
Was ist Few Shot Learning?



In der KI ist die Fähigkeit, aus begrenzten Daten effizient zu lernen, von entscheidender Bedeutung. Hier kommt Few Shot Learning ins Spiel, ein Ansatz, der die Art und Weise verbessert, wie KI-Modelle Wissen erwerben und sich an neue Aufgaben anpassen.
Aber was genau ist Few Shot Learning?
Definition von Few Shot Learning
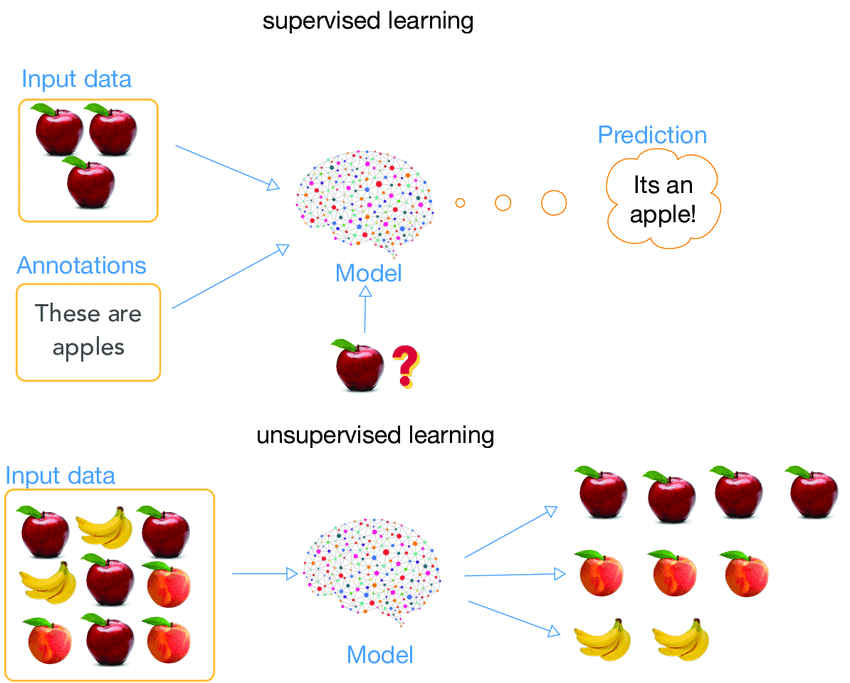
Few Shot Learning ist ein innovatives maschinelles Lernen Paradigma, das es KI-Modellen ermöglicht, neue Konzepte oder Aufgaben aus nur wenigen Beispielen zu lernen. Im Gegensatz zu herkömmlichen überwachten Lernmethoden, die große Mengen an markierten Trainingsdaten erfordern, ermöglichen Few Shot Learning-Techniken den Modellen eine effektive Verallgemeinerung anhand einer kleinen Anzahl von Beispielen. Dieser Ansatz ahmt die menschliche Fähigkeit nach, neue Ideen schnell zu erfassen, ohne dass umfangreiche Wiederholungen erforderlich sind.
Das Wesen des Few Shot Learning liegt in seiner Fähigkeit, Vorwissen zu nutzen und sich schnell an neue Szenarien anzupassen. Durch den Einsatz von Techniken wie dem Meta-Lernen, bei dem das Modell "lernt, wie man lernt", können Few Shot Learning-Algorithmen eine breite Palette von Aufgaben mit minimalem zusätzlichem Training bewältigen. Diese Flexibilität macht sie zu einem unschätzbaren Werkzeug in Szenarien, in denen Daten knapp, teuer zu beschaffen sind oder sich ständig weiterentwickeln.
Die Herausforderung der Datenknappheit in der KI
Nicht alle Daten sind gleich, und qualitativ hochwertige, markierte Daten können ein seltenes und kostbares Gut sein. Diese Knappheit stellt eine große Herausforderung für herkömmliche überwachte Lernansätze dar, die in der Regel Tausende oder sogar Millionen von markierten Beispielen benötigen, um eine zufriedenstellende Leistung zu erzielen.
Das Problem der Datenknappheit ist besonders akut in spezialisierten Bereichen wie dem Gesundheitswesen, wo es für seltene Krankheiten nur wenige dokumentierte Fälle gibt, oder in sich schnell verändernden Umgebungen, in denen häufig neue Datenkategorien auftauchen. In diesen Szenarien können die Zeit und die Ressourcen, die für die Sammlung und Kennzeichnung großer Datensätze erforderlich sind, unerschwinglich sein, was zu einem Engpass bei der Entwicklung und dem Einsatz von KI führt.
Few Shot Learning vs. traditionelles überwachtes Lernen
Um die Wirkung von Few Shot Learning zu verstehen, ist es wichtig zu wissen, wie es sich von traditionellen überwachten Lernmethoden unterscheidet und warum dieser Unterschied in der Praxis wichtig ist.
Grenzen der konventionellen Ansätze
Traditionell überwachtes Lernen beruht auf einem einfachen, aber datenintensiven Prinzip: Je mehr Beispiele ein Modell während des Trainings sieht, desto besser wird es darin, Muster zu erkennen und Vorhersagen zu treffen. Dieser Ansatz hat zwar zu bemerkenswerten Erfolgen in verschiedenen Bereichen geführt, birgt aber auch einige erhebliche Nachteile:
Daten-Abhängigkeit: Herkömmliche Modelle haben oft Probleme, wenn sie mit begrenzten Trainingsdaten konfrontiert werden, was zu einer Überanpassung oder schlechten Generalisierung führt.
Unflexibilität: Einmal trainiert, sind diese Modelle in der Regel nur bei den spezifischen Aufgaben, für die sie trainiert wurden, leistungsfähig und können sich nicht schnell an neue, verwandte Aufgaben anpassen.
Intensität der Ressourcen: Das Sammeln und Beschriften großer Datensätze ist zeitaufwändig, teuer und oft unpraktisch, insbesondere in spezialisierten oder sich schnell entwickelnden Bereichen.
Kontinuierliche Aktualisierung: In dynamischen Umgebungen, in denen häufig neue Datenkategorien auftauchen, müssen herkömmliche Modelle möglicherweise ständig umgeschult werden, um relevant zu bleiben.
Wie Few Shot Learning diese Herausforderungen meistert
Few Shot Learning bietet einen Paradigmenwechsel bei der Überwindung dieser Einschränkungen, indem es einen flexibleren und effizienteren Ansatz für maschinelles Lernen bietet:
Beispielhafte Effizienz: Durch den Einsatz von Meta-Learning-Techniken können Few-Shot-Learning-Modelle aus wenigen Beispielen verallgemeinern und sind damit in datenarmen Szenarien äußerst effektiv.
Schnelle Anpassung: Diese Modelle sind so konzipiert, dass sie sich schnell an neue Aufgaben oder Kategorien anpassen und oft nur eine kleine Anzahl von Beispielen benötigen, um eine gute Leistung zu erzielen.
Optimierung der Ressourcen: Mit der Fähigkeit, aus begrenzten Daten zu lernen, reduziert Few Shot Learning die Notwendigkeit einer umfangreichen Datenerfassung und -kennzeichnung und spart so Zeit und Ressourcen.
Kontinuierliches Lernen: Nur wenige Shot-Learning-Ansätze sind von Natur aus besser für kontinuierliche Lernszenarien geeignet, bei denen Modelle neues Wissen aufnehmen müssen, ohne zuvor gelernte Informationen zu vergessen.
Vielseitigkeit: Von Computer-Vision-Aufgaben wie der Klassifizierung von Bildern mit wenigen Aufnahmen bis hin zu Anwendungen für die Verarbeitung natürlicher Sprache zeigt das Few Shot Learning eine bemerkenswerte Vielseitigkeit in verschiedenen Bereichen.
Durch die Bewältigung dieser Herausforderungen eröffnet Few Shot Learning neue Möglichkeiten in der KI-Entwicklung und ermöglicht die Erstellung von anpassungsfähigeren und effizienteren Modellen.
Das Spektrum des probeneffizienten Lernens
Es gibt ein faszinierendes Spektrum von Ansätzen, die darauf abzielen, die Menge der benötigten Trainingsdaten zu minimieren. Dieses Spektrum umfasst Zero Shot Learning, One Shot Learning und Few Shot Learning, die jeweils einzigartige Möglichkeiten bieten, um die Herausforderung des Lernens aus begrenzten Beispielen zu bewältigen.
Zero Shot Learning: Lernen ohne Beispiele
Am äußersten Ende der Stichprobeneffizienz steht das Zero Shot Learning. Dieser bemerkenswerte Ansatz ermöglicht es Modellen, Instanzen von Klassen zu erkennen oder zu klassifizieren, die sie während des Trainings nie gesehen haben. Anstatt sich auf markierte Beispiele zu stützen, nutzt Zero Shot Learning Hilfsinformationen, wie z. B. textuelle Beschreibungen oder attributbasierte Darstellungen, um Vorhersagen über ungesehene Klassen zu treffen.
Ein Zero-Shot-Learning-Modell könnte beispielsweise in der Lage sein, eine neue Tierart, der es noch nie begegnet ist, allein auf der Grundlage einer textlichen Beschreibung ihrer Merkmale zu klassifizieren. Diese Fähigkeit ist besonders wertvoll in Szenarien, in denen es unpraktisch oder unmöglich ist, beschriftete Beispiele für alle möglichen Klassen zu erhalten.
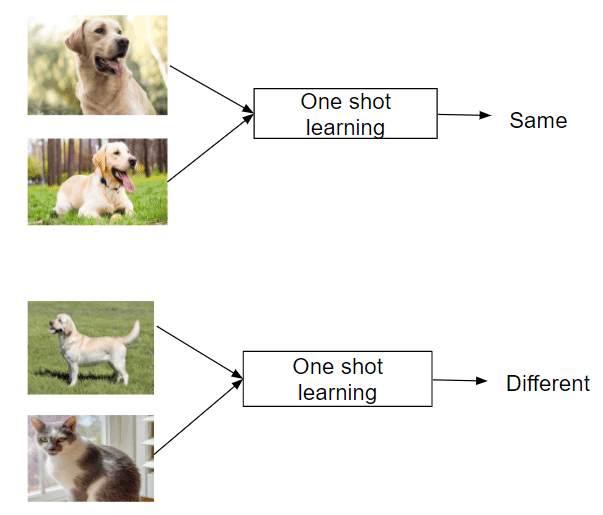
One Shot Learning: Lernen von einer einzigen Instanz
Im weiteren Verlauf des Spektrums stoßen wir auf das One Shot Learning, eine Untergruppe des Few Shot Learning, bei dem das Modell lernt, neue Klassen aus nur einem einzigen Beispiel zu erkennen. Dieser Ansatz ist von der menschlichen Kognition inspiriert und ahmt unsere Fähigkeit nach, neue Konzepte schnell zu erfassen, nachdem wir sie nur einmal gesehen haben.
One-Shot-Learning-Techniken stützen sich häufig auf den Vergleich neuer Instanzen mit dem einzigen Beispiel, das sie gesehen haben, unter Verwendung ausgefeilter Ähnlichkeitsmaße. Diese Methode hat bemerkenswerte Erfolge in Bereichen wie der Gesichtserkennung gezeigt, wo ein System lernen kann, eine Person anhand eines einzigen Fotos zu identifizieren.
Few Shot Learning: Aufgaben mit minimalen Daten bewältigen
Few Shot Learning erweitert das Konzept des One Shot Learning auf Szenarien, in denen für jede neue Klasse nur eine kleine Anzahl (typischerweise 2-5) von markierten Beispielen zur Verfügung steht. Dieser Ansatz schafft ein Gleichgewicht zwischen der extremen Dateneffizienz von Zero und One Shot Learning und den datenintensiveren traditionellen überwachten Lernmethoden.
Nur wenige Shot-Learning-Techniken ermöglichen es den Modellen, sich mit nur wenigen Beispielen schnell an neue Aufgaben oder Klassen anzupassen, was sie in Bereichen von unschätzbarem Wert macht, in denen Datenknappheit eine große Herausforderung darstellt. Durch den Einsatz von Meta-Learning-Strategien lernen diese Modelle, wie man lernt, und können so aus begrenzten Daten effektiv verallgemeinern.
Kernkonzepte des Few Shot Learning
Um das Potenzial von Few Shot Learning voll ausschöpfen zu können, ist es wichtig, einige grundlegende Konzepte zu verstehen, die diesem innovativen Ansatz zugrunde liegen.
N-way K-shot Klassifizierung erklärt
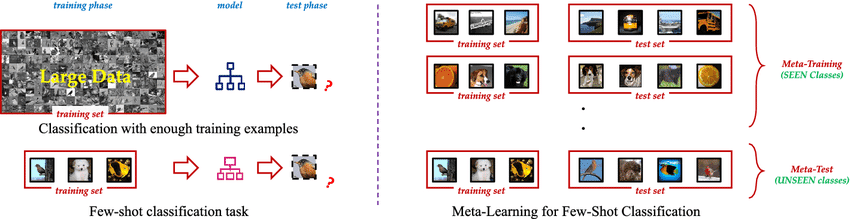
Das Herzstück von Few Shot Learning ist die N-way K-shot-Klassifikation. Diese Terminologie beschreibt die Struktur einer Few-Shot-Learning-Aufgabe:
N-way bezieht sich auf die Anzahl der Klassen, zwischen denen das Modell bei einer bestimmten Aufgabe unterscheiden muss.
K-shot gibt die Anzahl der Beispiele für jede Klasse an.
Eine 5-fache 3-Shot-Klassifizierungsaufgabe würde zum Beispiel die Unterscheidung zwischen 5 verschiedenen Klassen beinhalten, wobei für jede Klasse 3 Beispiele zur Verfügung stehen. Dieser Rahmen ermöglicht es Forschern und Praktikern, verschiedene Few-Shot-Learning-Algorithmen unter einheitlichen Bedingungen systematisch zu bewerten und zu vergleichen.
Die Rolle von Support und Abfragesets
Beim Few Shot Learning werden die Daten in der Regel in zwei verschiedene Gruppen unterteilt:
Unterstützungsset: Dieser enthält die wenigen markierten Beispiele (K Aufnahmen) für jede der N Klassen. Das Modell verwendet diesen Satz, um zu lernen oder sich an die neue Aufgabe anzupassen.
Abfrage-Set: Diese besteht aus zusätzlichen Beispielen aus denselben N Klassen, die das Modell richtig klassifizieren muss. Die Leistung des Modells bei der Abfragemenge bestimmt, wie gut es aus den begrenzten Beispielen in der Unterstützungsmenge gelernt hat.
Diese Struktur ermöglicht es dem Modell, aus einer kleinen Anzahl von Beispielen (der Unterstützungsmenge) zu lernen und dann sofort seine Fähigkeit zur Verallgemeinerung auf neue, ungesehene Beispiele (die Abfragemenge) innerhalb derselben Aufgabe zu testen.
Ansätze zum Few Shot Learning
Forscher haben verschiedene Ansätze entwickelt, um die Herausforderungen des Few Shot Learning zu bewältigen, jeder mit seinen eigenen Stärken und Anwendungen.
Techniken auf Datenebene
Ansätze auf Datenebene konzentrieren sich auf die Erweiterung oder Erzeugung zusätzlicher Trainingsdaten, um die begrenzten verfügbaren Beispiele zu ergänzen. Zu diesen Techniken gehören:
Datenerweiterung: Anwendung von Transformationen auf bestehende Muster, um neue, synthetische Beispiele zu schaffen.
Generative Modelle: Einsatz fortschrittlicher KI-Modelle zur Generierung realistischer, künstlicher Beispiele auf der Grundlage der begrenzten verfügbaren realen Daten.
Diese Methoden zielen darauf ab, die effektive Größe des Trainingssatzes zu erhöhen, um den Modellen zu helfen, robustere Darstellungen aus begrenzten Daten zu lernen.
Strategien auf Parameterebene
Ansätze auf Parameterebene konzentrieren sich auf die Optimierung der Parameter des Modells, um eine schnelle Anpassung an neue Aufgaben zu ermöglichen. Diese Strategien beinhalten häufig:
Initialisierungstechniken: Suche nach optimalen Ausgangspunkten für Modellparameter, die eine schnelle Anpassung an neue Aufgaben ermöglichen.
Regularisierungsmethoden: Einschränkung des Parameterraums des Modells, um eine Überanpassung an die begrenzten verfügbaren Daten zu verhindern.
Diese Ansätze zielen darauf ab, das Modell flexibler und anpassungsfähiger zu machen und es in die Lage zu versetzen, aus wenigen Beispielen effektiv zu lernen.
Metrikbasierte Methoden
Metrikbasierte Few Shot Learning-Techniken konzentrieren sich auf das Erlernen einer Distanz- oder Ähnlichkeitsfunktion, mit der neue Beispiele effektiv mit den begrenzten verfügbaren beschrifteten Daten verglichen werden können. Zu den beliebten metrikbasierten Methoden gehören:
Siamesische Netzwerke: Lernen zur Berechnung von Ähnlichkeitswerten zwischen Eingabepaaren.
Prototypische Netzwerke: Berechnung von Klassenprototypen und Klassifizierung neuer Beispiele auf der Grundlage ihres Abstands zu diesen Prototypen.
Diese Methoden eignen sich hervorragend für Aufgaben wie die Klassifizierung von Bildern mit wenigen Aufnahmen, da sie lernen, Ähnlichkeiten auf eine Weise zu messen, die sich gut auf neue Klassen übertragen lässt.
Gradientenbasiertes Meta-Lernen
Gradientenbasierte Meta-Learning-Ansätze, wie das Model Agnostic Meta-Learning (MAML), zielen darauf ab, zu lernen, wie man lernt. Diese Methoden umfassen in der Regel einen zweistufigen Optimierungsprozess:
Innere Schleife: Schnelle Anpassung an eine bestimmte Aufgabe mit Hilfe einiger weniger Steigungsstufen.
Äußere Schleife: Optimierung der Anfangsparameter des Modells, um eine schnelle Anpassung an eine Reihe von Aufgaben zu ermöglichen.
Durch das Lernen einer Reihe von Parametern, die schnell auf neue Aufgaben abgestimmt werden können, ermöglichen diese Ansätze eine schnelle Anpassung der Modelle an neue Szenarien mit nur wenigen Beispielen.
Jeder dieser Ansätze für Few Shot Learning bietet einzigartige Vorteile, und Forscher kombinieren oft mehrere Techniken, um leistungsfähigere und flexiblere Modelle zu erstellen. Da wir die Grenzen der KI immer weiter verschieben, spielen diese stichprobeneffizienten Lernmethoden eine immer wichtigere Rolle bei der Entwicklung anpassungsfähigerer und effizienterer maschineller Lernsysteme.
Branchenübergreifende Anwendungen
Few Shot Learning ist nicht nur ein theoretisches Konzept, es ist eine praktische Anwendungen in verschiedenen Branchen und verändert die Art und Weise, wie KI reale Herausforderungen bewältigt.
Computer Vision: Von der Bildklassifizierung zur Objekterkennung
Im Bereich des Computer-Vision stößt das Few Shot Learning an die Grenzen dessen, was mit begrenzten Daten möglich ist:
Bild-Klassifizierung: Nur wenige Bildklassifizierungsverfahren ermöglichen es Modellen, neue Objektkategorien aus nur einer Handvoll von Beispielen zu erkennen, was für Anwendungen wie die Überwachung von Wildtieren oder die industrielle Qualitätskontrolle von entscheidender Bedeutung ist.
Objekt-Erkennung: Nur wenige Methoden zur Erkennung von aufgenommenen Objekten verbessern die Fähigkeit von Systemen, neue Objekte in Bildern oder Videoströmen zu lokalisieren und zu identifizieren, wobei die Anwendungen von autonomen Fahrzeugen bis hin zu Sicherheitssystemen reichen.
Gesichtserkennungssysteme: One-Shot-Learning-Ansätze haben die Gesichtserkennungssysteme erheblich verbessert, denn sie ermöglichen die Identifizierung von Personen anhand eines einzigen Referenzbildes.
Verarbeitung natürlicher Sprache: Anpassung von Sprachmodellen
Few Shot Learning schlägt auch in der natürlichen Sprachverarbeitung (NLP) hohe Wellen und ermöglicht flexiblere und effizientere Sprachmodelle:
Text Klassifizierung: Modelle können sich schnell an neue Textkategorien oder Sentiment-Analyseaufgaben mit minimalen Beispielen anpassen, was für Anwendungen wie Content-Moderation oder Kundenfeedback-Analyse entscheidend ist.
Maschinelle Übersetzung: Nur wenige Shot-Techniken verbessern die Fähigkeit von Übersetzungssystemen, mit ressourcenarmen Sprachen oder domänenspezifischer Terminologie umzugehen.
Beantwortung von Fragen: Nur wenige Shot-Learning-Ansätze verbessern die Fähigkeit der KI, Fragen zu neuen Themen mit begrenzten Trainingsdaten zu beantworten.
Robotik: Schnelle Anpassung an neue Umgebungen
In der Robotik ist die Fähigkeit, schnell zu lernen und sich anzupassen, von entscheidender Bedeutung. Few Shot Learning ermöglicht es Robotern,:
Sie meistern neue Aufgaben mit minimalen Demonstrationen und steigern so ihre Vielseitigkeit in der Produktion und im Service.
Anpassung an neue Umgebungen oder unerwartete Situationen, entscheidend für den Einsatz in dynamischen realen Umgebungen.
Erlernen Sie neue Greiftechniken für neuartige Objekte und erweitern Sie damit ihren Nutzen in Lagerhaltung und Logistik.
Gesundheitswesen: Seltene Krankheiten mit begrenzten Daten bekämpfen
Few Shot Learning ist besonders wertvoll im Gesundheitswesen, wo Daten über seltene Krankheiten oft nur spärlich vorhanden sind:
Krankheitsdiagnose: Modelle können lernen, seltene Krankheiten anhand begrenzter medizinischer Bildgebungsdaten zu erkennen, wodurch Diagnose und Behandlung möglicherweise beschleunigt werden.
Entdeckung von Arzneimitteln: Wenige Shot-Techniken helfen bei der Identifizierung potenzieller Arzneimittelkandidaten für seltene Krankheiten, bei denen herkömmliche datenintensive Ansätze möglicherweise nicht ausreichen.
Personalisierte Medizin: Durch die schnelle Anpassung an individuelle Patientendaten tragen Few Shot Learning-Modelle zu stärker personalisierten Behandlungsplänen bei.
Herausforderungen und zukünftige Wege beim Few Shot Learning
Obwohl Few Shot Learning bemerkenswerte Fortschritte gemacht hat, gibt es noch einige Herausforderungen und spannende Forschungsrichtungen.
Derzeitige Einschränkungen:
Verallgemeinerung über Domänen hinweg: Viele Few-Shot-Learning-Modelle haben Schwierigkeiten, wenn sich die Verteilung der neuen Aufgabe erheblich von den Trainingsaufgaben unterscheidet.
Skalierbarkeit: Einige Ansätze, insbesondere metrisch basierte Methoden, können mit zunehmender Anzahl von Klassen rechenintensiv werden.
Robustheit: Wenige Shot-Learning-Modelle können empfindlich auf die Wahl der unterstützenden Beispiele reagieren, was zu inkonsistenten Leistungen führen kann.
Interpretierbarkeit: Wie bei vielen Deep-Learning-Ansätzen kann der Entscheidungsprozess bei Few Shot Learning-Modellen undurchsichtig sein, was ihre Anwendbarkeit in sensiblen Bereichen einschränkt.
Vielversprechende Forschungsbereiche:
Domänenübergreifendes Few Shot Learning: Entwicklung von Methoden, die sich über sehr unterschiedliche Bereiche hinweg verallgemeinern lassen, um die Vielseitigkeit von Few Shot Learning Modellen zu erhöhen.
Einbeziehung von nicht gekennzeichneten Daten: Erforschung von halbüberwachten Few Shot Learning-Ansätzen, um die Fülle an unbeschrifteten Daten zu nutzen, die in vielen Bereichen verfügbar sind.
Kontinuierliches Few Shot Learning: Schaffung von Modellen, die kontinuierlich neue Aufgaben erlernen können, ohne zuvor gelernte Informationen zu vergessen, was dem menschlichen Lernen sehr nahe kommt.
Erklärbares Few Shot Learning: Entwicklung interpretierbarer Few-Shot-Learning-Modelle zur Stärkung des Vertrauens und der Anwendbarkeit in kritischen Bereichen wie dem Gesundheits- und Finanzwesen.
Few Shot Learning in Reinforcement Learning: Ausweitung der Grundsätze des Few Shot Learning auf Szenarien des Reinforcement Learning zur schnelleren Anpassung in komplexen Umgebungen.
Die Quintessenz
Few Shot Learning hat sich zu einer transformativen Kraft entwickelt, die unsere Herangehensweise an die Herausforderungen des maschinellen Lernens neu gestaltet. Few Shot Learning ermöglicht es KI-Systemen, effizient aus begrenzten Daten zu lernen, und schließt damit die Lücke zwischen menschenähnlicher kognitiver Flexibilität und der datenintensiven Natur des traditionellen Deep Learning. Von der Verbesserung des maschinellen Sehens und der Verarbeitung natürlicher Sprache bis hin zur Förderung der Robotik und des Gesundheitswesens beweist Few Shot Learning seinen Wert in verschiedenen Branchen und eröffnet neue Grenzen der Innovation.
Da die Forscher weiterhin die derzeitigen Grenzen überwinden und vielversprechende Richtungen erforschen, können wir für die Zukunft noch leistungsfähigere und vielseitigere KI-Systeme erwarten. Die Fähigkeit, aus wenigen Beispielen schnell zu lernen und sich anzupassen, wird auf dem Weg zu einer allgemeineren künstlichen Intelligenz von entscheidender Bedeutung sein, um das maschinelle Lernen enger an die kognitiven Fähigkeiten des Menschen anzugleichen und neue Möglichkeiten in unserer sich rasch verändernden Welt zu erschließen.


