
AI Research Paper zusammengefasst: "Chain of Thought(lessness)?" Aufforderung



Chain-of-Thought (CoT) Prompting wurde als Durchbruch bei der Erschließung der Argumentationsfähigkeiten von großen Sprachmodellen (LLMs) gepriesen. Diese Technik, bei der LLMs durch Schritt-für-Schritt-Beispiele angeleitet werden, hat in der KI-Gemeinschaft große Aufmerksamkeit erregt. Viele Forscher und Praktiker haben behauptet, dass CoT Prompting es LLMs ermöglicht, komplexe Denkaufgaben effektiver zu bewältigen und so möglicherweise die Lücke zwischen maschineller Berechnung und menschenähnlicher Problemlösung zu schließen.
Ein kürzlich veröffentlichtes Papier mit dem Titel "Kette der Rücksichtslosigkeit? Eine Analyse von CoT in der Planung" stellt diese optimistischen Behauptungen in Frage. Dieses Forschungspapier, das sich auf Planungsaufgaben konzentriert, bietet eine kritische Untersuchung der Wirksamkeit und Verallgemeinerbarkeit von CoT-Prompting. Für KI-Praktiker ist es von entscheidender Bedeutung, diese Ergebnisse und ihre Auswirkungen auf die Entwicklung von KI-Anwendungen zu verstehen, die anspruchsvolle Argumentationsfähigkeiten erfordern.
Zum Verständnis der Studie
Die Forscher wählten eine klassische Planungsdomäne namens Blocksworld als primäres Testfeld. In Blocksworld besteht die Aufgabe darin, eine Reihe von Blöcken von einer Ausgangskonfiguration zu einer Zielkonfiguration umzuordnen, indem eine Reihe von Bewegungsaktionen durchgeführt wird. Diese Domäne eignet sich ideal zum Testen von Denk- und Planungsfähigkeiten, denn:
Es ermöglicht die Generierung von Problemen mit unterschiedlicher Komplexität
Sie hat klare, algorithmisch überprüfbare Lösungen
Es ist unwahrscheinlich, dass sie in den LLM-Trainingsdaten stark vertreten ist.
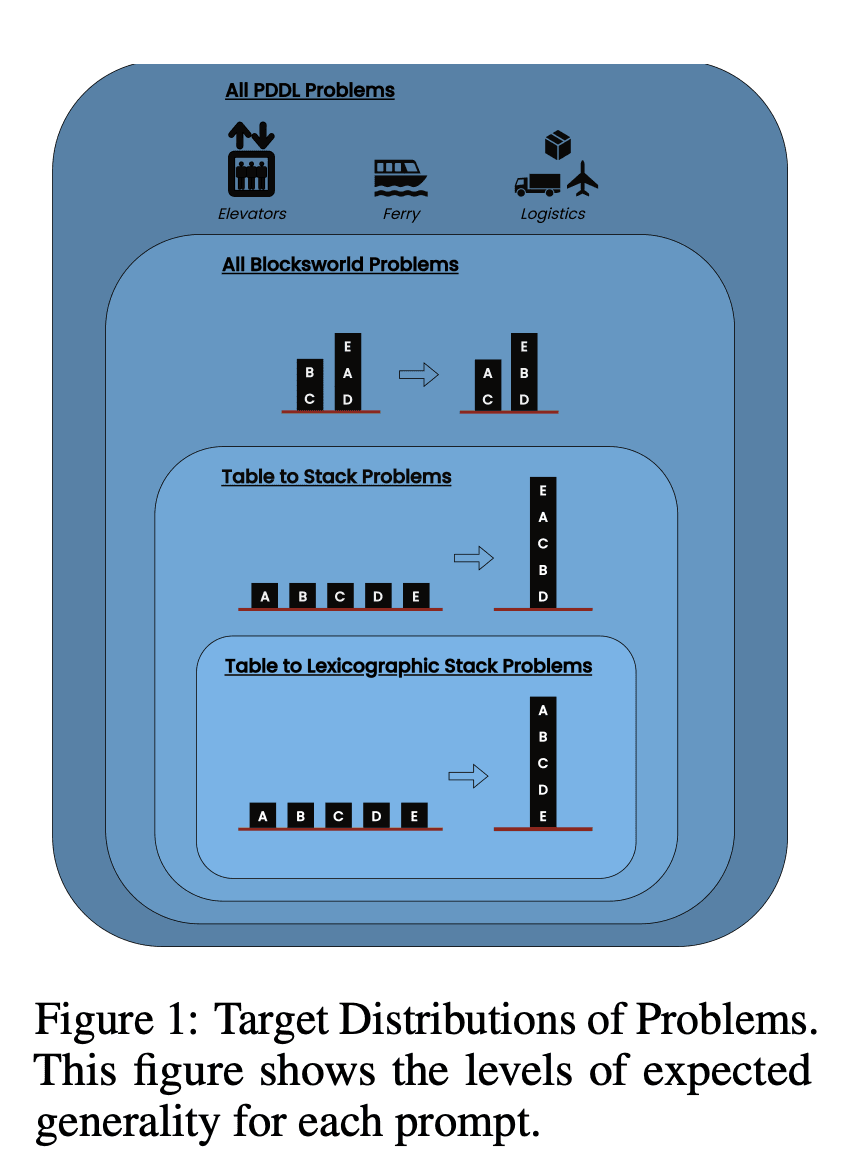
In der Studie wurden drei moderne LLMs untersucht: GPT-4, Claude-3-Opus und GPT-4-Turbo. Diese Modelle wurden mit Aufforderungen unterschiedlicher Spezifität getestet:
Null-Schuss Gedankenkette (Universal): Es genügt, der Aufforderung "Denken wir Schritt für Schritt" hinzuzufügen.
Fortschrittsnachweis (speziell für PDDL): Eine allgemeine Erläuterung der Korrektheit von Plänen mit Beispielen.
Blocksworld Universal Algorithmus: Demonstration eines allgemeinen Algorithmus zur Lösung beliebiger Blocksworld-Probleme.
Aufforderung zum Stapeln: Konzentration auf eine bestimmte Unterklasse von Blocksworld-Problemen (Tisch-zu-Stapel).
Lexikografische Stapelung: Weitere Eingrenzung auf eine bestimmte syntaktische Form des Zielzustandes.
Durch das Testen dieser Aufforderungen an immer komplexeren Problemen wollten die Forscher herausfinden, wie gut LLMs das in den Beispielen demonstrierte Denken verallgemeinern können.
Wesentliche Ergebnisse enthüllt
Die Ergebnisse dieser Studie stellen viele der vorherrschenden Annahmen über CoT-Prompting in Frage:
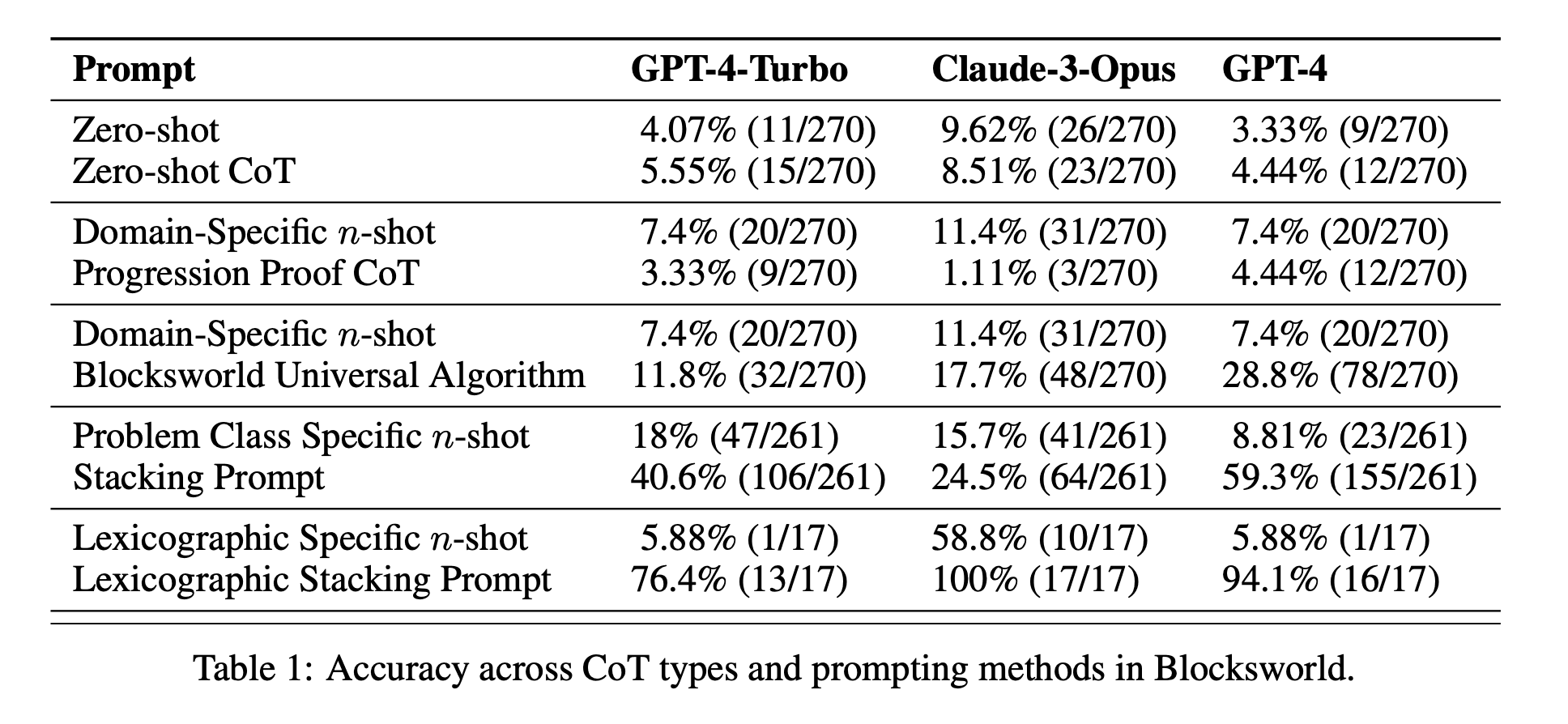
Begrenzte Wirksamkeit des CoT: Entgegen früherer Behauptungen zeigte das CoT-Prompting nur dann signifikante Leistungsverbesserungen, wenn die bereitgestellten Beispiele dem Abfrageproblem extrem ähnlich waren. Sobald die Probleme vom exakten Format der Beispiele abwichen, sank die Leistung drastisch.
Rasche Verschlechterung der Leistung: Mit zunehmender Komplexität der Probleme (gemessen an der Anzahl der beteiligten Blöcke) nahm die Genauigkeit aller Modelle drastisch ab, unabhängig von der verwendeten CoT-Aufforderung. Dies deutet darauf hin, dass LLMs Schwierigkeiten haben, das in einfachen Beispielen gezeigte logische Denken auf komplexere Szenarien zu übertragen.
Unwirksamkeit von allgemeinen Aufforderungen: Überraschenderweise schnitten allgemeinere CoT-Aufforderungen oft schlechter ab als Standardaufforderungen ohne Argumentationsbeispiele. Dies widerspricht der Vorstellung, dass CoT LLMs hilft, verallgemeinerbare Problemlösungsstrategien zu lernen.
Kompromiss bei der Spezifität: Die Studie ergab, dass mit hochspezifischen Aufforderungen eine hohe Genauigkeit erreicht werden kann, allerdings nur bei einer sehr kleinen Teilmenge von Problemen. Dies zeigt, dass es einen starken Kompromiss zwischen Leistungssteigerung und Anwendbarkeit der Aufforderung gibt.
Fehlen eines echten algorithmischen Lernens: Die Ergebnisse deuten stark darauf hin, dass LLMs nicht lernen, allgemeine algorithmische Verfahren aus den CoT-Beispielen anzuwenden. Stattdessen scheinen sie sich auf Mustervergleiche zu verlassen, die bei neuartigen oder komplexeren Problemen schnell versagen.
Diese Ergebnisse haben erhebliche Auswirkungen für KI-Praktiker und Unternehmen, die CoT-Prompting in ihren Anwendungen nutzen wollen. Sie deuten darauf hin, dass CoT zwar die Leistung in bestimmten engen Szenarien steigern kann, aber möglicherweise nicht das Allheilmittel für komplexe Denkaufgaben ist, auf das viele gehofft hatten.
Jenseits von Blocksworld: Ausweitung der Untersuchung
Um sicherzustellen, dass ihre Ergebnisse nicht auf die Blocksworld-Domäne beschränkt sind, haben die Forscher ihre Untersuchung auf mehrere synthetische Problemdomänen ausgedehnt, die in früheren CoT-Studien häufig verwendet wurden:
CoinFlip: Eine Aufgabe, bei der es darum geht, den Zustand einer Münze nach einer Reihe von Würfen vorherzusagen.
LastLetterConcatenation: Eine Textverarbeitungsaufgabe, bei der die letzten Buchstaben eines gegebenen Wortes aneinandergereiht werden müssen.
Mehrschrittige Arithmetik: Probleme mit der Vereinfachung komplexer arithmetischer Ausdrücke.
Diese Bereiche wurden ausgewählt, weil sie die Erzeugung von Problemen mit zunehmender Komplexität ermöglichen, ähnlich wie bei Blocksworld. Die Ergebnisse aus diesen zusätzlichen Experimenten stimmten auffallend gut mit den Ergebnissen von Blocksworld überein:
Mangelnde Verallgemeinerung: CoT-Prompting zeigte nur bei Problemen, die den vorgegebenen Beispielen sehr ähnlich waren, Verbesserungen. Mit zunehmender Problemkomplexität verschlechterte sich die Leistung schnell auf ein Niveau, das mit dem des Standardprompts vergleichbar oder sogar schlechter war.
Syntaktische Musterübereinstimmung: Bei der Aufgabe LastLetterConcatenation verbesserte die CoT-Aufforderung bestimmte syntaktische Aspekte der Antworten (z. B. die Verwendung der richtigen Buchstaben), konnte aber die Genauigkeit nicht aufrechterhalten, als die Anzahl der Wörter zunahm.
Scheitern trotz perfekter Zwischenschritte: Bei den arithmetischen Aufgaben konnten die Modelle zwar alle möglichen einstelligen Operationen perfekt lösen, aber sie waren nicht in der Lage, längere Operationsfolgen zu verallgemeinern.
Diese Ergebnisse untermauern die Schlussfolgerung, dass aktuelle LLMs keine wirklich verallgemeinerbaren Argumentationsstrategien aus CoT-Beispielen lernen. Stattdessen scheinen sie sich stark auf oberflächlichen Musterabgleich zu verlassen, der zusammenbricht, wenn sie mit Problemen konfrontiert werden, die von den gezeigten Beispielen abweichen.
Auswirkungen auf die KI-Entwicklung
Die Ergebnisse dieser Studie haben erhebliche Auswirkungen auf die KI-Entwicklung, insbesondere für Unternehmen, die an Anwendungen arbeiten, die komplexe Denk- oder Planungsfunktionen erfordern:
Neubewertung der CoT-Wirksamkeit: Die Studie stellt die Vorstellung in Frage, dass CoT-Anweisungen allgemeine Denkfähigkeiten bei LLMs "freischalten". KI-Entwickler sollten vorsichtig sein, wenn sie sich bei Aufgaben, die echtes algorithmisches Denken oder Verallgemeinerung auf neue Szenarien erfordern, auf CoT verlassen.
Beschränkungen der derzeitigen LLMs: Trotz ihrer beeindruckenden Fähigkeiten in vielen Bereichen haben moderne LLMs immer noch Schwierigkeiten mit konsistenten, verallgemeinerbaren Schlussfolgerungen. Dies deutet darauf hin, dass für Anwendungen, die eine robuste Planung oder mehrstufige Problemlösung erfordern, alternative Ansätze erforderlich sein könnten.
Die Kosten einer prompten Entwicklung: Während hochspezifische CoT-Prompts gute Ergebnisse für enge Problemgruppen liefern können, kann der menschliche Aufwand, der für die Erstellung dieser Prompts erforderlich ist, die Vorteile überwiegen, insbesondere angesichts ihrer begrenzten Verallgemeinerbarkeit.
Bewertungsmetriken überdenken: Die Studie unterstreicht, wie wichtig es ist, KI-Modelle an Problemen unterschiedlicher Komplexität und Struktur zu testen. Wenn man sich ausschließlich auf statische Testsätze verlässt, kann die tatsächliche Denkfähigkeit eines Modells überschätzt werden.
Die Kluft zwischen Wahrnehmung und Realität: Es besteht eine erhebliche Diskrepanz zwischen den wahrgenommenen Argumentationsfähigkeiten von LLMs (die im populären Diskurs oft anthropomorphisiert werden) und ihren tatsächlichen Fähigkeiten, wie in dieser Studie gezeigt wurde.
Empfehlungen für AI-Praktiker
Ausgehend von diesen Erkenntnissen sind hier einige wichtige Empfehlungen für KI-Praktiker und Unternehmen, die mit LLM arbeiten:
Strenge Bewertungspraktiken:
Implementierung von Test-Frameworks, die Probleme unterschiedlicher Komplexität erzeugen können.
Verlassen Sie sich nicht ausschließlich auf statische Testsätze oder Benchmarks, die in den Trainingsdaten enthalten sein können.
Bewerten Sie die Leistung über ein Spektrum von Problemvariationen, um eine echte Generalisierung zu beurteilen.
Realistische Erwartungen für CoT:
Setzen Sie das CoT-Prompting mit Bedacht ein und beachten Sie seine Grenzen bei der Verallgemeinerung.
Seien Sie sich bewusst, dass die Leistungsverbesserungen durch CoT auf bestimmte Problemgruppen beschränkt sein können.
Bedenken Sie die Abwägung zwischen zeitnahem technischen Aufwand und potenziellen Leistungssteigerungen.
Hybride Ansätze:
Für komplexe Schlussfolgerungsaufgaben sollten LLMs mit traditionellen algorithmischen Ansätzen oder spezialisierten Schlussfolgerungsmodulen kombiniert werden.
Erforschung von Methoden, die die Stärken von LLMs (z. B. natürliches Sprachverständnis) nutzen und gleichzeitig ihre Schwächen bei der algorithmischen Schlussfolgerung ausgleichen können.
Transparenz bei KI-Anwendungen:
Die Grenzen von KI-Systemen müssen klar kommuniziert werden, insbesondere wenn es sich um Denk- oder Planungsaufgaben handelt.
Vermeiden Sie eine Überbewertung der Fähigkeiten von LLMs, insbesondere bei sicherheitskritischen Anwendungen oder Anwendungen, bei denen viel auf dem Spiel steht.
Fortgesetzte Forschung und Entwicklung:
Investitionen in die Forschung zur Verbesserung der echten Denkfähigkeiten von KI-Systemen.
Erforschung alternativer Architekturen oder Trainingsmethoden, die zu einer robusteren Generalisierung bei komplexen Aufgaben führen könnten.
Bereichsspezifische Feinabstimmung:
Für enge, genau definierte Problemdomänen sollten Sie eine Feinabstimmung der Modelle auf domänenspezifische Daten und Argumentationsmuster in Betracht ziehen.
Seien Sie sich bewusst, dass eine solche Feinabstimmung die Leistung innerhalb des Bereichs verbessern kann, aber nicht über diesen hinaus verallgemeinert werden kann.
Indem sie diese Empfehlungen befolgen, können KI-Praktiker robustere und zuverlässigere KI-Anwendungen entwickeln und potenzielle Fallstricke vermeiden, die mit einer Überschätzung der Argumentationsfähigkeiten aktueller LLMs verbunden sind. Die Erkenntnisse aus dieser Studie dienen als wertvolle Erinnerung an die Bedeutung einer kritischen Bewertung und realistischen Einschätzung im sich schnell entwickelnden Bereich der KI.
Die Quintessenz
Diese bahnbrechende Studie über Gedankenketten bei Planungsaufgaben stellt unser Verständnis von LLM-Fähigkeiten in Frage und veranlasst eine Neubewertung der derzeitigen KI-Entwicklungspraktiken. Indem sie die Grenzen von CoT bei der Verallgemeinerung auf komplexe Probleme aufzeigt, unterstreicht sie den Bedarf an strengeren Tests und realistischen Erwartungen bei KI-Anwendungen.
Für KI-Praktiker und Unternehmen zeigen diese Ergebnisse, wie wichtig es ist, LLM-Stärken mit spezialisierten Schlussfolgerungsansätzen zu kombinieren, bei Bedarf in domänenspezifische Lösungen zu investieren und die Grenzen von KI-Systemen transparent zu machen. In Zukunft muss sich die KI-Gemeinschaft auf die Entwicklung neuer Architekturen und Trainingsmethoden konzentrieren, die die Lücke zwischen Mustererkennung und echtem algorithmischen Denken schließen können. Diese Studie ist eine wichtige Erinnerung daran, dass LLMs zwar bemerkenswerte Fortschritte gemacht haben, das Erreichen menschenähnlicher Denkfähigkeiten aber eine ständige Herausforderung in der KI-Forschung und -Entwicklung bleibt.


