
Llama 3.1 vs. proprietäre LLMs: Eine Kosten-Nutzen-Analyse für Unternehmen



Die Landschaft der großen Sprachmodelle (LLMs) hat sich zu einem Schlachtfeld zwischen Modellen mit offenem Gewicht wie Meta's Llama 3.1 und proprietäre Angebote von Tech-Giganten wie OpenAI. Während sich Unternehmen in diesem komplexen Terrain bewegen, hat die Entscheidung zwischen einem offenen Modell und einer Closed-Source-Lösung erhebliche Auswirkungen auf Innovation, Kosten und die langfristige KI-Strategie.
Llama 3.1, insbesondere seine beeindruckende Version mit 405B-Parametern, hat sich zu einem starken Konkurrenten für führende Closed-Source-Modelle wie GPT-4o und Claude 3.5 entwickelt. Dieser Wandel zwingt Unternehmen dazu, ihre Herangehensweise an die KI-Implementierung neu zu bewerten und dabei Faktoren zu berücksichtigen, die über reine Leistungsmetriken hinausgehen.
In dieser Analyse werden wir tief in die Kosten-Nutzen-Abwägungen zwischen Llama 3.1 und proprietären LLMs eintauchen und Entscheidungsträgern in Unternehmen einen umfassenden Rahmen für fundierte Entscheidungen über ihre KI-Investitionen an die Hand geben.
Kosten im Vergleich
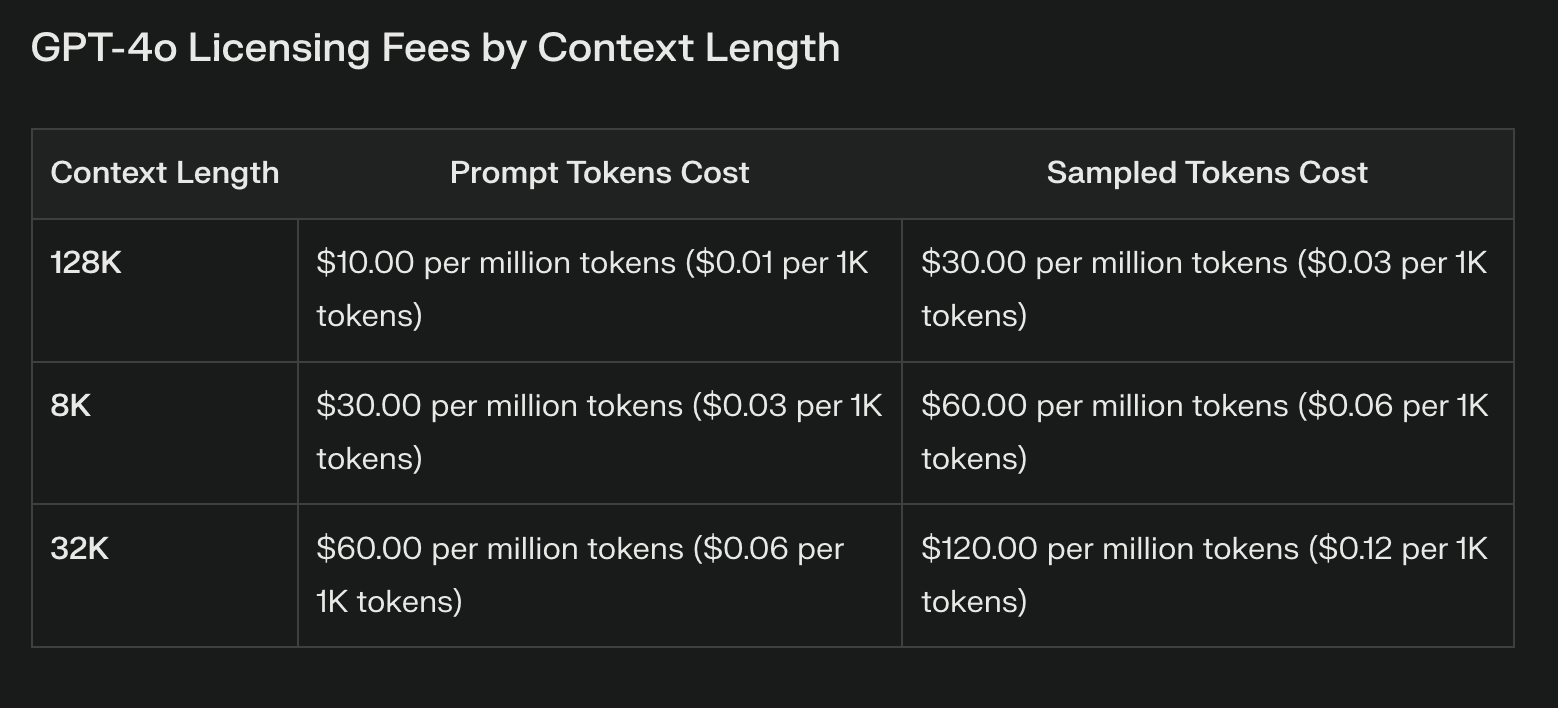
Lizenzierungsgebühren: Proprietäre vs. offene Modelle
Der offensichtlichste Kostenunterschied zwischen Llama 3.1 und proprietären Modellen liegt in den Lizenzgebühren. Proprietäre LLMs sind oft mit erheblichen wiederkehrenden Kosten verbunden, die mit der Nutzung stark ansteigen können. Diese Gebühren bieten zwar Zugang zu Spitzentechnologie, können aber die Budgets belasten und die Experimentierfreude einschränken.
Mit Llama 3.1 entfallen dank seiner offenen Gewichtung die Lizenzgebühren vollständig. Diese Kosteneinsparung kann erheblich sein, insbesondere für Unternehmen, die umfangreiche KI-Implementierungen planen. Es ist jedoch wichtig zu wissen, dass der Wegfall von Lizenzgebühren nicht gleichbedeutend mit Nullkosten ist.
Infrastruktur- und Bereitstellungskosten
Llama 3.1 spart zwar bei der Lizenzierung, erfordert aber erhebliche Rechenressourcen, insbesondere für das 405B-Parameter-Modell. Unternehmen müssen in eine robuste Hardware-Infrastruktur investieren, die oft auch High-End-GPU-Cluster oder Cloud-Computing-Ressourcen umfasst. Die effiziente Ausführung des vollständigen 405B-Modells kann beispielsweise mehrere NVIDIA H100-Grafikprozessoren erfordern, was einen erheblichen Investitionsaufwand darstellt.
Proprietäre Modelle, die in der Regel über APIs zugänglich sind, verlagern diese Infrastrukturkosten auf den Anbieter. Dies kann für Unternehmen von Vorteil sein, die nicht über die Ressourcen oder das Fachwissen zur Verwaltung einer komplexen KI-Infrastruktur verfügen. Allerdings können bei umfangreichen API-Aufrufen auch schnell Kosten anfallen, die die anfänglichen Einsparungen bei der Infrastruktur aufwiegen können.

Laufende Wartung und Updates
Die Aufrechterhaltung eines offengewichtigen Modells wie Llama 3.1 erfordert laufende Investitionen in Fachwissen und Ressourcen. Unternehmen müssen dafür Budget bereitstellen:
Regelmäßige Modellaktualisierungen und Feinabstimmungen
Sicherheitspatches und Schwachstellenmanagement
Leistungsoptimierung und Effizienzsteigerung
Proprietäre Modelle bieten diese Aktualisierungen oft als Teil ihrer Dienstleistung an, was die Belastung der internen Teams verringern kann. Diese Bequemlichkeit geht jedoch auf Kosten einer geringeren Kontrolle über den Aktualisierungsprozess und möglicher Unterbrechungen der Feinabstimmung der Modelle.
Leistungsvergleich
Benchmark-Ergebnisse über verschiedene Aufgaben hinweg
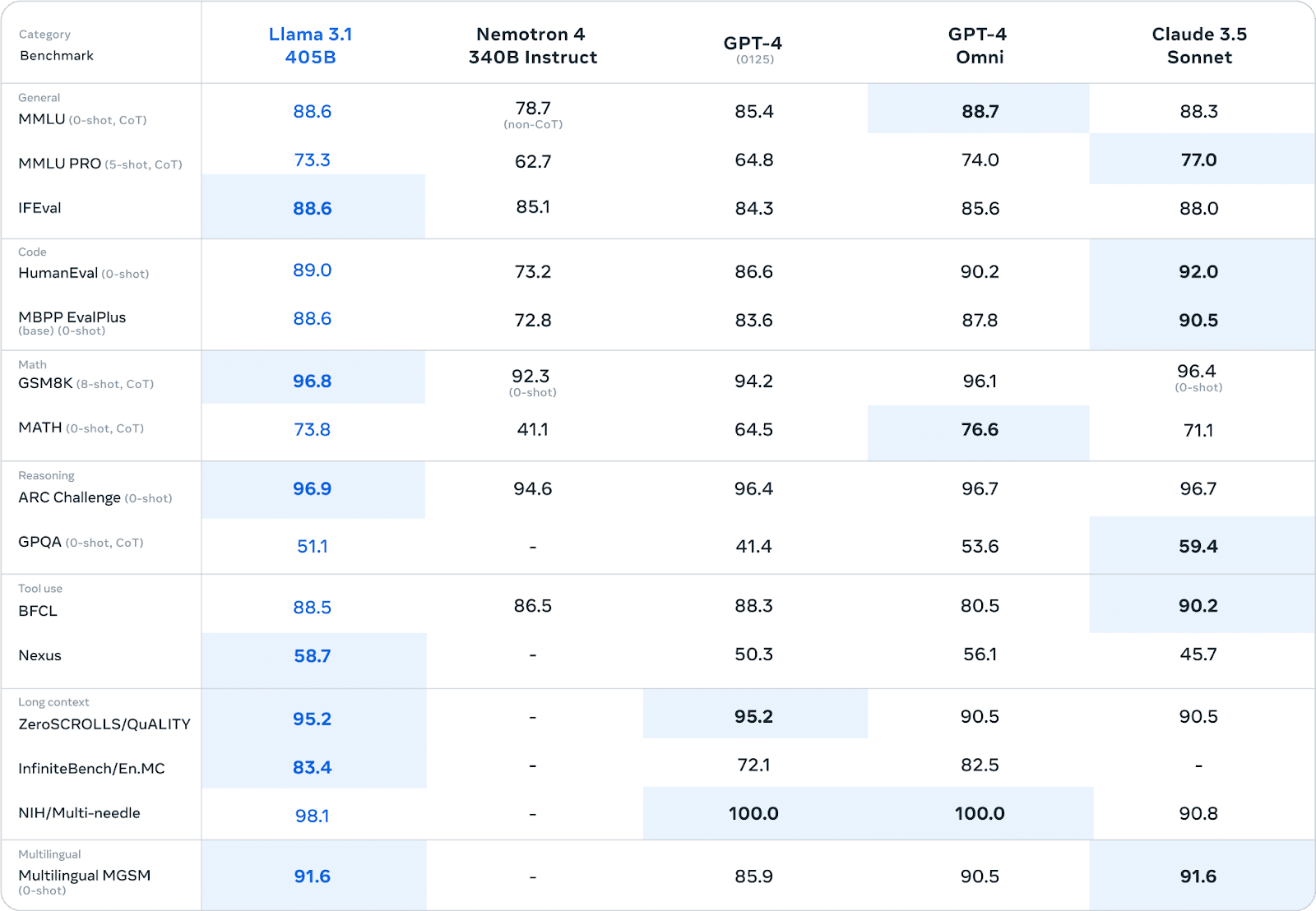
Llama 3.1 hat in verschiedenen Benchmarks eine beeindruckende Leistung gezeigt, die oft mit proprietären Modellen konkurriert oder sie sogar übertrifft. In umfangreichen menschlichen Bewertungen und automatisierten Tests hat die 405B-Parameter-Version eine vergleichbare Leistung wie führende Closed-Source-Modelle in Bereichen wie z. B.:
Allgemeinwissen und logisches Denken
Codegenerierung und Fehlerbehebung
Mathematisches Lösen von Problemen
Mehrsprachige Kenntnisse
Im MMLU-Benchmark (Massive Multitask Language Understanding) erreichte Llama 3.1 405B beispielsweise eine Punktzahl von 86,4% und steht damit in direkter Konkurrenz zu Modellen wie GPT-4.
Reale Leistung in Unternehmensumgebungen
Während Benchmarks wertvolle Einblicke liefern, ist die reale Leistung in Unternehmensumgebungen der wahre Test für die Fähigkeiten eines LLMs.
Hier wird das Bild differenzierter:
Anpassungsvorteil: Unternehmen, die Llama 3.1 einsetzen, berichten von erheblichen Vorteilen durch die Feinabstimmung des Modells auf domänenspezifische Daten. Diese Anpassung führt oft zu einer Leistung, die die von Standardmodellen für spezielle Aufgaben übertrifft.
Erzeugung synthetischer Daten: Die Fähigkeit von Llama 3.1, synthetische Daten zu erzeugen, hat sich als wertvoll für Unternehmen erwiesen, die ihre Trainingsdatensätze erweitern oder komplexe Szenarien simulieren wollen.
Kompromisse bei der Effizienz: Einige Unternehmen haben festgestellt, dass proprietäre Modelle zwar einen leichten Leistungsvorsprung haben, dass aber die Möglichkeit, spezialisierte, effiziente Modelle durch Techniken wie die Modelldestillation mit Llama 3.1 zu erstellen, zu besseren Gesamtergebnissen in Produktionsumgebungen führt.
Überlegungen zur Latenzzeit: Proprietäre Modelle, auf die über eine API zugegriffen wird, bieten möglicherweise eine geringere Latenzzeit für einzelne Abfragen, was für Echtzeitanwendungen entscheidend sein kann. Unternehmen, die Llama 3.1 auf dedizierter Hardware betreiben, berichten jedoch von einer konstanteren Leistung bei hoher Belastung.
Es ist zu beachten, dass Leistungsvergleiche in hohem Maße von spezifischen Anwendungsfällen und Implementierungsdetails abhängen. Unternehmen sollten gründliche Tests in ihren individuellen Umgebungen durchführen, um eine genaue Leistungsbewertung vornehmen zu können.
Langfristige Überlegungen
Die künftige Entwicklung von LLMs ist ein entscheidender Faktor bei der Entscheidungsfindung. Llama 3.1 profitiert von der schnellen Iteration durch eine globale Forschungsgemeinschaft, die zu bahnbrechenden Verbesserungen führen kann. Proprietäre Modelle, die von finanzstarken Unternehmen unterstützt werden, bieten kontinuierliche Aktualisierungen und die Möglichkeit der Integration proprietärer Technologien.
Die LLM-Markt ist anfällig für Störungen. Da offene Modelle wie Llama 3.1 sich der Leistung proprietärer Alternativen annähern oder diese übertreffen, könnten wir einen Trend zur Kommodifizierung von Basismodellen und eine zunehmende Spezialisierung beobachten. Aufkommende KI-Vorschriften könnten sich auch auf die Rentabilität verschiedener LLM-Ansätze auswirken.
Die Abstimmung mit umfassenderen KI-Strategien von Unternehmen ist entscheidend. Die Einführung von Llama 3.1 kann die Entwicklung unternehmensinterner KI-Expertise fördern, während das Engagement für proprietäre Modelle zu strategischen Partnerschaften mit Tech-Giganten führen kann.
Entscheidungsrahmen
Zu den Szenarien, die für Llama 3.1 sprechen, gehören:
Hochspezialisierte Industrieanwendungen, die eine umfassende Anpassung erfordern
Unternehmen mit starken internen KI-Teams, die in der Lage sind, Modelle zu verwalten
Unternehmen legen Wert auf Datenhoheit und vollständige Kontrolle über KI-Prozesse
Zu den Szenarien, die proprietäre Modelle begünstigen, gehören:
Notwendigkeit der sofortigen Bereitstellung mit minimaler Einrichtung der Infrastruktur
Erfordernis eines umfassenden Herstellersupports und garantierter SLAs
Integration in bestehende proprietäre KI-Ökosysteme
Die Quintessenz
Die Wahl zwischen Llama 3.1 und proprietären LLMs stellt einen kritischen Entscheidungspunkt für Unternehmen dar, die sich in der KI-Landschaft bewegen. Während Llama 3.1 beispiellose Flexibilität, Anpassungspotenzial und Kosteneinsparungen bei den Lizenzgebühren bietet, erfordert es erhebliche Investitionen in Infrastruktur und Fachwissen. Proprietäre Modelle bieten Benutzerfreundlichkeit, robusten Support und konsistente Updates, allerdings um den Preis einer geringeren Kontrolle und einer möglichen Anbieterbindung. Letztlich hängt die Entscheidung von den spezifischen Anforderungen, Ressourcen und der langfristigen KI-Strategie eines Unternehmens ab. Durch sorgfältiges Abwägen der in dieser Analyse dargelegten Faktoren können Entscheidungsträger einen Kurs einschlagen, der am besten mit den Zielen und Fähigkeiten ihres Unternehmens übereinstimmt.


