
Come costruire potenti applicazioni LLM con database vettoriali + RAG - AI&YOU#55



Statistica/fatto della settimana: 30% di imprese utilizzeranno database vettoriali per fondare i loro modelli di IA generativa entro il 2026, rispetto a 2% nel 2023. (Gartner)
I LLM come GPT-4, Claude e Llama 3 sono emersi come potenti strumenti per le aziende che implementano l'NLP, dimostrando notevoli capacità di comprensione e generazione di testi simili a quelli umani. Tuttavia, spesso hanno problemi di consapevolezza del contesto e di accuratezza, soprattutto quando si tratta di informazioni specifiche del dominio.
Ecco perché nell'edizione di questa settimana di AI&YOU esploriamo il modo in cui queste sfide vengono affrontate attraverso tre blog che abbiamo pubblicato:
Combinazione di database vettoriali e RAG per potenti applicazioni LLM
I 10 principali vantaggi dell'utilizzo di un database vettoriale open source
Combinare database vettoriali e RAG per potenti applicazioni LLM - AI&YOU #55
Per affrontare queste sfide, ricercatori e sviluppatori si sono rivolti a tecniche innovative come la Retrieval Augmented Generation (RAG) e database vettoriali. La RAG migliora i LLM consentendo loro di accedere e recuperare informazioni rilevanti da basi di conoscenza esterne, mentre i database vettoriali forniscono una soluzione efficiente e scalabile per memorizzare e interrogare rappresentazioni di dati ad alta dimensionalità.
La sinergia tra database vettoriali e RAG
I database vettoriali e i RAG formano una potente sinergia che migliora le capacità dei modelli linguistici di grandi dimensioni. Al centro di questa sinergia c'è l'archiviazione e il recupero efficiente delle incorporazioni delle basi di conoscenza. I database vettoriali sono progettati per gestire rappresentazioni vettoriali ad alta dimensione dei dati. Consentono una ricerca di similarità rapida e accurata, permettendo ai LLM di recuperare rapidamente le informazioni rilevanti da vaste basi di conoscenza.
Integrando i database vettoriali con RAG, possiamo creare una pipeline senza soluzione di continuità per aumentare le risposte dei LLM con conoscenze esterne. Quando un LLM riceve un'interrogazione, RAG può cercare in modo efficiente nel database vettoriale le informazioni più rilevanti in base all'embedding dell'interrogazione. Le informazioni recuperate vengono quindi utilizzate per arricchire il contesto del LLM, consentendogli di generare risposte più accurate e informative in tempo reale.
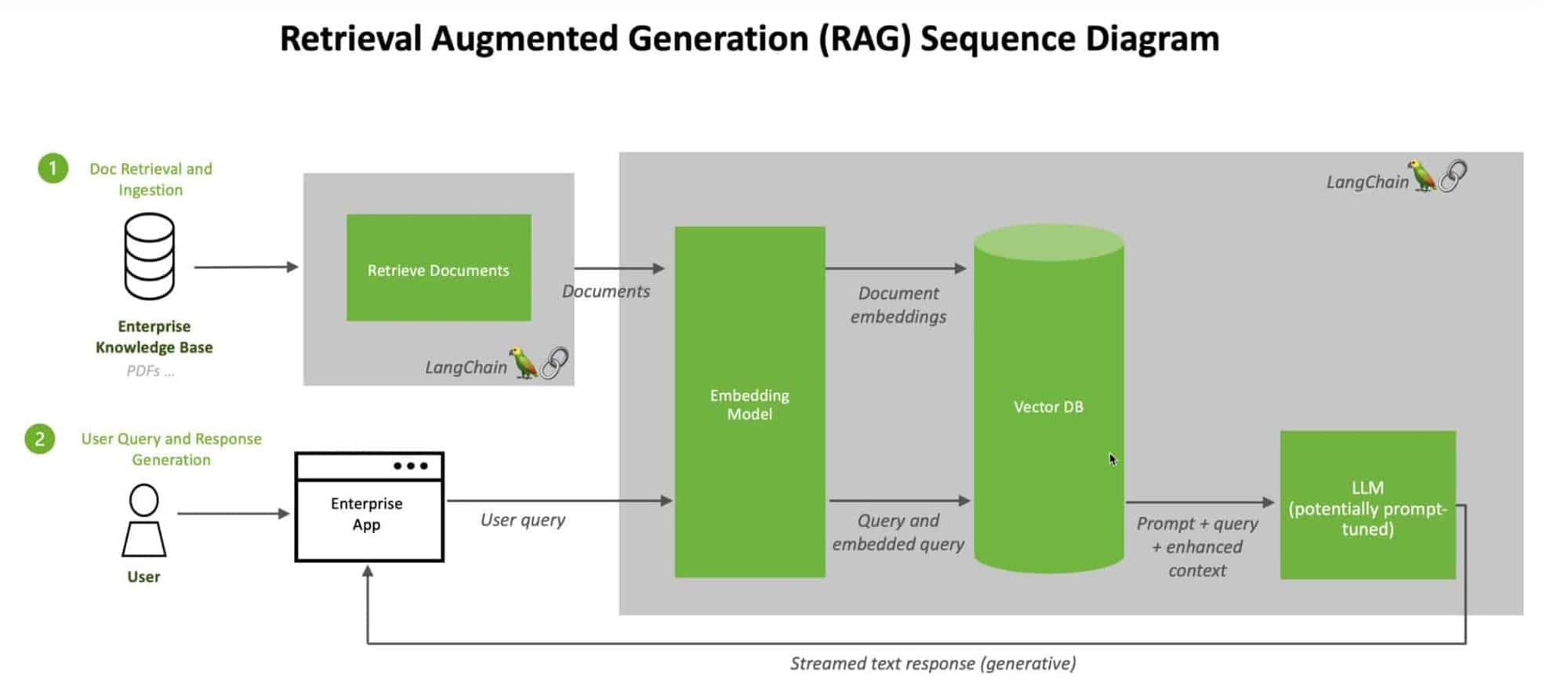
Vantaggi della combinazione di database vettoriali e RAG
La combinazione di database vettoriali e RAG offre diversi vantaggi significativi per le applicazioni di modelli linguistici di grandi dimensioni:
Miglioramento della precisione e riduzione delle allucinazioni
Uno dei principali vantaggi della combinazione di database vettoriali e RAG è il significativo miglioramento dell'accuratezza delle risposte dei LLM. Fornendo ai LLM l'accesso a conoscenze esterne rilevanti, la RAG contribuisce a ridurre il verificarsi di "allucinazioni", ossia di casi in cui il modello genera informazioni incoerenti o di fatto errate. Grazie alla capacità di recuperare e incorporare informazioni specifiche sul dominio da fonti affidabili, i LLM possono produrre risultati più accurati e affidabili.
Scalabilità e prestazioni
I database vettoriali sono progettati per scalare in modo efficiente, consentendo di gestire grandi volumi di dati ad alta dimensionalità. Questa scalabilità è fondamentale quando si ha a che fare con basi di conoscenza estese che devono essere ricercate e recuperate in tempo reale. Sfruttando la potenza dei database vettoriali, RAG è in grado di eseguire ricerche di similarità rapide ed efficienti, consentendo ai LLM di generare risposte in tempi rapidi senza compromettere la qualità delle informazioni recuperate.
Abilitazione di applicazioni specifiche per il dominio
La combinazione di database vettoriali e RAG apre nuove possibilità per la creazione di applicazioni LLM specifiche per il dominio. Curando basi di conoscenza specifiche per i vari domini, i LLM possono essere adattati per fornire informazioni accurate e pertinenti in quei contesti. Ciò consente lo sviluppo di assistenti AI specializzati, chatbot e sistemi di gestione della conoscenza in grado di soddisfare le esigenze specifiche di diversi settori e casi d'uso.

Implementazione di RAG con database vettoriali
Per sfruttare la potenza della combinazione di database vettoriali e RAG, è essenziale comprendere il processo di implementazione.
Analizziamo le fasi principali della creazione di un sistema RAG con un database vettoriale:
Indicizzazione e archiviazione delle incorporazioni di basi di conoscenza: Il primo passo consiste nel convertire i dati testuali della base di conoscenza in vettori ad alta dimensionalità utilizzando modelli di embedding come BERT, per poi indicizzare e memorizzare questi embeddings nel database vettoriale per una ricerca e un recupero efficienti delle similarità.
Interrogazione del database vettoriale per ottenere informazioni rilevanti: Quando un LLM riceve un'interrogazione, il sistema RAG trasforma l'interrogazione in una rappresentazione vettoriale utilizzando lo stesso modello di incorporamento e il database vettoriale esegue una ricerca di similarità per recuperare gli incorporamenti della base di conoscenza più rilevanti in base a una metrica di similarità scelta.
Integrare le informazioni recuperate nelle risposte del LLM: Le informazioni rilevanti recuperate dal database vettoriale vengono integrate nel processo di generazione delle risposte del LLM, concatenandole con la query originale o utilizzando tecniche come i meccanismi di attenzione, consentendo al LLM di generare risposte più accurate e informative sulla base del contesto aumentato.
Scegliere il database vettoriale giusto per la propria applicazione: La scelta del database vettoriale appropriato è cruciale e tiene conto di fattori quali la scalabilità, le prestazioni, la facilità d'uso e la compatibilità con lo stack tecnologico esistente, oltre che di requisiti specifici quali le dimensioni della base di conoscenza, il volume delle query e la latenza di risposta desiderata.
Migliori pratiche e considerazioni
Per garantire il successo della vostra implementazione RAG con i database vettoriali, ci sono diverse best practice e considerazioni da tenere a mente.
Ottimizzazione delle incorporazioni di basi di conoscenza per il recupero:
La qualità delle incorporazioni della base di conoscenza è fondamentale e richiede la sperimentazione di diversi modelli e tecniche di incorporazione, la messa a punto su dati specifici del dominio e l'aggiornamento e l'espansione regolari delle incorporazioni man mano che si rendono disponibili nuove informazioni per mantenere la pertinenza e l'accuratezza.
Bilanciare la velocità di recupero e l'accuratezza:
Esiste un compromesso tra velocità di recupero e accuratezza, che richiede tecniche come la ricerca approssimativa del vicino per accelerare il recupero mantenendo un'accuratezza accettabile, nonché la memorizzazione nella cache degli embeddings di frequente accesso e l'implementazione di strategie di bilanciamento del carico per ottimizzare le prestazioni.
Garantire la sicurezza e la privacy dei dati:
Stabilire un'archiviazione sicura dei dati, controlli di accesso e tecniche di crittografia come la crittografia omomorfa è essenziale per impedire l'accesso non autorizzato e proteggere i dati sensibili nelle incorporazioni della base di conoscenza, rispettando al contempo le normative sulla protezione dei dati.
Monitoraggio e manutenzione del sistema:
Il monitoraggio continuo di metriche quali la latenza delle query, l'accuratezza del recupero e l'utilizzo delle risorse, l'implementazione di meccanismi automatici di monitoraggio e di allerta e la definizione di un solido programma di manutenzione, comprendente backup, aggiornamenti e messa a punto delle prestazioni, sono fondamentali per garantire le prestazioni e l'affidabilità a lungo termine del sistema RAG.
Sfruttare la potenza dei database vettoriali e del RAG nella vostra azienda
Poiché l'IA continua a plasmare il nostro futuro, è fondamentale per la vostra azienda rimanere all'avanguardia di questi progressi tecnologici. Esplorando e implementando tecniche all'avanguardia come i database vettoriali e il RAG, è possibile sbloccare il pieno potenziale dei modelli linguistici di grandi dimensioni e creare sistemi di IA più intelligenti, adattabili e con un maggiore ROI.
I 10 principali vantaggi dell'utilizzo di un database vettoriale open source
Tra le soluzioni di database vettoriali, i database vettoriali open-source offrono un'interessante combinazione di flessibilità, scalabilità ed economicità. Sfruttando la potenza collettiva della comunità open-source, questi database vettoriali specializzati stanno ridefinendo il modo in cui le organizzazioni affrontano la gestione e l'analisi dei dati.
Questa settimana, il nostro blog ha esplorato anche i 10 principali vantaggi dell'utilizzo di un database vettoriale open-source:
La scalabilità e l'economicità consentono una crescita continua senza costi elevati, eliminando il vendor lock-in e fornendo una soluzione economica.
Flessibilità e personalizzazione consentono di adattare il database a esigenze specifiche, di modificare le funzionalità e di integrarlo con i sistemi esistenti.
Una gestione efficiente dei dati non strutturati sfrutta tecniche come l'NLP e le incorporazioni vettoriali per un'archiviazione, una ricerca e un'analisi efficaci.
La potente ricerca per similarità vettoriale facilita il recupero accurato basato sulla similarità semantica, consentendo applicazioni come le raccomandazioni personalizzate e la scoperta intelligente dei contenuti.
L'integrazione con gli ecosistemi open-source garantisce l'interoperabilità con strumenti e framework complementari, migliorando la produttività e favorendo la collaborazione.
Le solide misure di sicurezza e di privacy dei dati danno priorità alla trasparenza, alla crittografia, al controllo degli accessi e al rispetto degli standard di conformità.
Prestazioni elevate e gestione efficiente dei dati garantiscono un'esecuzione fulminea delle query e la versatilità di diversi carichi di lavoro.
La compatibilità con l'analitica avanzata e l'apprendimento automatico consente una perfetta integrazione con tecniche e framework all'avanguardia.
L'architettura scalabile e a prova di futuro consente una crescita e un adattamento continui alle tecnologie emergenti e all'evoluzione dei requisiti dei dati.
L'innovazione e il supporto della comunità favoriscono il miglioramento continuo, la condivisione delle conoscenze e le preziose risorse per sfruttare questi potenti strumenti.
I 5 migliori database vettoriali per l'azienda
Oltre ai principali vantaggi, questa settimana abbiamo pubblicato un blog sui 5 migliori database vettoriali per la vostra azienda:
1. Croma
Chroma è progettato per una perfetta integrazione con i modelli e i framework di apprendimento automatico, semplificando il processo di creazione di applicazioni basate sull'intelligenza artificiale. Offre un'efficiente archiviazione vettoriale, il recupero, la ricerca per similarità, l'indicizzazione in tempo reale e l'archiviazione dei metadati. Supporta diverse metriche di distanza e algoritmi di indicizzazione per ottenere prestazioni ottimali in casi d'uso come la ricerca semantica, le raccomandazioni e il rilevamento di anomalie.

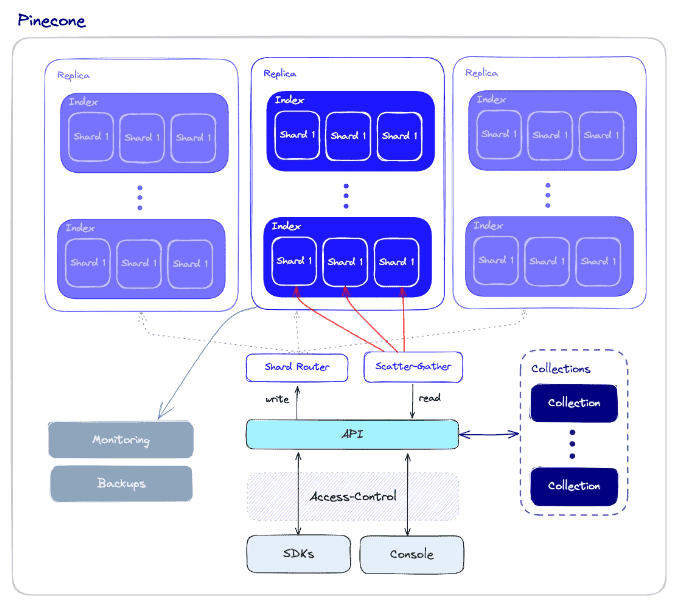
2. Pigna
Pinecone è un database vettoriale completamente gestito e privo di server che privilegia le prestazioni elevate e la facilità d'uso. Combina algoritmi avanzati di ricerca vettoriale con filtraggio e infrastruttura distribuita per una ricerca vettoriale veloce e affidabile su scala. Si integra perfettamente con framework di apprendimento automatico e fonti di dati per applicazioni come la ricerca semantica, le raccomandazioni, il rilevamento delle anomalie e la risposta alle domande.
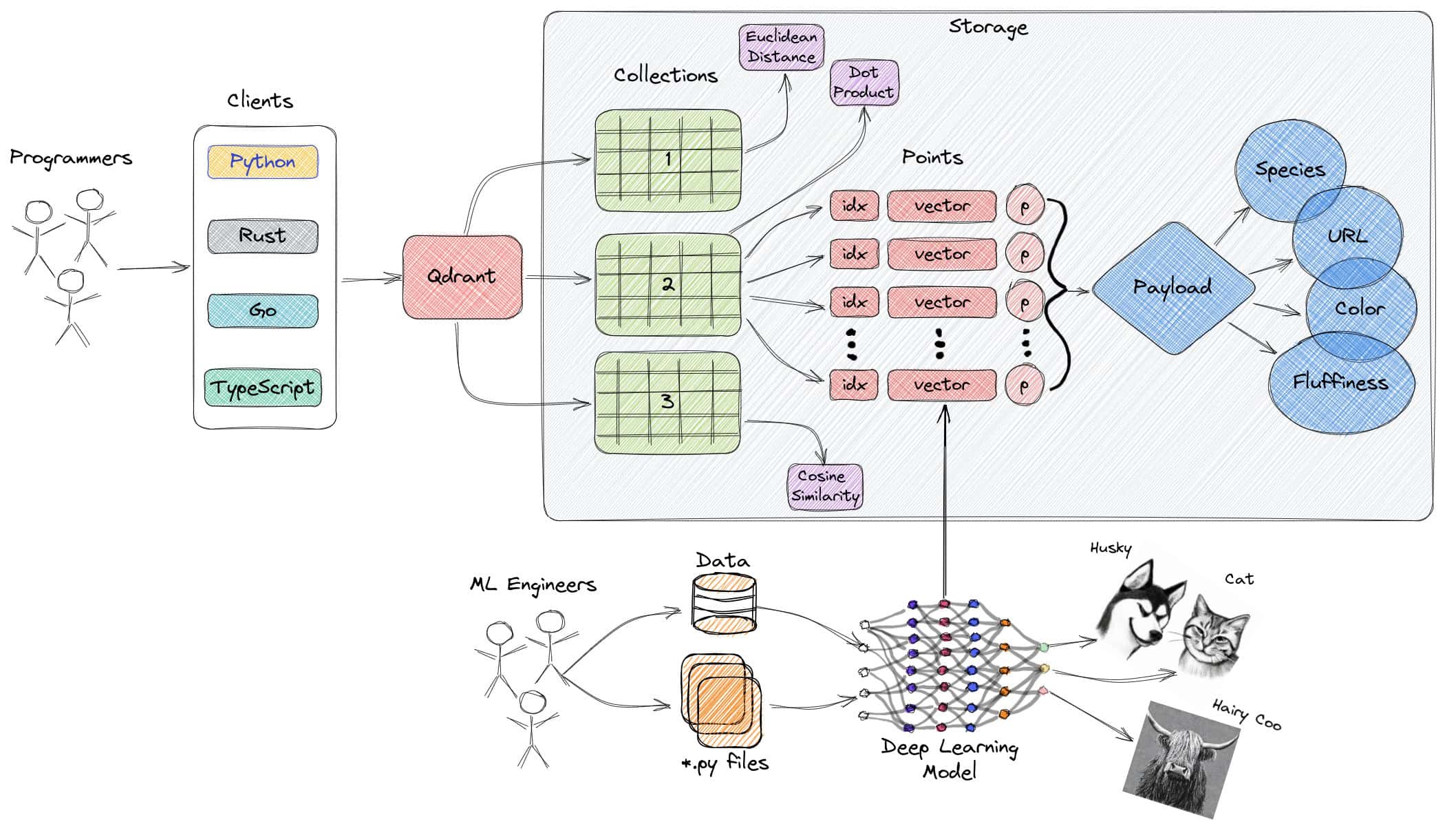
3. Qdrant
Qdrant è un motore di ricerca di similarità vettoriale open-source, ad alta velocità e scalabile, scritto in Rust. Fornisce una comoda API per la memorizzazione, la ricerca e la gestione di vettori con metadati, consentendo applicazioni pronte per la produzione per il matching, la ricerca, la raccomandazione e altro ancora. Le caratteristiche includono aggiornamenti in tempo reale, filtri avanzati, indici distribuiti e opzioni di distribuzione cloud-native.
4. Weaviate
Weaviate è un database vettoriale open-source che privilegia la velocità, la scalabilità e la facilità d'uso. Consente di memorizzare sia oggetti che vettori, combinando la ricerca vettoriale con il filtraggio strutturato. Offre un'API basata su GraphQL, operazioni CRUD, scalabilità orizzontale e distribuzione cloud-native. Incorpora moduli per attività NLP, configurazione automatica dello schema e vettorizzazione personalizzata.
5. Milvus
Milvus è un database vettoriale open-source progettato per la gestione delle incorporazioni, la ricerca di similarità e le applicazioni AI scalabili. Offre supporto per calcoli eterogenei, affidabilità dello storage, metriche complete e un'architettura cloud-native. Fornisce un'API flessibile per indici, metriche di distanza e tipi di query e può scalare fino a miliardi di vettori con plugin personalizzati.
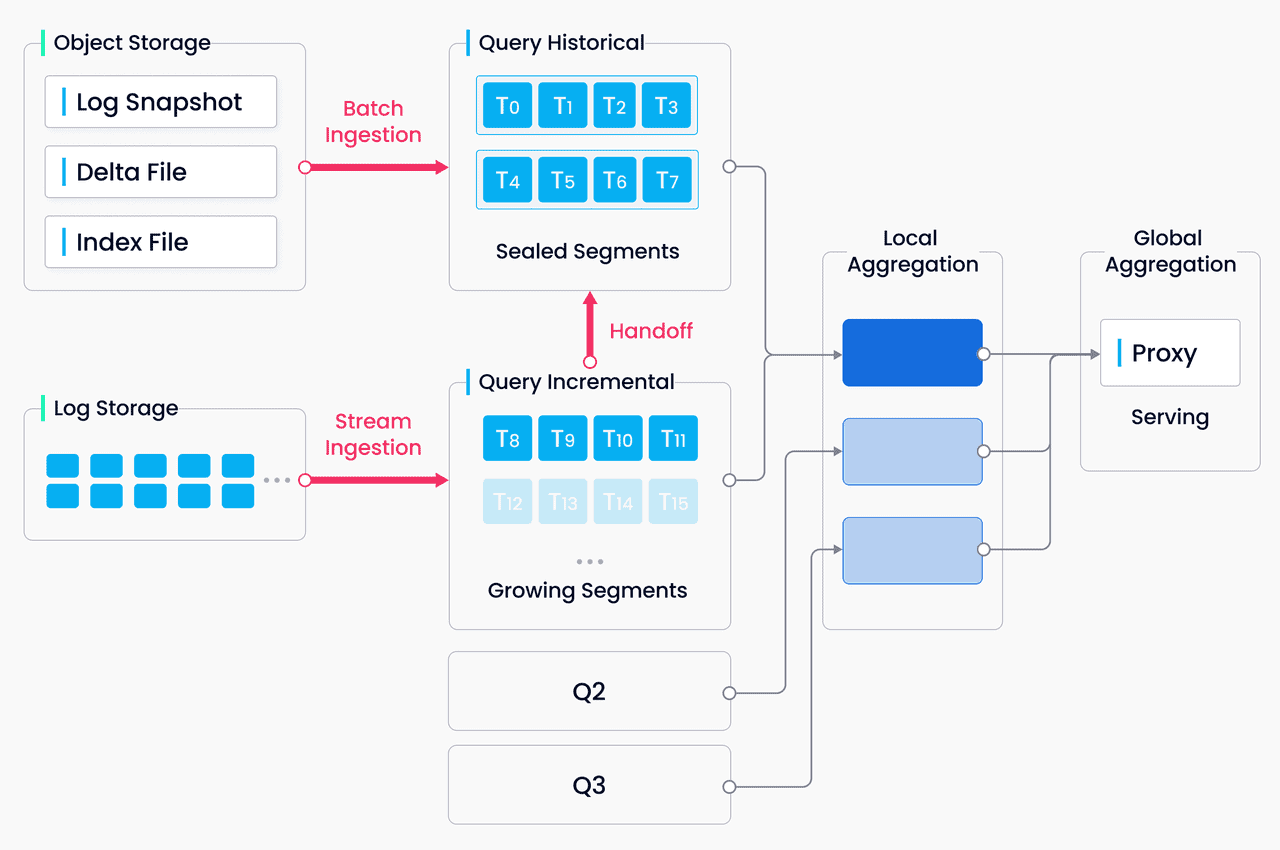
Scegliere il database vettoriale giusto per l'azienda
Che si tratti di un motore di ricerca semantico, di un sistema di raccomandazione o di qualsiasi altra applicazione basata sull'intelligenza artificiale, i database vettoriali costituiscono la base per liberare tutto il potenziale dei modelli di apprendimento automatico. Consentendo una rapida ricerca per similarità, un filtraggio avanzato e una perfetta integrazione con i framework più diffusi, questi database permettono agli sviluppatori di concentrarsi sulla creazione di soluzioni innovative senza preoccuparsi delle complessità sottostanti alla gestione dei dati vettoriali.
Per ulteriori contenuti sull'IA aziendale, tra cui infografiche, statistiche, guide, articoli e video, seguite Skim AI su LinkedIn
Siete un fondatore, un CEO, un Venture Capitalist o un investitore alla ricerca di servizi di consulenza o due diligence sull'IA? Ottenete la guida necessaria per prendere decisioni informate sulla strategia di prodotto AI della vostra azienda o sulle opportunità di investimento.
Costruiamo prodotti personalizzati Soluzioni AI per le aziende sostenute da Venture Capital e Private Equity nei seguenti settori: Tecnologia medica, aggregazione di notizie e contenuti, produzione di film e foto, tecnologia educativa, tecnologia legale, Fintech e criptovalute.


