
Few-Shot Prompting vs. Fine-Tuning LLM für generative AI-Lösungen



Das wahre Potenzial großer Sprachmodelle (LLMs) liegt nicht nur in ihrer umfangreichen Wissensbasis, sondern auch in ihrer Fähigkeit, sich mit minimalem zusätzlichem Training an spezifische Aufgaben und Bereiche anzupassen. Hier kommen die Konzepte des "few-shot prompting" und der Feinabstimmung ins Spiel und verbessern die Nutzung der Leistung von LLMs in realen Szenarien.
LLMs werden zwar auf riesigen Datensätzen trainiert, die ein breites Spektrum an Wissen umfassen, haben aber oft Probleme, wenn sie mit hochspezialisierten Aufgaben oder domänenspezifischem Jargon konfrontiert werden. Herkömmliche überwachte Lernansätze würden große Mengen an gelabelten Daten erfordern, um diese Modelle anzupassen, was in vielen realen Situationen unpraktisch oder unmöglich ist. Diese Herausforderung hat Forscher und Praktiker dazu veranlasst, effizientere Methoden zur Anpassung von LLMs an spezifische Anwendungsfälle zu erforschen, die nur eine kleine Anzahl von Beispielen verwenden.
Kurzer Überblick über Few-Shot Prompting und Fine-Tuning
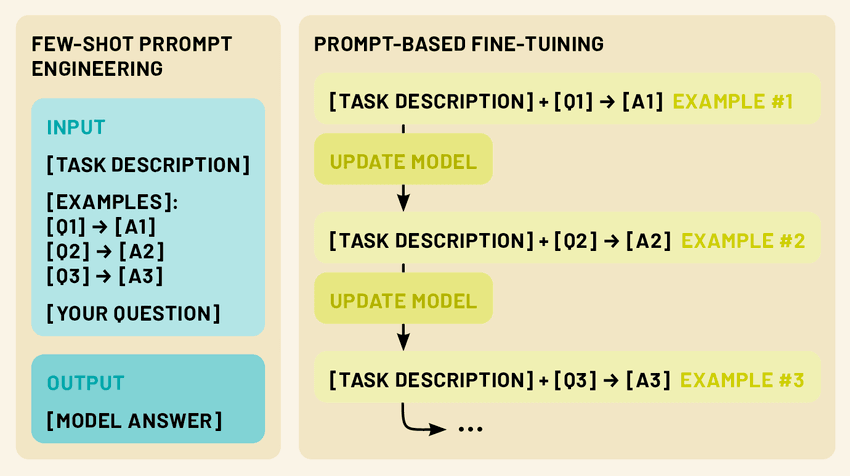
Es gibt zwei leistungsstarke Techniken, um diese Herausforderung zu meistern: "few-shot prompting" und "fine-tuning". Beim Few-Shot Prompting werden clevere Eingabeaufforderungen erstellt, die eine kleine Anzahl von Beispielen enthalten und das Modell dazu anleiten, eine bestimmte Aufgabe ohne zusätzliches Training auszuführen. Bei der Feinabstimmung hingegen werden die Parameter des Modells anhand einer begrenzten Menge aufgabenspezifischer Daten aktualisiert, so dass das Modell sein umfangreiches Wissen an einen bestimmten Bereich oder eine bestimmte Anwendung anpassen kann.
Beide Ansätze fallen unter den Begriff "few-shot learning", ein Paradigma, das es Modellen ermöglicht, neue Aufgaben zu erlernen oder sich an neue Bereiche anzupassen, indem sie nur wenige Beispiele verwenden. Durch den Einsatz dieser Techniken können wir die Leistung und Vielseitigkeit von LLMs drastisch verbessern und sie zu praktischen und effektiven Werkzeugen für eine breite Palette von Anwendungen in der natürlichen Sprachverarbeitung und darüber hinaus machen.
Few-Shot Prompting: Das LLM-Potenzial freisetzen
Few-Shot Prompting ist eine leistungsstarke Technik, die es uns ermöglicht, LLMs auf bestimmte Aufgaben oder Bereiche zu lenken, ohne dass zusätzliches Training erforderlich ist. Diese Methode nutzt die dem Modell innewohnende Fähigkeit, Anweisungen zu verstehen und zu befolgen, und "programmiert" das LLM durch sorgfältig formulierte Aufforderungen effektiv.
Im Kern geht es beim "few-shot prompting" darum, dem LLM eine kleine Anzahl von Beispielen (in der Regel 1-5) zur Verfügung zu stellen, die die gewünschte Aufgabe demonstrieren, gefolgt von einer neuen Eingabe, auf die das Modell eine Antwort erzeugen soll. Dieser Ansatz nutzt die Fähigkeit des Modells, Muster zu erkennen und sein Verhalten auf der Grundlage der gegebenen Beispiele anzupassen, so dass es Aufgaben ausführen kann, für die es nicht ausdrücklich trainiert wurde.
Das Schlüsselprinzip hinter dem "few-shot prompting" ist, dass wir das Modell durch die Präsentation eines klaren Musters von Eingaben und Ausgaben dazu bringen können, ähnliche Überlegungen auf neue, unbekannte Eingaben anzuwenden. Diese Technik zapft die Fähigkeit des LLM zum kontextbezogenen Lernen an und ermöglicht es ihm, sich schnell an neue Aufgaben anzupassen, ohne seine Parameter zu aktualisieren.
Arten von "few-shot"-Aufforderungen (zero-shot, one-shot, few-shot)
Few-shot prompting umfasst ein Spektrum von Ansätzen, die jeweils durch die Anzahl der angebotenen Beispiele definiert sind:
Null-Schuss-Eingabeaufforderung: In diesem Szenario werden keine Beispiele gegeben. Stattdessen wird dem Modell eine klare Anweisung oder Beschreibung der Aufgabe gegeben. Zum Beispiel: "Übersetzen Sie den folgenden englischen Text ins Französische: [Eingabetext]".
Einmalige Eingabeaufforderung: Hier wird der eigentlichen Eingabe ein einziges Beispiel vorangestellt. Dadurch erhält das Modell ein konkretes Beispiel für die erwartete Input-Output-Beziehung. Ein Beispiel: "Klassifizieren Sie die Stimmung der folgenden Rezension als positiv oder negativ. Beispiel: 'Dieser Film war fantastisch!' - Positive Eingabe: 'Ich konnte die Handlung nicht ertragen.' - [Modell generiert Antwort]"
Wenige Schüsse Souffleuse: Bei diesem Ansatz werden mehrere Beispiele (in der Regel 2-5) vor der eigentlichen Eingabe gegeben. Dies ermöglicht es dem Modell, komplexere Muster und Nuancen in der Aufgabe zu erkennen. Zum Beispiel: "Klassifizieren Sie die folgenden Sätze als Fragen oder Aussagen: 'Der Himmel ist blau.' - Aussage: 'Wie spät ist es?' - Frage: 'Ich liebe Eiscreme.' - Aussage Eingabe: 'Wo finde ich das nächste Restaurant?' - [Modell erzeugt Antwort]"
Gestaltung von effektiven Aufforderungen in wenigen Augenblicken
Das Verfassen von effektiven "few-shot prompts" ist sowohl eine Kunst als auch eine Wissenschaft. Hier sind einige wichtige Grundsätze zu beachten:
Klarheit und Kohärenz: Achten Sie darauf, dass Ihre Beispiele und Anweisungen klar sind und einem einheitlichen Format folgen. Dadurch kann das Modell das Muster leichter erkennen.
Vielfältigkeit: Wenn Sie mehrere Beispiele verwenden, versuchen Sie, eine Reihe möglicher Eingaben und Ausgaben abzudecken, um dem Modell ein breiteres Verständnis der Aufgabe zu vermitteln.
Relevanz: Wählen Sie Beispiele, die in engem Zusammenhang mit der spezifischen Aufgabe oder dem Bereich stehen, auf den Sie abzielen. So kann sich das Modell auf die wichtigsten Aspekte seines Wissens konzentrieren.
Prägnanz: Es ist zwar wichtig, genügend Kontext zu liefern, aber vermeiden Sie übermäßig lange oder komplexe Aufforderungen, die das Modell verwirren oder die Schlüsselinformationen verwässern könnten.
Experimentieren: Scheuen Sie sich nicht davor, zu iterieren und mit verschiedenen Aufforderung Strukturen und Beispiele, um herauszufinden, was für Ihren speziellen Anwendungsfall am besten geeignet ist.
Durch die Beherrschung der Kunst des "few-shot prompting" können wir das volle Potenzial von LLMs freisetzen und sie in die Lage versetzen, ein breites Spektrum von Aufgaben mit minimalem zusätzlichem Input oder Training zu bewältigen.
Feinabstimmung von LLMs: Anpassung von Modellen mit begrenzten Daten
Während das "few-shot prompting" eine leistungsstarke Technik ist, um LLMs an neue Aufgaben anzupassen, ohne das Modell selbst zu verändern, bietet das "fine-tuning" eine Möglichkeit, die Parameter des Modells zu aktualisieren, um eine noch bessere Leistung bei spezifischen Aufgaben oder Domänen zu erzielen. Die Feinabstimmung ermöglicht es uns, das umfangreiche Wissen, das in vortrainierten LLMs kodiert ist, zu nutzen und sie gleichzeitig auf unsere spezifischen Bedürfnisse zuzuschneiden, indem wir nur eine kleine Menge aufgabenspezifischer Daten verwenden.
Verständnis der Feinabstimmung im Kontext der LLMs
Bei der Feinabstimmung eines LLM wird ein bereits trainiertes Modell auf einem kleineren, aufgabenspezifischen Datensatz weiter trainiert. Dieser Prozess ermöglicht es dem Modell, seine gelernten Repräsentationen an die Feinheiten der Zielaufgabe oder -domäne anzupassen. Der Hauptvorteil der Feinabstimmung besteht darin, dass sie auf dem reichhaltigen Wissen und dem Sprachverständnis aufbaut, das bereits in dem vorab trainierten Modell vorhanden ist, und weit weniger Daten und Rechenressourcen erfordert als das Training eines Modells von Grund auf.
Im Zusammenhang mit LLMs konzentriert sich die Feinabstimmung in der Regel auf die Anpassung der Gewichte der oberen Schichten des Netzes, die für aufgabenspezifische Merkmale verantwortlich sind, während die unteren Schichten (die allgemeinere Sprachmuster erfassen) weitgehend unverändert bleiben. Dieser Ansatz, der oft als "Transferlernen" bezeichnet wird, ermöglicht es dem Modell, sein breites Sprachverständnis beizubehalten und gleichzeitig spezielle Fähigkeiten für die Zielaufgabe zu entwickeln.
Feintuning-Techniken mit wenigen Aufnahmen
Die Feinabstimmung in wenigen Schritten geht noch einen Schritt weiter, indem versucht wird, das Modell mit einer sehr kleinen Anzahl von Beispielen anzupassen - normalerweise im Bereich von 10 bis 100 Beispielen pro Klasse oder Aufgabe. Dieser Ansatz ist besonders wertvoll, wenn beschriftete Daten für die Zielaufgabe knapp oder teuer zu beschaffen sind. Zu den wichtigsten Techniken für die Feinabstimmung mit wenigen Beispielen gehören:
Prompt-basierte Feinabstimmung: Diese Methode kombiniert die Ideen des "few-shot prompting" mit der Aktualisierung von Parametern. Das Modell wird anhand eines kleinen Datensatzes feinabgestimmt, bei dem jedes Beispiel als Aufforderungs-Vervollständigungs-Paar formatiert ist, ähnlich wie bei "few-shot prompts".
Ansätze des Meta-Lernens: Techniken wie Modell-Agnostisches Meta-Lernen (MAML) können für die Feinabstimmung von LLMs in wenigen Schritten angepasst werden. Diese Methoden zielen darauf ab, einen guten Initialisierungspunkt zu finden, der es dem Modell ermöglicht, sich mit minimalen Daten schnell an neue Aufgaben anzupassen.
Adapterbasierte Feinabstimmung: Anstatt alle Modellparameter zu aktualisieren, werden bei diesem Ansatz kleine "Adapter"-Module zwischen den Schichten des vortrainierten Modells eingesetzt. Nur diese Adapter werden für die neue Aufgabe trainiert, wodurch die Anzahl der trainierbaren Parameter und das Risiko eines katastrophalen Vergessens reduziert werden.
Kontextbezogenes Lernen: In einigen neueren Ansätzen wird versucht, LLMs so zu optimieren, dass sie besser kontextbezogenes Lernen betreiben und sich allein durch Aufforderungen an neue Aufgaben anpassen können.
Few-Shot Prompting vs. Fine-Tuning: Die Wahl des richtigen Ansatzes
Bei der Anpassung von LLMs an spezifische Aufgaben bieten sowohl das "few-shot prompting" als auch das "fine-tuning" leistungsfähige Lösungen. Jede Methode hat jedoch ihre eigenen Stärken und Grenzen, und die Wahl des richtigen Ansatzes hängt von verschiedenen Faktoren ab.
Stärken und Grenzen der einzelnen Methoden
Few-Shot Prompting: Stärken:
Erfordert keine Aktualisierung der Modellparameter, so dass das ursprüngliche Modell erhalten bleibt
Hochflexibel und fliegend anpassbar
Keine zusätzliche Schulungszeit oder Rechenressourcen erforderlich
Nützlich für schnelles Prototyping und Experimentieren
Beschränkungen:
Die Leistung kann weniger konsistent sein, insbesondere bei komplexen Aufgaben.
Begrenzt durch die ursprünglichen Fähigkeiten und Kenntnisse des Modells
Kann sich mit hochspezialisierten Bereichen oder Aufgaben schwer tun
Feinabstimmung: Stärken:
Erzielt oft eine bessere Leistung bei bestimmten Aufgaben
Kann das Modell an neue Bereiche und Fachvokabular anpassen
Einheitlichere Ergebnisse bei ähnlichen Eingaben
Potenzial für kontinuierliches Lernen und Verbesserung
Beschränkungen:
Erfordert zusätzliche Ausbildungszeit und Rechenressourcen
Gefahr des katastrophalen Vergessens, wenn nicht sorgfältig gehandelt wird
Kann bei kleinen Datensätzen zu stark angepasst werden
Weniger flexibel; erfordert Umschulung bei wesentlichen Aufgabenänderungen
Faktoren, die bei der Auswahl einer Technik zu berücksichtigen sind
Bei der Auswahl einer Technik sollten Sie mehrere Faktoren berücksichtigen:
Verfügbarkeit der Daten: Wenn Sie über eine kleine Menge hochwertiger, aufgabenspezifischer Daten verfügen, könnte eine Feinabstimmung vorzuziehen sein. Bei Aufgaben mit sehr wenigen oder gar keinen spezifischen Daten könnte die Eingabeaufforderung mit wenigen Schüssen die bessere Wahl sein.
Komplexität der Aufgabe: Einfache Aufgaben, die nahe am Trainingsbereich des Modells liegen, funktionieren möglicherweise gut mit einer kurzen Eingabeaufforderung. Komplexere oder spezialisierte Aufgaben profitieren oft von einer Feinabstimmung.
Ressourcenbeschränkungen: Berücksichtigen Sie die Ihnen zur Verfügung stehenden Rechenressourcen und die zeitlichen Beschränkungen. Das Prompting mit wenigen Schüssen ist im Allgemeinen schneller und weniger ressourcenintensiv.
Flexibilitätsanforderungen: Wenn Sie sich schnell an verschiedene Aufgaben anpassen oder Ihre Vorgehensweise häufig ändern müssen, bietet die Eingabeaufforderung in wenigen Schritten mehr Flexibilität.
Leistungsanforderungen: Bei Anwendungen, die eine hohe Genauigkeit und Konsistenz erfordern, liefert die Feinabstimmung oft bessere Ergebnisse, insbesondere bei ausreichenden aufgabenspezifischen Daten.
Datenschutz und Sicherheit: Wenn Sie mit sensiblen Daten arbeiten, ist das "few-shot prompting" vorzuziehen, da es keine Freigabe von Daten für Modellaktualisierungen erfordert.
Praktische Anwendungen von Few-Shot-Techniken für LLMs
Few-shot-Lerntechniken haben eine breite Palette von Anwendungen für LLMs in verschiedenen Bereichen eröffnet, die es diesen Modellen ermöglichen, sich schnell an spezifische Aufgaben mit minimalen Beispielen anzupassen.
Aufgaben zur Verarbeitung natürlicher Sprache:
Text Klassifizierung: Mit Hilfe von Few-Shot-Techniken können LLMs Text mit nur wenigen Beispielen pro Kategorie in vordefinierte Klassen einteilen. Dies ist nützlich für Content-Tagging, Spam-Erkennung und Themenmodellierung.
Stimmungsanalyse: LLMs können sich schnell an domänenspezifische Aufgaben der Stimmungsanalyse anpassen und verstehen die Nuancen des Stimmungsausdrucks in verschiedenen Kontexten.
Erkennung von benannten Entitäten (NER): Mit Hilfe von Few-Shot-Learning können LLMs benannte Entitäten in spezialisierten Bereichen identifizieren und klassifizieren, wie z. B. die Identifizierung von chemischen Verbindungen in der wissenschaftlichen Literatur.
Beantwortung von Fragen: LLMs können auf die Beantwortung von Fragen in bestimmten Bereichen oder Formaten zugeschnitten werden, was ihren Nutzen für den Kundendienst und für Systeme zur Informationsgewinnung erhöht.
Bereichsspezifische Anpassungen:
Rechtlich: Wenige Techniken ermöglichen es LLMs, juristische Dokumente zu verstehen und zu generieren, Rechtsfälle zu klassifizieren und relevante Informationen aus Verträgen zu extrahieren - und das mit minimalem domänenspezifischem Training.
Medizinisch: LLMs können an Aufgaben wie die Zusammenfassung von medizinischen Berichten, die Klassifizierung von Krankheiten anhand von Symptomen und die Vorhersage von Arzneimittelinteraktionen angepasst werden, wobei nur eine kleine Anzahl von medizinischen Beispielen verwendet wird.
Technisch: In Bereichen wie den Ingenieurwissenschaften oder der Informatik ermöglicht es LLMs, spezialisierte technische Inhalte zu verstehen und zu generieren, Code zu debuggen oder komplexe Konzepte unter Verwendung einer domänenspezifischen Terminologie zu erklären.
Mehrsprachige und sprachenübergreifende Anwendungen:
Übersetzung in ressourcenarme Sprachen: Few-shot-Techniken können LLMs bei der Durchführung von Übersetzungsaufgaben für Sprachen mit begrenzter Datenverfügbarkeit helfen.
Sprachübergreifender Transfer: Modelle, die in Sprachen mit hohen Ressourcen trainiert wurden, können mit Hilfe von "few-shot learning" an Aufgaben in Sprachen mit niedrigen Ressourcen angepasst werden.
Mehrsprachige Aufgabenanpassung: LLMs können sich schnell anpassen, um dieselbe Aufgabe in mehreren Sprachen mit nur wenigen Beispielen in jeder Sprache auszuführen.
Herausforderungen und Grenzen von Few-Shot-Techniken
Während die "few-shot"-Techniken für LLMs ein enormes Potenzial bieten, sind sie auch mit einigen Herausforderungen und Einschränkungen verbunden, die es zu bewältigen gilt.
Fragen der Konsistenz und Zuverlässigkeit:
Leistungsvariabilität: Methoden mit nur wenigen Schritten können manchmal zu uneinheitlichen Ergebnissen führen, insbesondere bei komplexen Aufgaben oder Randfällen.
Promptes Feingefühl: Kleine Änderungen im Wortlaut der Aufforderungen oder in der Auswahl der Beispiele können zu erheblichen Abweichungen in der Qualität der Ergebnisse führen.
Aufgabenspezifische Einschränkungen: Bei manchen Aufgaben ist es von Natur aus schwierig, aus nur wenigen Beispielen zu lernen, was zu einer suboptimalen Leistung führt.
Ethische Überlegungen und Vorurteile:
Verstärkung von Vorurteilen: Das Lernen mit wenigen Aufnahmen könnte die in den begrenzten Beispielen vorhandenen Verzerrungen verstärken, was zu ungerechten oder diskriminierenden Ergebnissen führen könnte.
Mangelnde Robustheit: Modelle, die mit "few-shot"-Techniken angepasst wurden, sind möglicherweise anfälliger für Angriffe von außen oder unerwartete Eingaben.
Transparenz und Erklärbarkeit: Es kann schwierig sein, zu verstehen und zu erklären, wie das Modell in Szenarien mit wenigen Aufnahmen zu seinen Schlussfolgerungen kommt.
Rechenressourcen und Effizienz:
Beschränkungen der Modellgröße: Mit zunehmender Größe der LLMs werden die Rechenanforderungen für die Feinabstimmung immer anspruchsvoller, was die Zugänglichkeit möglicherweise einschränkt.
Inferenzzeit: Komplexe Eingabeaufforderungen, die nur wenige Sekunden dauern, können die Inferenzzeit verlängern, was sich auf Echtzeitanwendungen auswirken kann.
Energieverbrauch: Die für den groß angelegten Einsatz von "few-shot"-Techniken erforderlichen Rechenressourcen geben Anlass zu Bedenken hinsichtlich der Energieeffizienz und der Umweltauswirkungen.
Die Bewältigung dieser Herausforderungen und Einschränkungen ist entscheidend für die weitere Entwicklung und den verantwortungsvollen Einsatz von "few-shot"-Lernverfahren in LLMs. Mit dem Fortschreiten der Forschung können wir innovative Lösungen erwarten, die die Zuverlässigkeit, Fairness und Effizienz dieser leistungsstarken Methoden verbessern.
Die Quintessenz
Few-Shot Prompting und Fine-Tuning sind bahnbrechende Ansätze, die es LLMs ermöglichen, sich mit minimalen Daten schnell an spezielle Aufgaben anzupassen. Wie wir erforscht haben, bieten diese Techniken eine noch nie dagewesene Flexibilität und Effizienz bei der Anpassung von LLMs an verschiedene Anwendungen in verschiedenen Branchen, von der Verbesserung von Aufgaben der natürlichen Sprachverarbeitung bis hin zur Ermöglichung domänenspezifischer Anpassungen in Bereichen wie Gesundheitswesen, Recht und Technologie.
Auch wenn es noch Herausforderungen gibt, insbesondere in Bezug auf Konsistenz, ethische Erwägungen und Recheneffizienz, ist das Potenzial des "few-shot learning" in LLMs unbestreitbar. Wenn die Forschung weiter voranschreitet, die derzeitigen Grenzen überwindet und neue Optimierungsstrategien aufdeckt, können wir mit noch leistungsfähigeren und vielseitigeren Anwendungen dieser Techniken rechnen. Die Zukunft der KI liegt nicht nur in größeren Modellen, sondern in intelligenteren, anpassungsfähigeren Modellen - und das "few-shot learning" ebnet den Weg für diese neue Ära intelligenter, effizienter und hochspezialisierter Sprachmodelle, die unsere sich ständig verändernden Bedürfnisse wirklich verstehen und darauf reagieren können.


