
10 bewährte Strategien zur Senkung Ihrer LLM-Kosten



Da sich Unternehmen zunehmend auf große Sprachmodelle (LLMs) für verschiedene Anwendungen verlassen, von Chatbots für den Kundenservice bis hin zur Inhaltserstellung, ist die Herausforderung des LLM-Kostenmanagements in den Vordergrund gerückt. Die Betriebskosten, die mit dem Einsatz und der Wartung von LLMs verbunden sind, können ohne angemessene Aufsicht und Optimierungsstrategien schnell außer Kontrolle geraten. Unerwartete Kostenspitzen können Budgets entgleisen lassen und die breite Einführung dieser leistungsstarken Tools behindern.
Dieser Blog-Beitrag befasst sich mit zehn bewährten Strategien, die Ihrem Unternehmen helfen, die LLM-Kosten effektiv zu verwalten, und die sicherstellen, dass Sie das volle Potenzial dieser Modelle nutzen und gleichzeitig die Kosteneffizienz und die Kontrolle über die Ausgaben behalten können.
Strategie 1: Intelligente Modellauswahl
Eine der wirkungsvollsten Strategien für das LLM-Kostenmanagement ist die Auswahl des richtigen Modells für jede Aufgabe. Nicht jede Anwendung erfordert die modernsten und größten verfügbaren Modelle. Indem Sie die Komplexität des Modells an die Anforderungen der Aufgabe anpassen, können Sie die Kosten erheblich senken, ohne die Leistung zu beeinträchtigen.
Bei der Implementierung von LLM-Anwendungen ist es von entscheidender Bedeutung, die Komplexität der einzelnen Aufgaben zu bewerten und ein Modell zu wählen, das diese spezifischen Anforderungen erfüllt. Beispielsweise erfordern einfache Klassifizierungsaufgaben oder die Beantwortung grundlegender Fragen möglicherweise nicht die vollen Fähigkeiten von GPT-4o oder anderen großen, ressourcenintensiven Modellen.
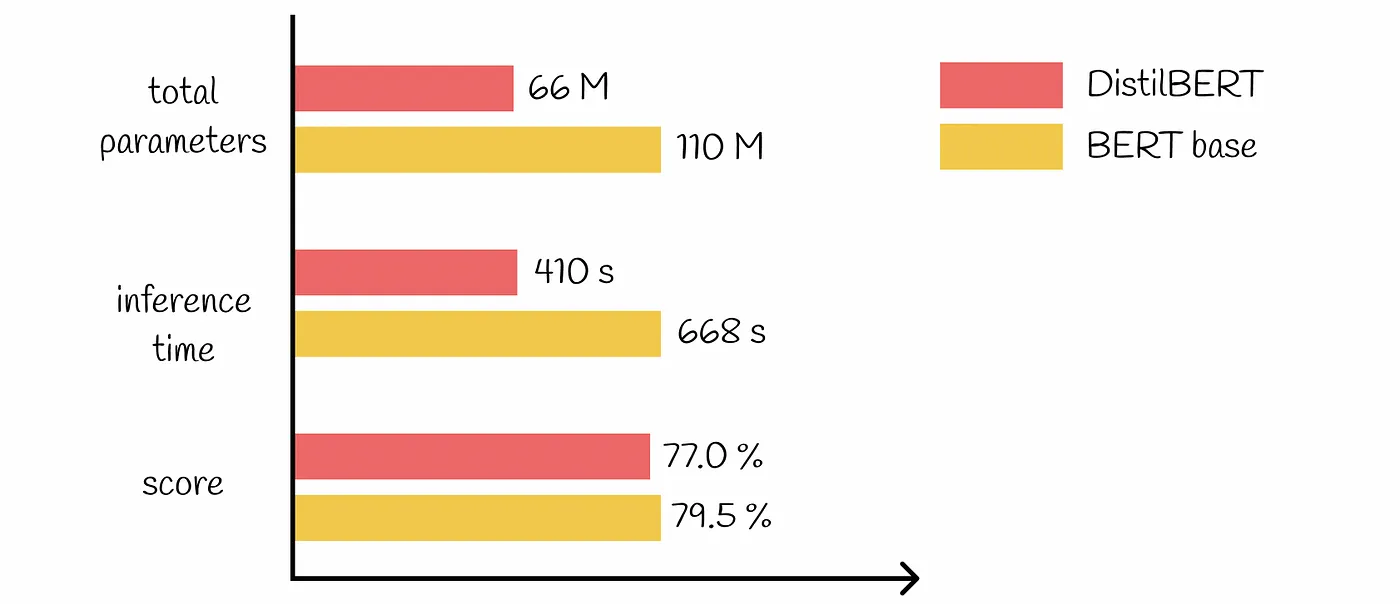
Es gibt viele vortrainierte Modelle in verschiedenen Größen und Komplexitäten. Die Entscheidung für kleinere, effizientere Modelle für einfache Aufgaben kann zu erheblichen Kosteneinsparungen führen. Sie könnten zum Beispiel ein leichtes Modell verwenden wie DistilBERT für die Stimmungsanalyse anstelle eines komplexeren Modells wie BERT-Groß.
Strategie 2: Einführung einer zuverlässigen Verfolgung der Nutzung
Ein effektives LLM-Kostenmanagement beginnt mit einem klaren Verständnis darüber, wie diese Modelle in Ihrem Unternehmen genutzt werden. Die Implementierung robuster Mechanismen zur Verfolgung der Nutzung ist entscheidend für die Identifizierung ineffizienter Bereiche und von Optimierungsmöglichkeiten.
Um einen umfassenden Überblick über Ihre LLM-Nutzungist es wichtig, Kennzahlen auf mehreren Ebenen zu verfolgen:
Konversationsniveau: Überwachen Sie die Token-Nutzung, Antwortzeiten und Modellaufrufe für einzelne Interaktionen.
Benutzerebene: Analysieren Sie Muster in der Modellnutzung zwischen verschiedenen Benutzern oder Abteilungen.
Ebene des Unternehmens: Aggregieren Sie Daten, um den gesamten LLM-Verbrauch und Trends zu verstehen.
Es gibt verschiedene Tools und Plattformen, die dabei helfen, die Nutzung von LLM effektiv zu verfolgen. Diese können umfassen:
Integrierte analytische Dashboards, die von LLM-Dienstleistern bereitgestellt werden
Überwachungstools von Drittanbietern, die speziell für KI- und ML-Anwendungen entwickelt wurden
Maßgeschneiderte Tracking-Lösungen, die in Ihre bestehende Infrastruktur integriert sind
Durch die Analyse von Nutzungsdaten können Sie wertvolle Erkenntnisse gewinnen, die zu Strategien zur Kostensenkung führen. So könnten Sie beispielsweise feststellen, dass bestimmte Abteilungen zu viele teure Modelle für Aufgaben verwenden, die von kostengünstigeren Alternativen erledigt werden könnten. Oder Sie erkennen Muster redundanter Abfragen, die durch Caching oder andere Optimierungstechniken behoben werden könnten.
Strategie 3: Optimierung des Prompt Engineering
Schnelles Engineering ist ein kritischer Aspekt bei der Arbeit mit LLMs und kann erhebliche Auswirkungen auf Leistung und Kosten haben. Durch die Optimierung Ihrer Prompts können Sie die Verwendung von Token reduzieren und die Effizienz Ihrer LLM-Anwendungen verbessern.
Minimierung der Anzahl der API-Aufrufe und Reduzierung der damit verbundenen Kosten:
Verwenden Sie klare und spezifische Anweisungen in Ihren Aufforderungen
Implementierung einer Fehlerbehandlung zur Behebung allgemeiner Probleme, ohne dass zusätzliche LLM-Abfragen erforderlich sind
Verwendung von Prompt-Vorlagen, die sich für bestimmte Aufgaben bewährt haben
Die Art und Weise, wie Sie Ihre Prompts strukturieren, kann die Anzahl der vom Modell verarbeiteten Token erheblich beeinflussen. Einige bewährte Verfahren sind:
Prägnant sein und unnötigen Kontext vermeiden
Verwendung von Formatierungstechniken wie Aufzählungspunkten oder nummerierten Listen, um Informationen effizient zu organisieren
Nutzung integrierter Funktionen oder vom LLM-Dienst bereitgestellter Parameter zur Steuerung von Länge und Format der Ausgabe
Durch die Implementierung dieser prompten Optimierungstechniken können Sie die Verwendung von Token und folglich die mit Ihren LLM-Anwendungen verbundenen Kosten erheblich reduzieren.
Strategie 4: Nutzen Sie die Feinabstimmung für die Spezialisierung
Die Feinabstimmung von vortrainierten Modellen für bestimmte Aufgaben ist eine leistungsstarke Technik im LLM-Kostenmanagement. Durch die Anpassung der Modelle an Ihre individuellen Bedürfnisse können Sie eine bessere Leistung mit kleineren, effizienteren Modellen erzielen, was zu erheblichen Kosteneinsparungen führt.
Anstatt sich ausschließlich auf große, universell einsetzbare LLMs zu verlassen, sollten Sie eine Feinabstimmung kleinerer Modelle für spezielle Aufgaben in Betracht ziehen. Dieser Ansatz ermöglicht es Ihnen, das Wissen von vortrainierten Modellen zu nutzen und gleichzeitig für Ihren speziellen Anwendungsfall zu optimieren.
Die Feinabstimmung erfordert zwar eine Anfangsinvestition, kann aber langfristig zu erheblichen Einsparungen führen. Feinabgestimmte Modelle benötigen oft weniger Token, um die gleichen oder bessere Ergebnisse zu erzielen, was die Ableitungskosten senkt. Aufgrund der verbesserten Genauigkeit sind möglicherweise auch weniger Wiederholungen oder Korrekturen erforderlich, was die Kosten weiter senkt. Außerdem können spezialisierte Modelle oft kleiner sein, was den Rechenaufwand und die damit verbundenen Kosten reduziert.
Um die Vorteile der Feinabstimmung zu maximieren, sollten Sie mit einem kleineren, vortrainierten Modell als Basis beginnen. Verwenden Sie für die Feinabstimmung hochwertige, domänenspezifische Daten, und bewerten Sie regelmäßig die Leistung und Kosteneffizienz des Modells. Dieser fortlaufende Optimierungsprozess stellt sicher, dass Ihre fein abgestimmten Modelle auch weiterhin einen Mehrwert bieten und gleichzeitig die Kosten unter Kontrolle halten.
Strategie 5: Erkundung kostenloser und kostengünstiger Optionen
Für viele Unternehmen, insbesondere in der Entwicklungs- und Testphase, ist die Nutzung von kostenlose oder kostengünstige LLM-Optionen können die Kosten erheblich senken, ohne dass die Qualität darunter leidet. Diese Optionen sind besonders wertvoll für das Prototyping neuer LLM-Anwendungen, die Schulung von Entwicklern zur LLM-Implementierung und die Ausführung nicht kritischer oder interner Dienste.
Kostenlose Optionen können zwar die Kosten drastisch senken, aber es ist wichtig, die Nachteile zu bedenken. Die Auswirkungen auf den Datenschutz und die Sicherheit sollten sorgfältig geprüft werden, insbesondere wenn es um sensible Informationen geht. Achten Sie außerdem auf mögliche Einschränkungen bei den Modellfunktionen oder Anpassungsoptionen. Berücksichtigen Sie langfristige Skalierbarkeit und Migrationspfade, um sicherzustellen, dass Ihre kostensparenden Maßnahmen nicht zu einem Hindernis für zukünftiges Wachstum werden.
Strategie 6: Optimierung der Kontextfensterverwaltung
Die Größe des Kontextfensters in LLMs kann sowohl die Leistung als auch die Kosten erheblich beeinflussen. Eine wirksame Verwaltung von Kontextfenstern ist entscheidend für die Kontrolle der Ausgaben bei gleichzeitiger Aufrechterhaltung der Ausgabequalität. Größere Kontextfenster ermöglichen ein umfassenderes Verständnis, sind jedoch mit höheren Kosten verbunden, da pro Abfrage mehr Token verwendet werden und der Rechenaufwand höher ist.
Um die Nutzung von Kontextfenstern zu optimieren, sollten Sie die Implementierung einer dynamischen Kontextgröße auf der Grundlage der Aufgabenkomplexität in Betracht ziehen. Nutzen Sie Zusammenfassungsmethoden, um relevante Informationen zu verdichten, und verwenden Sie gleitende Fensteransätze für lange Dokumente oder Konversationen. Diese Methoden können Ihnen helfen, den goldenen Mittelweg zwischen Verständlichkeit und Kosteneffizienz zu finden.
Analysieren Sie regelmäßig das Verhältnis zwischen Kontextgröße und Ausgabequalität, um Ihren Ansatz zu optimieren. Passen Sie die Kontextfenster auf der Grundlage der spezifischen Aufgabenanforderungen an und erwägen Sie die Implementierung eines abgestuften Ansatzes, bei dem größere Kontexte nur bei Bedarf verwendet werden. Durch eine sorgfältige Verwaltung Ihrer Kontextfenster können Sie die Verwendung von Token und die damit verbundenen Kosten erheblich reduzieren, ohne die Qualität Ihrer LLM-Ausgaben zu beeinträchtigen.
Strategie 7: Einführung von Multi-Agenten-Systemen
Multi-Agenten-Systeme bieten einen leistungsfähigen Ansatz zur Verbesserung der Effizienz und Kostenwirksamkeit von LLM-Anwendungen. Durch die Verteilung von Aufgaben auf spezialisierte Agenten können Unternehmen die Ressourcenzuweisung optimieren und die Gesamtkosten für das LLM senken.
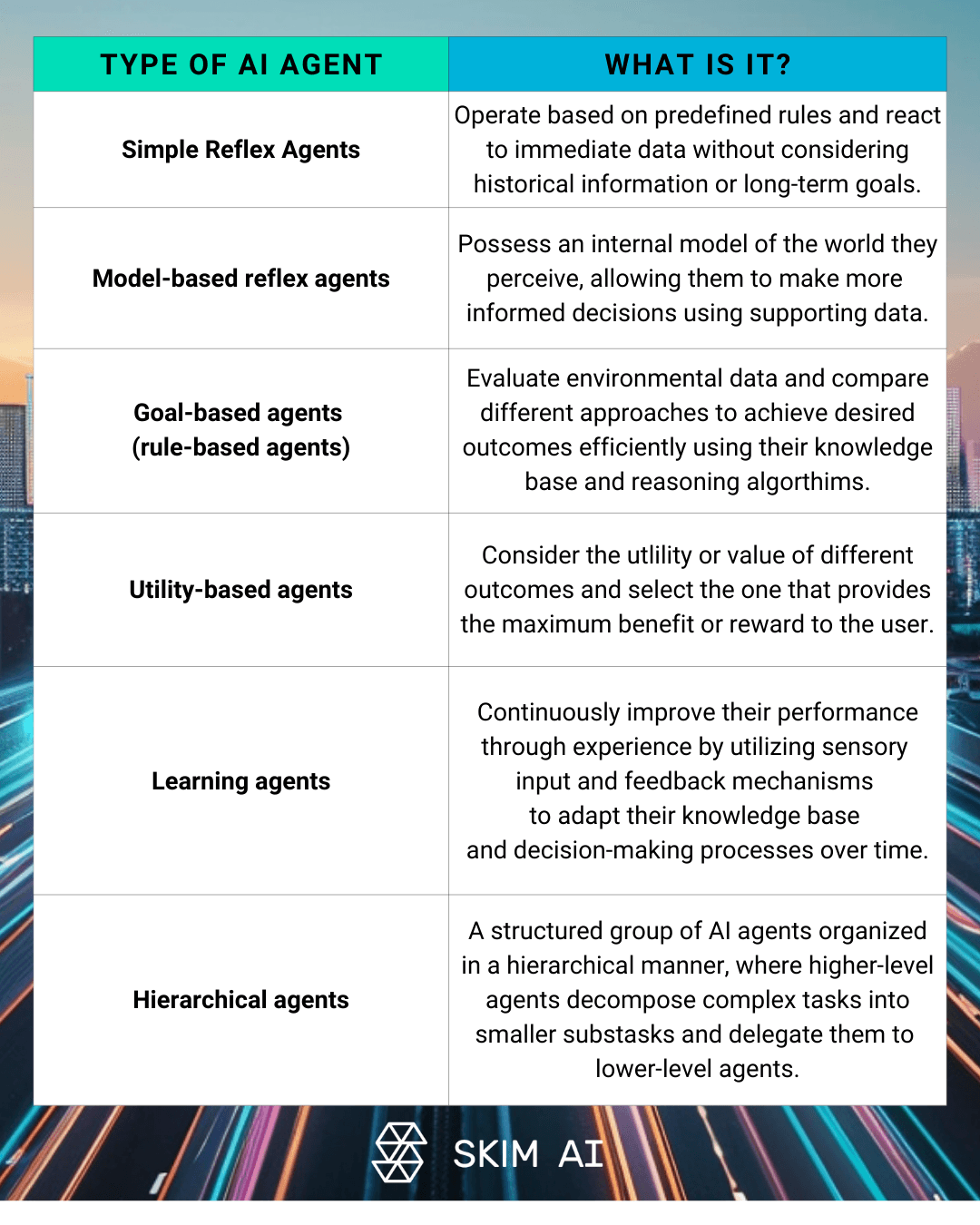
Multi-Agenten-LLM-Architekturen umfassen mehrere KI-Agenten gemeinsam an der Lösung komplexer Probleme arbeiten. Dieser Ansatz kann spezialisierte Agenten für verschiedene Aspekte einer Aufgabe, hierarchische Strukturen mit Aufsichts- und Arbeitsagenten oder kollaborative Problemlösungen zwischen mehreren LLMs umfassen. Durch die Implementierung solcher Systeme können Unternehmen ihre Abhängigkeit von teuren, groß angelegten Modellen für jede Aufgabe verringern.
Die Kostenvorteile einer verteilten Aufgabenbearbeitung sind erheblich. Multi-Agenten-Systeme ermöglichen:
Optimierte Ressourcenzuweisung auf der Grundlage der Aufgabenkomplexität
Verbesserte Gesamtsystemeffizienz und Reaktionszeiten
Geringerer Token-Verbrauch durch gezielten Modell-Einsatz
Um die Kosteneffizienz in Multi-Agenten-Systemen aufrechtzuerhalten, ist es jedoch entscheidend, robuste Debugging-Mechanismen zu implementieren. Dazu gehören die Protokollierung und Überwachung der Kommunikation zwischen den Agenten, die Analyse von Token-Nutzungsmustern zur Ermittlung redundanter Austauschvorgänge und die Optimierung der Arbeitsteilung zwischen den Agenten zur Minimierung des unnötigen Token-Verbrauchs.
Strategie 8: Verwendung von Ausgabeformatierungswerkzeugen
Die korrekte Formatierung der Ausgabe ist ein Schlüsselfaktor für das LLM-Kostenmanagement. Indem sie die effiziente Nutzung von Token sicherstellen und den Bedarf an zusätzlicher Verarbeitung minimieren, können Unternehmen ihre Betriebskosten erheblich senken.
Diese Tools bieten leistungsstarke Funktionen für erzwungene Funktionsausgaben, mit denen Entwickler genaue Formate für LLM-Antworten festlegen können. Dieser Ansatz reduziert die Variabilität in den Ausgaben und minimiert die Token-Verschwendung, indem sichergestellt wird, dass das Modell nur die notwendigen Informationen generiert.
Die Verringerung der Variabilität der LLM-Ausgaben wirkt sich unmittelbar auf die damit verbundenen Kosten aus. Konsistente, gut strukturierte Antworten verringern die Wahrscheinlichkeit fehlerhafter oder unbrauchbarer Ausgaben, was wiederum den Bedarf an zusätzlichen API-Aufrufen zur Klärung oder Neuformatierung von Informationen reduziert.
Die Implementierung von JSON-Ausgaben kann für die Effizienz besonders effektiv sein. JSON bietet eine kompakte Darstellung strukturierter Daten, eine einfache Analyse und Integration in verschiedene Systeme sowie eine geringere Verwendung von Token im Vergleich zu natürlichsprachlichen Antworten. Durch den Einsatz dieser Ausgabeformatierungstools können Unternehmen ihre LLM-Workflows rationalisieren und die Verwendung von Token optimieren.
Strategie 9: Integration von Nicht-LLM-Tools
LLMs sind zwar leistungsstark, aber nicht immer die kostengünstigste Lösung für jede Aufgabe. Die Integration von NichtLLM-Werkzeuge in Ihre Arbeitsabläufe zu integrieren, kann die Betriebskosten erheblich senken und gleichzeitig eine hohe Qualität der Ergebnisse gewährleisten.
Die Einbindung von Python-Skripten zur Bewältigung bestimmter Aufgaben, die nicht die vollen Fähigkeiten eines LLM erfordern, kann zu erheblichen Kosteneinsparungen führen. So können beispielsweise einfache Datenverarbeitung oder regelbasierte Entscheidungsfindung mit herkömmlichen Programmieransätzen oft effizienter gehandhabt werden.
Bei der Abwägung zwischen LLM und herkömmlichen Werkzeugen in Arbeitsabläufen sind die Komplexität der Aufgabe, die erforderliche Genauigkeit und die möglichen Kosteneinsparungen zu berücksichtigen. Ein hybrider Ansatz, der die Stärken sowohl von LLMs als auch von herkömmlichen Werkzeugen nutzt, führt oft zu den besten Ergebnissen in Bezug auf Leistung und Kosteneffizienz.
Die Durchführung einer gründlichen Kosten-Nutzen-Analyse für hybride Ansätze ist von entscheidender Bedeutung. Bei dieser Analyse sollten Faktoren wie die folgenden berücksichtigt werden:
Entwicklungs- und Wartungskosten für benutzerdefinierte Tools
Bearbeitungszeit und Ressourcenbedarf
Genauigkeit und Zuverlässigkeit der Ergebnisse
Langfristige Skalierbarkeit und Flexibilität
Strategie 10: Regelmäßige Prüfung und Optimierung
Die Einführung von LLM-Kostenmanagementtechniken ist ein fortlaufender Prozess, der ständige Wachsamkeit und Optimierung erfordert. Die regelmäßige Überprüfung Ihrer LLM-Nutzung und -Kosten ist entscheidend für die Ermittlung von Ineffizienzen und die Umsetzung von Verbesserungen zur Kostenkontrolle.
Die Bedeutung des laufenden Kostenmanagements und der Kostensenkung kann nicht hoch genug eingeschätzt werden. Mit der Weiterentwicklung und Skalierung Ihrer LLM-Anwendungen werden neue Herausforderungen und Optimierungsmöglichkeiten auftauchen. Durch die konsequente Überwachung und Analyse Ihrer LLM-Nutzung können Sie potenziellen Kostenüberschreitungen zuvorkommen und sicherstellen, dass Ihre KI-Investitionen maximalen Nutzen bringen.
Um verschwendete Token zu identifizieren, sollten Sie robuste Verfolgungs- und Analysetools einsetzen. Suchen Sie nach Mustern für redundante Abfragen, übermäßige Kontextfenster oder ineffiziente Eingabeaufforderungen. Nutzen Sie diese Daten, um Ihre LLM-Strategien zu verfeinern und unnötigen Token-Verbrauch zu vermeiden.
Schließlich ist die Förderung einer Kultur des Kostenbewusstseins innerhalb Ihrer Organisation der Schlüssel zum langfristigen Erfolg einer effizienten LLM-Ressourcenverwaltung. Ermutigen Sie die Teams, die Kostenauswirkungen ihrer LLM-Nutzung zu berücksichtigen und aktiv nach Möglichkeiten zur Optimierung und Ausgabenkontrolle zu suchen. Indem Sie Kosteneffizienz zu einer gemeinsamen Verantwortung machen, können Sie sicherstellen, dass Ihr Unternehmen die Vorteile der LLM-Technologie voll ausschöpft und gleichzeitig die Kosten unter Kontrolle hält.
Die Quintessenz
Da sich große Sprachmodelle weiterhin auf KI-Anwendungen in Unternehmen auswirken, ist die Beherrschung des LLM-Kostenmanagements entscheidend für den langfristigen Erfolg. Durch die Umsetzung der zehn in diesem Artikel beschriebenen Strategien - von der intelligenten Modellauswahl bis hin zur regelmäßigen Prüfung und Optimierung - kann Ihr Unternehmen die Kosten für Sprachmodelle erheblich senken und gleichzeitig die Leistung beibehalten oder sogar verbessern. Denken Sie daran, dass ein effektives Kostenmanagement ein fortlaufender Prozess ist, der eine kontinuierliche Überwachung, Analyse und Anpassung erfordert. Durch die Förderung einer Kultur des Kostenbewusstseins und den Einsatz der richtigen Tools und Techniken können Sie das volle Potenzial von LLMs nutzen und gleichzeitig die Betriebskosten unter Kontrolle halten, um sicherzustellen, dass Ihre KI-Investitionen Ihrem Unternehmen maximalen Nutzen bringen.
Zögern Sie nicht, sich mit uns in Verbindung zu setzen, um mehr über LLM-Kostenmanagement zu erfahren.


