
Scomposizione del documento di ricerca AI per ChainPoll: un metodo ad alta efficacia per il rilevamento delle allucinazioni LLM



In questo articolo analizzeremo un importante lavoro di ricerca che affronta una delle sfide più pressanti per i modelli linguistici di grandi dimensioni (LLM): le allucinazioni. Il documento, intitolato "ChainPoll: un metodo ad alta efficacia per il rilevamento delle allucinazioni LLMintroduce un approccio innovativo per identificare e mitigare queste imprecisioni generate dall'IA.
Il documento ChainPoll, redatto dai ricercatori di Galileo Technologies Inc., presenta una nuova metodologia per rilevare le allucinazioni nelle produzioni LLM. Questo metodo, denominato ChainPoll, supera le alternative esistenti sia in termini di accuratezza che di efficienza. Inoltre, il documento presenta RealHall, una suite di dati di riferimento accuratamente curata e progettata per valutare le metriche di rilevamento delle allucinazioni in modo più efficace rispetto ai benchmark precedenti.
Le allucinazioni nei LLM si riferiscono a casi in cui questi modelli di intelligenza artificiale generano testo che è di fatto errato, senza senso o non correlato ai dati di input. Con la crescente integrazione dei LLM in varie applicazioni, dai chatbot agli strumenti per la creazione di contenuti, il rischio di propagare informazioni errate attraverso queste allucinazioni cresce in modo esponenziale. Questo problema rappresenta una sfida significativa per l'affidabilità e l'attendibilità dei contenuti generati dall'IA.
La capacità di individuare e attenuare con precisione le allucinazioni è fondamentale per una diffusione responsabile dei sistemi di IA. Questa ricerca fornisce un metodo più robusto per identificare questi errori, che può portare a una maggiore affidabilità dei contenuti generati dall'IA, a una maggiore fiducia degli utenti nelle applicazioni di IA e a una riduzione del rischio di diffusione di informazioni errate attraverso i sistemi di IA. Affrontando il problema dell'allucinazione, questa ricerca apre la strada ad applicazioni di IA più affidabili e degne di fiducia in diversi settori.

Background e dichiarazione del problema
L'individuazione delle allucinazioni nei risultati dei LLM è un compito complesso a causa di diversi fattori. L'enorme quantità di testo che i LLM possono generare, unita alla natura spesso sottile delle allucinazioni, le rende difficili da distinguere dalle informazioni accurate. Inoltre, la natura dipendente dal contesto di molte allucinazioni e la mancanza di una "verità di base" completa con cui verificare tutti i contenuti generati complicano ulteriormente il processo di rilevamento.
Prima del documento ChainPoll, i metodi di rilevamento delle allucinazioni esistenti presentavano diverse limitazioni. Molti non erano efficaci in diversi compiti e domini, mentre altri erano troppo costosi dal punto di vista computazionale per le applicazioni in tempo reale. Alcuni metodi dipendevano da architetture di modelli o dati di addestramento specifici e la maggior parte faticava a distinguere tra diversi tipi di allucinazioni, come gli errori fattuali da quelli contestuali.
Inoltre, i benchmark utilizzati per valutare questi metodi spesso non rispecchiano le vere sfide poste dagli LLM di ultima generazione nelle applicazioni reali. Molti si basavano su modelli più vecchi e deboli o si concentravano su compiti ristretti e specifici che non rappresentavano l'intera gamma di capacità e potenziali allucinazioni dei LLM.
Per affrontare questi problemi, i ricercatori che hanno redatto il documento ChainPoll hanno adottato un duplice approccio:
Sviluppo di un nuovo e più efficace metodo di rilevamento delle allucinazioni (ChainPoll)
Creare una suite di benchmark più rilevante e stimolante (RealHall)
Questo approccio globale mirava non solo a migliorare il rilevamento delle allucinazioni, ma anche a stabilire un quadro più robusto per valutare e confrontare i diversi metodi di rilevamento.
Contributi chiave del documento
Il documento ChainPoll offre tre contributi principali al campo della ricerca e dello sviluppo dell'intelligenza artificiale, ciascuno dei quali affronta un aspetto critico della sfida del rilevamento delle allucinazioni.
In primo luogo, il documento introduce ChainPolluna nuova metodologia di rilevamento delle allucinazioni. ChainPoll sfrutta la potenza degli stessi LLM per identificare le allucinazioni, utilizzando una tecnica di sollecitazione attentamente studiata e un metodo di aggregazione per migliorare l'accuratezza e l'affidabilità. Impiega la tecnica di sollecitazione della catena di pensieri per ottenere spiegazioni più dettagliate e sistematiche, esegue più iterazioni del processo di rilevamento per aumentare l'affidabilità e si adatta a scenari di rilevamento delle allucinazioni sia a dominio aperto che a dominio chiuso.
In secondo luogo, riconoscendo i limiti dei benchmark esistenti, gli autori hanno sviluppato RealHalluna nuova serie di set di dati di riferimento. RealHall è stato progettato per fornire una valutazione più realistica e impegnativa dei metodi di rilevamento delle allucinazioni. Comprende quattro set di dati accuratamente selezionati che rappresentano una sfida anche per i LLM più avanzati, si concentra su compiti rilevanti per le applicazioni LLM del mondo reale e copre scenari di allucinazione sia a dominio aperto che a dominio chiuso.
Infine, il documento fornisce un confronto approfondito di ChainPoll con un'ampia gamma di metodi di rilevamento delle allucinazioni esistenti. Questa valutazione completa utilizza la suite di benchmark RealHall di recente sviluppo, include sia metriche consolidate che innovazioni recenti nel campo e considera fattori quali l'accuratezza, l'efficienza e l'efficacia dei costi. Attraverso questa valutazione, il documento dimostra le prestazioni superiori di ChainPoll in vari compiti e tipi di allucinazioni.
Offrendo questi tre contributi chiave, il documento di ChainPoll non solo avanza lo stato dell'arte nel rilevamento delle allucinazioni, ma fornisce anche un quadro più solido per la ricerca e lo sviluppo futuri in quest'area critica della sicurezza e dell'affidabilità dell'IA.
Approfondimento della metodologia ChainPoll
Nel suo nucleo, ChainPoll sfrutta le capacità dei modelli linguistici di grandi dimensioni per identificare le allucinazioni nei testi generati dall'intelligenza artificiale. Questo approccio si distingue per la sua semplicità, efficacia e adattabilità a diversi tipi di allucinazioni.
Come funziona ChainPoll
Il metodo ChainPoll si basa su un principio semplice ma potente. Utilizza un LLM (in particolare, GPT-3,5-turbo negli esperimenti del paper) per valutare se un dato completamento di testo contiene allucinazioni.
Il processo prevede tre fasi fondamentali:
In primo luogo, il sistema chiede all'LLM di valutare la presenza di allucinazioni nel testo di riferimento, utilizzando una procedura accuratamente tempestivamente.
Successivamente, questo processo viene ripetuto più volte, in genere cinque, per garantire l'affidabilità.
Infine, il sistema calcola un punteggio dividendo il numero di risposte "sì" (che indicano la presenza di allucinazioni) per il numero totale di risposte.
Questo approccio consente a ChainPoll di sfruttare le capacità di comprensione linguistica dei LLM, attenuando al contempo gli errori di valutazione individuali grazie all'aggregazione.
Il ruolo della catena di pensiero
Un'innovazione cruciale di ChainPoll è l'uso della sollecitazione della catena del pensiero (CoT). Questa tecnica incoraggia il LLM a fornire una spiegazione passo per passo del suo ragionamento nel determinare se un testo contiene allucinazioni. Gli autori hanno riscontrato che una richiesta di "CoT dettagliata", accuratamente progettata, ha permesso di ottenere dal modello spiegazioni più sistematiche e affidabili.
Incorporando la CoT, ChainPoll non solo migliora l'accuratezza del rilevamento delle allucinazioni, ma fornisce anche preziose informazioni sul processo decisionale del modello. Questa trasparenza può essere fondamentale per capire perché certi testi vengono segnalati come contenenti allucinazioni, aiutando potenzialmente lo sviluppo di LLM più robusti in futuro.
Distinzione tra allucinazioni a dominio aperto e a dominio chiuso
Uno dei punti di forza di ChainPoll è la sua capacità di affrontare sia le allucinazioni a dominio aperto che quelle a dominio chiuso. Le allucinazioni a dominio aperto si riferiscono a false affermazioni sul mondo in generale, mentre quelle a dominio chiuso riguardano incongruenze con un testo o un contesto di riferimento specifico.
Per gestire questi diversi tipi di allucinazioni, gli autori hanno sviluppato due varianti di ChainPoll: Correttezza a catena per le allucinazioni a dominio aperto e Aderenza a catena di Poll per allucinazioni a dominio chiuso. Queste varianti si differenziano principalmente per la strategia di sollecitazione, che consente al sistema di adattarsi a diversi contesti di valutazione, pur mantenendo la metodologia di base di ChainPoll.
La suite di benchmark RealHall
Riconoscendo i limiti dei benchmark esistenti, gli autori hanno anche sviluppato RealHall, una nuova suite di benchmark progettata per fornire una valutazione più realistica e impegnativa dei metodi di rilevamento delle allucinazioni.
Criteri per la selezione dei dataset (sfida, realismo, diversità dei compiti)
La creazione di RealHall è stata guidata da tre principi chiave:
Sfida: I set di dati dovrebbero porre difficoltà significative anche ai LLM più avanzati, garantendo che il benchmark rimanga rilevante man mano che i modelli migliorano.
Realismo: I compiti dovrebbero rispecchiare fedelmente le applicazioni reali dei LLM, rendendo i risultati dei benchmark più applicabili a scenari pratici.
Diversità dei compiti: La suite dovrebbe coprire un'ampia gamma di capacità di LLM, fornendo una valutazione completa dei metodi di rilevamento delle allucinazioni.
Questi criteri hanno portato alla selezione di quattro serie di dati che, nel complesso, offrono un solido terreno di prova per i metodi di rilevamento delle allucinazioni.
Panoramica dei quattro set di dati di RealHall
RealHall comprende due coppie di set di dati, ognuno dei quali affronta un aspetto diverso del rilevamento delle allucinazioni:
RealHall ha chiuso: Questa coppia comprende il dataset COVID-QA con recupero e il dataset DROP. Questi si concentrano sulle allucinazioni a dominio chiuso, testando la capacità di un modello di rimanere coerente con i testi di riferimento forniti.
RealHall Open: Questa coppia è composta dal dataset Open Assistant prompts e dal dataset TriviaQA. Si tratta di allucinazioni di dominio aperto, che valutano la capacità di un modello di evitare di fare affermazioni false sul mondo.
Ogni set di dati di RealHall è stato scelto per le sue sfide uniche e la sua rilevanza per le applicazioni LLM del mondo reale. Per esempio, il set di dati COVID-QA riproduce scenari di generazione aumentata del reperimento, mentre DROP mette alla prova le capacità di ragionamento discreto.
Come RealHall affronta i limiti dei benchmark precedenti
RealHall rappresenta un miglioramento significativo rispetto ai benchmark precedenti sotto diversi aspetti. In primo luogo, utilizza LLM più recenti e potenti per generare le risposte, assicurando che le allucinazioni rilevate siano rappresentative di quelle prodotte dagli attuali modelli all'avanguardia. In questo modo si risolve un problema comune ai benchmark precedenti, che utilizzavano modelli obsoleti che producevano allucinazioni facilmente rilevabili.
In secondo luogo, l'attenzione di RealHall alla diversità dei compiti e al realismo significa che fornisce una valutazione più completa e rilevante dal punto di vista pratico dei metodi di rilevamento delle allucinazioni. Ciò contrasta con molti benchmark precedenti che si concentravano su compiti ristretti e specifici o su scenari artificiali.
Infine, includendo compiti sia a dominio aperto che a dominio chiuso, RealHall consente una valutazione più sfumata dei metodi di rilevamento delle allucinazioni. Questo è particolarmente importante perché molte applicazioni LLM del mondo reale richiedono entrambi i tipi di rilevamento delle allucinazioni.
Grazie a questi miglioramenti, RealHall fornisce un punto di riferimento più rigoroso e pertinente per la valutazione dei metodi di rilevamento delle allucinazioni, stabilendo un nuovo standard nel settore.
Risultati sperimentali e analisi
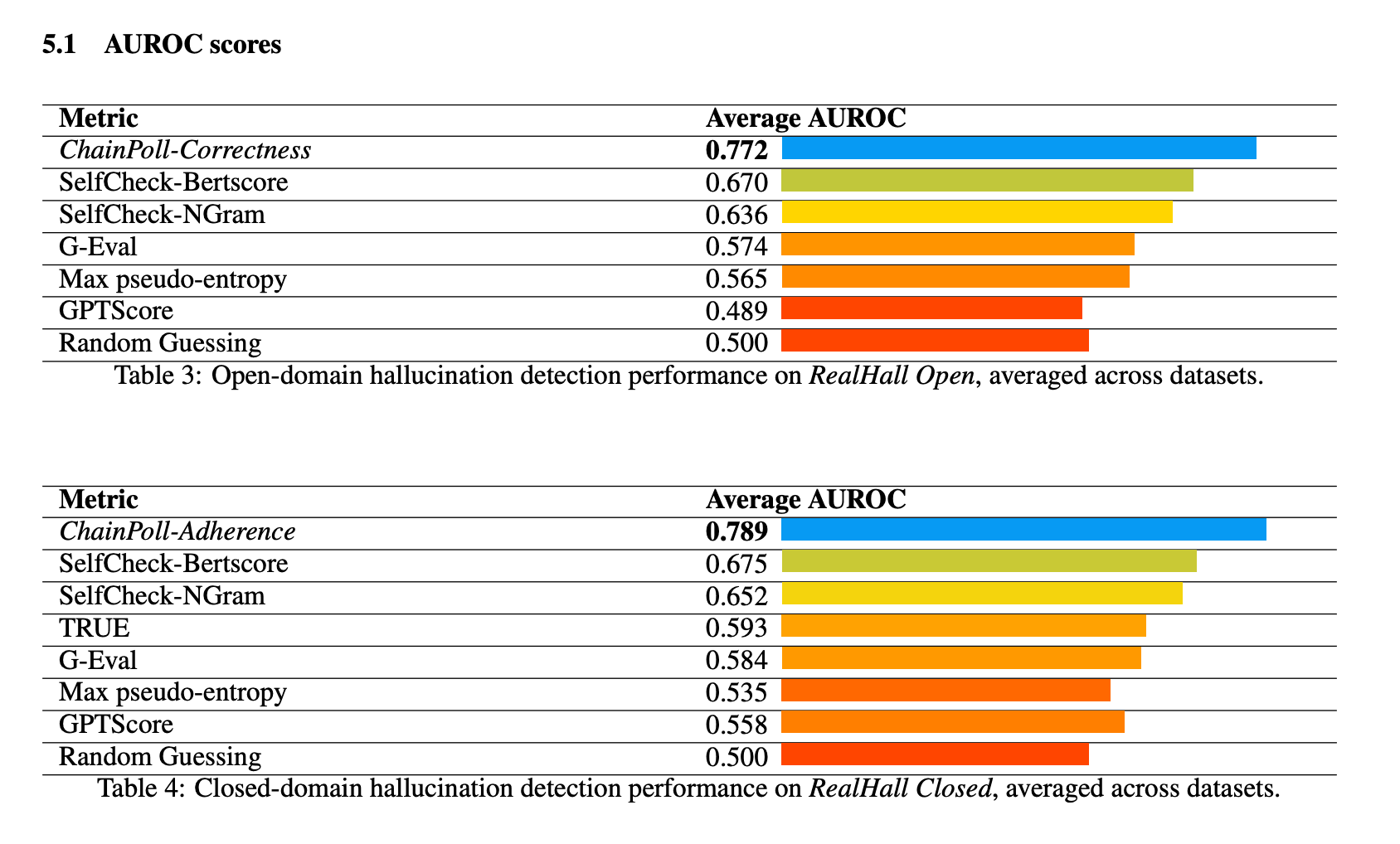
ChainPoll ha dimostrato prestazioni superiori in tutti i benchmark della suite RealHall. Ha ottenuto un AUROC (Area Under the Receiver Operating Characteristic curve) aggregato di 0,781, superando in modo significativo il metodo successivo migliore, SelfCheck-BertScore, che ha ottenuto un punteggio di 0,673. Questo miglioramento sostanziale rispetto a 10% rappresenta un salto significativo nella capacità di rilevamento delle allucinazioni.
Tra gli altri metodi testati figurano SelfCheck-NGram, G-Eval e GPTScore, tutti con risultati nettamente peggiori rispetto a ChainPoll. È interessante notare che alcuni metodi che si erano dimostrati promettenti in studi precedenti, come GPTScore, hanno ottenuto scarsi risultati nei benchmark più impegnativi e diversificati di RealHall.

Le prestazioni di ChainPoll sono state costantemente elevate sia nei compiti di rilevamento delle allucinazioni a dominio aperto sia in quelli a dominio chiuso. Per i compiti a dominio aperto (utilizzando ChainPoll-Correctness), ha ottenuto un AUROC medio di 0,772, mentre per i compiti a dominio chiuso (utilizzando ChainPoll-Adherence), ha ottenuto un punteggio di 0,789.
Il metodo si è dimostrato particolarmente efficace in set di dati impegnativi come DROP, che richiede un ragionamento discreto.
Oltre alla sua superiore accuratezza, ChainPoll si è dimostrato anche più efficiente ed economico di molti metodi concorrenti. Raggiunge i suoi risultati utilizzando solo 1/4 dell'inferenza LLM rispetto al metodo migliore, SelfCheck-BertScore. Inoltre, ChainPoll non richiede l'uso di modelli aggiuntivi come BERT, riducendo ulteriormente l'overhead computazionale.
Questa efficienza è fondamentale per le applicazioni pratiche, in quanto consente di rilevare le allucinazioni in tempo reale negli ambienti di produzione senza incorrere in costi o latenze proibitivi.
Implicazioni e lavoro futuro
ChainPoll rappresenta un progresso significativo nel campo del rilevamento delle allucinazioni per gli LLM. Il suo successo dimostra il potenziale dell'utilizzo degli LLM stessi come strumenti per migliorare la sicurezza e l'affidabilità delle IA. Questo approccio apre nuove strade alla ricerca sui sistemi di intelligenza artificiale che si auto-migliorano e si auto-verificano.
L'efficienza e la precisione di ChainPoll lo rendono adatto a essere integrato in un'ampia gamma di applicazioni di IA. Potrebbe essere utilizzato per aumentare l'affidabilità dei chatbot, migliorare l'accuratezza dei contenuti generati dall'IA in campi come il giornalismo o la scrittura tecnica e aumentare l'affidabilità degli assistenti IA in settori critici come la sanità o la finanza.
Sebbene ChainPoll mostri risultati impressionanti, c'è ancora spazio per ulteriori ricerche e miglioramenti. Il lavoro futuro potrebbe esplorare:
Adattare ChainPoll per lavorare con una gamma più ampia di LLM e compiti linguistici
Studiare modi per migliorare ulteriormente l'efficienza senza sacrificare l'accuratezza.
Esplorazione del potenziale di ChainPoll per altri tipi di contenuti generati dall'intelligenza artificiale oltre al testo
Sviluppare metodi per non solo rilevare, ma anche correggere o prevenire le allucinazioni in tempo reale.
Il documento ChainPoll apporta un contributo significativo al campo della sicurezza e dell'affidabilità dell'IA grazie all'introduzione di un nuovo metodo di rilevamento delle allucinazioni e di un benchmark di valutazione più robusto. Dimostrando prestazioni superiori nel rilevamento di allucinazioni sia a dominio aperto che a dominio chiuso, ChainPoll apre la strada a sistemi di IA più affidabili. Poiché i LLM continuano a svolgere un ruolo sempre più importante in varie applicazioni, la capacità di rilevare e attenuare accuratamente le allucinazioni diventa fondamentale. Questa ricerca non solo fa avanzare le nostre attuali capacità, ma apre anche nuove strade per l'esplorazione e lo sviluppo futuri nell'area critica del rilevamento delle allucinazioni dell'IA.


