
Tutoriel : Comment affiner le BERT pour la synthèse extractive
Tutoriel : Comment affiner le BERT pour la synthèse extractive
Publié à l'origine par Chris Tran, chercheur en apprentissage automatique chez Skim AI1. Introduction
Le résumé est depuis longtemps un défi dans le domaine du traitement du langage naturel. Pour générer une version courte d'un document tout en conservant les informations les plus importantes, nous avons besoin d'un modèle capable d'extraire avec précision les points clés tout en évitant les informations répétitives. Heureusement, des travaux récents en TAL, tels que les modèles transformateurs et le pré-entraînement des modèles de langage, ont permis de faire progresser l'état de l'art en matière de résumé.
Dans cet article, nous allons explorer BERTSUM, une variante simple de BERT, pour le résumé extractif à partir de Résumés de textes à l'aide d'encodeurs pré-entraînés (Liu et al., 2019). Ensuite, dans un effort pour rendre le résumé extractif encore plus rapide et plus petit pour les appareils à faibles ressources, nous affinerons DistilBERT (Sanh et al, 2019) et MobileBERT (Sun et al, 2019), deux versions allégées récentes de BERT, et discutons de nos résultats.
2. Synthèse extractive
Il existe deux types de résumés : abstractive et résumé extractif. Le résumé abstrait consiste essentiellement à réécrire les points clés, tandis que le résumé extractif génère un résumé en copiant directement les passages/phrases les plus importants d'un document.
Le résumé abstrait est plus difficile pour les humains et plus coûteux en termes de calcul pour les machines. Cependant, le choix du meilleur résumé dépend de l'objectif de l'utilisateur final. Si vous rédigez une dissertation, le résumé abstractif peut être un meilleur choix. En revanche, si vous faites des recherches et que vous avez besoin d'un résumé rapide de ce que vous lisez, le résumé extractif sera plus utile.
Dans cette section, nous allons explorer l'architecture de notre modèle de résumé extractif. Le résumeur BERT comporte deux parties : un codeur BERT et un classificateur de résumé.
Codeur BERT

L'architecture générale de BERTSUM
Notre codeur BERT est le codeur de base BERT pré-entraîné de la tâche de modélisation du langage masqué (Devlin et autres, 2018). La tâche de résumé extractif est un problème de classification binaire au niveau de la phrase. Nous voulons attribuer à chaque phrase une étiquette $y_i dans {0, 1}$ indiquant si la phrase doit être incluse dans le résumé final. Par conséquent, nous devons ajouter un jeton [CLS] avant chaque phrase. Après avoir effectué une passe avant dans l'encodeur, la dernière couche cachée de ces [CLS] seront utilisés pour représenter nos phrases.
Résumé Classificateur
Après avoir obtenu la représentation vectorielle de chaque phrase, nous pouvons utiliser une simple couche d'anticipation comme classificateur afin d'obtenir un score pour chaque phrase. Dans cet article, l'auteur a expérimenté un simple classificateur linéaire, un réseau neuronal récurrent et un petit modèle Transformer à 3 couches. Le classificateur Transformer donne les meilleurs résultats, montrant que les interactions entre les phrases par le biais du mécanisme d'auto-attention sont importantes pour sélectionner les phrases les plus importantes.
Ainsi, dans le codeur, nous apprenons les interactions entre les tokens de notre document, tandis que dans le classificateur de résumé, nous apprenons les interactions entre les phrases.
3. Rendre le résumé encore plus rapide
Les modèles de transformateurs atteignent des performances de pointe dans la plupart des tests de NLP ; cependant, l'entraînement et la réalisation de prédictions à partir de ces modèles sont coûteux en termes de calcul. Dans le but de rendre le résumé plus léger et plus rapide pour être déployé sur des appareils à faibles ressources, j'ai modifié le modèle de Transformer. codes sources fourni par les auteurs de BERTSUM pour remplacer l'encodeur BERT par DistilBERT et MobileBERT. Les couches récapitulatives ne sont pas modifiées.
Voici les pertes d'entraînement de ces 3 variantes : TensorBoard

Bien qu'il soit 40% plus petit que BERT-base, DistilBERT a les mêmes pertes d'entraînement que BERT-base, tandis que MobileBERT est légèrement moins performant. Le tableau ci-dessous montre leurs performances sur l'ensemble de données CNN/DailyMail, la taille et la durée d'exécution d'une passe avant :
| Modèles | ROUGE-1 | ROUGE-2 | ROUGE-L | Temps d'inférence* | Taille | Params |
|---|---|---|---|---|---|---|
| bert-base | 43.23 | 20.24 | 39.63 | 1.65 s | 475 MB | 120.5 M |
| distilbert | 42.84 | 20.04 | 39.31 | 925 ms | 310 MB | 77.4 M |
| mobilebert | 40.59 | 17.98 | 36.99 | 609 ms | 128 MB | 30.8 M |
*Temps d'exécution moyen d'une passe avant sur un seul GPU sur un ordinateur portable Google Colab standard
Avec 45% de plus, DistilBERT a presque les mêmes performances que BERT-base. MobileBERT conserve les 94% de performance de BERT-base, tout en étant 4x plus petit que BERT-base et 2.5x plus petit que DistilBERT. Dans l'article MobileBERT, il est montré que MobileBERT est significativement plus performant que DistilBERT sur SQuAD v1.1. Cependant, ce n'est pas le cas pour le résumé extractif. Il s'agit néanmoins d'un résultat impressionnant pour MobileBERT avec une taille de disque de seulement 128 Mo.
4. Résumons
Tous les points de contrôle prédéfinis, les détails de la formation et les instructions d'installation peuvent être consultés sur le site suivant ce dépôt GitHub. En outre, j'ai déployé une démonstration de BERTSUM avec l'encodeur MobileBERT.
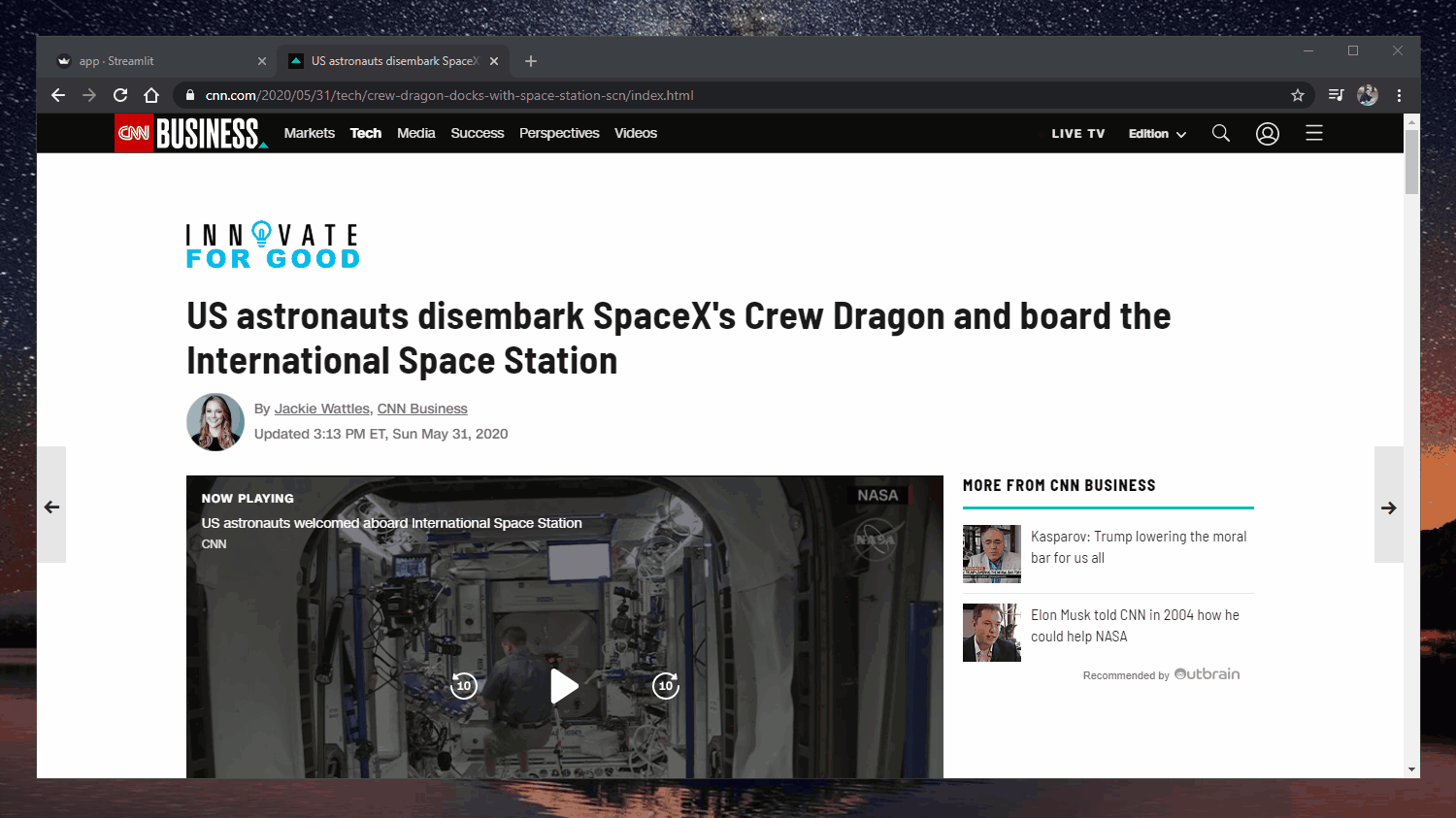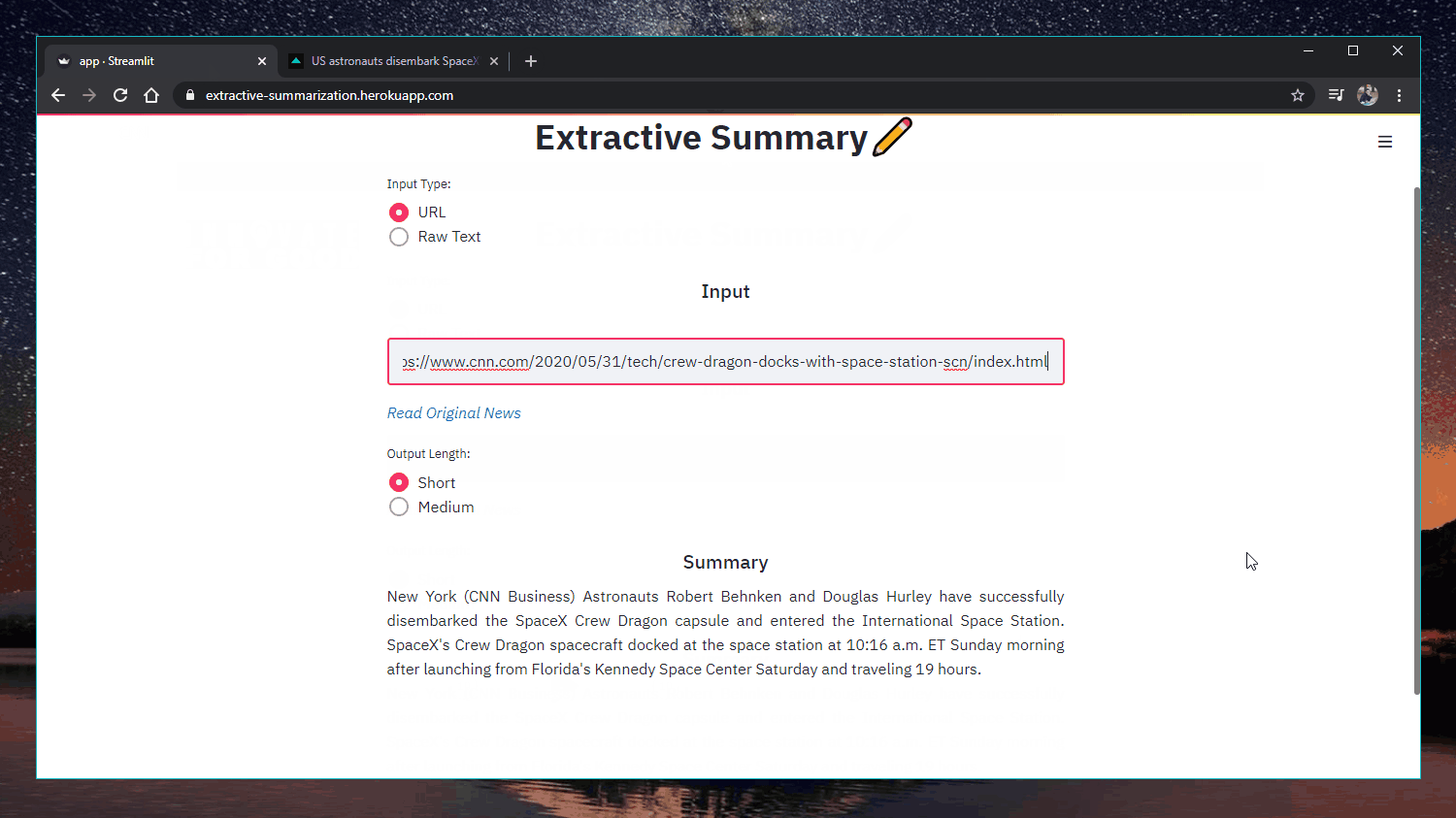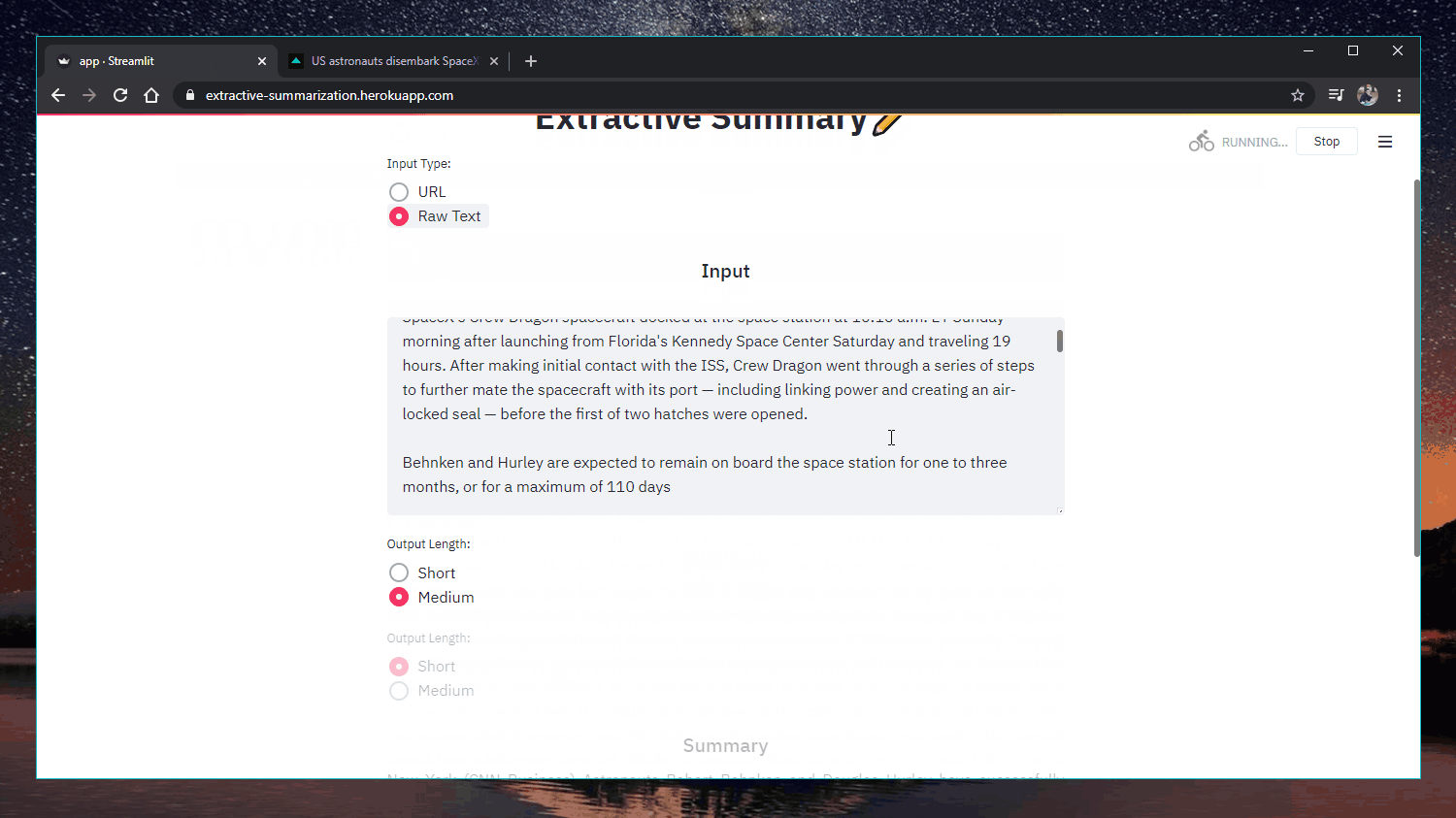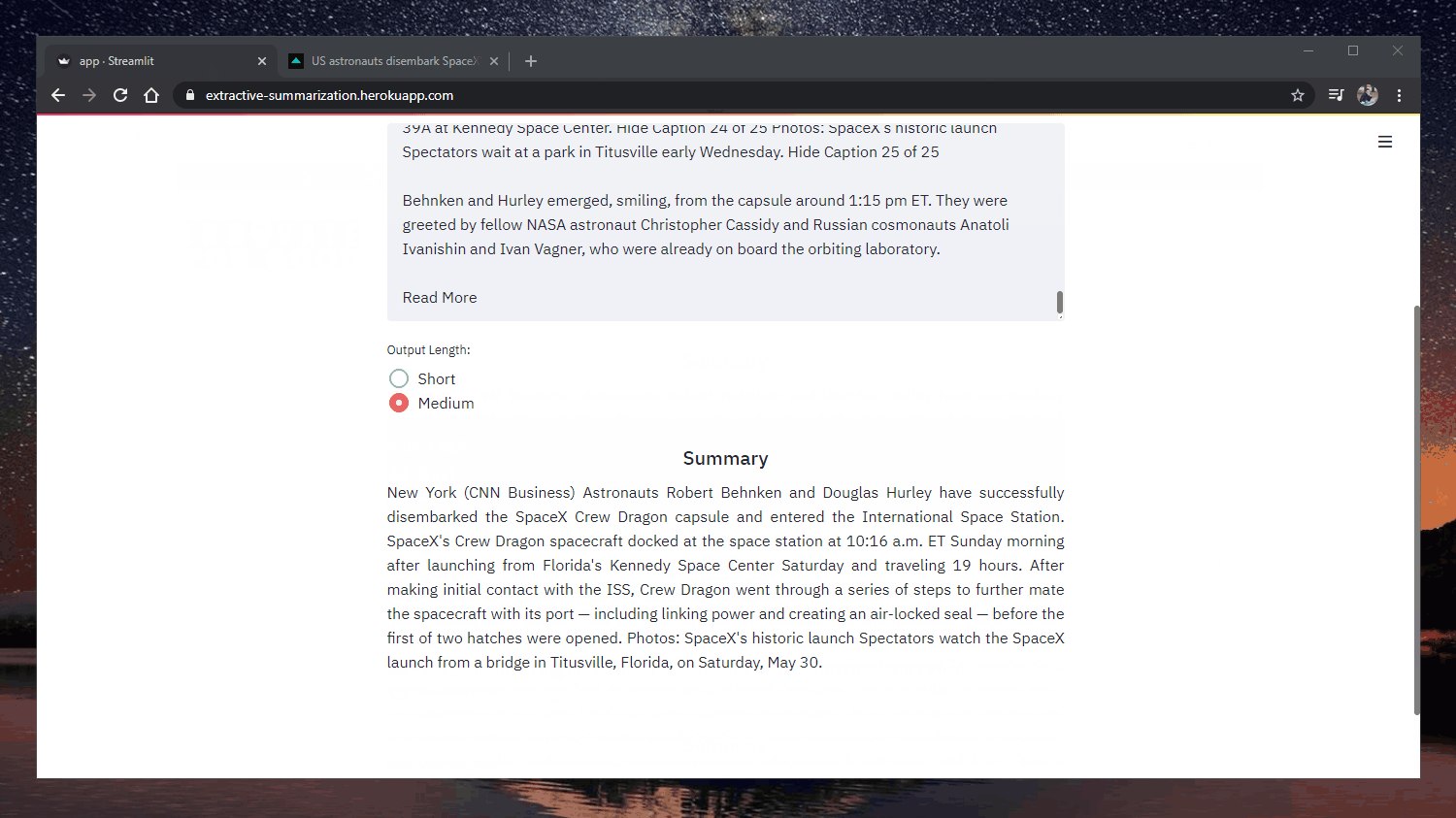
Application web : https://extractive-summarization.herokuapp.com/
Code :
import torch
from models.model_builder import ExtSummarizer
from ext_sum import summarize
# Charger le modèle
model_type = 'mobilebert' #@param ['bertbase', 'distilbert', 'mobilebert']
checkpoint = torch.load(f'checkpoints/{model_type}_ext.pt', map_location='cpu')
model = ExtSummarizer(checkpoint=checkpoint, bert_type=model_type, device='cpu')
# Résumé de l'exécution
input_fp = 'raw_data/input.txt' (données brutes/entrée.txt)
result_fp = 'results/summary.txt' (résultats/résumé.txt)
summary = summarize(input_fp, result_fp, model, max_length=3)
print(résumé)
Résumé de l'échantillon
Original : https://www.cnn.com/2020/05/22/business/hertz-bankruptcy/index.html
En se déclarant en faillite, Hertz affirme vouloir poursuivre ses activités tout en restructurant ses dettes et en émergeant en tant qu'entreprise financièrement plus saine.
une entreprise financièrement plus saine. L'entreprise loue des voitures depuis 1918, date à laquelle elle s'est installée avec une douzaine de modèles Ford T. Elle a survécu à la Grande Dépression et au quasi-arrêt de la production automobile américaine.
Elle a survécu à la Grande Dépression, au quasi-arrêt de la production automobile américaine pendant la Seconde Guerre mondiale et à de nombreux chocs pétroliers.
et à de nombreux chocs pétroliers. "L'impact de Covid-19 sur la demande de voyages a été soudain et dramatique, entraînant un déclin brutal de l'entreprise.
de l'entreprise et des réservations futures", a déclaré l'entreprise.
5. Conclusion
Dans cet article, nous avons exploré BERTSUM, une variante simple de BERT, pour le résumé extractif d'un article. Résumés de textes à l'aide d'encodeurs pré-entraînés (Liu et al., 2019). Ensuite, dans le but de rendre le résumé extractif encore plus rapide et plus petit pour les appareils à faibles ressources, nous avons affiné DistilBERT (Sanh et al., 2019) et MobileBERT (Sun et al., 2019) sur les ensembles de données CNN/DailyMail.
DistilBERT conserve les performances de BERT-base en matière de résumé extractif tout en étant 45% plus petit. MobileBERT est 4 fois plus petit et 2,7 fois plus rapide que BERT-base tout en conservant 94% de ses performances.
Enfin, nous avons déployé une application web de démonstration de MobileBERT pour le résumé extractif à l'adresse suivante https://extractive-summarization.herokuapp.com/.


