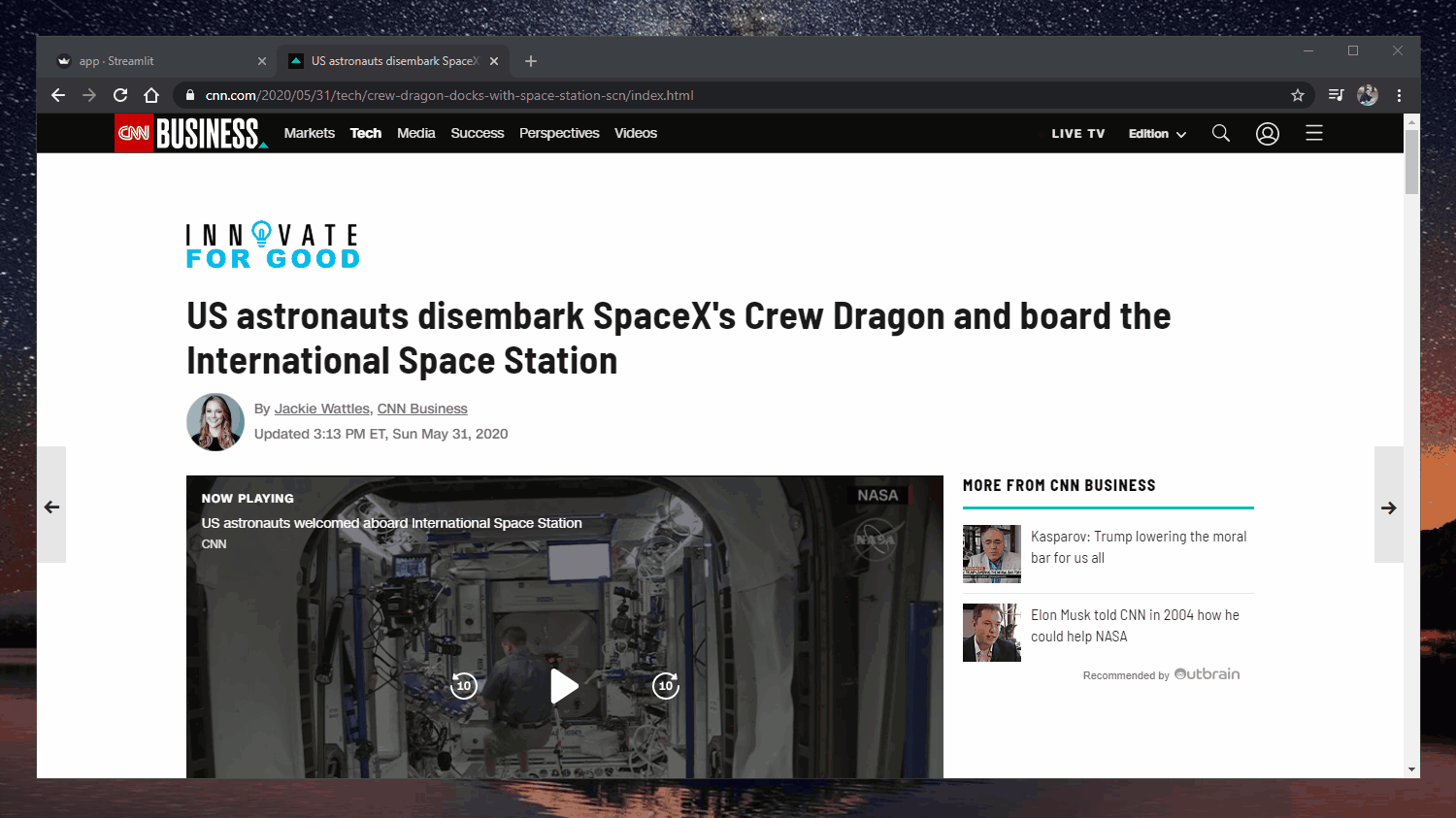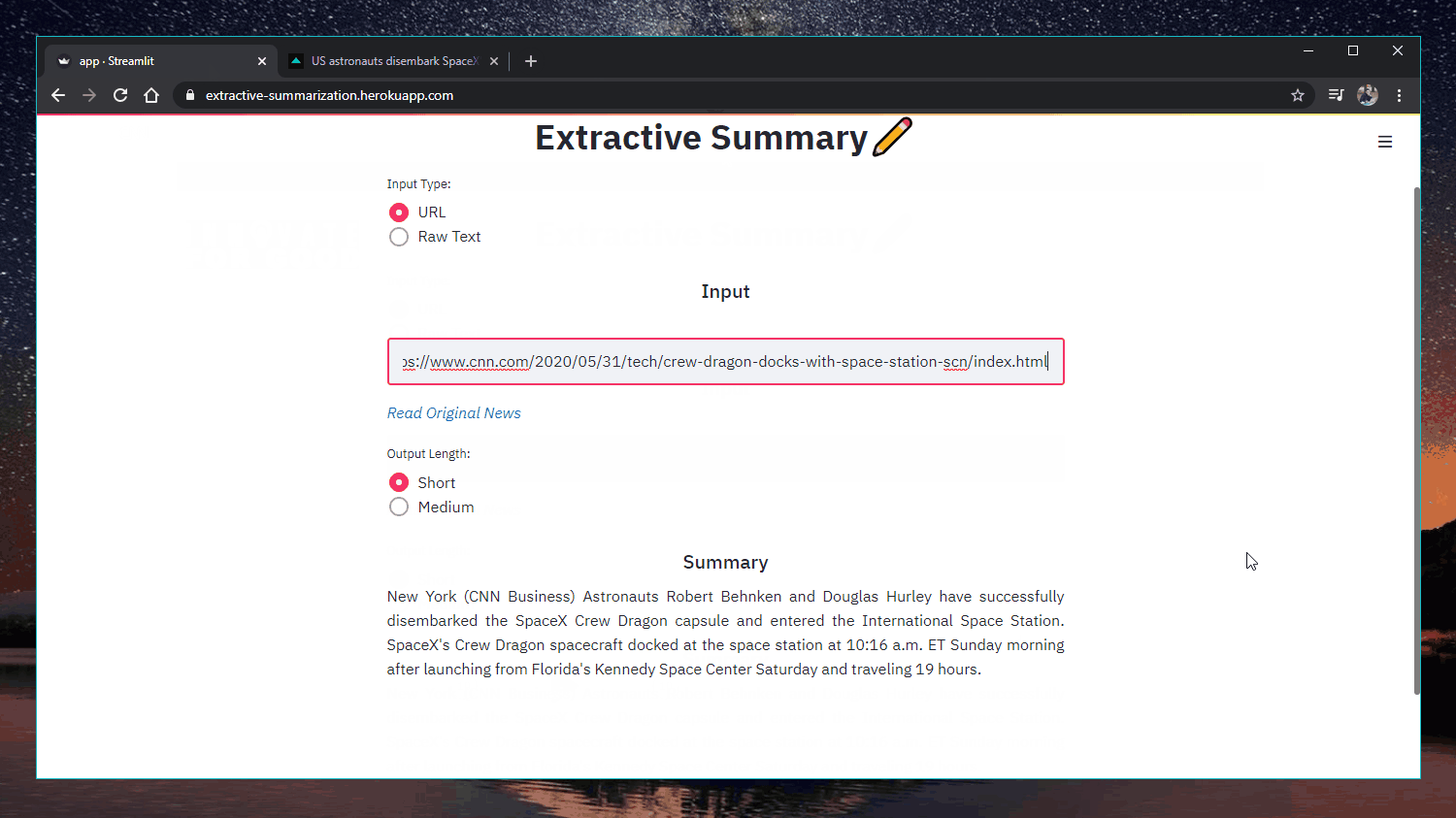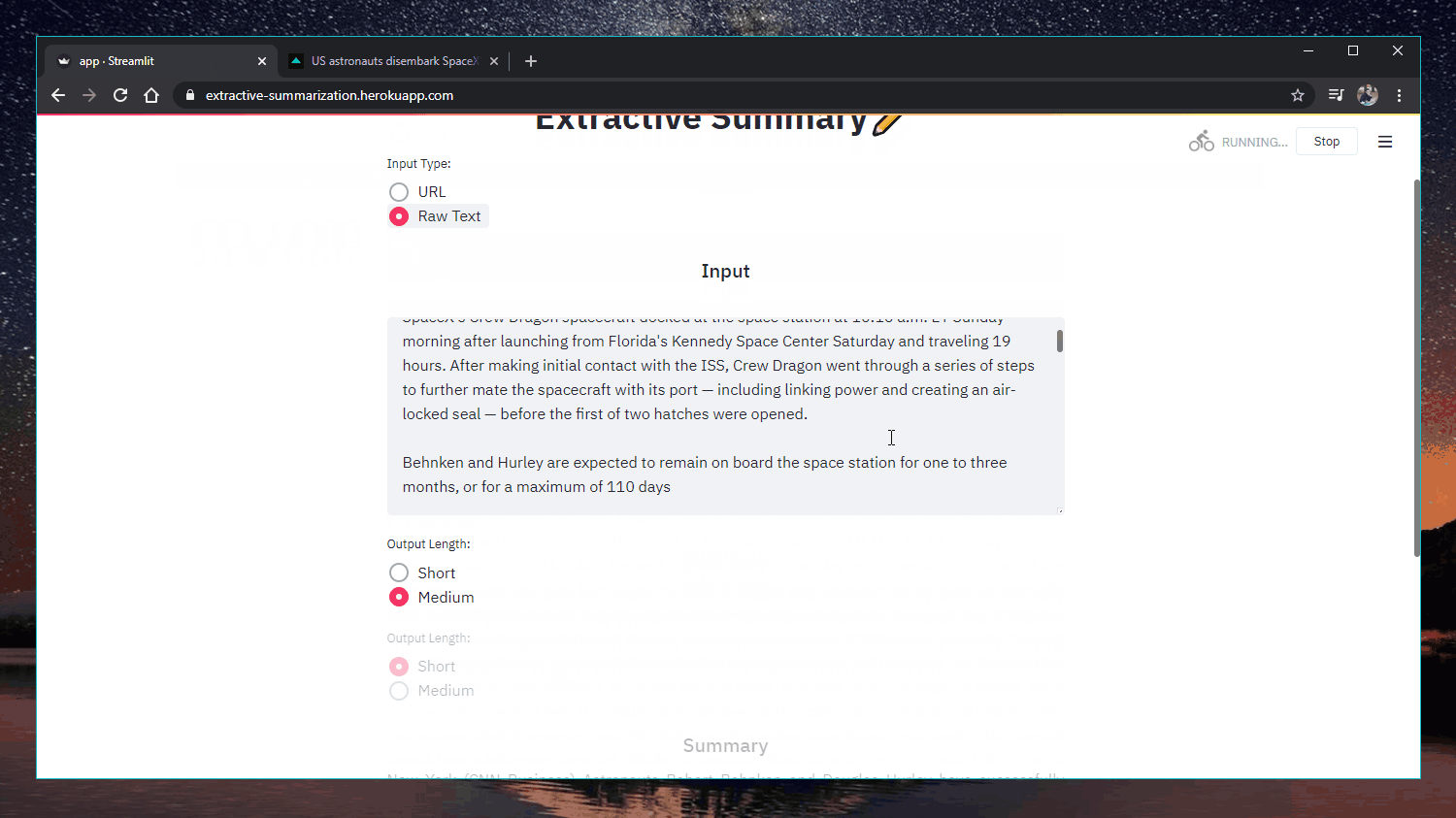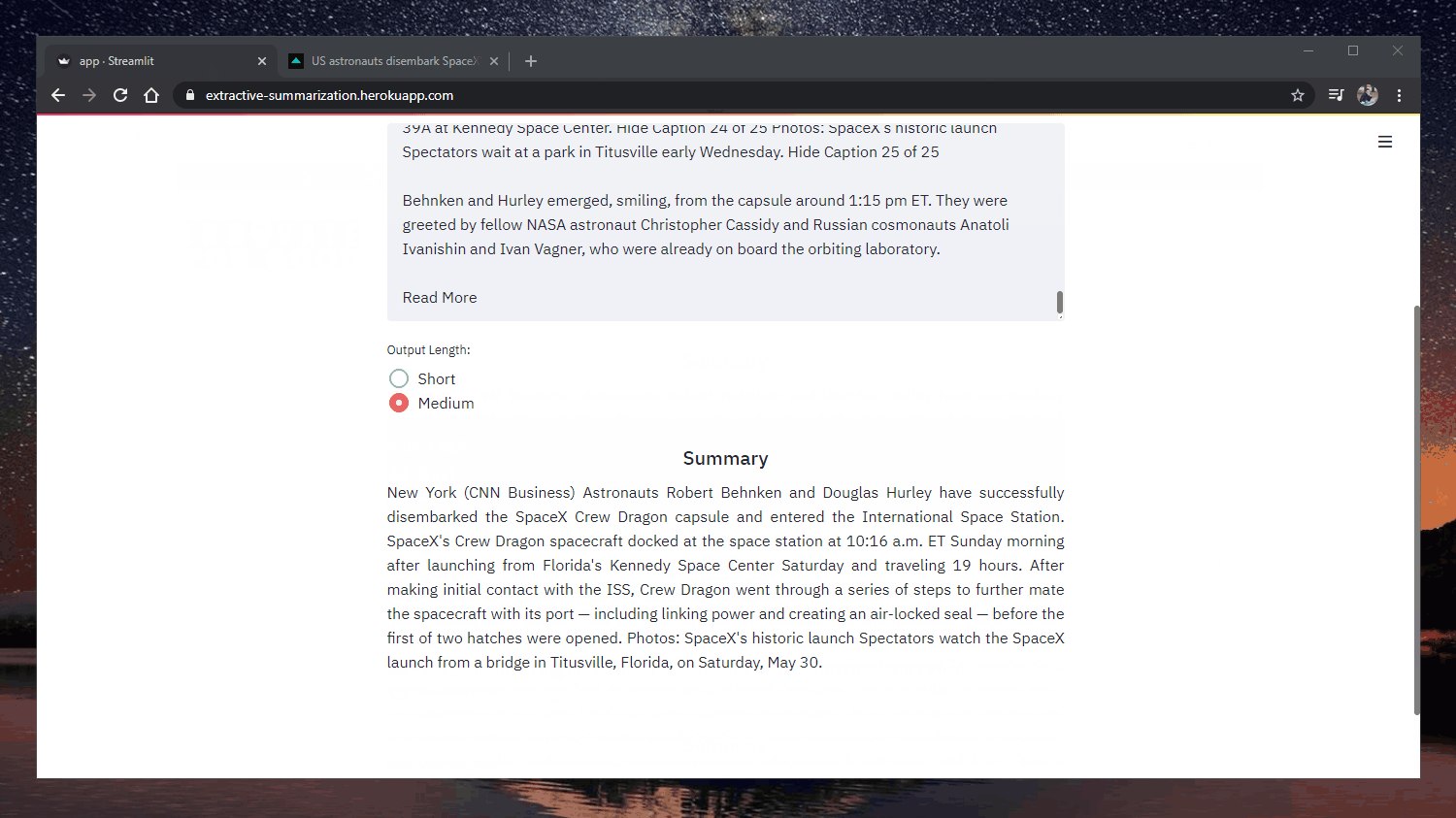
オリジナルだ: https://www.cnn.com/2020/05/22/business/hertz-bankruptcy/index.html
ハーツは破産を宣言することで、負債を再構築し、財務的に健全な企業に生まれ変わる一方で、事業を継続する意向だという。
ハーツは1918年に10数人の従業員で店を構えて以来、レンタカー業を営んできた。ハーツは、1918年に12台のフォード・モデル・ツで店を構えて以来、レンタカー業を営んできた。
世界大恐慌、第二次世界大戦中の米国自動車生産の事実上の停止、そして数々の石油価格高騰を乗り越えてきた。
そして数々の石油価格ショックも乗り越えてきた。「Covid-19の旅行需要への影響は突然かつ劇的であった。
コビッド19が旅行需要に与えた影響は突然かつ劇的であり、同社の収益と今後の予約に急激な減少をもたらした」と同社の声明は述べている。
5.結論
本稿では、BERTの単純な変形であるBERTSUMを用いて、論文からの抽出的要約を試みた。 事前訓練されたエンコーダによるテキスト要約 (Liuら、2019)。次に、低リソースデバイス向けに抽出的要約をさらに高速化・小型化するために、我々はCNN/DailyMailデータセット上でDistilBERT(Sanh et al.、2019)とMobileBERT(Sun et al.、2019)を微調整した。
DistilBERT は、抽出要約において BERT-base の性能を維持しながら、45% より小さい。MobileBERTは、BERT-baseより4倍小さく、2.7倍高速でありながら、94%の性能を維持している。
最後に、抽出的要約のためのMobileBERTのウェブアプリのデモを、以下のサイトで展開した。 https://extractive-summarization.herokuapp.com/.


