
Few-Shot Prompting, Learning und Fine-Tuning für LLMs - AI&YOU #67 Few-Shot Prompting, Learning und Fine-Tuning für LLMs - AI&YOU #67



Few-Shot Prompting, Learning und Fine-Tuning für LLMs - AI&YOU #67 Few-Shot Prompting, Learning und Fine-Tuning für LLMs - AI&YOU #67
Statistik der Woche: Untersuchungen von MobiDev über das Lernen mit wenigen Aufnahmen zur Klassifizierung von Münzbildern ergaben, dass mit nur 4 Bildbeispielen pro Münzwert eine Genauigkeit von ~70% erreicht werden konnte.
In der künstlichen Intelligenz ist die Fähigkeit, effizient aus begrenzten Daten zu lernen, von entscheidender Bedeutung. Deshalb ist es für Unternehmen wichtig, sich mit dem Lernen in wenigen Schritten, der Eingabeaufforderung in wenigen Schritten und der Feinabstimmung von LLMs vertraut zu machen.
In dieser Ausgabe von AI&YOU befassen wir uns mit den Erkenntnissen aus drei Blogs, die wir zu diesen Themen veröffentlicht haben:
Few-Shot Prompting, Lernen und Feinabstimmung für LLMs - AI&YOU #67
Few Shot Learning ist ein innovatives Paradigma des maschinellen Lernens, das es KI-Modellen ermöglicht, neue Konzepte oder Aufgaben aus nur wenigen Beispielen zu lernen. Im Gegensatz zu herkömmlichen überwachten Lernmethoden, die große Mengen an markierten Trainingsdaten erfordern, ermöglichen Few Shot Learning-Techniken den Modellen eine effektive Verallgemeinerung anhand einer kleinen Anzahl von Beispielen. Dieser Ansatz ahmt die menschliche Fähigkeit nach, neue Ideen schnell zu erfassen, ohne dass umfangreiche Wiederholungen erforderlich sind.
Das Wesen des Few Shot Learning liegt in seiner Fähigkeit, Vorwissen zu nutzen und sich schnell an neue Szenarien anzupassen. Durch den Einsatz von Techniken wie dem Meta-Lernen, bei dem das Modell "lernt, wie man lernt", können Few Shot Learning-Algorithmen eine breite Palette von Aufgaben mit minimalem zusätzlichem Training bewältigen. Diese Flexibilität macht sie zu einem unschätzbaren Werkzeug in Szenarien, in denen Daten knapp, teuer zu beschaffen sind oder sich ständig weiterentwickeln.

Die Herausforderung der Datenknappheit in der KI
Nicht alle Daten sind gleich, und qualitativ hochwertige, markierte Daten können ein seltenes und kostbares Gut sein. Diese Knappheit stellt eine große Herausforderung für herkömmliche überwachte Lernansätze dar, die in der Regel Tausende oder sogar Millionen von markierten Beispielen benötigen, um eine zufriedenstellende Leistung zu erzielen.
Das Problem der Datenknappheit ist besonders akut in spezialisierten Bereichen wie dem Gesundheitswesen, wo es für seltene Krankheiten nur wenige dokumentierte Fälle gibt, oder in sich schnell verändernden Umgebungen, in denen häufig neue Datenkategorien auftauchen. In diesen Szenarien können die Zeit und die Ressourcen, die für die Sammlung und Kennzeichnung großer Datensätze erforderlich sind, unerschwinglich sein, was zu einem Engpass bei der Entwicklung und dem Einsatz von KI führt.
Few Shot Learning vs. traditionelles überwachtes Lernen
Das Verständnis des Unterschieds zwischen Few Shot Learning und traditionellem überwachten Lernen ist entscheidend, um die Auswirkungen in der Praxis zu verstehen.
Traditionell überwachtes Lernenist zwar leistungsstark, hat aber auch Nachteile:
Daten-Abhängigkeit: Kämpft mit begrenzten Trainingsdaten.
Unflexibilität: Erbringt nur bei bestimmten Aufgaben gute Leistungen.
Intensität der Ressourcen: Erfordert große, teure Datensätze.
Kontinuierliche Aktualisierung: Erfordert häufige Umschulungen in dynamischen Umgebungen.
Wenige Schüsse Lernen bietet einen Paradigmenwechsel:
Beispielhafte Effizienz: Verallgemeinert aus wenigen Beispielen durch Meta-Lernen.
Schnelle Anpassung: Passt sich schnell an neue Aufgaben an und braucht nur wenige Beispiele.
Optimierung der Ressourcen: Reduziert den Bedarf an Datenerfassung und Kennzeichnung.
Kontinuierliches Lernen: Geeignet, um neues Wissen aufzunehmen, ohne es zu vergessen.
Vielseitigkeit: Anwendbar in verschiedenen Bereichen, von Computer Vision bis NLP.
Durch die Bewältigung dieser Herausforderungen ermöglicht Few Shot Learning anpassungsfähigere und effizientere KI-Modelle und eröffnet neue Möglichkeiten für die KI-Entwicklung.
Das Spektrum des probeneffizienten Lernens
Ein faszinierendes Spektrum von Ansätzen zielt darauf ab, die erforderlichen Trainingsdaten zu minimieren, darunter Zero Shot, One Shot und Few Shot Learning.
Zero Shot Learning: Lernen ohne Beispiele
Erkennt ungesehene Klassen anhand von Hilfsinformationen wie Textbeschreibungen
Wertvoll, wenn beschriftete Beispiele für alle Klassen unpraktisch oder unmöglich sind
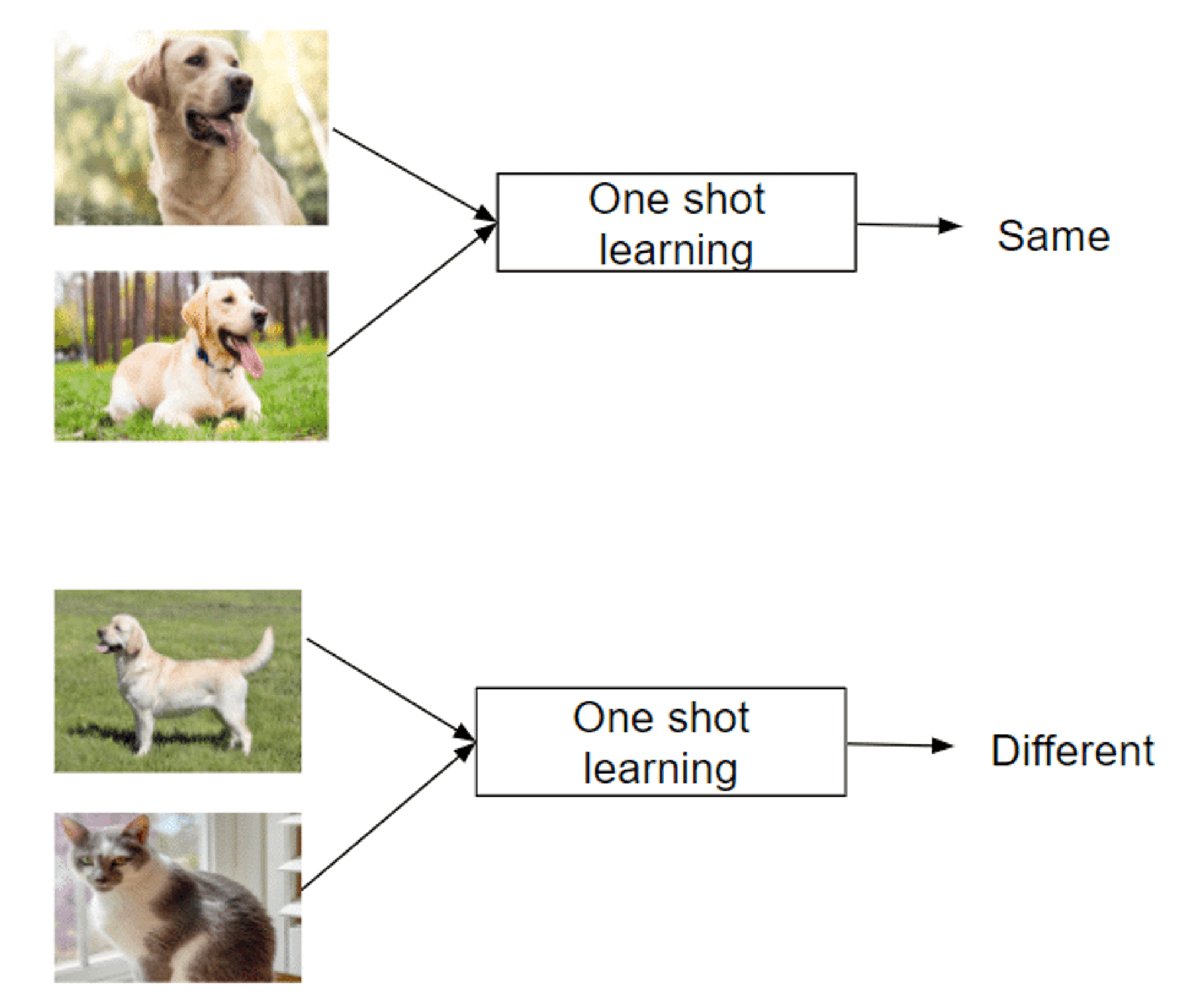
One Shot Learning: Lernen von einer einzigen Instanz
Erkennt neue Klassen anhand eines einzigen Beispiels
Ahmt die menschliche Fähigkeit nach, Konzepte schnell zu erfassen
Erfolgreich in Bereichen wie Gesichtserkennung
Few Shot Learning: Aufgaben mit minimalen Daten bewältigen
Verwendet 2-5 beschriftete Beispiele pro neuer Klasse
Gleichgewicht zwischen extremer Dateneffizienz und traditionellen Methoden
Ermöglicht eine schnelle Anpassung an neue Aufgaben oder Klassen
Nutzt Meta-Lernstrategien, um zu lernen, wie man lernt
Dieses Spektrum von Ansätzen bietet einzigartige Fähigkeiten, um die Herausforderung des Lernens aus begrenzten Beispielen zu bewältigen, was sie in datenarmen Bereichen von unschätzbarem Wert macht.
Few Shot Prompting vs. Feinabstimmung LLM
In diesem Bereich gibt es zwei leistungsfähigere Techniken: few-shot prompting und fine-tuning. Beim Few-Shot Prompting werden clevere Eingabeaufforderungen mit einer kleinen Anzahl von Beispielen erstellt, die das Modell dazu anleiten, eine bestimmte Aufgabe ohne zusätzliches Training auszuführen. Bei der Feinabstimmung hingegen werden die Parameter des Modells anhand einer begrenzten Menge aufgabenspezifischer Daten aktualisiert, so dass das Modell sein umfangreiches Wissen an einen bestimmten Bereich oder eine bestimmte Anwendung anpassen kann.
Beide Ansätze fallen unter den Begriff des "few-shot learning". Durch den Einsatz dieser Techniken können wir die Leistung und Vielseitigkeit von LLMs drastisch verbessern und sie zu praktischeren und effektiveren Werkzeugen für eine breite Palette von Anwendungen in der natürlichen Sprachverarbeitung und darüber hinaus machen.
Few-Shot Prompting: Das LLM-Potenzial freisetzen
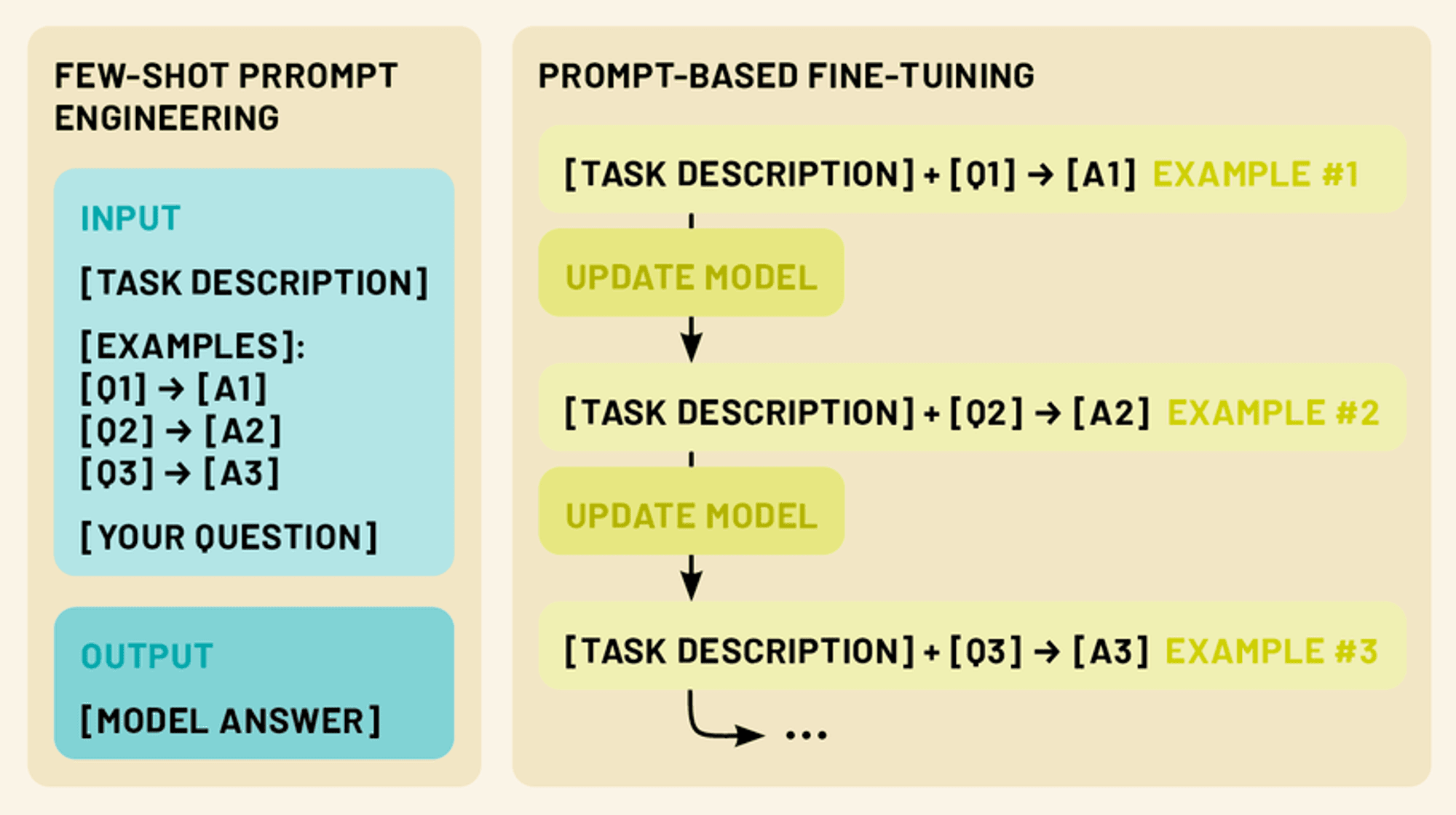
Das Few-Shot Prompting nutzt die Fähigkeit des Modells, Anweisungen zu verstehen, und "programmiert" das LLM durch gezielte Prompts effektiv.
Die Eingabeaufforderung mit wenigen Bildern liefert 1-5 Beispiele für die gewünschte Aufgabe und nutzt die Mustererkennung und Anpassungsfähigkeit des Modells. Dies ermöglicht die Ausführung von Aufgaben, für die nicht explizit trainiert wurde, und nutzt die Fähigkeit des LLM zum kontextbezogenen Lernen.
Durch die Darstellung klarer Eingabe-/Ausgabemuster leitet das LLM das System dazu an, ähnliche Überlegungen auf neue Eingaben anzuwenden, was eine schnelle Anpassung an neue Aufgaben ohne Parameteraktualisierung ermöglicht.
Arten von "few-shot"-Aufforderungen (zero-shot, one-shot, few-shot)
Few-shot prompting umfasst ein Spektrum von Ansätzen, die jeweils durch die Anzahl der angebotenen Beispiele definiert sind. (Genau wie beim Lernen mit wenigen Beispielen):
Null-Schuss-Eingabeaufforderung: In diesem Szenario werden keine Beispiele gegeben. Stattdessen wird dem Modell eine klare Anweisung oder Beschreibung der Aufgabe gegeben. Zum Beispiel: "Übersetzen Sie den folgenden englischen Text ins Französische: [Eingabetext]".
Einmalige Eingabeaufforderung: Hier wird der eigentlichen Eingabe ein einziges Beispiel vorangestellt. Dadurch erhält das Modell ein konkretes Beispiel für die erwartete Input-Output-Beziehung. Ein Beispiel: "Klassifizieren Sie die Stimmung der folgenden Rezension als positiv oder negativ. Beispiel: 'Dieser Film war fantastisch!' - Positive Eingabe: 'Ich konnte die Handlung nicht ertragen.' - [Modell generiert Antwort]"
Wenige Schüsse Souffleuse: Bei diesem Ansatz werden mehrere Beispiele (in der Regel 2-5) vor der eigentlichen Eingabe gegeben. Dies ermöglicht es dem Modell, komplexere Muster und Nuancen in der Aufgabe zu erkennen. Zum Beispiel: "Klassifizieren Sie die folgenden Sätze als Fragen oder Aussagen: 'Der Himmel ist blau.' - Aussage: 'Wie spät ist es?' - Frage: 'Ich liebe Eiscreme.' - Aussage Eingabe: 'Wo finde ich das nächste Restaurant?' - [Modell erzeugt Antwort]"
Gestaltung von effektiven Aufforderungen in wenigen Augenblicken
Das Verfassen von effektiven "few-shot prompts" ist sowohl eine Kunst als auch eine Wissenschaft. Hier sind einige wichtige Grundsätze zu beachten:
Klarheit und Kohärenz: Achten Sie darauf, dass Ihre Beispiele und Anweisungen klar sind und einem einheitlichen Format folgen. Dadurch kann das Modell das Muster leichter erkennen.
Vielfältigkeit: Wenn Sie mehrere Beispiele verwenden, versuchen Sie, eine Reihe möglicher Eingaben und Ausgaben abzudecken, um dem Modell ein breiteres Verständnis der Aufgabe zu vermitteln.
Relevanz: Wählen Sie Beispiele, die in engem Zusammenhang mit der spezifischen Aufgabe oder dem Bereich stehen, auf den Sie abzielen. So kann sich das Modell auf die wichtigsten Aspekte seines Wissens konzentrieren.
Prägnanz: Es ist zwar wichtig, genügend Kontext zu liefern, aber vermeiden Sie übermäßig lange oder komplexe Aufforderungen, die das Modell verwirren oder die Schlüsselinformationen verwässern könnten.
Experimentieren: Scheuen Sie sich nicht, mit verschiedenen Aufforderungsstrukturen und Beispielen zu experimentieren, um herauszufinden, was für Ihren speziellen Anwendungsfall am besten geeignet ist.
Durch die Beherrschung der Kunst des "few-shot prompting" können wir das volle Potenzial von LLMs freisetzen und sie in die Lage versetzen, ein breites Spektrum von Aufgaben mit minimalem zusätzlichem Input oder Training zu bewältigen.
Feinabstimmung von LLMs: Anpassung von Modellen mit begrenzten Daten
Während das "few-shot prompting" eine leistungsstarke Technik ist, um LLMs an neue Aufgaben anzupassen, ohne das Modell selbst zu verändern, bietet das "fine-tuning" eine Möglichkeit, die Parameter des Modells zu aktualisieren, um eine noch bessere Leistung bei spezifischen Aufgaben oder Domänen zu erzielen. Die Feinabstimmung ermöglicht es uns, das umfangreiche Wissen, das in vortrainierten LLMs kodiert ist, zu nutzen und sie gleichzeitig auf unsere spezifischen Bedürfnisse zuzuschneiden, indem wir nur eine kleine Menge aufgabenspezifischer Daten verwenden.
Verständnis der Feinabstimmung im Kontext der LLMs
Die Feinabstimmung eines LLM umfasst das weitere Training eines vortrainierten Modells auf einem kleineren, aufgabenspezifischen Datensatz. Durch diesen Prozess wird das Modell an die Zielaufgabe angepasst, während es auf vorhandenem Wissen aufbaut und weniger Daten und Ressourcen benötigt als ein Training von Grund auf.
Bei LLMs werden bei der Feinabstimmung normalerweise die Gewichte in den oberen Schichten für aufgabenspezifische Merkmale angepasst, während die unteren Schichten weitgehend unverändert bleiben. Bei diesem Ansatz des "Transfer-Lernens" wird ein breites Sprachverständnis beibehalten, während spezialisierte Fähigkeiten entwickelt werden.
Feintuning-Techniken mit wenigen Aufnahmen
Bei der Feinabstimmung in wenigen Schritten wird das Modell anhand von nur 10 bis 100 Stichproben pro Klasse oder Aufgabe angepasst, was sich als nützlich erweist, wenn nur wenige beschriftete Daten vorliegen. Zu den wichtigsten Techniken gehören:
Prompt-basierte Feinabstimmung: Kombiniert die Eingabeaufforderung in wenigen Schritten mit der Aktualisierung der Parameter.
Ansätze des Meta-Lernens: Methoden wie MAML Ziel ist es, gute Ausgangspunkte für eine schnelle Anpassung zu finden.
Adapterbasierte Feinabstimmung: Einführung von kleinen "Adapter"-Modulen zwischen vortrainierten Modellschichten, wodurch die trainierbaren Parameter reduziert werden.
Kontextbezogenes Lernen: Feinabstimmung der LLMs, um eine bessere Anpassung allein durch Aufforderungen zu erreichen.
Diese Techniken ermöglichen es den LLM, sich mit minimalen Daten an neue Aufgaben anzupassen, was ihre Vielseitigkeit und Effizienz erhöht.
Few-Shot Prompting vs. Fine-Tuning: Die Wahl des richtigen Ansatzes
Bei der Anpassung von LLMs an spezifische Aufgaben bieten sowohl das "few-shot prompting" als auch das "fine-tuning" leistungsfähige Lösungen. Jede Methode hat jedoch ihre eigenen Stärken und Grenzen, und die Wahl des richtigen Ansatzes hängt von verschiedenen Faktoren ab.
Few-Shot Prompting Stärken:
Erfordert keine Aktualisierung der Modellparameter, so dass das ursprüngliche Modell erhalten bleibt
Hochflexibel und fliegend anpassbar
Keine zusätzliche Schulungszeit oder Rechenressourcen erforderlich
Nützlich für schnelles Prototyping und Experimentieren
Beschränkungen:
Die Leistung kann weniger konsistent sein, insbesondere bei komplexen Aufgaben.
Begrenzt durch die ursprünglichen Fähigkeiten und Kenntnisse des Modells
Kann sich mit hochspezialisierten Bereichen oder Aufgaben schwer tun
Feinabstimmung der Stärken:
Erzielt oft eine bessere Leistung bei bestimmten Aufgaben
Kann das Modell an neue Bereiche und Fachvokabular anpassen
Einheitlichere Ergebnisse bei ähnlichen Eingaben
Potenzial für kontinuierliches Lernen und Verbesserung
Beschränkungen:
Erfordert zusätzliche Ausbildungszeit und Rechenressourcen
Gefahr des katastrophalen Vergessens, wenn nicht sorgfältig gehandelt wird
Kann bei kleinen Datensätzen zu stark angepasst werden
Weniger flexibel; erfordert Umschulung bei wesentlichen Aufgabenänderungen
Die 5 besten Forschungspapiere für das Lernen mit wenigen Strichen
In dieser Woche befassen wir uns auch mit den folgenden fünf Veröffentlichungen, die diesen Bereich erheblich vorangebracht haben und innovative Ansätze vorstellen, die die KI-Fähigkeiten neu gestalten.

1️⃣ Matching Networks for One Shot Learning" (Vinyals et al., 2016)
Einführung eines bahnbrechenden Ansatzes, der Gedächtnis- und Aufmerksamkeitsmechanismen nutzt. Die Abgleichsfunktion vergleicht Abfragebeispiele mit markierten Hilfsbeispielen und setzt damit einen neuen Standard für Lernmethoden mit wenigen Schritten.
2️⃣ Prototypische Netzwerke für Few-shot Learning" (Snell et al., 2017)
Er stellte einen einfacheren, aber effektiven Ansatz vor, bei dem ein metrischer Raum erlernt wird, in dem die Klassen durch einen einzigen Prototyp repräsentiert werden. Seine Einfachheit und Effektivität machten ihn zu einer beliebten Grundlage für nachfolgende Forschungen.
3️⃣ Lernen zu vergleichen: Relation Network for Few-Shot Learning" (Sung et al., 2018)
Einführung eines lernfähigen Beziehungsmoduls, mit dem das Modell eine auf bestimmte Aufgaben und Datenverteilungen zugeschnittene Vergleichsmetrik erlernen kann. Nachweislich starke Leistung bei verschiedenen Benchmarks.
4️⃣ A Closer Look at Few-shot Classification" (Chen et al., 2019)
Er lieferte eine umfassende Analyse bestehender Methoden und stellte gängige Annahmen in Frage. Er schlug einfache Basismodelle vor, die komplexeren Ansätzen entsprachen oder sie sogar übertrafen, wobei er die Bedeutung von Merkmalsgrundgerüsten und Trainingsstrategien hervorhob.
5️⃣ Meta-Baseline: Erforschung des einfachen Meta-Lernens für Few-Shot Learning" (Chen et al., 2021)
Kombinierte das Standard-Pre-Training mit einer Meta-Learning-Phase und erreichte so eine Spitzenleistung. Hervorhebung der Kompromisse zwischen den Zielen des Standardtrainings und des Meta-Learnings.
Diese Arbeiten haben nicht nur die akademische Forschung vorangebracht, sondern auch den Weg für praktische Anwendungen der KI in Unternehmen geebnet. Sie stellen einen Fortschritt auf dem Weg zu effizienteren, anpassungsfähigen KI-Systemen dar, die in der Lage sind, aus begrenzten Daten zu lernen - eine entscheidende Fähigkeit in vielen Geschäftskontexten.
Die Quintessenz
Few-Shot-Learning, Prompting und Fine-Tuning sind bahnbrechende Ansätze, die es LLMs ermöglichen, sich mit minimalen Daten schnell an spezielle Aufgaben anzupassen. Wie wir untersucht haben, bieten diese Techniken eine noch nie dagewesene Flexibilität und Effizienz bei der Anpassung von LLMs an verschiedene Anwendungen in verschiedenen Branchen, von der Verbesserung von Aufgaben der natürlichen Sprachverarbeitung bis hin zur Ermöglichung domänenspezifischer Anpassungen in Bereichen wie Gesundheitswesen, Recht und Technologie.
Danke, dass Sie sich die Zeit genommen haben, AI & YOU zu lesen!
Für noch mehr Inhalte zum Thema KI für Unternehmen, einschließlich Infografiken, Statistiken, Anleitungen, Artikeln und Videos, folgen Sie Skim AI auf LinkedIn
Sie sind Gründer, CEO, Risikokapitalgeber oder Investor und suchen KI-Beratung, fraktionierte KI-Entwicklung oder Due-Diligence-Dienstleistungen? Holen Sie sich die Beratung, die Sie brauchen, um fundierte Entscheidungen über die KI-Produktstrategie Ihres Unternehmens und Investitionsmöglichkeiten zu treffen.
Wir entwickeln maßgeschneiderte KI-Lösungen für von Venture Capital und Private Equity unterstützte Unternehmen in den folgenden Branchen: Medizintechnik, Nachrichten/Content-Aggregation, Film- und Fotoproduktion, Bildungstechnologie, Rechtstechnologie, Fintech und Kryptowährungen.


