
Come la vostra azienda dovrebbe utilizzare i database vettoriali per le sue applicazioni LLM nel 2024



Negli ultimi anni, i modelli linguistici di grandi dimensioni (LLM) hanno rivoluzionato il panorama delle applicazioni AI aziendali. Questi potenti modelli di apprendimento automatico hanno dimostrato notevoli capacità di elaborazione, generazione e comprensione del linguaggio naturale, aprendo un mondo di possibilità per le aziende di tutti i settori. Tuttavia, man mano che gli LLM diventano sempre più sofisticati ed esigenti, le aziende devono affrontare la sfida di archiviare e recuperare in modo efficiente le grandi quantità di dati necessari per addestrare e far funzionare questi modelli. I database vettoriali sono la chiave per sbloccare il pieno potenziale dei modelli LLM. LLM in impresa Applicazioni AI.
Conoscere i database vettoriali
I database vettoriali sono database specializzati progettati per memorizzare e gestire dati vettoriali ad alta dimensione. A differenza dei database tradizionali che memorizzano i dati come righe e colonne, i database vettoriali rappresentano i dati come vettori numerici in uno spazio vettoriale. Ogni punto di dati, come un documento di testo o un'immagine, viene convertito in un embedding vettoriale, una rappresentazione numerica densa e a lunghezza fissa che cattura il significato semantico dei dati.
Come funzionano i database vettoriali
Alla base dei database vettoriali c'è il concetto di embedding vettoriale e di spazio vettoriale. Gli embeddings vettoriali sono generati utilizzando modelli di apprendimento automatico, come word2vec o BERT, che imparano a mappare i punti di dati in uno spazio vettoriale ad alta dimensione. In questo spazio vettoriale, i punti di dati simili sono rappresentati da vettori vicini tra loro, mentre i punti di dati dissimili sono più distanti.
I database vettoriali consentono di effettuare efficienti operazioni di ricerca per similarità e vicinanza. Quando viene fornito un vettore di interrogazione, il database è in grado di trovare rapidamente i vettori più simili nello spazio vettoriale utilizzando metriche di distanza come la somiglianza coseno o la distanza euclidea. Ciò consente di recuperare in modo rapido e accurato i dati pertinenti in base alla somiglianza semantica piuttosto che alle corrispondenze esatte delle parole chiave.
Vantaggi dell'utilizzo di database vettoriali per applicazioni LLM
I database vettoriali offrono diversi vantaggi rispetto ai database tradizionali quando si tratta di supportare applicazioni LLM:
Ricerca semantica: I database vettoriali consentono la ricerca semantica, permettendo ai LLM di recuperare le informazioni in base al significato e al contesto dell'interrogazione, anziché affidarsi alle corrispondenze esatte delle parole chiave. Questo porta a risultati più pertinenti e accurati.
Scalabilità: I database vettoriali sono progettati per gestire in modo efficiente i dati vettoriali su larga scala. Possono memorizzare ed elaborare milioni o addirittura miliardi di vettori ad alta dimensionalità, il che li rende ideali per gli enormi insiemi di dati richiesti per l'addestramento e il funzionamento dei LLM.
Tempi di interrogazione più rapidi: Gli algoritmi specializzati di indicizzazione e ricerca utilizzati dai database vettoriali consentono tempi di interrogazione rapidissimi, anche su grandi insiemi di dati. Ciò è fondamentale per le applicazioni LLM in tempo reale che richiedono un accesso rapido alle informazioni rilevanti.
Miglioramento della precisione: Sfruttando le informazioni semantiche catturate nelle incorporazioni vettoriali, i database vettoriali possono aiutare i LLM a fornire risposte più accurate e contestualmente rilevanti alle interrogazioni degli utenti.
Mentre le aziende cercano di sfruttare la potenza degli LLM nelle loro applicazioni di intelligenza artificiale, i database vettoriali emergono come uno strumento essenziale per l'archiviazione e il recupero efficiente dei dati.

LLM e database vettoriali: Un'accoppiata perfetta per l'IA aziendale
Il successo delle LLM dipende in larga misura dalla qualità e dall'accessibilità dei dati su cui vengono addestrate. È qui che entrano in gioco i database vettoriali, che offrono una soluzione potente per archiviare e recuperare le grandi quantità di dati richieste dai LLM.
Il ruolo dei dati nell'addestramento e nella messa a punto degli LLM
Gli LLM vengono addestrati su enormi set di dati contenenti miliardi di parole, consentendo loro di apprendere le complessità del linguaggio e di sviluppare una profonda comprensione del contesto e del significato. Una volta preaddestrati, gli LLM possono essere perfezionati su dati specifici per il settore, per adattarsi a casi d'uso e industrie particolari. La qualità e la pertinenza di questi dati hanno un impatto diretto sulle prestazioni e sull'accuratezza delle LLM nelle applicazioni di IA aziendali.
Le sfide dell'utilizzo di database tradizionali per l'archiviazione e il recupero dei dati di LLM
I database tradizionali, come quelli relazionali, non sono adatti a gestire i dati non strutturati e ad alta dimensionalità richiesti dai LLM. Questi database devono affrontare le seguenti sfide:
Scalabilità: I database tradizionali hanno spesso problemi di prestazioni quando si tratta di insiemi di dati su larga scala, rendendo difficile l'archiviazione e il recupero delle enormi quantità di dati necessari per la formazione e il funzionamento del LLM.
Ricerca inefficiente: La ricerca basata sulle parole chiave nei database tradizionali non riesce a cogliere il significato semantico e il contesto dei dati, portando a risultati irrilevanti o incompleti quando vengono interrogati dai LLM.
Mancanza di flessibilità: Lo schema rigido dei database tradizionali rende difficile accogliere i tipi di dati e le strutture diverse e in evoluzione associate ai LLM.
Come i database vettoriali superano queste sfide
I database vettoriali sono stati progettati specificamente per risolvere i limiti dei database tradizionali quando si tratta di supportare gli LLM:
Ricerca di similarità efficiente per il recupero di dati context-aware: Rappresentando i dati come vettori in uno spazio ad alta dimensione, i database vettoriali consentono una ricerca di similarità rapida e accurata. I LLM sono in grado di recuperare le informazioni rilevanti in base al significato semantico della query, garantendo risposte più adeguate al contesto.
Scalabilità per la gestione di grandi insiemi di dati: I database vettoriali sono costruiti per gestire in modo efficiente enormi quantità di dati vettoriali. Possono scalare orizzontalmente su più macchine, consentendo l'archiviazione e l'elaborazione di miliardi di incorporazioni vettoriali richieste dagli LLM.
Esempi reali di LLM che sfruttano i database vettoriali
Diverse applicazioni di IA aziendali di rilievo hanno integrato con successo gli LLM con i database vettoriali per migliorare le prestazioni e l'efficienza:
GPT-4 di OpenAI e i database di Anthropic: OpenAI e Anthropic utilizzano database vettoriali per memorizzare e recuperare le vaste basi di conoscenza che alimentano i loro LLM all'avanguardia, consentendo una generazione del linguaggio più contestuale e accurata.
Ricerca aziendale e gestione della conoscenza: Aziende come Microsoft e Google utilizzano i database vettoriali per migliorare i loro sistemi di ricerca e di gestione della conoscenza, consentendo ai dipendenti di trovare informazioni pertinenti in modo rapido e semplice utilizzando query in linguaggio naturale.
Assistenza clienti e chatbot: Le aziende utilizzano database vettoriali per memorizzare e recuperare i dati dei clienti, le informazioni sui prodotti e le cronologie delle conversazioni, consentendo ai chatbot alimentati da LLM di fornire un'assistenza clienti più personalizzata ed efficiente.
Identificare i casi d'uso dei database vettoriali nelle applicazioni LLM
Prima di implementare un database vettoriale, è fondamentale identificare i casi d'uso specifici in cui può fornire il massimo valore per le applicazioni di IA aziendali. La ricerca semantica e il recupero delle informazioni è un'area in cui i database vettoriali eccellono, consentendo agli utenti di trovare informazioni pertinenti utilizzando query in linguaggio naturale. Rappresentando documenti, immagini e altri dati come vettori, gli LLM possono recuperare i risultati più simili dal punto di vista semantico, migliorando l'accuratezza e la pertinenza dei risultati della ricerca.
Un altro caso d'uso chiave è la generazione aumentata del reperimento, in cui i LLM possono generare risposte più accurate e contestualmente rilevanti integrandosi con i database vettoriali. Durante il processo di generazione, il LLM può recuperare informazioni rilevanti dal database vettoriale in base alla query in ingresso, migliorando la coerenza e la correttezza fattuale del testo generato.
Anche i sistemi di personalizzazione e raccomandazione possono trarre grandi vantaggi dai database vettoriali. Rappresentando le preferenze dell'utente, i comportamenti e le caratteristiche degli oggetti come vettori, i LLM possono generare raccomandazioni altamente mirate, suggerimenti di contenuti e risultati specifici per l'utente. Ciò si ottiene calcolando la somiglianza tra i vettori degli utenti e degli oggetti.
Infine, i database vettoriali possono essere utilizzati per la gestione della conoscenza e l'organizzazione dei contenuti. Le aziende possono sfruttare i database vettoriali per organizzare e gestire grandi volumi di dati non strutturati, come documenti, relazioni e contenuti multimediali. Raggruppando vettori simili, le aziende possono categorizzare e taggare automaticamente i contenuti, rendendoli più facili da scoprire e navigare.
Scegliere il database vettoriale più adatto alle proprie esigenze
La scelta del database vettoriale appropriato è fondamentale per il successo delle applicazioni di intelligenza artificiale aziendali. Quando si valutano le diverse soluzioni di database vettoriali, bisogna considerare i compromessi tra le opzioni open-source e quelle proprietarie. I database vettoriali open-source offrono flessibilità, personalizzazione e convenienza. Hanno comunità attive, aggiornamenti regolari e un'ampia documentazione. D'altro canto, le soluzioni proprietarie, spesso fornite da piattaforme cloud o da fornitori specializzati, offrono servizi gestiti, assistenza di livello aziendale e una perfetta integrazione con altri strumenti del loro ecosistema. Tuttavia, possono comportare costi più elevati e rischi di vendor lock-in.
La scalabilità e le prestazioni sono fattori critici da valutare quando si sceglie un database vettoriale. Valutate la capacità del database di gestire la scala dei vostri dati, sia in termini di capacità di archiviazione che di prestazioni di interrogazione. Cercate soluzioni in grado di elaborare in modo efficiente milioni o miliardi di vettori ad alta dimensionalità. Considerate gli algoritmi di indicizzazione e di ricerca del database, come la ricerca approssimata del vicino (ANN), che può accelerare in modo significativo la ricerca di similarità su grandi insiemi di dati. Inoltre, valutate le opzioni di scalabilità orizzontale e verticale del database per assicurarvi che possa crescere con i vostri dati e la vostra base di utenti.
La facilità di integrazione è un'altra considerazione importante. Verificate la capacità del database vettoriale di integrarsi con lo stack tecnologico esistente, compresi i quadri LLM, pipeline di dati e applicazioni a valle. Cercate database che offrano API, SDK e connettori per i linguaggi di programmazione e i framework più diffusi, per facilitare l'integrazione e la manutenzione da parte del team di sviluppo.
Infine, date la priorità ai database vettoriali con comunità attive, documentazione completa e canali di supporto reattivi. Una comunità forte garantisce l'accesso a un aiuto tempestivo, alla correzione di bug e agli aggiornamenti delle funzionalità. Valutate l'ecosistema di strumenti, plugin e integrazioni del database, perché un ecosistema ricco può accelerare lo sviluppo, fornire funzionalità aggiuntive e facilitare l'integrazione con altri sistemi aziendali.

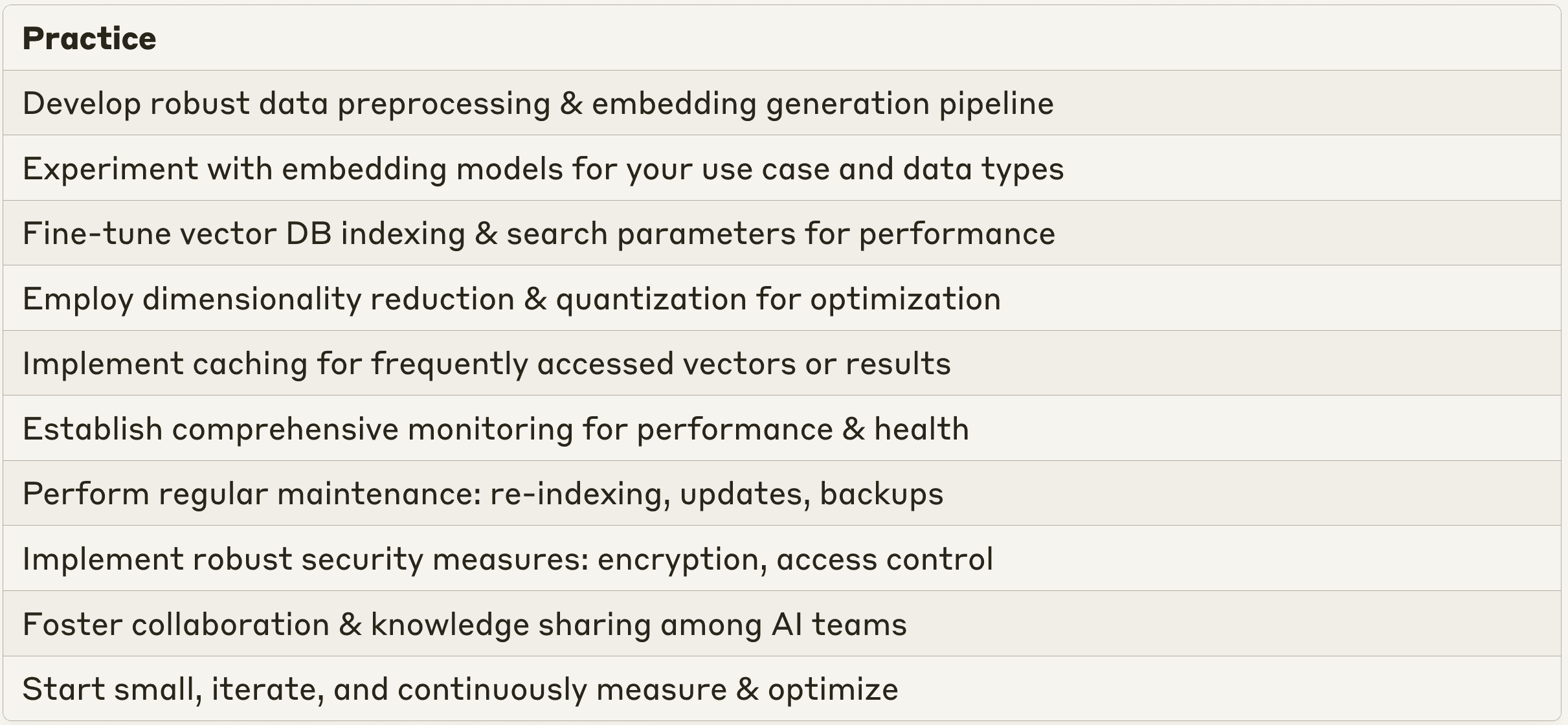
Le migliori pratiche per integrare i database vettoriali con le applicazioni LLM
Per garantire un'implementazione fluida ed efficace dei database vettoriali nelle applicazioni di intelligenza artificiale aziendali, è necessario seguire diverse best practice. Innanzitutto, sviluppare una solida pipeline di pre-elaborazione dei dati per pulire, normalizzare e trasformare i dati grezzi in un formato adatto alla generazione di embedding vettoriali. Sperimentate diversi modelli e tecniche di embedding per trovare l'approccio più appropriato per il vostro caso d'uso specifico e per i tipi di dati. Mettere a punto i modelli di embedding pre-addestrati sui dati specifici del vostro dominio per catturare la semantica e le relazioni uniche nel contesto della vostra azienda. Implementare i controlli di qualità dei dati e le fasi di convalida per garantire la coerenza e l'affidabilità delle incorporazioni vettoriali.
L'ottimizzazione delle query e la messa a punto delle prestazioni sono essenziali per un uso efficiente dei database vettoriali. Per trovare un equilibrio tra velocità e precisione delle interrogazioni, è necessario regolare con precisione i parametri di indicizzazione e di ricerca del database vettoriale, come il numero di vicini, il raggio di ricerca o gli algoritmi di clustering. Utilizzate tecniche come la riduzione della dimensionalità per ridurre le dimensioni dei vettori preservandone le informazioni semantiche, migliorando l'efficienza di archiviazione e le prestazioni delle query. Utilizzare metodi di quantizzazione, come la quantizzazione del prodotto o la compressione vettoriale, per ottimizzare ulteriormente la memorizzazione e il recupero dei vettori. Implementare meccanismi di caching per memorizzare i vettori o i risultati delle ricerche più frequenti, riducendo la latenza delle interrogazioni ripetute.
Il monitoraggio e la manutenzione sono fondamentali per garantire il buon funzionamento del database dei vettori. Stabilite un sistema di monitoraggio completo per tenere traccia delle prestazioni, della disponibilità e della salute del vostro database vettoriale. Monitorate le metriche chiave come la latenza delle query, il throughput e i tassi di errore. Impostate avvisi e notifiche per identificare e risolvere in modo proattivo eventuali colli di bottiglia delle prestazioni, limitazioni delle risorse o anomalie. Eseguire regolari attività di manutenzione, tra cui reindicizzazione, aggiornamenti dei dati e backup, per garantire l'integrità e la freschezza dei dati vettoriali. Valutare e ottimizzare continuamente le prestazioni del database vettoriale in base ai modelli di utilizzo reali e al feedback degli utenti. Intervenite sulle strategie di indicizzazione, sugli algoritmi di ricerca e sulle configurazioni hardware, se necessario.
La sicurezza e il controllo degli accessi sono fondamentali quando si tratta di dati aziendali sensibili. Implementate solide misure di sicurezza per proteggere la riservatezza, l'integrità e la disponibilità dei vostri dati vettoriali. Applicate meccanismi di crittografia, autenticazione e controllo degli accessi per salvaguardare le informazioni sensibili. Definite politiche di accesso e permessi granulari per garantire che solo gli utenti e le applicazioni autorizzate possano accedere e manipolare il database del vettore. Verificate ed esaminate regolarmente i registri di accesso per individuare e prevenire tentativi di accesso non autorizzati o attività sospette.
Infine, la promozione di una cultura di collaborazione e condivisione delle conoscenze tra i team di IA è essenziale per il successo dell'implementazione dei database vettoriali. Incoraggiate lo scambio di best practice, lezioni apprese e idee innovative relative ai database vettoriali e alle applicazioni LLM. Istituite forum interni, workshop o hackathon per promuovere la sperimentazione, lo sviluppo delle competenze e la collaborazione interfunzionale sulle tecnologie dei database vettoriali. Partecipare a comunità esterne, conferenze ed eventi di settore per rimanere informati sugli ultimi progressi, sui casi d'uso e sulle best practice dei database vettoriali e dell'IA aziendale.
Seguendo queste best practice e tenendo conto dei requisiti specifici della vostra azienda, potrete implementare con successo i database vettoriali e sfruttare appieno il potenziale delle vostre applicazioni LLM. Ricordate di iniziare in piccolo, di iterare frequentemente e di misurare e ottimizzare continuamente le prestazioni del vostro database vettoriale per garantire che offra il massimo valore alla vostra azienda.
Il futuro dei database vettoriali nell'IA aziendale
Con il continuo progresso della tecnologia dei database vettoriali, possiamo aspettarci di vedere una pletora di applicazioni nuove e innovative nell'IA aziendale:
Creazione di contenuti personalizzati: I LLM alimentati da database vettoriali possono generare contenuti altamente personalizzati, come articoli, relazioni e materiali di marketing, adattati alle preferenze e al contesto dei singoli utenti.
Elaborazione intelligente dei documenti: I database vettoriali possono consentire la classificazione, l'indicizzazione e l'estrazione automatica di informazioni chiave da grandi volumi di documenti non strutturati, snellendo i flussi di lavoro e migliorando i processi decisionali.
Assistenti AI multilingue: Incorporando le incorporazioni vettoriali di più lingue, le aziende possono sviluppare assistenti AI in grado di comprendere e rispondere agli utenti nella loro lingua madre, abbattendo le barriere linguistiche e migliorando la collaborazione globale.
Manutenzione predittiva e rilevamento delle anomalie: I database vettoriali possono aiutare a identificare schemi e anomalie nei dati dei sensori e nei registri delle apparecchiature, consentendo una manutenzione proattiva e riducendo i tempi di fermo in ambito industriale.
Poiché il panorama dell'IA aziendale continua a evolversi a ritmo sostenuto, è fondamentale per le aziende tenersi informate sugli ultimi progressi della tecnologia dei database vettoriali e degli LLM. Tenendosi aggiornate su nuove tecniche, strumenti e best practice, le aziende possono assicurarsi che le loro applicazioni di IA rimangano competitive e offrano il massimo valore ai loro utenti.
Abbracciando il futuro dei database vettoriali e degli LLM, le aziende possono sbloccare nuovi livelli di efficienza, accuratezza e comprensione nelle loro applicazioni di IA, favorendo in ultima analisi la crescita del business e il successo negli anni a venire.


