
Dobbiamo ripensare la catena del pensiero (CoT) che spinge l'AI&YOU #68



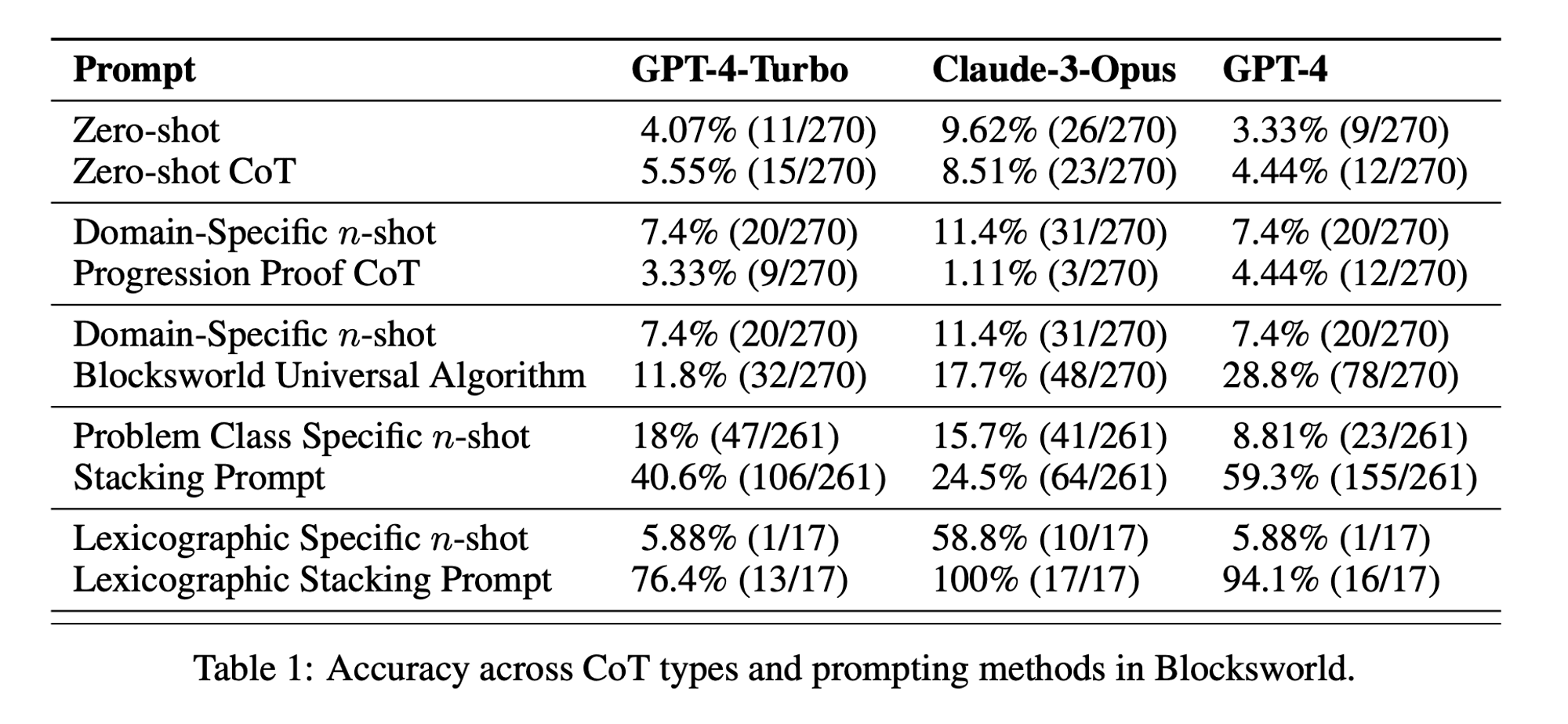
Statistica della settimana: Le prestazioni di CoT a colpo zero sono state solo 5,55% per GPT-4-Turbo, 8,51% per Claude-3-Opus e 4,44% per GPT-4. (documento "Catena di sconsideratezza?")
Il prompt Chain-of-Thought (CoT) è stato salutato come una svolta per sbloccare le capacità di ragionamento dei modelli linguistici di grandi dimensioni (LLM). Tuttavia, recenti ricerche hanno messo in discussione queste affermazioni e ci hanno spinto a rivedere la tecnica.
Nell'edizione di questa settimana di AI&YOU, esploriamo le intuizioni di tre blog che abbiamo pubblicato sull'argomento:
Dobbiamo ripensare la catena del pensiero (CoT) che spinge l'AI&YOU #68
I LLM dimostrano notevoli capacità di elaborazione e generazione del linguaggio naturale (NLP). Tuttavia, di fronte a compiti di ragionamento complessi, questi modelli possono faticare a produrre risultati accurati e affidabili. È qui che entra in gioco il Chain-of-Thought (CoT) prompting, una tecnica che mira a migliorare le capacità di problem solving dei LLM.
Un'avanzata ingegneria tempestiva è stata progettata per guidare i LLM attraverso un processo di ragionamento graduale. A differenza dei metodi di prompting standard che mirano a ottenere risposte dirette, il prompting CoT incoraggia il modello a generare fasi di ragionamento intermedie prima di arrivare a una risposta finale.
Il nucleo della CoT consiste nello strutturare le richieste di input in modo da suscitare una sequenza logica di pensieri da parte del modello. Scomponendo i problemi complessi in fasi più piccole e gestibili, la CoT tenta di consentire ai LLM di navigare attraverso percorsi di ragionamento intricati in modo più efficace.
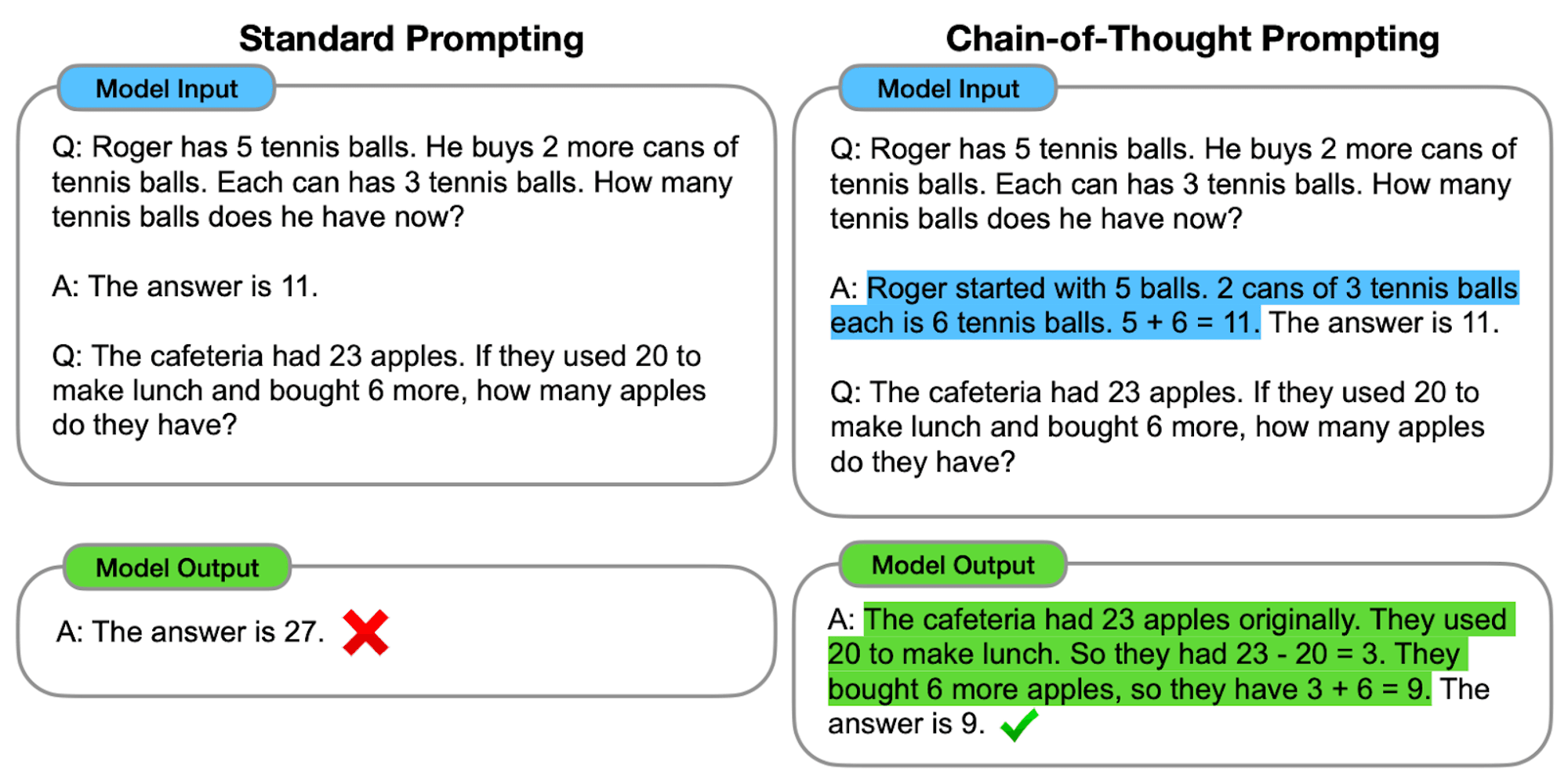
Come funziona la CoT
Nella sua essenza, la richiesta di CoT guida i modelli linguistici attraverso una serie di fasi intermedie di ragionamento prima di arrivare a una risposta finale. Questo processo prevede in genere:
Decomposizione del problema: Il compito complesso viene suddiviso in fasi più piccole e gestibili.
Ragionamento passo-passo: Il modello viene invitato a riflettere esplicitamente su ogni fase.
Progressione logica: Ogni passo si basa sul precedente, creando una catena di pensieri.
Disegno di conclusione: La risposta finale deriva dalle fasi di ragionamento accumulate.
Tipi di sollecitazione della CoT
La sollecitazione della catena di pensiero può essere attuata in vari modi, tra cui spiccano due tipi principali:
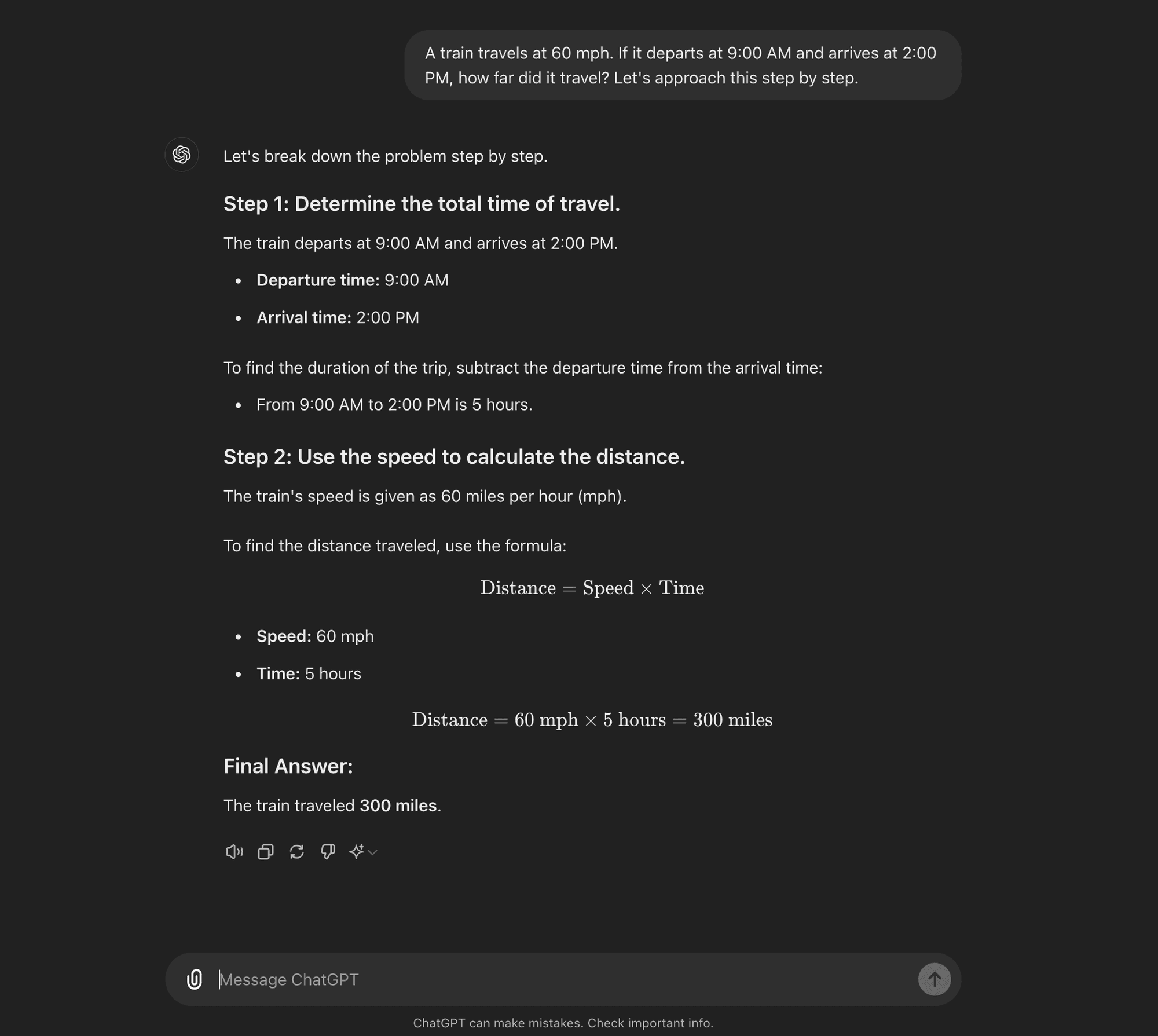
CoT a colpo zero: La CoT a colpo zero non richiede esempi specifici per il compito. Al contrario, utilizza un semplice prompt come "Affrontiamo la questione passo dopo passo" per incoraggiare il modello a scomporre il suo processo di ragionamento.****
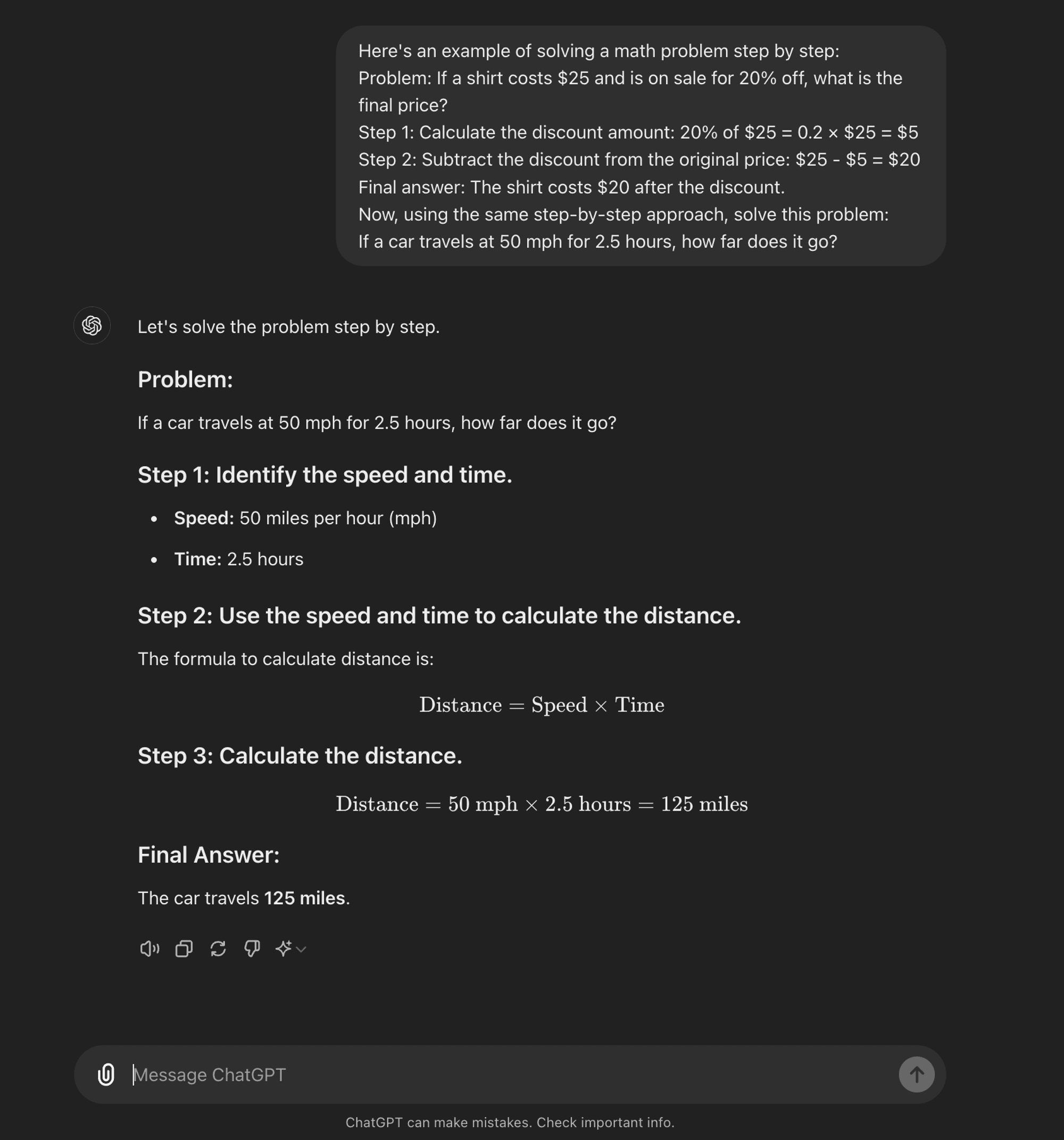
CoT a pochi colpi: La CoT a pochi colpi consiste nel fornire al modello un piccolo numero di esempi che dimostrano il processo di ragionamento desiderato. Questi esempi servono come modello da seguire per il modello quando affronta problemi nuovi e sconosciuti.
CoT a colpo zero
CoT a pochi colpi
Analisi del documento di ricerca sull'IA: "Catena di sconsideratezza?"
Ora che sapete che cos'è il prompting della CoT, possiamo immergerci in alcune ricerche recenti che mettono in discussione alcuni dei suoi benefici e offrono alcune indicazioni su quando è effettivamente utile.
Il documento di ricerca, intitolato "Catena di sconsideratezza? Un'analisi della CoT nella pianificazione," fornisce un esame critico dell'efficacia e della generalizzabilità del prompt della CoT. Come professionisti dell'IA, è fondamentale comprendere questi risultati e le loro implicazioni per lo sviluppo di applicazioni di IA che richiedono sofisticate capacità di ragionamento.

I ricercatori hanno scelto un dominio di pianificazione classico chiamato Blocksworld come terreno di prova principale. In Blocksworld, il compito è quello di riorganizzare un insieme di blocchi da una configurazione iniziale a una configurazione finale, utilizzando una serie di azioni di spostamento. Questo dominio è ideale per testare le capacità di ragionamento e di pianificazione perché:
Permette di generare problemi di complessità variabile.
Ha soluzioni chiare e verificabili dal punto di vista algoritmico.
È improbabile che sia molto rappresentato nei dati di formazione di LLM.
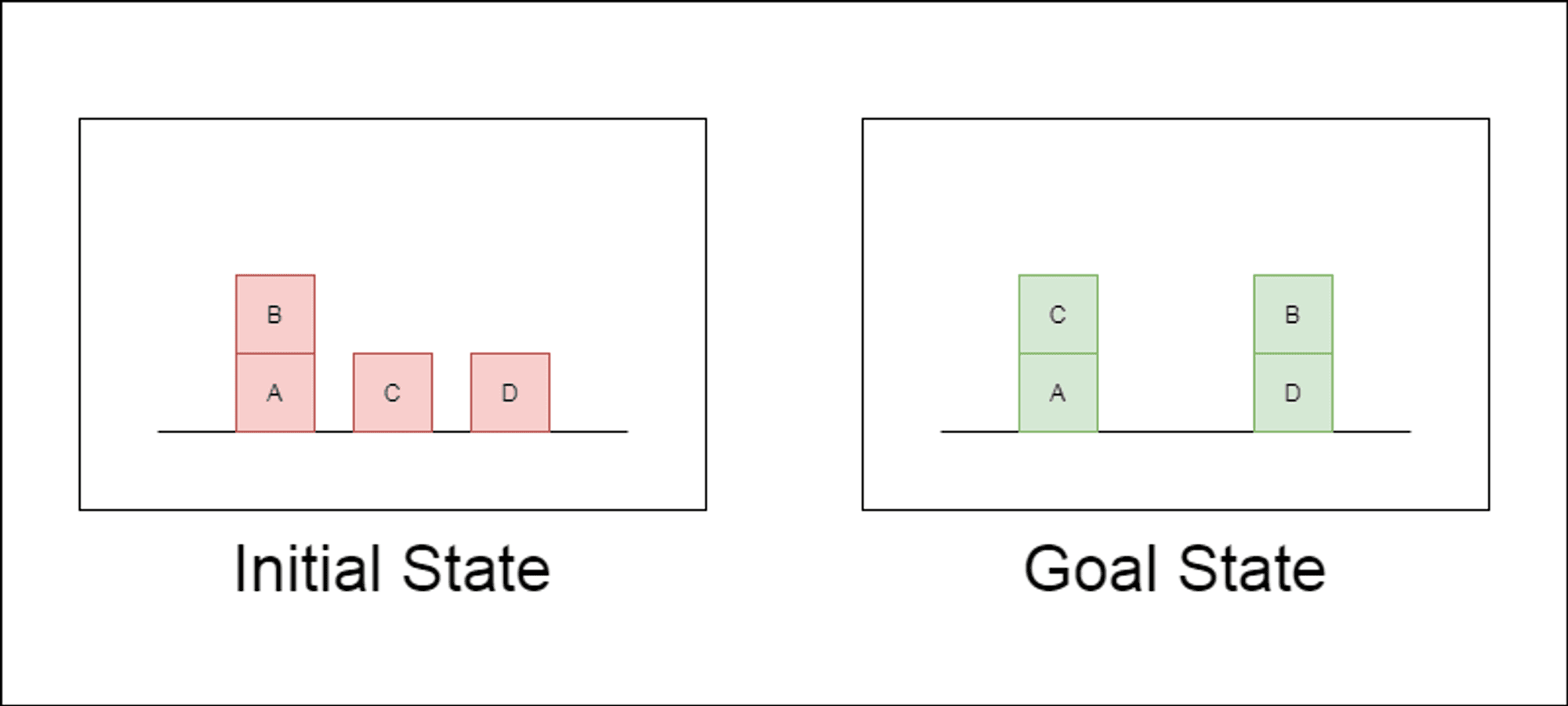
Lo studio ha esaminato tre LLM di ultima generazione: GPT-4, Claude-3-Opus e GPT-4-Turbo. Questi modelli sono stati testati utilizzando prompt di diversa specificità:
Catena di pensieri a colpo zero (Universale): Semplicemente aggiungendo "pensiamo passo dopo passo" al prompt.
Prova di progressione (specifica per la PDDL): Fornire una spiegazione generale della correttezza del piano con esempi.
Algoritmo universale di Blocksworld: Dimostrare un algoritmo generale per risolvere qualsiasi problema di Blocksworld.
Prompt di impilamento: Concentrarsi su una sottoclasse specifica di problemi di Blocksworld (table-to-stack).
Accatastamento lessicografico: Ulteriore restringimento a una particolare forma sintattica dello stato obiettivo.
Testando questi suggerimenti su problemi di complessità crescente, i ricercatori hanno voluto valutare quanto i LLM fossero in grado di generalizzare il ragionamento dimostrato negli esempi.
Svelati i risultati principali
I risultati di questo studio mettono in discussione molte delle ipotesi prevalenti sulla richiesta di CoT:
Efficacia limitata della CoT: Contrariamente a quanto affermato in precedenza, la richiesta di CoT ha mostrato miglioramenti significativi delle prestazioni solo quando gli esempi forniti erano estremamente simili al problema da interrogare. Non appena i problemi si discostano dall'esatto formato mostrato negli esempi, le prestazioni calano drasticamente.
Rapido degrado delle prestazioni: Con l'aumentare della complessità dei problemi (misurata in base al numero di blocchi coinvolti), l'accuratezza di tutti i modelli è diminuita drasticamente, indipendentemente dal prompt CoT utilizzato. Ciò suggerisce che i LLM faticano a estendere il ragionamento dimostrato in esempi semplici a scenari più complessi.
Inefficacia dei suggerimenti generali: Sorprendentemente, i suggerimenti più generali della CoT hanno spesso dato risultati peggiori rispetto a quelli standard senza esempi di ragionamento. Questo contraddice l'idea che la CoT aiuti i LLM ad apprendere strategie generalizzabili di risoluzione dei problemi.
Trade-off di specificità: Lo studio ha rilevato che i prompt altamente specifici possono raggiungere un'elevata accuratezza, ma solo su un sottoinsieme molto ristretto di problemi. Ciò evidenzia un forte compromesso tra l'aumento delle prestazioni e l'applicabilità del prompt.
Mancanza di un vero apprendimento algoritmico: I risultati suggeriscono fortemente che i LLM non stanno imparando ad applicare procedure algoritmiche generali dagli esempi di CoT. Sembrano invece affidarsi alla corrispondenza dei modelli, che si rompe rapidamente quando si trovano di fronte a problemi nuovi o più complessi.
Questi risultati hanno implicazioni significative per i professionisti dell'intelligenza artificiale e per le aziende che desiderano sfruttare i prompt della CoT nelle loro applicazioni. Suggeriscono che, sebbene la CoT possa aumentare le prestazioni in alcuni scenari ristretti, potrebbe non essere la panacea per i compiti di ragionamento complessi che molti avevano sperato.
Implicazioni per lo sviluppo dell'IA
I risultati di questo studio hanno implicazioni significative per lo sviluppo dell'IA, in particolare per le imprese che lavorano su applicazioni che richiedono capacità complesse di ragionamento o pianificazione:
Rivalutazione dell'efficacia della CTF: Gli sviluppatori di IA dovrebbero essere cauti nell'affidarsi alla CoT per compiti che richiedono un vero pensiero algoritmico o la generalizzazione a scenari nuovi.
Limiti degli attuali LLM: Per le applicazioni che richiedono una solida pianificazione o la risoluzione di problemi in più fasi possono essere necessari approcci alternativi.
Il costo dell'ingegneria tempestiva: Sebbene i suggerimenti di CoT altamente specifici possano dare buoni risultati per insiemi di problemi ristretti, l'impegno umano richiesto per creare questi suggerimenti può superare i benefici, soprattutto in considerazione della loro limitata generalizzabilità.
Ripensare le metriche di valutazione: Affidarsi esclusivamente a set di test statici può portare a sovrastimare le reali capacità di ragionamento di un modello.
Il divario tra percezione e realtà: C'è una discrepanza significativa tra le capacità di ragionamento percepite dei LLM (spesso antropomorfizzate nel discorso popolare) e le loro reali capacità, come dimostrato in questo studio.
Raccomandazioni per gli operatori dell'IA:
Valutazione: Implementare diversi framework di test per valutare l'effettiva generalizzazione attraverso la complessità dei problemi.
Utilizzo del CoT: Applicare la sollecitazione a catena di pensieri con giudizio, riconoscendo i suoi limiti nella generalizzazione.
Soluzioni ibride: Considerare la possibilità di combinare gli LLM con algoritmi tradizionali per compiti di ragionamento complessi.
Trasparenza: Comunicare chiaramente i limiti del sistema di IA, soprattutto per i compiti di ragionamento o di pianificazione.
Focus R&S: Investire nella ricerca per migliorare le reali capacità di ragionamento dei sistemi di IA.
Messa a punto: Considerare la messa a punto specifica del dominio, ma essere consapevoli dei potenziali limiti di generalizzazione.
Per gli operatori dell'IA e le imprese, questi risultati evidenziano l'importanza di combinare i punti di forza dell'LLM con approcci di ragionamento specializzati, di investire in soluzioni specifiche per il dominio, ove necessario, e di mantenere la trasparenza sui limiti dei sistemi di IA. La comunità dell'IA deve concentrarsi sullo sviluppo di nuove architetture e metodi di addestramento in grado di colmare il divario tra la corrispondenza dei modelli e il vero ragionamento algoritmico.
10 migliori tecniche di sollecitazione per i LLM
Questa settimana esploriamo anche dieci delle tecniche di prompting più potenti e comuni, offrendo approfondimenti sulle loro applicazioni e sulle migliori pratiche.

I suggerimenti ben progettati possono migliorare significativamente le prestazioni di un LLM, consentendo di ottenere risultati più accurati, pertinenti e creativi. Che siate sviluppatori di IA esperti o alle prime armi con gli LLM, queste tecniche vi aiuteranno a sbloccare il pieno potenziale dei modelli di IA.
Per saperne di più su ciascuno di essi, visitate il blog completo.
Grazie per aver dedicato del tempo alla lettura di AI & YOU!
Per ulteriori contenuti sull'IA aziendale, tra cui infografiche, statistiche, guide, articoli e video, seguite Skim AI su LinkedIn
Siete un fondatore, un CEO, un Venture Capitalist o un investitore alla ricerca di servizi di consulenza sull'IA, di sviluppo frazionario dell'IA o di due diligence? Ottenete la guida necessaria per prendere decisioni informate sulla strategia di prodotto AI della vostra azienda e sulle opportunità di investimento.
Realizziamo soluzioni AI personalizzate per aziende sostenute da Venture Capital e Private Equity nei seguenti settori: Tecnologia medica, aggregazione di notizie e contenuti, produzione di film e foto, tecnologia educativa, tecnologia legale, Fintech e criptovalute.


