
Verständnis der LLM-Preisstrukturen: Inputs, Outputs und Kontextfenster



Für KI-Strategien in Unternehmen ist das Verständnis der Preisstrukturen für große Sprachmodelle (Large Language Model, LLM) entscheidend für ein effektives Kostenmanagement. Die mit LLMs verbundenen Betriebskosten können ohne angemessene Überwachung schnell eskalieren und zu unerwarteten Kostenspitzen führen, die Budgets zum Scheitern bringen und eine breite Einführung verhindern können. T
ieser Blog-Beitrag befasst sich mit den wichtigsten Komponenten der LLM-Preisstrukturen und bietet Einblicke, die Ihnen dabei helfen werden, Ihre LLM-Nutzung zu optimieren und die Kosten zu kontrollieren.
Die Preise für LLM-Studiengänge setzen sich in der Regel aus drei Hauptkomponenten zusammen: Eingabe-Token, Ausgabe-Token und Kontextfenster. Jedes dieser Elemente spielt eine wichtige Rolle bei der Bestimmung der Gesamtkosten für den Einsatz von LLMs in Ihren Anwendungen. Durch ein gründliches Verständnis dieser Komponenten sind Sie besser in der Lage, fundierte Entscheidungen über Modellauswahl, Nutzungsmuster und Optimierungsstrategien zu treffen.
Grundlegende Bestandteile der LLM-Preisgestaltung
Eingabe-Token
Eingabe-Token stellen den Text dar, der dem LLM zur Verarbeitung übergeben wird. Dazu gehören Ihre Aufforderungen, Anweisungen und jeder zusätzliche Kontext, der dem Modell zur Verfügung gestellt wird. Die Anzahl der Eingabe-Token wirkt sich direkt auf die Kosten jedes API-Aufrufs aus, da mehr Token mehr Rechenressourcen zur Verarbeitung erfordern.
Token ausgeben
Ausgabe-Token sind der Text, der vom LLM als Reaktion auf Ihre Eingabe erzeugt wird. Die Preise für Output-Token unterscheiden sich oft von denen für Input-Token, was den zusätzlichen Rechenaufwand für die Texterstellung widerspiegelt. Die Verwaltung der Output-Token-Nutzung ist entscheidend für die Kostenkontrolle, insbesondere bei Anwendungen, die große Mengen an Text erzeugen.
Kontext Fenster
Kontextfenster beziehen sich auf die Menge an früherem Text, die das Modell bei der Generierung von Antworten berücksichtigen kann. Größere Kontextfenster ermöglichen ein umfassenderes Verständnis, sind aber mit höheren Kosten verbunden, da mehr Token verwendet werden und der Rechenaufwand höher ist.
Eingabemarken: Was sie sind und wie sie aufgeladen werden
Eingabe-Token sind die grundlegenden Texteinheiten, die von einem LLM verarbeitet werden. Sie entsprechen in der Regel Teilen von Wörtern, wobei häufige Wörter oft durch ein einziges Token dargestellt werden und weniger häufige Wörter in mehrere Token aufgeteilt werden. Zum Beispiel könnte der Satz "The quick brown fox" als ["The", "quick", "bro", "wn", "fox"] tokenisiert werden, was zu 5 Eingabe-Token führt.
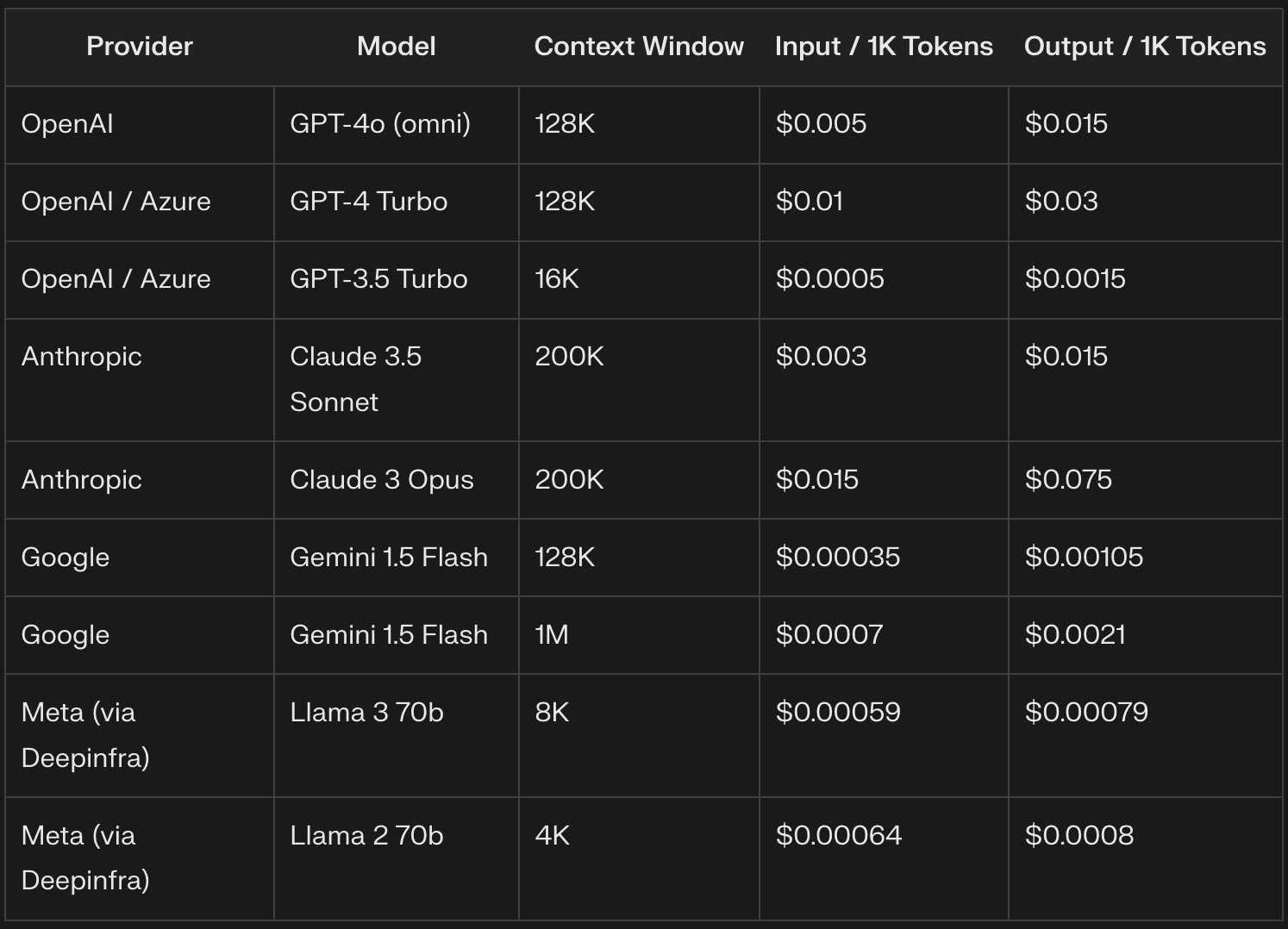
LLM-Anbieter berechnen die Eingabe-Token oft auf der Grundlage eines Tausender-Token-Satzes. So berechnet GPT-4o beispielsweise $5 pro 1 Million Input-Token, was $0,005 pro 1.000 Input-Token entspricht. Die genaue Preisgestaltung kann je nach Anbieter und Modellversion erheblich variieren, wobei für fortschrittlichere Modelle in der Regel höhere Preise verlangt werden.
Um die LLM-Kosten effektiv zu verwalten, sollten Sie diese Strategien zur Optimierung der Verwendung von Eingabe-Token in Betracht ziehen:
Prägnante Aufforderungen formulieren: Lassen Sie unnötige Worte weg und konzentrieren Sie sich auf klare, direkte Anweisungen.
Verwenden Sie eine effiziente Kodierung: Wählen Sie eine Kodierungsmethode, die Ihren Text mit weniger Token darstellt.
Implementieren Sie Prompt-Vorlagen: Entwicklung und Wiederverwendung optimierter Eingabeaufforderungsstrukturen für allgemeine Aufgaben.
Durch eine sorgfältige Verwaltung Ihrer Eingabe-Tokens können Sie die mit der LLM-Nutzung verbundenen Kosten erheblich senken und gleichzeitig die Qualität und Effektivität Ihrer KI-Anwendungen aufrechterhalten.
Output-Token: Die Kosten verstehen
Ausgabe-Token stellen den Text dar, der vom LLM als Antwort auf Ihre Eingabe generiert wird. Ähnlich wie die Eingabe-Token werden die Ausgabe-Token auf der Grundlage des Tokenisierungsprozesses des Modells berechnet. Die Anzahl der Ausgabe-Token kann jedoch je nach Aufgabe und Konfiguration des Modells erheblich variieren. So kann beispielsweise eine einfache Frage eine kurze Antwort mit wenigen Token erzeugen, während eine Anfrage nach einer detaillierten Erklärung Hunderte von Token ergeben kann.
LLM-Anbieter berechnen für Output-Token oft einen anderen Preis als für Input-Token, in der Regel einen höheren Satz aufgrund der Rechenkomplexität der Texterstellung. OpenAI zum Beispiel berechnet $15 pro 1 Million Token ($0,015 pro 1.000 Token) für GPT-4o.
Optimierung der Nutzung von Output-Token und Kostenkontrolle:
Legen Sie in Ihren Prompts oder API-Aufrufen eindeutige Grenzen für die Ausgabelänge fest.
Verwenden Sie Techniken wie "few-shot learning", um das Modell zu präziseren Antworten zu führen.
Implementierung einer Nachbearbeitung, um unnötige Inhalte aus den LLM-Ausgaben zu entfernen.
Erwägen Sie die Zwischenspeicherung häufig angeforderter Informationen, um redundante LLM-Aufrufe zu reduzieren.
Kontext-Fenster: Der verborgene Kostentreiber
Kontextfenster bestimmen, wie viel früheren Text das LLM bei der Erstellung einer Antwort berücksichtigen kann. Diese Funktion ist entscheidend für die Aufrechterhaltung der Kohärenz in Gesprächen und ermöglicht es dem Modell, auf frühere Informationen zu verweisen. Die Größe des Kontextfensters kann die Leistung des Modells erheblich beeinflussen, insbesondere bei Aufgaben, die ein Langzeitgedächtnis oder komplexes Denken erfordern.
Größere Kontextfenster erhöhen direkt die Anzahl der vom Modell verarbeiteten Eingabe-Token, was zu höheren Kosten führt. Zum Beispiel:
Ein Modell mit einem Kontextfenster mit 4.000 Token, das eine Konversation mit 3.000 Token verarbeitet, berechnet alle 3.000 Token.
Die gleiche Unterhaltung mit einem Kontextfenster von 8.000 Token könnte 7.000 Token kosten, einschließlich früherer Teile der Unterhaltung.
Diese Skalierung kann zu erheblichen Kostensteigerungen führen, insbesondere bei Anwendungen, die längere Dialoge oder Dokumentenanalysen durchführen.
Um die Nutzung des Kontextfensters zu optimieren:
Implementierung einer dynamischen Kontextgrößenanpassung auf der Grundlage der Aufgabenanforderungen.
Nutzen Sie Techniken der Zusammenfassung, um relevante Informationen aus längeren Gesprächen zu verdichten.
Verwendung von Sliding-Window-Ansätzen für die Verarbeitung langer Dokumente, die sich auf die wichtigsten Abschnitte konzentrieren.
Erwägen Sie den Einsatz kleinerer, spezialisierter Modelle für Aufgaben, die keinen umfassenden Kontext erfordern.
Durch die sorgfältige Verwaltung von Kontextfenstern können Sie ein Gleichgewicht zwischen der Aufrechterhaltung hochwertiger Ergebnisse und der Kontrolle der LLM-Kosten herstellen. Denken Sie daran, dass das Ziel darin besteht, ausreichend Kontext für die jeweilige Aufgabe bereitzustellen, ohne den Tokenverbrauch und die damit verbundenen Kosten unnötig in die Höhe zu treiben.
Künftige Trends bei der Preisgestaltung für LLM-Studiengänge
Da sich die LLM-Landschaft weiterentwickelt, kann es zu Verschiebungen in den Preisstrukturen kommen:
Aufgabenbezogene Preisgestaltung: Die Modelle werden nach der Komplexität der Aufgabe und nicht nach der Anzahl der Token berechnet.
Abonnement-Modelle: Pauschaler Zugang zu LLMs mit Nutzungsbeschränkungen oder gestaffelten Preisen.
Leistungsabhängige Preisgestaltung: Kosten, die an die Qualität oder Genauigkeit der Ergebnisse und nicht nur an die Quantität gebunden sind.
Auswirkungen des technologischen Fortschritts auf die Kosten
Die laufende Forschung und Entwicklung im Bereich der KI kann zu folgenden Ergebnissen führen:
Effizientere Modelle: Geringerer Rechenaufwand führt zu niedrigeren Betriebskosten.
Verbesserte Komprimierungstechniken: Verbesserte Methoden zur Reduzierung der Anzahl von Eingabe- und Ausgabe-Token.
Integration von Edge Computing: Lokale Verarbeitung von LLM-Aufgaben, wodurch die Kosten für Cloud-Computing gesenkt werden können.
Die Quintessenz
Das Verständnis der LLM-Preisstrukturen ist für ein effektives Kostenmanagement bei KI-Anwendungen in Unternehmen unerlässlich. Wenn Unternehmen die Feinheiten von Eingabe- und Ausgabe-Token sowie Kontextfenstern verstehen, können sie fundierte Entscheidungen über Modellauswahl und Nutzungsmuster treffen. Die Implementierung strategischer Kostenmanagementtechniken, wie z. B. die Optimierung der Token-Nutzung und die Nutzung von Caching, kann zu erheblichen Einsparungen führen.
Da sich die LLM-Technologie ständig weiterentwickelt, ist es für die Aufrechterhaltung eines kosteneffizienten KI-Betriebs entscheidend, über Preistrends und neue Optimierungsstrategien informiert zu bleiben. Denken Sie daran, dass ein erfolgreiches LLM-Kostenmanagement ein fortlaufender Prozess ist, der eine kontinuierliche Überwachung, Analyse und Anpassung erfordert, um den maximalen Nutzen aus Ihren KI-Investitionen zu gewährleisten.
Wenn Sie erfahren möchten, wie Ihr Unternehmen die LLM-Preisstrukturen effektiver nutzen kann, nehmen Sie Kontakt mit uns auf!


