Tutorial: Cómo afinar el BERT para la síntesis extractiva
Tutorial: Cómo afinar el BERT para la síntesis extractiva
Originally published by Skim AI's Machine Learning Researcher, Chris Tran1. Introducción
La síntesis es desde hace tiempo un reto en el Procesamiento del Lenguaje Natural. Para generar una versión breve de un documento conservando su información más importante, necesitamos un modelo capaz de extraer con precisión los puntos clave evitando la información repetitiva. Afortunadamente, algunos trabajos recientes en PNL, como los modelos transformadores y el preentrenamiento de modelos lingüísticos, han hecho avanzar el estado del arte en materia de resumen.
En este artículo, exploraremos BERTSUM, una variante sencilla de BERT, para el resumen extractivo a partir de Resumir textos con codificadores preentrenados (Liu et al., 2019). Luego, en un esfuerzo por hacer que el resumen extractivo sea aún más rápido y pequeño para dispositivos de bajos recursos, afinaremos DistilBERT (Sanh y otros, 2019) y MobileBERT (Sun y otros, 2019), dos versiones lite recientes de BERT, y analizamos nuestros resultados.
2. Resumen extractivo
Existen dos tipos de resumen: abstracción y resumen extractivo. El resumen abstractivo consiste básicamente en reescribir los puntos clave, mientras que el resumen extractivo genera el resumen copiando directamente los espacios/frase más importantes de un documento.
El resumen abstracto es más difícil para los humanos y también más caro computacionalmente para las máquinas. Sin embargo, qué resumen es mejor depende del propósito del usuario final. Si estás escribiendo un ensayo, el resumen abstracto puede ser la mejor opción. Por otro lado, si estás investigando y necesitas un resumen rápido de lo que estás leyendo, el resumen extractivo te resultará más útil.
En esta sección exploraremos la arquitectura de nuestro modelo de resumen extractivo. El resumidor BERT consta de 2 partes: un codificador BERT y un clasificador de resumen.
Codificador BERT

La arquitectura general de BERTSUM
Nuestro codificador BERT es el codificador BERT-base preentrenado de la tarea de modelado de lenguaje enmascarado (Devlin y otros, 2018). La tarea de resumen extractivo es un problema de clasificación binaria a nivel de frase. Queremos asignar a cada frase una etiqueta $y_i \in {0, 1}$ que indique si la frase debe incluirse en el resumen final. Por lo tanto, tenemos que añadir un token [CLS] antes de cada frase. Después de realizar una pasada hacia delante por el codificador, la última capa oculta de estas [CLS] se utilizarán como representaciones de nuestras frases.
Clasificador de resumen
Una vez obtenida la representación vectorial de cada frase, podemos utilizar una simple capa feed forward como clasificador para obtener una puntuación para cada frase. En el artículo, el autor experimenta con un clasificador lineal simple, una red neuronal recurrente y un pequeño modelo Transformer de tres capas. El clasificador Transformer arroja los mejores resultados, lo que demuestra que las interacciones entre frases a través del mecanismo de autoatención son importantes para seleccionar las frases más importantes.
Así, en el codificador aprendemos las interacciones entre los tokens de nuestro documento, mientras que en el clasificador de resúmenes aprendemos las interacciones entre las frases.
3. Resumir aún más rápido
Los modelos de transformadores alcanzan un rendimiento puntero en la mayoría de las pruebas de PNL; sin embargo, entrenarlos y hacer predicciones a partir de ellos es costoso desde el punto de vista computacional. Con el fin de aligerar y agilizar el proceso de resumen en dispositivos con pocos recursos, he modificado el modelo códigos fuente proporcionado por los autores de BERTSUM para sustituir el codificador BERT por DistilBERT y MobileBERT. Las capas de resumen se mantienen sin jaula.
He aquí las pérdidas de entrenamiento de estas 3 variantes: TensorBoard

A pesar de ser 40% más pequeño que BERT-base, DistilBERT tiene las mismas pérdidas de entrenamiento que BERT-base, mientras que MobileBERT obtiene resultados ligeramente peores. La tabla siguiente muestra su rendimiento en el conjunto de datos CNN/DailyMail, el tamaño y el tiempo de ejecución de una pasada hacia delante:
| Modelos | ROUGE-1 | ROUGE-2 | ROUGE-L | Tiempo de inferencia | Talla | Parámetros |
|---|---|---|---|---|---|---|
| bert-base | 43.23 | 20.24 | 39.63 | 1.65 s | 475 MB | 120.5 M |
| destilbert | 42.84 | 20.04 | 39.31 | 925 ms | 310 MB | 77.4 M |
| mobilebert | 40.59 | 17.98 | 36.99 | 609 ms | 128 MB | 30.8 M |
*Tiempo medio de ejecución de un pase de avance en una sola GPU en un portátil estándar de Google Colab
Al ser 45% más rápido, DistilBERT tiene casi el mismo rendimiento que BERT-base. MobileBERT mantiene el rendimiento de 94% de BERT-base, siendo 4 veces más pequeño que BERT-base y 2,5 veces más pequeño que DistilBERT. En el artículo sobre MobileBERT, se demuestra que supera significativamente a DistilBERT en SQuAD v1.1. Sin embargo, no es el caso del resumen extractivo. Pero sigue siendo un resultado impresionante para MobileBERT con un tamaño de disco de sólo 128 MB.
4. Resumamos
Todos los puntos de control preentrenados, los detalles del entrenamiento y las instrucciones de configuración se encuentran en este repositorio de GitHub. Además, he desplegado una demo de BERTSUM con el codificador MobileBERT.
Aplicación web: https://extractive-summarization.herokuapp.com/
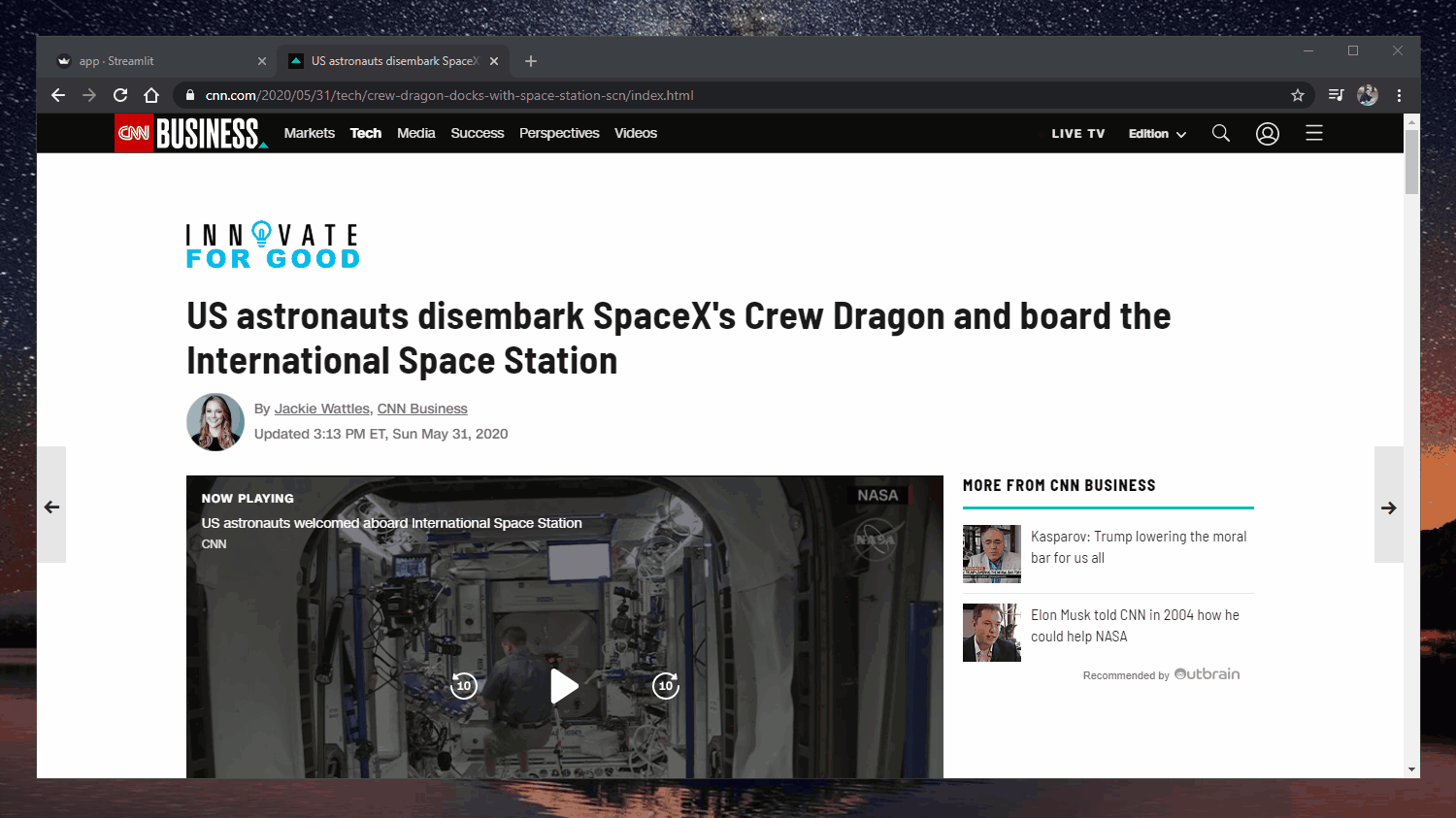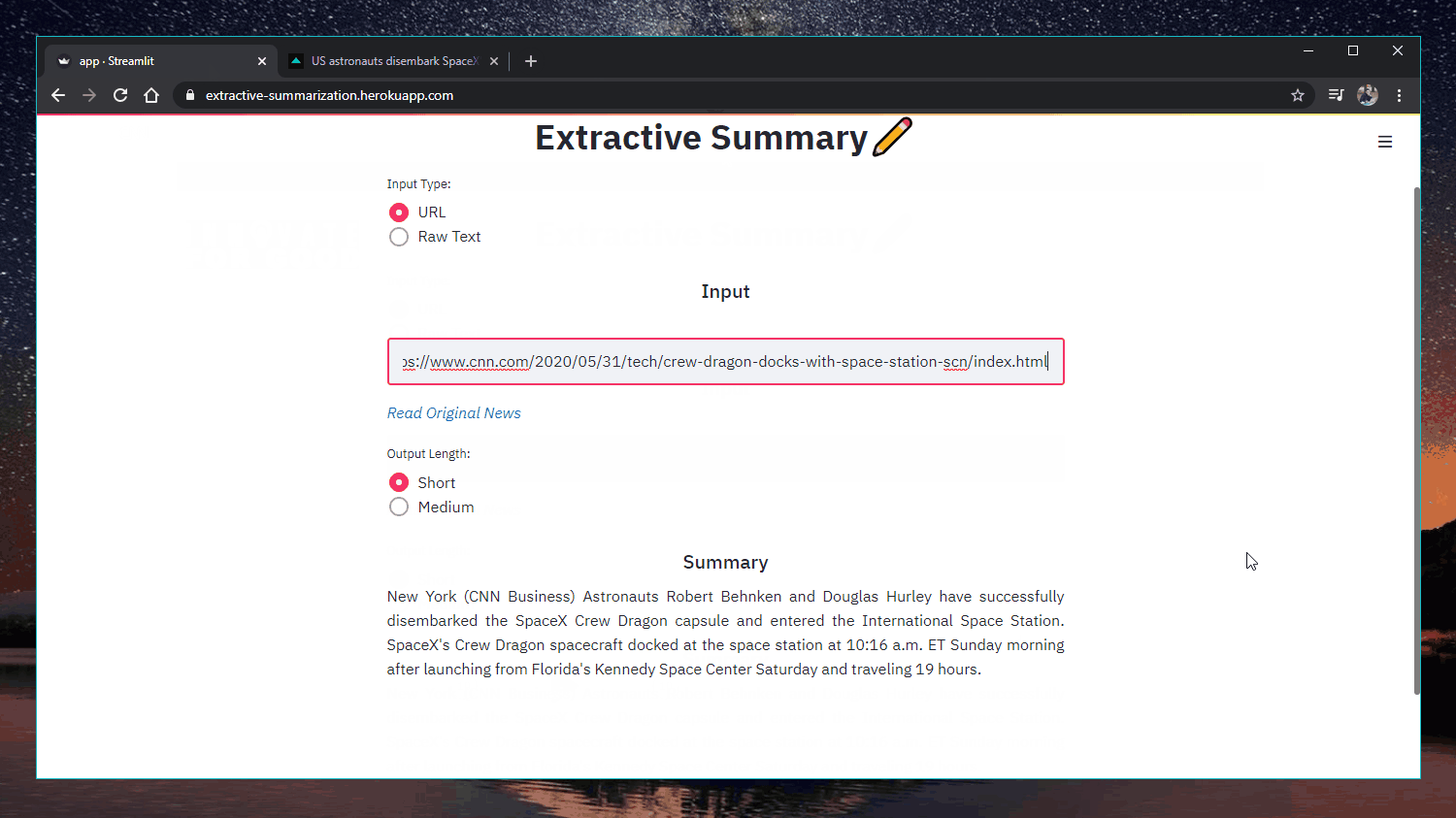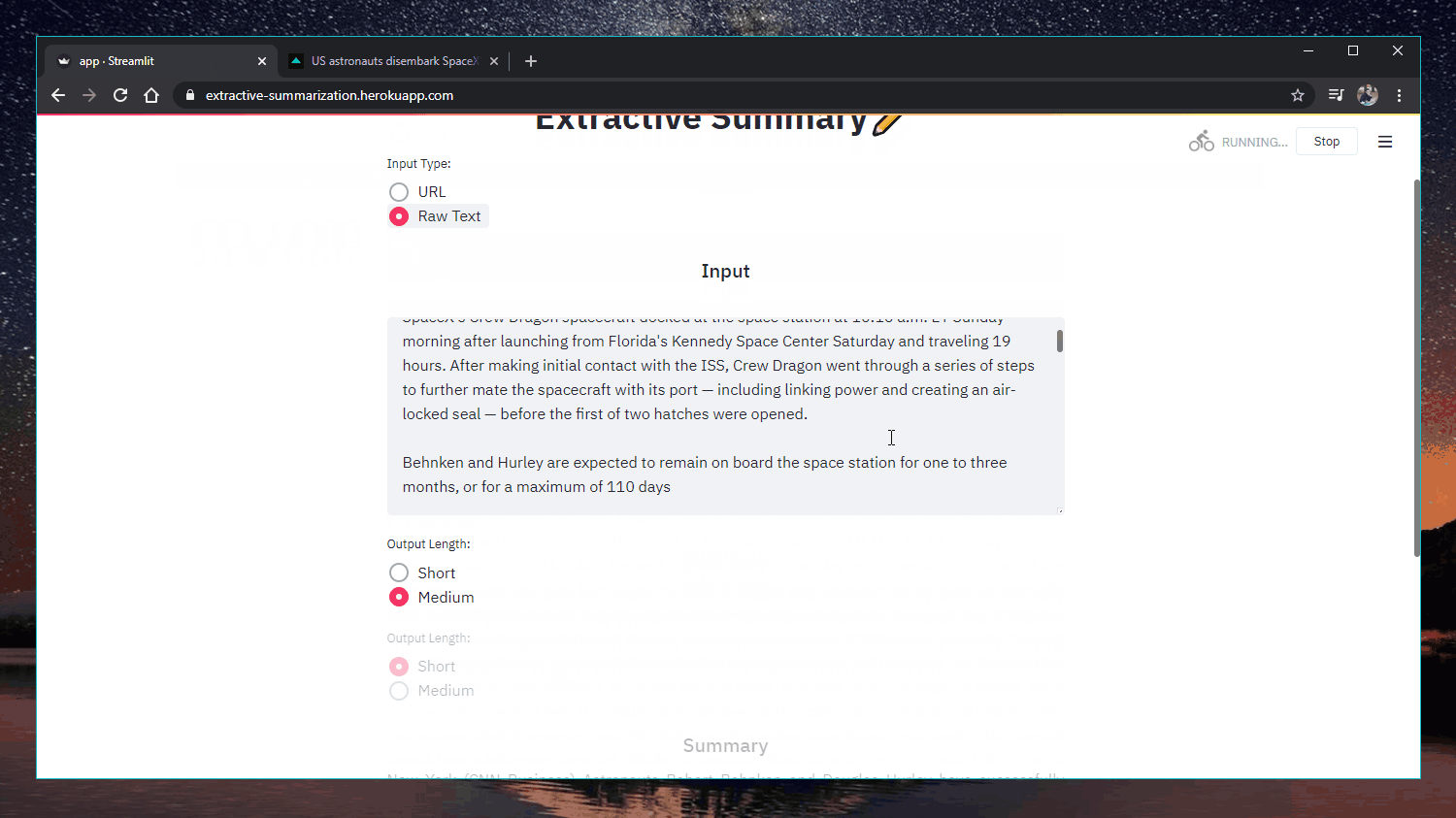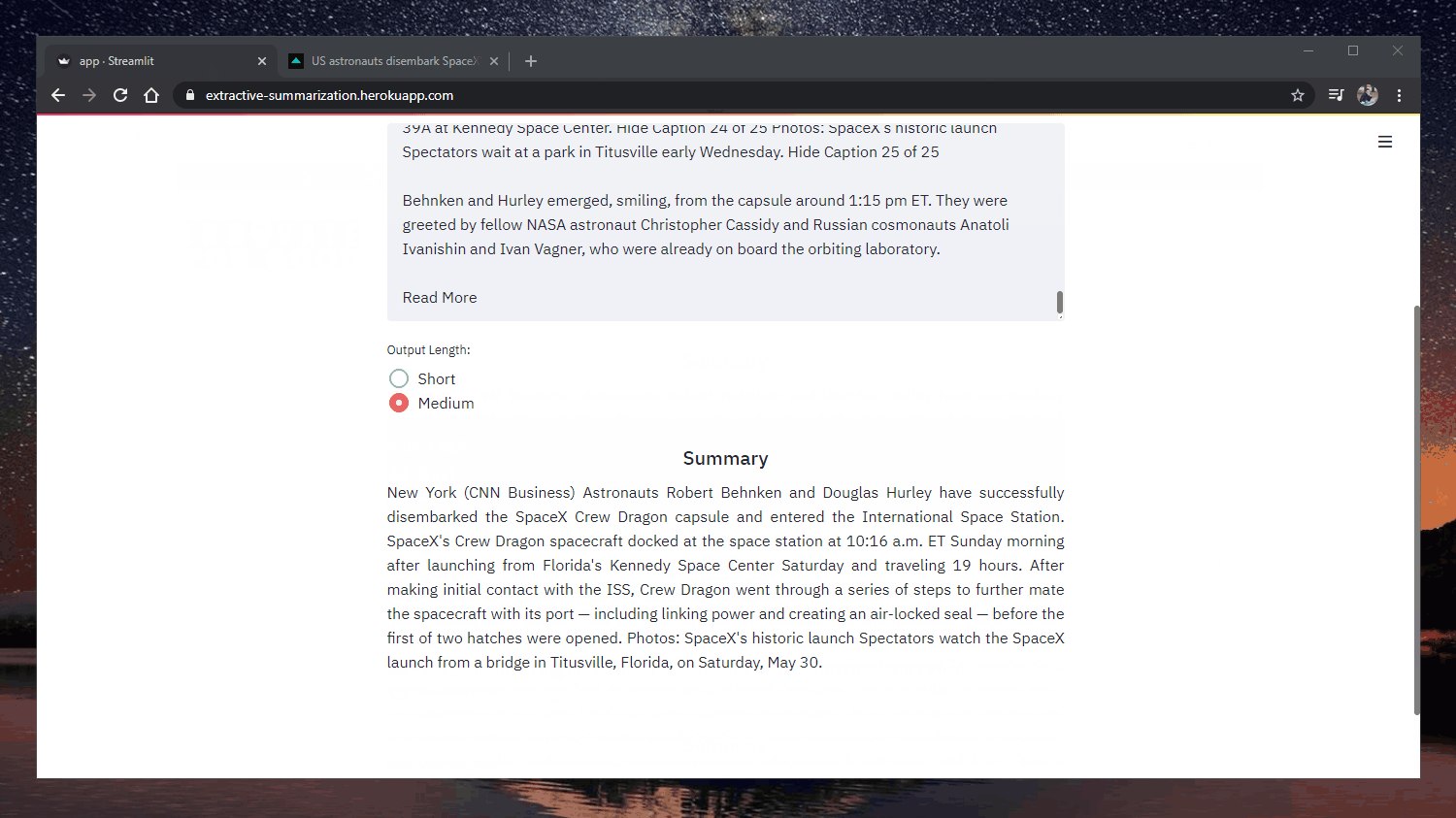
Código:
importar antorcha
from modelos.model_builder import ExtSummarizer
from ext_sum import resumir
# Cargar modelo
model_type = 'mobilebert' #@param ['bertbase', 'distilbert', 'mobilebert']
checkpoint = torch.load(f'checkpoints/{tipo_modelo}_ext.pt', map_location='cpu')
model = ExtSummarizer(checkpoint=checkpoint, bert_type=tipo_modelo, device='cpu')
# Ejecutar la integración
input_fp = 'datos_brutos/input.txt'
result_fp = 'resultados/resumen.txt'
summary = resumir(entrada_fp, resultado_fp, modelo, max_longitud=3)
print(resumen)
Muestra resumida
Original: https://www.cnn.com/2020/05/22/business/hertz-bankruptcy/index.html
Al declararse en quiebra, Hertz afirma que pretende seguir en activo al tiempo que reestructura sus deudas y se convierte en una empresa financieramente más saneada.
empresa financieramente más saneada. La empresa lleva alquilando coches desde 1918, cuando se estableció con una docena de
Ford Modelo T, y ha sobrevivido a la Gran Depresión, al cese de la producción de automóviles en EE.UU. durante la Segunda Guerra Mundial y a numerosas crisis de los precios del petróleo.
y numerosas crisis del precio del petróleo. "El impacto de Covid-19 en la demanda de viajes fue repentino y dramático, causando un
El impacto de Covid-19 en la demanda de viajes fue repentino y drástico, y provocó un brusco descenso de los ingresos y las reservas futuras de la empresa", afirma el comunicado de la empresa.
5. Conclusión
En este artículo, hemos explorado BERTSUM, una variante simple de BERT, para el resumen extractivo del papel Resumir textos con codificadores preentrenados (Liu et al., 2019). Luego, en un esfuerzo por hacer que el resumen extractivo sea aún más rápido y pequeño para dispositivos de bajos recursos, afinamos DistilBERT (Sanh et al., 2019) y MobileBERT (Sun et al., 2019) en los conjuntos de datos CNN/DailyMail.
DistilBERT retains BERT-base's performance in extractive summarization while being 45% smaller. MobileBERT is 4x smaller and 2.7x faster than BERT-base yet retains 94% of its performance.
Por último, desplegamos una aplicación web de demostración de MobileBERT para el resumen extractivo en https://extractive-summarization.herokuapp.com/.


