
10 strategie comprovate per ridurre i costi dell'LLM



Poiché le organizzazioni si affidano sempre più a modelli linguistici di grandi dimensioni (LLM) per varie applicazioni, dai chatbot del servizio clienti alla generazione di contenuti, la sfida della gestione dei costi degli LLM è venuta alla ribalta. I costi operativi associati all'implementazione e alla manutenzione degli LLM possono rapidamente andare fuori controllo senza un'adeguata supervisione e strategie di ottimizzazione. Impennate inaspettate dei costi possono far deragliare i bilanci e ostacolare l'adozione diffusa di questi potenti strumenti.
Questo blog post esplorerà dieci strategie comprovate per aiutare la vostra azienda a gestire efficacemente i costi dei LLM, assicurandovi di poter sfruttare il pieno potenziale di questi modelli mantenendo l'efficienza dei costi e il controllo delle spese.
Strategia 1: Selezione intelligente del modello
Una delle strategie più efficaci per la gestione dei costi LLM consiste nel selezionare il modello giusto per ogni attività. Non tutte le applicazioni richiedono i modelli più avanzati e più grandi disponibili. Adattando la complessità del modello ai requisiti dell'attività, è possibile ridurre significativamente i costi senza sacrificare le prestazioni.
Quando si implementano applicazioni LLM, è fondamentale valutare la complessità di ogni compito e scegliere un modello che soddisfi le esigenze specifiche. Per esempio, semplici compiti di classificazione o di risposta a domande di base potrebbero non richiedere tutte le capacità di GPT-4o o di altri modelli di grandi dimensioni e ad alta intensità di risorse.
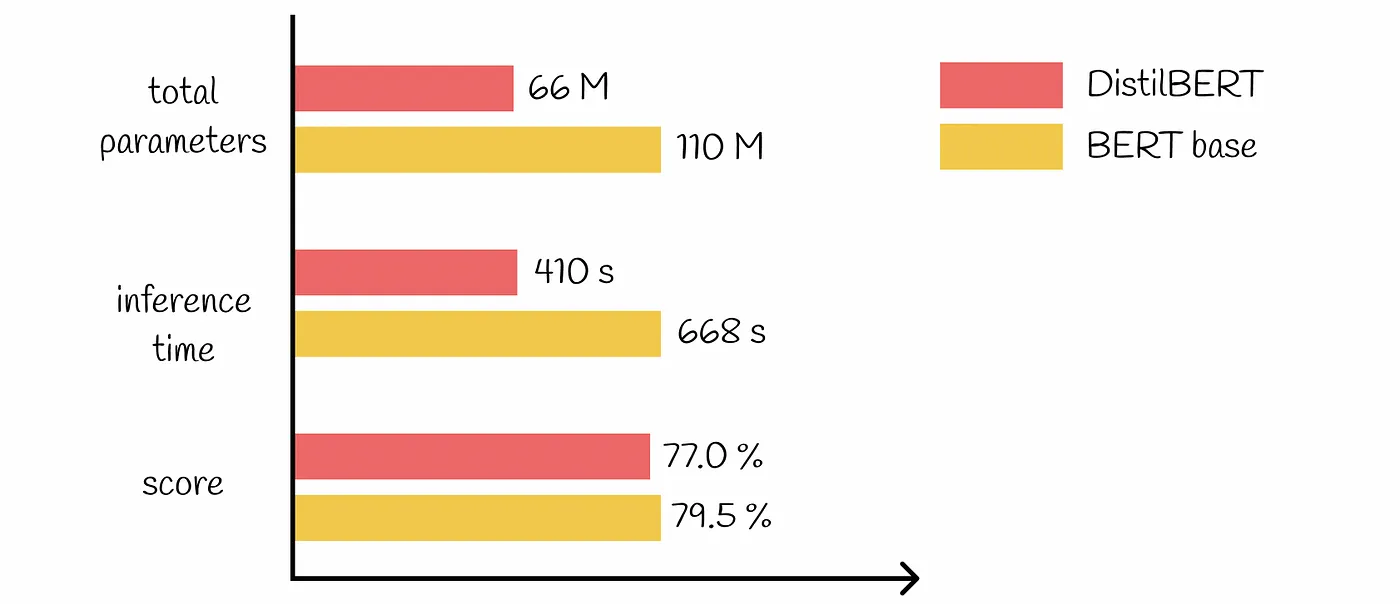
Sono disponibili molti modelli pre-addestrati di varie dimensioni e complessità. La scelta di modelli più piccoli ed efficienti per le attività più semplici può portare a un sostanziale risparmio sui costi. Ad esempio, si può utilizzare un modello leggero come Distillatore per l'analisi del sentiment invece di un modello più complesso come BERT-Grande.
Strategia 2: implementare un robusto monitoraggio dell'utilizzo
Una gestione efficace dei costi LLM inizia con una chiara comprensione di come questi modelli vengono utilizzati all'interno della vostra organizzazione. L'implementazione di solidi meccanismi di monitoraggio dell'utilizzo è essenziale per identificare le aree di inefficienza e le opportunità di ottimizzazione.
Per ottenere una visione completa del vostro Utilizzo dell'LLMÈ fondamentale tracciare le metriche a più livelli:
Livello di conversazione: Monitorare l'utilizzo dei token, i tempi di risposta e le chiamate di modello per le singole interazioni.
Livello utente: Analizzare gli schemi di utilizzo dei modelli tra i diversi utenti o reparti.
Livello aziendale: Aggregare i dati per comprendere il consumo complessivo di LLM e le tendenze.
Sono disponibili diversi strumenti e piattaforme per monitorare efficacemente l'utilizzo dell'LLM. Questi possono includere:
Cruscotti analitici incorporati forniti dai fornitori di servizi LLM
Strumenti di monitoraggio di terze parti progettati specificamente per applicazioni AI e ML
Soluzioni di tracciamento personalizzate integrate con l'infrastruttura esistente
Analizzando i dati di utilizzo, si possono scoprire preziose intuizioni che portano a strategie di riduzione dei costi. Ad esempio, si potrebbe scoprire che alcuni reparti utilizzano eccessivamente modelli più costosi per attività che potrebbero essere gestite da alternative a basso costo. Oppure si possono identificare schemi di query ridondanti che potrebbero essere affrontati attraverso il caching o altre tecniche di ottimizzazione.
Strategia 3: Ottimizzare l'ingegneria dei prompt
Ingegneria tempestiva è un aspetto critico del lavoro con gli LLM e può avere un impatto significativo sulle prestazioni e sui costi. Ottimizzando i prompt, è possibile ridurre l'uso dei token e migliorare l'efficienza delle applicazioni LLM.
Per minimizzare il numero di chiamate API e ridurre i costi associati:
Utilizzate istruzioni chiare e specifiche nei vostri suggerimenti
Implementare la gestione degli errori per risolvere i problemi più comuni senza richiedere query LLM aggiuntive.
Utilizzate modelli di prompt che si sono dimostrati efficaci per compiti specifici.
Il modo in cui si strutturano le richieste può influenzare in modo significativo il numero di token elaborati dal modello. Alcune buone pratiche includono:
Essere concisi ed evitare contesti inutili
Utilizzare tecniche di formattazione come punti elenco o elenchi numerati per organizzare le informazioni in modo efficiente.
Sfruttare le funzioni integrate o i parametri forniti dal servizio LLM per controllare la lunghezza e il formato dell'output.
Implementando queste tecniche di ottimizzazione immediata, è possibile ridurre sostanzialmente l'utilizzo dei token e, di conseguenza, i costi associati alle applicazioni LLM.
Strategia 4: sfruttare la messa a punto per la specializzazione
La messa a punto di modelli pre-addestrati per compiti specifici è una tecnica potente nella gestione dei costi del LLM. Adattando i modelli alle vostre esigenze specifiche, potete ottenere prestazioni migliori con modelli più piccoli e più efficienti, con un notevole risparmio sui costi.
Invece di affidarsi esclusivamente a LLM di grandi dimensioni e di uso generale, si può pensare di mettere a punto modelli più piccoli per compiti specializzati. Questo approccio consente di sfruttare le conoscenze dei modelli pre-addestrati, ottimizzando al contempo il caso d'uso specifico.
Sebbene la messa a punto richieda un investimento iniziale, può portare a sostanziali risparmi a lungo termine. I modelli perfezionati spesso richiedono meno token per ottenere risultati uguali o migliori, riducendo i costi di inferenza. Possono anche richiedere meno tentativi o correzioni grazie alla maggiore precisione, riducendo ulteriormente i costi. Inoltre, i modelli specializzati possono spesso essere più piccoli, riducendo l'overhead computazionale e le spese associate.
Per massimizzare i vantaggi del fine-tuning, iniziate con un modello pre-addestrato di dimensioni ridotte come base. Utilizzate dati di alta qualità e specifici per il dominio per la messa a punto e valutate regolarmente le prestazioni e l'efficienza del modello. Questo processo di ottimizzazione continua garantisce che i modelli perfezionati continuino a fornire valore, mantenendo i costi sotto controllo.
Strategia 5: Esplorare le opzioni gratuite e a basso costo
Per molte aziende, soprattutto durante le fasi di sviluppo e di test, l'utilizzo di opzioni LLM gratuite o a basso costo possono ridurre significativamente le spese senza compromettere la qualità. Queste opzioni sono particolarmente utili per la prototipazione di nuove applicazioni LLM, per la formazione degli sviluppatori sull'implementazione di LLM e per l'esecuzione di servizi non critici o rivolti all'interno.
Tuttavia, anche se le opzioni gratuite possono ridurre drasticamente i costi, è fondamentale considerare i compromessi. Le implicazioni sulla privacy e sulla sicurezza dei dati devono essere valutate attentamente, soprattutto quando si tratta di informazioni sensibili. Inoltre, bisogna essere consapevoli delle potenziali limitazioni nelle capacità del modello o nelle opzioni di personalizzazione. Considerate la scalabilità a lungo termine e i percorsi di migrazione per garantire che le misure di risparmio non diventino ostacoli alla crescita futura.
Strategia 6: Ottimizzare la gestione della finestra contestuale
La dimensione della finestra di contesto nei LLM può avere un impatto significativo sia sulle prestazioni che sui costi. Una gestione efficace delle finestre di contesto è fondamentale per controllare le spese e mantenere la qualità dei risultati. Finestre di contesto più ampie consentono una comprensione più completa, ma hanno un costo maggiore a causa dell'aumento dell'utilizzo di token per ogni interrogazione e dei requisiti computazionali.
Per ottimizzare l'uso della finestra di contesto, si può considerare l'implementazione di un dimensionamento dinamico del contesto in base alla complessità dell'attività. Utilizzate tecniche di riassunto per condensare le informazioni rilevanti e approcci a finestra scorrevole per documenti o conversazioni lunghe. Questi metodi possono aiutarvi a trovare il punto di equilibrio tra comprensione ed efficienza economica.
Analizzate regolarmente la relazione tra le dimensioni del contesto e la qualità dell'output per perfezionare il vostro approccio. Regolate le finestre di contesto in base ai requisiti specifici dell'attività e prendete in considerazione l'implementazione di un approccio a livelli, utilizzando contesti più grandi solo quando necessario. Gestendo con attenzione le finestre di contesto, è possibile ridurre in modo significativo l'uso dei token e i costi associati, senza sacrificare la qualità degli output LLM.
Strategia 7: implementare sistemi multi-agente
I sistemi multi-agente offrono un approccio potente per migliorare l'efficienza e l'economicità delle applicazioni di LLM. Distribuendo i compiti tra agenti specializzati, le aziende possono ottimizzare l'allocazione delle risorse e ridurre i costi complessivi del LLM.
Le architetture LLM multi-agente prevedono più Agenti AI collaborare per risolvere problemi complessi. Questo approccio può includere agenti specializzati per i diversi aspetti di un compito, strutture gerarchiche con agenti di supervisione e agenti lavoratori, o la risoluzione collaborativa di problemi tra più LLM. Implementando tali sistemi, le organizzazioni possono ridurre la loro dipendenza da modelli costosi e su larga scala per ogni compito.
I vantaggi in termini di costi della gestione distribuita dei compiti sono significativi. I sistemi multi-agente consentono di:
Allocazione ottimizzata delle risorse in base alla complessità del compito
Miglioramento dell'efficienza complessiva del sistema e dei tempi di risposta
Riduzione dell'utilizzo dei token grazie alla distribuzione mirata del modello
Tuttavia, per mantenere l'efficienza dei costi nei sistemi multi-agente, è fondamentale implementare solidi meccanismi di debug. Ciò include la registrazione e il monitoraggio delle comunicazioni tra agenti, l'analisi dei modelli di utilizzo dei token per identificare gli scambi ridondanti e l'ottimizzazione della divisione del lavoro tra gli agenti per ridurre al minimo il consumo di token non necessari.
Strategia 8: utilizzare gli strumenti di formattazione dell'output
La corretta formattazione dell'output è un fattore chiave nella gestione dei costi di LLM. Garantendo un uso efficiente dei token e riducendo al minimo la necessità di ulteriori elaborazioni, le aziende possono ridurre significativamente i costi operativi.
Questi strumenti offrono potenti capacità di forzare gli output delle funzioni, consentendo agli sviluppatori di specificare i formati esatti delle risposte LLM. Questo approccio riduce la variabilità degli output e minimizza lo spreco di token, garantendo che il modello generi solo le informazioni necessarie.
La riduzione della variabilità degli output LLM ha un impatto diretto sui costi associati. Risposte coerenti e ben strutturate riducono la probabilità di output malformati o inutilizzabili, il che a sua volta riduce la necessità di ulteriori chiamate API per chiarire o riformattare le informazioni.
L'implementazione di output JSON può essere particolarmente efficace per l'efficienza. JSON offre una rappresentazione compatta dei dati strutturati, una facile analisi e integrazione con vari sistemi e un uso ridotto di token rispetto alle risposte in linguaggio naturale. Sfruttando questi strumenti di formattazione degli output, le aziende possono semplificare i loro flussi di lavoro LLM e ottimizzare l'uso dei token.
Strategia 9: Integrare gli strumenti non-LLM
Pur essendo potenti, gli LLM non sono sempre la soluzione più conveniente per ogni attività. L'integrazione di soluzioni nonStrumenti LLM nei vostri flussi di lavoro può ridurre in modo significativo i costi operativi, mantenendo al contempo risultati di alta qualità.
L'integrazione di script Python per la gestione di compiti specifici che non richiedono le capacità complete di un LLM può portare a sostanziali risparmi sui costi. Ad esempio, una semplice elaborazione dei dati o un processo decisionale basato su regole possono spesso essere gestiti in modo più efficiente con approcci di programmazione tradizionali.
Quando si cerca di bilanciare LLM e strumenti tradizionali nei flussi di lavoro, occorre considerare la complessità dell'attività, l'accuratezza richiesta e il potenziale risparmio economico. Un approccio ibrido che sfrutti i punti di forza di entrambi gli LLM e degli strumenti tradizionali offre spesso i migliori risultati in termini di prestazioni ed efficienza economica.
È fondamentale condurre un'analisi approfondita dei costi e dei benefici degli approcci ibridi. Questa analisi dovrebbe considerare fattori quali:
Costi di sviluppo e manutenzione di strumenti personalizzati
Tempo di elaborazione e requisiti delle risorse
Precisione e affidabilità dei risultati
Scalabilità e flessibilità a lungo termine
Strategia 10: Audit e ottimizzazione regolari
Stabilire tecniche di gestione dei costi della LLM è un processo continuo che richiede una costante vigilanza e ottimizzazione. Un controllo regolare dell'utilizzo e dei costi della LLM è fondamentale per identificare le inefficienze e implementare miglioramenti per il controllo dei costi.
L'importanza della gestione e della riduzione dei costi non può essere sopravvalutata. Con l'evoluzione e la scalabilità delle applicazioni LLM, emergeranno nuove sfide e opportunità di ottimizzazione. Monitorando e analizzando costantemente l'utilizzo dell'LLM, è possibile evitare potenziali sforamenti dei costi e garantire che gli investimenti nell'IA offrano il massimo valore.
Per identificare i token sprecati, è necessario implementare solidi strumenti di monitoraggio e analisi. Cercate modelli di query ridondanti, finestre contestuali eccessive o design inefficienti dei prompt. Utilizzate questi dati per affinare le vostre strategie di LLM ed eliminare il consumo inutile di token.
Infine, la promozione di una cultura di consapevolezza dei costi all'interno dell'organizzazione è fondamentale per il successo a lungo termine nella gestione efficiente delle risorse LLM. Incoraggiate i team a considerare le implicazioni di costo del loro utilizzo di LLM e a cercare attivamente le opportunità di ottimizzazione e di controllo delle spese. Rendendo l'efficienza dei costi una responsabilità condivisa, è possibile garantire che la vostra azienda raccolga tutti i vantaggi della tecnologia LLM mantenendo le spese sotto controllo.
Il bilancio
Poiché i modelli linguistici di grandi dimensioni continuano a influenzare le applicazioni di intelligenza artificiale delle aziende, la gestione dei costi LLM diventa fondamentale per il successo a lungo termine. Implementando le dieci strategie descritte in questo articolo, dalla selezione intelligente dei modelli all'audit e all'ottimizzazione regolari, la vostra azienda può ridurre significativamente i costi dei LLM mantenendo o addirittura migliorando le prestazioni. Ricordate che una gestione efficace dei costi è un processo continuo che richiede monitoraggio, analisi e adattamento continui. Promuovendo una cultura di attenzione ai costi e sfruttando gli strumenti e le tecniche giuste, è possibile sfruttare tutto il potenziale degli LLM tenendo sotto controllo i costi operativi e assicurando che gli investimenti nell'IA forniscano il massimo valore all'azienda.
Non esitate a contattarci per saperne di più sulla gestione dei costi dell'LLM.


