
10 strategie comprovate per ridurre i costi del vostro LLM - AI&YOU #65



Statistica della settimana: L'utilizzo di LLM più piccoli come GPT-J in una cascata può ridurre il costo complessivo di 80%, migliorando al contempo la precisione di 1,5% rispetto a GPT-4. (Dataiku)
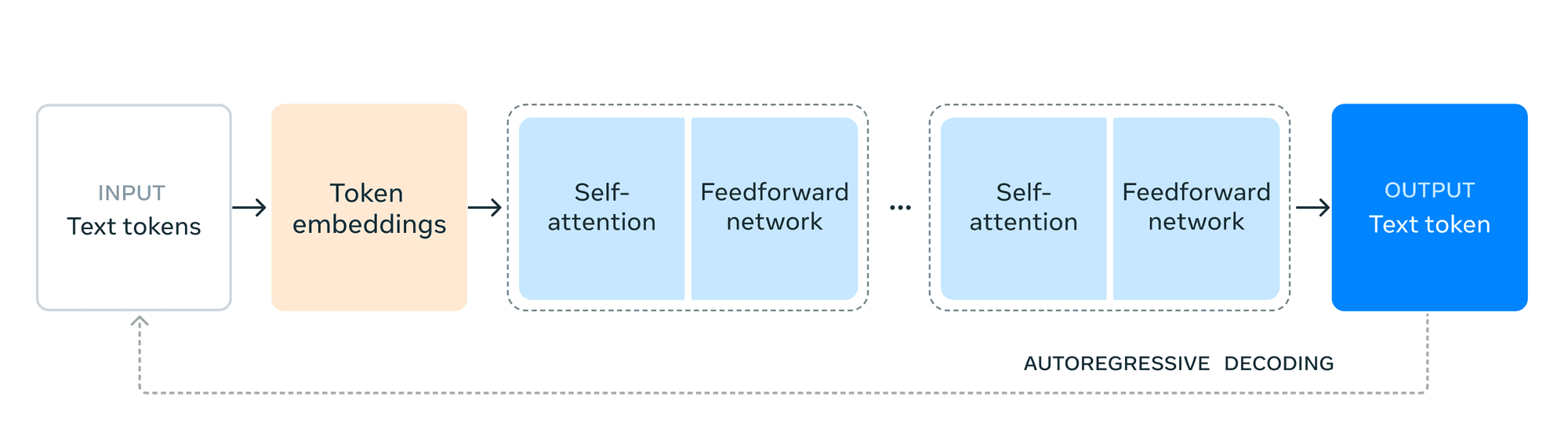
Poiché le organizzazioni si affidano sempre più spesso a modelli linguistici di grandi dimensioni (LLM) per varie applicazioni, i costi operativi associati alla loro implementazione e manutenzione possono rapidamente andare fuori controllo senza un'adeguata supervisione e strategie di ottimizzazione.
Meta ha anche rilasciato Llama 3.1, che ultimamente ha fatto parlare di sé per essere il più avanzato LLM open-source.
Nell'edizione di questa settimana di AI&YOU, esploriamo le intuizioni di tre blog che abbiamo pubblicato su questi temi:
Comprendere le strutture di prezzo LLM: Ingressi, uscite e finestre di contesto
Meta's Llama 3.1: Spingersi oltre i confini dell'intelligenza artificiale open source
10 strategie comprovate per ridurre i costi del vostro LLM - AI&YOU #65
Questo blog post esplorerà dieci strategie comprovate per aiutare la vostra azienda a gestire efficacemente i costi dei LLM, assicurandovi di poter sfruttare il pieno potenziale di questi modelli mantenendo l'efficienza dei costi e il controllo delle spese.
1. Selezione intelligente del modello
Ottimizzate i costi dell'LLM abbinando con cura la complessità del modello ai requisiti dell'attività. Non tutte le applicazioni hanno bisogno del modello più recente e più grande. Per compiti più semplici, come la classificazione di base o la semplice Q&A, si può considerare l'utilizzo di modelli pre-addestrati più piccoli ed efficienti. Questo approccio può portare a risparmi sostanziali senza compromettere le prestazioni.
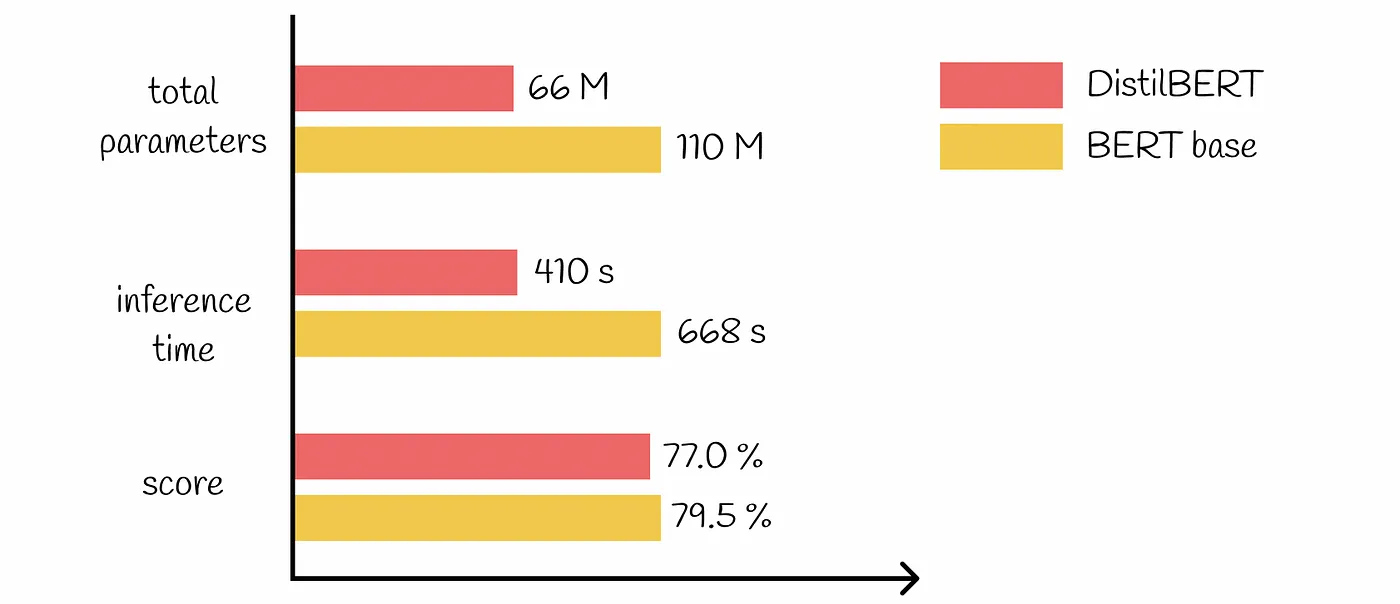
Ad esempio, l'impiego di DistilBERT per l'analisi del sentiment al posto di BERT-Large può ridurre significativamente l'overhead computazionale e le spese associate, pur mantenendo un'elevata accuratezza per il compito specifico da svolgere.
2. Implementare un robusto monitoraggio dell'uso
Ottenere una visione completa del vostro Utilizzo dell'LLM implementando meccanismi di tracciamento a più livelli. Monitorate l'utilizzo dei token, i tempi di risposta e le chiamate modello a livello di conversazione, utente e azienda. Sfruttate le dashboard analitiche integrate dei fornitori di LLM o implementate soluzioni di tracciamento personalizzate integrate con la vostra infrastruttura.
Questa visione granulare consente di identificare le inefficienze, come ad esempio l'uso eccessivo da parte dei reparti di modelli costosi per attività semplici o modelli di query ridondanti. Analizzando questi dati, è possibile scoprire preziose strategie di riduzione dei costi e ottimizzare il consumo complessivo di LLM.
3. Ottimizzare l'ingegneria del prompt
Affinate le tecniche di progettazione dei prompt per ridurre significativamente l'uso dei token e migliorare l'efficienza dell'LLM. Create istruzioni chiare e concise nei vostri prompt, implementate la gestione degli errori per risolvere i problemi più comuni senza ulteriori query e utilizzate modelli di prompt collaudati per compiti specifici. Strutturate i vostri prompt in modo efficiente evitando contesti non necessari, utilizzando tecniche di formattazione come i punti elenco e sfruttando le funzioni integrate per controllare la lunghezza dell'output.
Queste ottimizzazioni possono ridurre in modo sostanziale il consumo di token e i costi associati, mantenendo o addirittura migliorando la qualità dei risultati LLM.
4. Sfruttare la messa a punto per la specializzazione
Sfruttate la potenza della regolazione fine per creare modelli più piccoli e più efficienti, adatti alle vostre esigenze specifiche. Pur richiedendo un investimento iniziale, questo approccio può portare a significativi risparmi a lungo termine. I modelli perfezionati spesso richiedono meno token per ottenere risultati uguali o migliori, riducendo i costi di inferenza e la necessità di ripetizioni o correzioni.
Iniziate con un modello pre-addestrato di dimensioni ridotte, utilizzate dati specifici di alta qualità per la messa a punto e valutate regolarmente le prestazioni e l'efficienza dei costi. Questa ottimizzazione continua garantisce che i modelli continuino a fornire valore, mantenendo i costi operativi sotto controllo.
5. Esplorare le opzioni gratuite e a basso costo
Sfruttate le opzioni LLM gratuite o a basso costo, soprattutto durante le fasi di sviluppo e di test, per ridurre significativamente le spese senza compromettere la qualità. Queste alternative sono particolarmente preziose per la prototipazione, la formazione degli sviluppatori e i servizi non critici o rivolti all'interno.
Tuttavia, valutate attentamente i compromessi, considerando la privacy dei dati, le implicazioni sulla sicurezza e le potenziali limitazioni nelle funzionalità o nella personalizzazione. Valutate la scalabilità a lungo termine e i percorsi di migrazione per assicurarvi che le misure di risparmio siano in linea con i piani di crescita futuri e non si trasformino in ostacoli.
6. Ottimizzare la gestione della finestra contestuale
Gestire efficacemente le finestre di contesto per controllare i costi e mantenere la qualità dell'output. Implementare il dimensionamento dinamico del contesto in base alla complessità dell'attività, utilizzare tecniche di riassunto per condensare le informazioni rilevanti e impiegare approcci a finestra scorrevole per documenti o conversazioni lunghi. Analizzare regolarmente la relazione tra dimensione del contesto e qualità dell'output, regolando le finestre in base ai requisiti specifici dell'attività.
Considerate un approccio a livelli, utilizzando contesti più grandi solo quando necessario. Questa gestione strategica delle finestre di contesto può ridurre significativamente l'uso dei token e i costi associati, senza sacrificare le capacità di comprensione delle applicazioni LLM.
7. Implementare i sistemi multi-agente
Migliorare l'efficienza e l'economicità implementando architetture LLM multi-agente. Questo approccio prevede la collaborazione di più agenti di intelligenza artificiale per risolvere problemi complessi, consentendo di ottimizzare l'allocazione delle risorse e di ridurre il ricorso a modelli costosi e su larga scala.
I sistemi multi-agente consentono un'implementazione mirata dei modelli, migliorando l'efficienza complessiva del sistema e i tempi di risposta e riducendo l'utilizzo dei token. Per mantenere l'efficienza dei costi, è necessario implementare solidi meccanismi di debug, tra cui la registrazione delle comunicazioni tra gli agenti e l'analisi dei modelli di utilizzo dei token.
Ottimizzando la divisione del lavoro tra gli agenti, è possibile ridurre al minimo il consumo di token non necessari e massimizzare i vantaggi della gestione distribuita dei task.
8. Utilizzare gli strumenti di formattazione dell'output
Sfruttate gli strumenti di formattazione degli output per garantire un uso efficiente dei token e ridurre al minimo le esigenze di elaborazione aggiuntiva. Implementare output di funzioni forzate per specificare formati di risposta esatti, riducendo la variabilità e lo spreco di token. Questo approccio riduce la probabilità di output malformati e la necessità di chiamate API di chiarimento.
Considerate l'uso di output JSON per la loro rappresentazione compatta dei dati strutturati, la facilità di parsing e l'uso ridotto di token rispetto alle risposte in linguaggio naturale. Semplificando i flussi di lavoro LLM con questi strumenti di formattazione, è possibile ottimizzare in modo significativo l'uso dei token e ridurre i costi operativi, mantenendo al contempo output di alta qualità.
9. Integrare strumenti non-LLM
Completate le vostre applicazioni LLM con strumenti non LLM per ottimizzare costi ed efficienza. Incorporate script Python o approcci di programmazione tradizionali per le attività che non richiedono tutte le capacità di un LLM, come la semplice elaborazione dei dati o il processo decisionale basato su regole.
Quando si progettano i flussi di lavoro, è necessario bilanciare attentamente l'LLM e gli strumenti convenzionali in base alla complessità del compito, all'accuratezza richiesta e al potenziale risparmio economico. Eseguire analisi approfondite dei costi e dei benefici, considerando fattori quali i costi di sviluppo, i tempi di elaborazione, l'accuratezza e la scalabilità a lungo termine. Questo approccio ibrido spesso produce i migliori risultati in termini di prestazioni e di efficienza economica.
10. Audit e ottimizzazione regolari
Implementare un solido sistema di verifica e ottimizzazione periodica per garantire una gestione costante dei costi dell'LLM. Monitorate e analizzate costantemente il vostro utilizzo di LLM per identificare le inefficienze, come le query ridondanti o le finestre di contesto eccessive. Utilizzate strumenti di monitoraggio e analisi per affinare le vostre strategie di LLM ed eliminare il consumo di token non necessario.
Promuovete una cultura di consapevolezza dei costi all'interno della vostra organizzazione, incoraggiando i team a considerare attivamente le implicazioni di costo del loro utilizzo dell'LLM e a cercare opportunità di ottimizzazione. Rendendo l'efficienza dei costi una responsabilità condivisa, è possibile massimizzare il valore degli investimenti nell'intelligenza artificiale e tenere sotto controllo le spese a lungo termine.
Comprendere le strutture di prezzo LLM: Ingressi, uscite e finestre di contesto
Per le strategie di IA aziendali, la comprensione delle strutture di prezzo dei LLM è fondamentale per una gestione efficace dei costi. I costi operativi associati agli LLM possono aumentare rapidamente senza un'adeguata supervisione, portando potenzialmente a picchi di costo inaspettati che possono far deragliare i bilanci e ostacolare l'adozione diffusa.
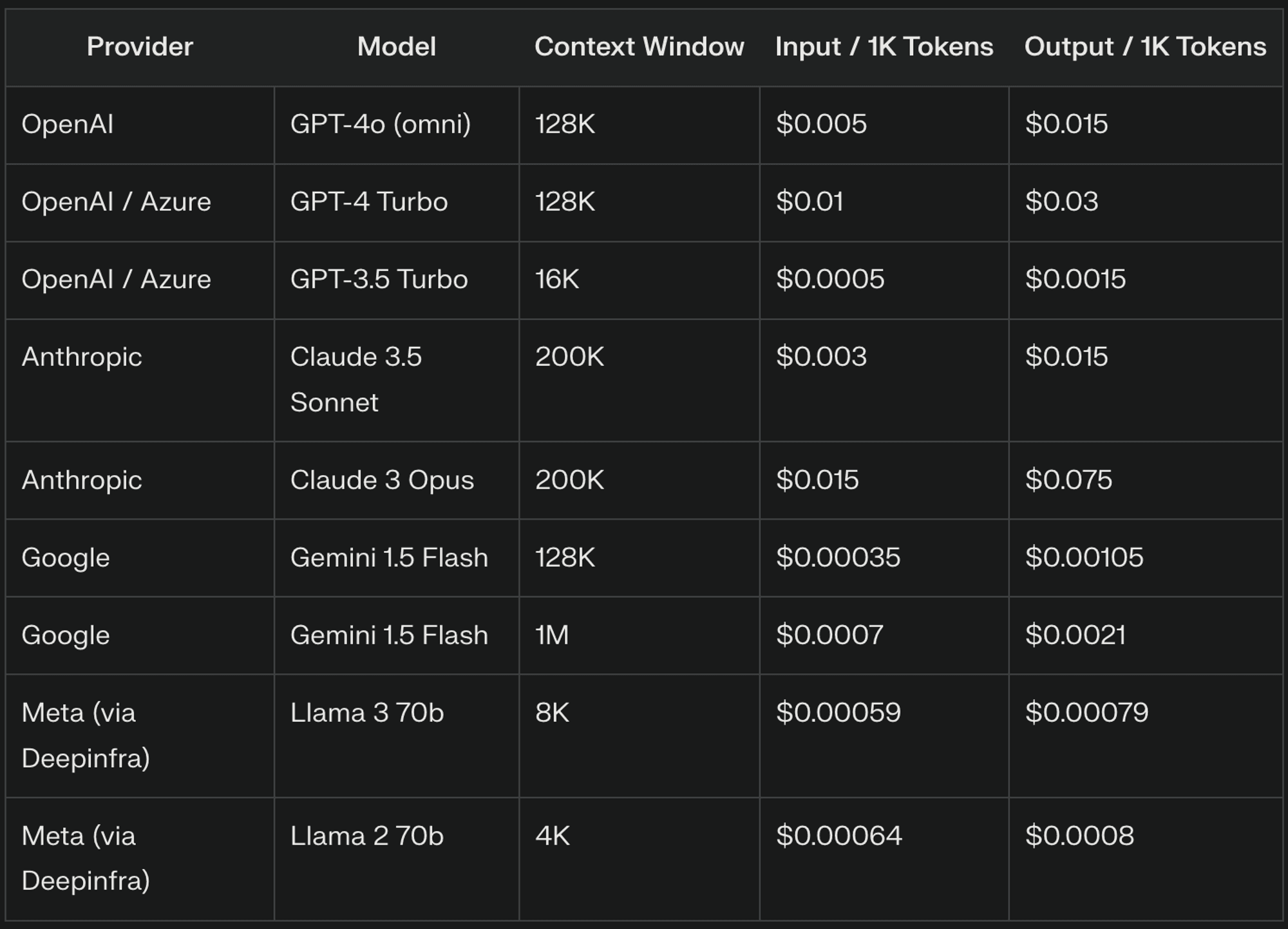
Il prezzo dell'LLM si articola in genere intorno a tre componenti principali: token di ingresso, token di uscita e finestre contestuali. Ognuno di questi elementi gioca un ruolo significativo nel determinare il costo complessivo dell'utilizzo degli LLM nelle vostre applicazioni.
Gettoni di ingresso: Cosa sono e come vengono addebitati
I token di input sono le unità fondamentali del testo elaborato dai LLM, che corrispondono tipicamente a parti di parole. Ad esempio, "The quick brown fox" potrebbe essere tokenizzato come ["The", "quick", "bro", "wn", "fox"], ottenendo così 5 token di input. I fornitori di LLM generalmente addebitano i token di input sulla base di una tariffa per mille token, con prezzi che variano significativamente tra i fornitori e le versioni del modello.
Per ottimizzare l'uso dei token di ingresso e ridurre i costi, considerate queste strategie:
Elaborare suggerimenti concisi: Concentratevi su istruzioni chiare e dirette.
Utilizzare una codifica efficiente: Scegliere metodi che rappresentino il testo con un minor numero di token.
Implementare i modelli di richiesta: Sviluppare strutture ottimizzate per compiti comuni.
Sfruttare le tecniche di compressione: Ridurre le dimensioni dell'input senza perdere informazioni critiche.
Gettoni di uscita: Comprendere i costi
I token di output rappresentano il testo generato dal LLM in risposta all'input dell'utente. Il numero di token di output può variare in modo significativo a seconda dell'attività e della configurazione del modello. I fornitori di LLM spesso applicano un prezzo più alto ai token di output rispetto a quelli di input, a causa della complessità computazionale della generazione del testo.
Per ottimizzare l'utilizzo dei gettoni di uscita e controllare i costi:
Impostare limiti chiari di lunghezza dell'output nei prompt o nelle chiamate API.
Utilizzate l'"apprendimento con pochi colpi" per guidare il modello verso risposte concise.
Implementare la post-elaborazione per tagliare i contenuti non necessari.
Considerate la possibilità di memorizzare nella cache le informazioni richieste di frequente.
Utilizzare gli strumenti di formattazione dell'output per garantire un uso efficiente dei token.
Finestre contestuali: Il fattore di costo nascosto
Le finestre di contesto determinano la quantità di testo precedente che il LLM considera quando genera una risposta, fondamentale per mantenere la coerenza e fare riferimento alle informazioni precedenti. Finestre di contesto più ampie aumentano il numero di token in ingresso elaborati, con conseguenti costi più elevati. Ad esempio, una finestra di contesto da 8.000 token potrebbe far pagare 7.000 token in una conversazione, mentre una finestra da 4.000 token potrebbe far pagare solo 3.000 token.
Per ottimizzare l'uso della finestra contestuale:
Implementare il dimensionamento dinamico del contesto in base ai requisiti dell'attività.
Utilizzare tecniche di sintesi per condensare le informazioni rilevanti.
Utilizzare approcci a finestre scorrevoli per documenti lunghi.
Considerate modelli più piccoli e specializzati per attività che richiedono un contesto limitato.
Analizzare regolarmente la relazione tra dimensione del contesto e qualità del prodotto.
Gestendo con attenzione questi componenti delle strutture tariffarie LLM, le aziende possono ridurre i costi operativi mantenendo la qualità delle loro applicazioni AI.
Il bilancio
La comprensione delle strutture dei prezzi LLM è essenziale per una gestione efficace dei costi nelle applicazioni AI aziendali. Conoscendo le sfumature dei token di input, dei token di output e delle finestre di contesto, le organizzazioni possono prendere decisioni informate sulla selezione dei modelli e sui modelli di utilizzo. L'implementazione di tecniche strategiche di gestione dei costi, come l'ottimizzazione dell'uso dei token e lo sfruttamento del caching, può portare a risparmi significativi.
Meta's Llama 3.1: Spingersi oltre i confini dell'intelligenza artificiale open source
Tra le grandi novità recenti, Meta ha annunciato Llama 3.1, il suo più avanzato modello linguistico open-source fino ad oggi. Questo rilascio segna una pietra miliare significativa nella democratizzazione della tecnologia AI, colmando potenzialmente il divario tra i modelli open-source e quelli proprietari.
Llama 3.1 si basa sui suoi predecessori con diversi progressi chiave:
Aumento delle dimensioni del modello: L'introduzione del modello di parametri 405B spinge i confini di ciò che è possibile fare nell'IA open-source.
Lunghezza del contesto estesa: Da 4K token in Llama 2 a 128K in Llama 3.1, consentendo una comprensione più complessa e ricca di sfumature dei testi più lunghi.
Funzionalità multilingue: L'ampliamento del supporto linguistico consente applicazioni più diversificate in diverse regioni e casi d'uso.
Miglioramento del ragionamento e dei compiti specializzati: Prestazioni migliorate in aree come il ragionamento matematico e la generazione di codice.
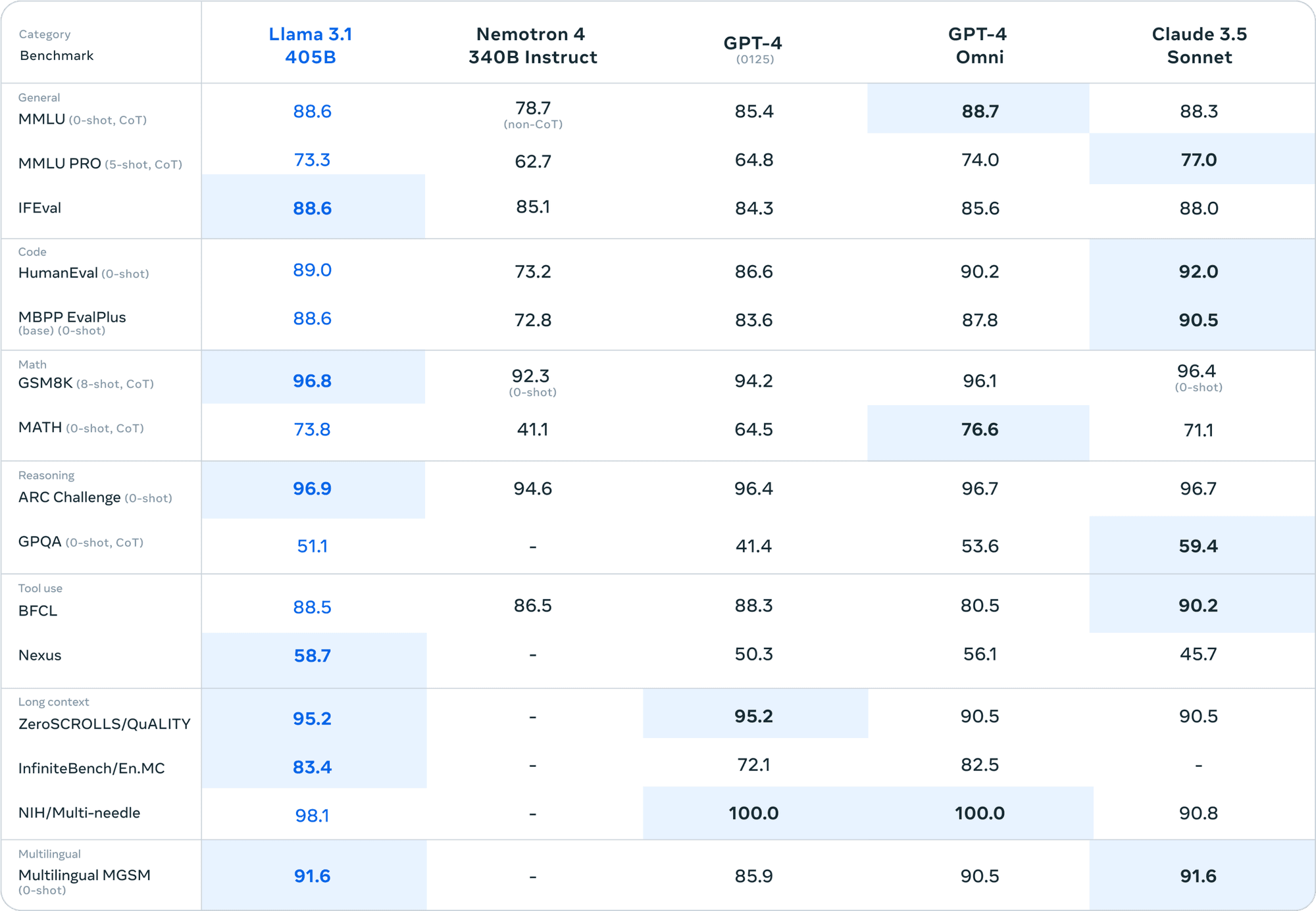
Rispetto a modelli closed-source come GPT-4 e Claude 3.5 Sonnet, Llama 3.1 405B si distingue in diversi benchmark. Questo livello di prestazioni in un modello open-source non ha precedenti.
Specifiche tecniche di Llama 3.1
Entrando nei dettagli tecnici, Llama 3.1 offre una gamma di dimensioni del modello per soddisfare le diverse esigenze e risorse di calcolo:
Modello a parametri 8B: Adatto per applicazioni leggere e dispositivi edge.
Modello di parametro 70B: Un equilibrio tra prestazioni e requisiti di risorse.
Modello di parametro 405B: Il modello di punta, che spinge i limiti delle capacità dell'intelligenza artificiale open-source.
La metodologia di addestramento di Llama 3.1 ha coinvolto un enorme set di dati di oltre 15 trilioni di token, significativamente più grande dei suoi predecessori.
Dal punto di vista architetturale, Llama 3.1 mantiene un modello di trasformatore solo decodificatore, dando priorità alla stabilità dell'addestramento rispetto ad approcci più sperimentali come la miscela di esperti.
Tuttavia, Meta ha implementato diverse ottimizzazioni per consentire un addestramento e un'inferenza efficienti su una scala senza precedenti:
Infrastruttura di formazione scalabile: Utilizzando oltre 16.000 GPU H100 per addestrare il modello 405B.
Procedura iterativa di post-formazione: Impiegare la messa a punto supervisionata e l'ottimizzazione diretta delle preferenze per migliorare le capacità specifiche.
Tecniche di quantizzazione: Riduzione del modello da 16 bit a 8 bit per un'inferenza più efficiente, che consente l'implementazione su singoli nodi server.
Capacità innovative
Llama 3.1 introduce diverse funzionalità innovative che lo distinguono nel panorama dell'intelligenza artificiale:
Lunghezza del contesto espanso: Il passaggio a una finestra di contesto da 128K token è una svolta. Questa capacità ampliata consente a Llama 3.1 di elaborare e comprendere pezzi di testo molto più lunghi, permettendo:
Supporto multilingue: Il supporto di Llama 3.1 per otto lingue amplia notevolmente la sua applicabilità a livello globale.
Ragionamento avanzato e uso degli strumenti: Il modello dimostra sofisticate capacità di ragionamento e la capacità di utilizzare efficacemente strumenti esterni.
Generazione di codice e abilità matematica: Llama 3.1 mostra notevoli capacità nei settori tecnici:
Generazione di codice funzionale di alta qualità in più linguaggi di programmazione
Risolvere con precisione problemi matematici complessi
Assistenza nella progettazione e nell'ottimizzazione degli algoritmi
Le promesse e le potenzialità di Llama 3.1
Il rilascio di Llama 3.1 da parte di Meta segna un momento cruciale nel panorama dell'IA, democratizzando l'accesso a capacità di IA di livello avanzato. Offrendo un modello a 405B parametri con prestazioni all'avanguardia, supporto multilingue ed estensione della lunghezza del contesto, il tutto all'interno di un framework open-source, Meta ha stabilito un nuovo standard per l'IA accessibile e potente. Questa mossa non solo sfida il dominio dei modelli closed-source, ma apre anche la strada a un'innovazione e a una collaborazione senza precedenti nella comunità dell'IA.
Grazie per aver dedicato del tempo alla lettura di AI & YOU!
Per ulteriori contenuti sull'IA aziendale, tra cui infografiche, statistiche, guide, articoli e video, seguite Skim AI su LinkedIn
Siete un fondatore, un CEO, un Venture Capitalist o un investitore alla ricerca di servizi di consulenza sull'IA, di sviluppo frazionario dell'IA o di due diligence? Ottenete la guida necessaria per prendere decisioni informate sulla strategia di prodotto AI della vostra azienda e sulle opportunità di investimento.
Realizziamo soluzioni AI personalizzate per aziende sostenute da Venture Capital e Private Equity nei seguenti settori: Tecnologia medica, aggregazione di notizie e contenuti, produzione di film e foto, tecnologia educativa, tecnologia legale, Fintech e criptovalute.


