
10 bewährte Strategien zur Senkung Ihrer LLM-Kosten - AI&YOU #65



Statistik der Woche: Die Verwendung kleinerer LLMs wie GPT-J in einer Kaskade kann die Gesamtkosten um 80% senken und gleichzeitig die Genauigkeit um 1,5% im Vergleich zu GPT-4 verbessern. (Dataiku)
Da sich Unternehmen zunehmend auf große Sprachmodelle (LLMs) für verschiedene Anwendungen verlassen, können die Betriebskosten, die mit der Bereitstellung und Wartung dieser Modelle verbunden sind, ohne angemessene Aufsicht und Optimierungsstrategien schnell außer Kontrolle geraten.
Meta hat auch Llama 3.1 herausgebracht, das in letzter Zeit als das fortschrittlichste Open-Source-LLM gilt, das es gibt.
In dieser Ausgabe von AI&YOU befassen wir uns mit den Erkenntnissen aus drei Blogs, die wir zu diesen Themen veröffentlicht haben:
10 bewährte Strategien zur Senkung Ihrer LLM-Kosten - AI&YOU #65
Dieser Blog-Beitrag befasst sich mit zehn bewährten Strategien, die Ihrem Unternehmen helfen, die LLM-Kosten effektiv zu verwalten, und die sicherstellen, dass Sie das volle Potenzial dieser Modelle nutzen und gleichzeitig die Kosteneffizienz und die Kontrolle über die Ausgaben behalten können.
1. Intelligente Modellauswahl
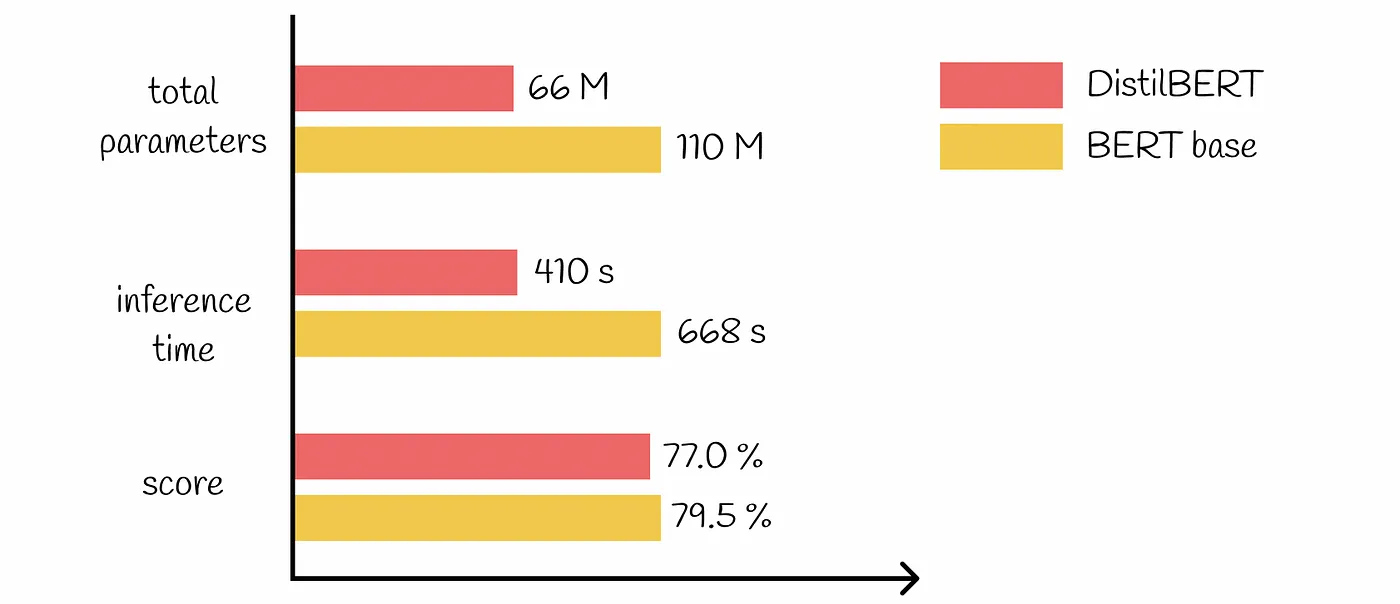
Optimieren Sie Ihre LLM-Kosten durch sorgfältige Anpassung der Modellkomplexität an die Aufgabenanforderungen. Nicht jede Anwendung benötigt das neueste und größte Modell. Für einfachere Aufgaben wie grundlegende Klassifizierung oder unkomplizierte Fragen und Antworten sollten Sie kleinere, effizientere, vorab trainierte Modelle verwenden. Dieser Ansatz kann zu erheblichen Einsparungen führen, ohne die Leistung zu beeinträchtigen.
So kann beispielsweise der Einsatz von DistilBERT für die Stimmungsanalyse anstelle von BERT-Large den Rechenaufwand und die damit verbundenen Kosten erheblich reduzieren und gleichzeitig eine hohe Genauigkeit für die jeweilige Aufgabe gewährleisten.
2. Robuste Verfolgung der Nutzung implementieren
Verschaffen Sie sich einen umfassenden Überblick über Ihre LLM-Nutzung durch die Implementierung mehrstufiger Verfolgungsmechanismen. Überwachen Sie Token-Nutzung, Antwortzeiten und Modellaufrufe auf Gesprächs-, Benutzer- und Unternehmensebene. Nutzen Sie die integrierten Analyse-Dashboards von LLM-Anbietern oder implementieren Sie benutzerdefinierte Tracking-Lösungen, die in Ihre Infrastruktur integriert sind.
Anhand dieses detaillierten Einblicks können Sie Ineffizienzen erkennen, z. B. Abteilungen, die für einfache Aufgaben zu teure Modelle verwenden, oder Muster von redundanten Abfragen. Durch die Analyse dieser Daten können Sie wertvolle Strategien zur Kostenreduzierung aufdecken und Ihren LLM-Verbrauch insgesamt optimieren.
3. Prompt Engineering optimieren
Verfeinern Sie Ihre Prompt-Engineering-Techniken, um die Verwendung von Token deutlich zu reduzieren und die LLM-Effizienz zu verbessern. Verfassen Sie klare, prägnante Anweisungen in Ihren Prompts, implementieren Sie eine Fehlerbehandlung, um häufige Probleme ohne zusätzliche Abfragen zu lösen, und verwenden Sie bewährte Prompt-Vorlagen für bestimmte Aufgaben. Strukturieren Sie Ihre Prompts effizient, indem Sie unnötigen Kontext vermeiden, Formatierungstechniken wie Aufzählungspunkte verwenden und integrierte Funktionen zur Steuerung der Ausgabelänge nutzen.
Diese Optimierungen können den Token-Verbrauch und die damit verbundenen Kosten erheblich reduzieren, während die Qualität Ihrer LLM-Ausgaben beibehalten oder sogar verbessert wird.
4. Nutzen Sie die Feinabstimmung für die Spezialisierung
Nutzen Sie die Kraft der Feinabstimmung, um kleinere, effizientere Modelle zu schaffen, die auf Ihre speziellen Bedürfnisse zugeschnitten sind. Dieser Ansatz erfordert zwar eine Anfangsinvestition, kann aber langfristig zu erheblichen Einsparungen führen. Feinabgestimmte Modelle benötigen oft weniger Token, um gleiche oder bessere Ergebnisse zu erzielen, was die Kosten für Schlussfolgerungen und die Notwendigkeit von Wiederholungen oder Korrekturen reduziert.
Beginnen Sie mit einem kleineren vortrainierten Modell, verwenden Sie hochwertige domänenspezifische Daten für die Feinabstimmung und bewerten Sie regelmäßig Leistung und Kosteneffizienz. Durch diese fortlaufende Optimierung wird sichergestellt, dass Ihre Modelle weiterhin einen Mehrwert liefern und gleichzeitig die Betriebskosten unter Kontrolle halten.
5. Erkunden Sie kostenlose und kostengünstige Optionen
Nutzen Sie kostenlose oder kostengünstige LLM-Optionen, insbesondere während der Entwicklungs- und Testphasen, um die Kosten ohne Qualitätseinbußen erheblich zu senken. Diese Alternativen sind besonders wertvoll für Prototypen, Entwicklerschulungen und unkritische oder interne Dienste.
Wägen Sie jedoch sorgfältig die Nachteile ab und berücksichtigen Sie dabei den Datenschutz, die Auswirkungen auf die Sicherheit und mögliche Einschränkungen bei den Funktionen oder der Anpassung. Beurteilen Sie die langfristige Skalierbarkeit und Migrationspfade, um sicherzustellen, dass Ihre kostensparenden Maßnahmen mit zukünftigen Wachstumsplänen übereinstimmen und nicht zu einem Hindernis werden.
6. Optimieren der Kontextfensterverwaltung
Effektive Verwaltung von Kontextfenstern zur Kostenkontrolle bei gleichbleibender Ausgabequalität. Implementieren Sie eine dynamische Größenanpassung des Kontexts auf der Grundlage der Aufgabenkomplexität, verwenden Sie Zusammenfassungsmethoden, um relevante Informationen zu verdichten, und setzen Sie gleitende Fenster für lange Dokumente oder Konversationen ein. Regelmäßige Analyse des Verhältnisses zwischen Kontextgröße und Ausgabequalität und Anpassung der Fenster an die jeweiligen Aufgabenanforderungen.
Ziehen Sie einen abgestuften Ansatz in Betracht, bei dem größere Kontexte nur bei Bedarf verwendet werden. Diese strategische Verwaltung von Kontextfenstern kann die Verwendung von Token und die damit verbundenen Kosten erheblich reduzieren, ohne die Verständnisfähigkeiten Ihrer LLM-Anwendungen zu beeinträchtigen.
7. Implementierung von Multi-Agenten-Systemen
Verbesserung der Effizienz und Kostenwirksamkeit durch die Implementierung von Multi-Agenten-LLM-Architekturen. Bei diesem Ansatz arbeiten mehrere KI-Agenten zusammen, um komplexe Probleme zu lösen. Dies ermöglicht eine optimierte Ressourcenzuweisung und eine geringere Abhängigkeit von teuren, groß angelegten Modellen.
Multi-Agenten-Systeme ermöglichen eine gezielte Modellbereitstellung und verbessern die Gesamtsystemeffizienz und die Reaktionszeiten bei gleichzeitiger Reduzierung der Token-Nutzung. Um die Kosteneffizienz aufrechtzuerhalten, sollten Sie robuste Debugging-Mechanismen implementieren, einschließlich der Protokollierung der Kommunikation zwischen den Agenten und der Analyse der Token-Nutzungsmuster.
Durch die Optimierung der Arbeitsteilung zwischen den Agenten können Sie den unnötigen Tokenverbrauch minimieren und die Vorteile der verteilten Aufgabenbearbeitung maximieren.
8. Verwendung von Ausgabeformatierungswerkzeugen
Nutzen Sie Tools zur Ausgabeformatierung, um eine effiziente Verwendung von Token zu gewährleisten und den zusätzlichen Verarbeitungsbedarf zu minimieren. Implementieren Sie erzwungene Funktionsausgaben, um exakte Antwortformate festzulegen und so die Variabilität und Token-Verschwendung zu reduzieren. Dieser Ansatz verringert die Wahrscheinlichkeit von fehlerhaften Ausgaben und die Notwendigkeit von API-Aufrufen zur Klärung.
Erwägen Sie die Verwendung von JSON-Ausgaben aufgrund ihrer kompakten Darstellung strukturierter Daten, der einfachen Analyse und der geringeren Verwendung von Token im Vergleich zu Antworten in natürlicher Sprache. Durch die Rationalisierung Ihrer LLM-Workflows mit diesen Formatierungswerkzeugen können Sie die Verwendung von Token erheblich optimieren und die Betriebskosten senken, während Sie gleichzeitig qualitativ hochwertige Ausgaben erhalten.
9. Integration von Nicht-LLM-Tools
Ergänzen Sie Ihre LLM-Anwendungen mit Nicht-LLM-Tools, um Kosten und Effizienz zu optimieren. Integrieren Sie Python-Skripte oder herkömmliche Programmieransätze für Aufgaben, die nicht die vollen Fähigkeiten eines LLM erfordern, wie einfache Datenverarbeitung oder regelbasierte Entscheidungsfindung.
Wägen Sie bei der Gestaltung von Arbeitsabläufen LLM und herkömmliche Werkzeuge sorgfältig ab, basierend auf der Komplexität der Aufgabe, der erforderlichen Genauigkeit und den möglichen Kosteneinsparungen. Führen Sie gründliche Kosten-Nutzen-Analysen durch, die Faktoren wie Entwicklungskosten, Verarbeitungszeit, Genauigkeit und langfristige Skalierbarkeit berücksichtigen. Dieser hybride Ansatz führt oft zu den besten Ergebnissen in Bezug auf Leistung und Kosteneffizienz.
10. Regelmäßige Prüfung und Optimierung
Implementieren Sie ein robustes System zur regelmäßigen Überprüfung und Optimierung, um ein kontinuierliches LLM-Kostenmanagement zu gewährleisten. Überwachen und analysieren Sie konsequent Ihre LLM-Nutzung, um Ineffizienzen zu erkennen, wie z. B. redundante Abfragen oder übermäßige Kontextfenster. Verwenden Sie Tracking- und Analysetools, um Ihre LLM-Strategien zu verfeinern und unnötigen Token-Verbrauch zu vermeiden.
Fördern Sie eine Kultur des Kostenbewusstseins in Ihrem Unternehmen und ermutigen Sie die Teams, die Kostenauswirkungen ihrer LLM-Nutzung aktiv zu berücksichtigen und nach Optimierungsmöglichkeiten zu suchen. Indem Sie Kosteneffizienz zu einer gemeinsamen Verantwortung machen, können Sie den Wert Ihrer KI-Investitionen maximieren und gleichzeitig die Ausgaben langfristig unter Kontrolle halten.
Verständnis der LLM-Preisstrukturen: Inputs, Outputs und Kontextfenster
Für KI-Strategien von Unternehmen ist das Verständnis der Preisstrukturen für LLMs entscheidend für ein effektives Kostenmanagement. Die mit LLMs verbundenen Betriebskosten können ohne angemessene Aufsicht schnell eskalieren, was zu unerwarteten Kostenspitzen führen kann, die Budgets entgleisen lassen und eine breite Akzeptanz verhindern können.
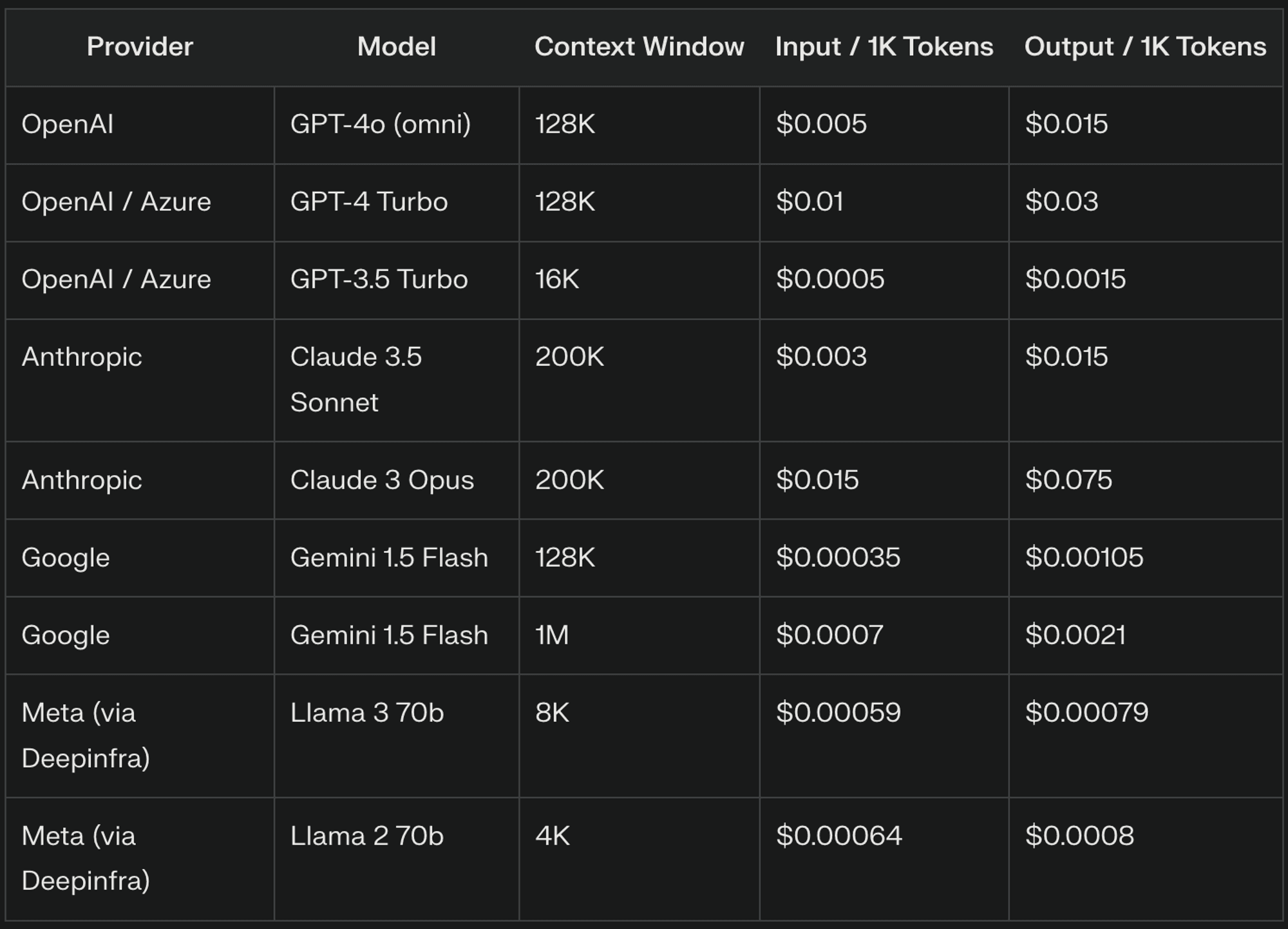
Die Preise für LLM-Studiengänge setzen sich in der Regel aus drei Hauptkomponenten zusammen: Eingabe-Token, Ausgabe-Token und Kontextfenster. Jedes dieser Elemente spielt eine wichtige Rolle bei der Bestimmung der Gesamtkosten für die Nutzung von LLMs in Ihren Anwendungen
Eingabemarken: Was sie sind und wie sie aufgeladen werden
Eingabe-Token sind die grundlegenden Texteinheiten, die von LLMs verarbeitet werden und in der Regel Teilen von Wörtern entsprechen. Zum Beispiel könnte "The quick brown fox" als ["The", "quick", "bro", "wn", "fox"] tokenisiert werden, was zu 5 Input-Token führt. LLM-Anbieter berechnen die Eingabe von Token in der Regel auf der Grundlage eines Tausender-Token-Satzes, wobei die Preise je nach Anbieter und Modellversion erheblich variieren.
Um die Verwendung von Eingabe-Token zu optimieren und die Kosten zu senken, sollten Sie diese Strategien in Betracht ziehen:
Verfassen Sie prägnante Aufforderungen: Konzentrieren Sie sich auf klare, direkte Anweisungen.
Verwenden Sie eine effiziente Kodierung: Wählen Sie Methoden, die Text mit weniger Token darstellen.
Implementieren Sie Prompt-Vorlagen: Entwickeln Sie optimierte Strukturen für allgemeine Aufgaben.
Nutzung von Komprimierungstechniken: Reduzieren Sie die Eingabegröße, ohne wichtige Informationen zu verlieren.
Output-Token: Die Kosten verstehen
Ausgabe-Token stellen den Text dar, der vom LLM als Antwort auf Ihre Eingabe generiert wird. Die Anzahl der Output-Token kann je nach Aufgabe und Modellkonfiguration erheblich variieren. LLM-Anbieter verlangen für Output-Token oft einen höheren Preis als für Input-Token, da die Texterzeugung sehr rechenintensiv ist.
Optimierung der Nutzung von Output-Token und Kostenkontrolle:
Legen Sie in Ihren Prompts oder API-Aufrufen eindeutige Grenzen für die Ausgabelänge fest.
Nutzen Sie das "few-shot learning", um das Modell zu prägnanten Antworten zu führen.
Implementieren Sie eine Nachbearbeitung, um unnötige Inhalte zu kürzen.
Erwägen Sie die Zwischenspeicherung häufig angeforderter Informationen.
Nutzen Sie die Werkzeuge zur Formatierung der Ausgabe, um eine effiziente Verwendung der Token zu gewährleisten.
Kontext-Fenster: Der verborgene Kostentreiber
Kontextfenster bestimmen, wie viel früheren Text der LLM bei der Erstellung einer Antwort berücksichtigt, was für die Aufrechterhaltung der Kohärenz und die Bezugnahme auf frühere Informationen entscheidend ist. Größere Kontextfenster erhöhen die Anzahl der verarbeiteten Eingabe-Token, was zu höheren Kosten führt. Ein Kontextfenster mit 8.000 Token könnte zum Beispiel 7.000 Token in einer Konversation berechnen, während ein Fenster mit 4.000 Token nur 3.000 Token berechnen könnte.
Um die Nutzung des Kontextfensters zu optimieren:
Implementierung einer dynamischen Kontextgrößenanpassung auf der Grundlage der Aufgabenanforderungen.
Nutzen Sie Techniken der Zusammenfassung, um relevante Informationen zu verdichten.
Verwendung von Sliding-Window-Ansätzen für lange Dokumente.
Ziehen Sie kleinere, spezialisierte Modelle für Aufgaben mit begrenztem Kontextbedarf in Betracht.
Analysieren Sie regelmäßig das Verhältnis zwischen Kontextgröße und Ausgabequalität.
Durch eine sorgfältige Verwaltung dieser Komponenten der LLM-Preisstrukturen können Unternehmen ihre Betriebskosten senken und gleichzeitig die Qualität ihrer KI-Anwendungen aufrechterhalten.
Die Quintessenz
Das Verständnis der LLM-Preisstrukturen ist für ein effektives Kostenmanagement bei KI-Anwendungen in Unternehmen unerlässlich. Wenn Unternehmen die Feinheiten von Eingabe- und Ausgabe-Token sowie Kontextfenstern verstehen, können sie fundierte Entscheidungen über Modellauswahl und Nutzungsmuster treffen. Die Implementierung strategischer Kostenmanagementtechniken, wie z. B. die Optimierung der Token-Nutzung und die Nutzung von Caching, kann zu erheblichen Einsparungen führen.
Metas Llama 3.1: Die Grenzen der Open-Source-KI verschieben
Kürzlich hat Meta eine große Neuigkeit angekündigt Llama 3.1sein bisher fortschrittlichstes Open-Source-Modell für große Sprachen. Diese Veröffentlichung stellt einen wichtigen Meilenstein in der Demokratisierung der KI-Technologie dar und überbrückt möglicherweise die Kluft zwischen Open-Source- und proprietären Modellen.
Llama 3.1 baut auf seinen Vorgängern auf und bietet mehrere wichtige Verbesserungen:
Erhöhte Modellgröße: Die Einführung des 405B-Parameter-Modells verschiebt die Grenzen dessen, was in der Open-Source-KI möglich ist.
Erweiterte Kontextlänge: Von 4K Token in Llama 2 auf 128K in Llama 3.1, was ein komplexeres und differenzierteres Verständnis von längeren Texten ermöglicht.
Mehrsprachige Fähigkeiten: Die erweiterte Sprachunterstützung ermöglicht eine größere Vielfalt von Anwendungen in verschiedenen Regionen und Anwendungsfällen.
Verbessertes logisches Denken und spezialisierte Aufgaben: Verbesserte Leistung in Bereichen wie mathematische Argumentation und Codegenerierung.
Im Vergleich zu Closed-Source-Modellen wie GPT-4 und Claude 3.5 Sonnet behauptet sich Llama 3.1 405B in verschiedenen Benchmarks. Dieses Leistungsniveau bei einem Open-Source-Modell ist beispiellos.
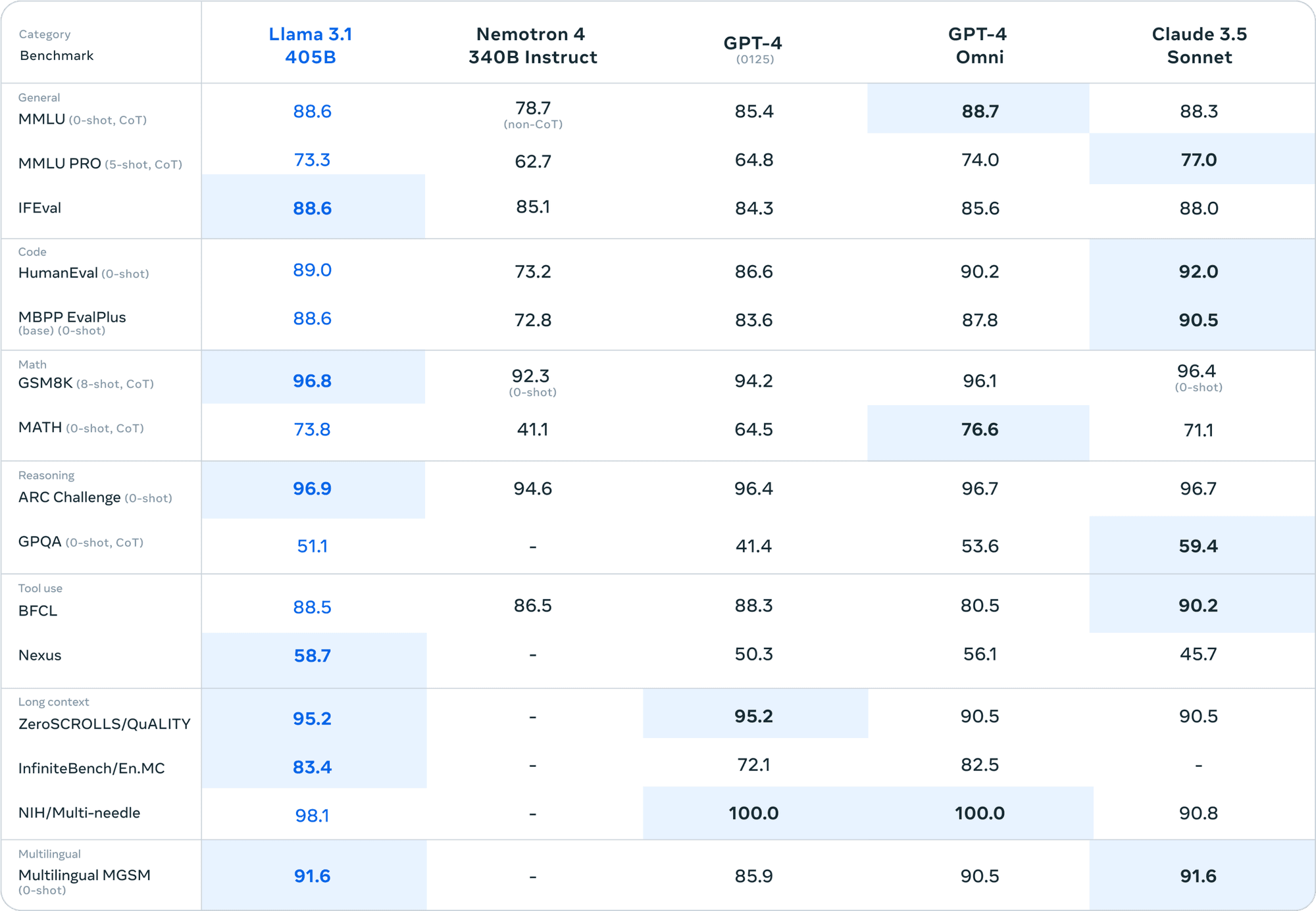
Technische Daten von Llama 3.1
Zu den technischen Details: Llama 3.1 bietet eine Reihe von Modellgrößen, um unterschiedlichen Bedürfnissen und Rechenressourcen gerecht zu werden:
8B-Parameter-Modell: Geeignet für leichte Anwendungen und Edge-Geräte.
70B-Parameter-Modell: Ein ausgewogenes Verhältnis zwischen Leistungs- und Ressourcenanforderungen.
405B-Parameter-Modell: Das Vorzeigemodell, das die Grenzen der Open-Source-KI-Funktionen ausreizt.
Die Trainingsmethodik für Llama 3.1 umfasste einen riesigen Datensatz von über 15 Billionen Token, deutlich mehr als die Vorgängerversionen.
Architektonisch bleibt Llama 3.1 bei einem reinen Decoder-Transformator-Modell, das der Trainingsstabilität Vorrang vor experimentelleren Ansätzen wie Mixture-of-Experts einräumt.
Meta hat jedoch mehrere Optimierungen vorgenommen, um effizientes Training und Inferenzen in diesem beispiellosen Umfang zu ermöglichen:
Skalierbare Schulungsinfrastruktur: Verwendung von über 16.000 H100-GPUs zum Trainieren des 405B-Modells.
Iteratives Nachschulungsverfahren: Einsatz von überwachter Feinabstimmung und direkter Präferenzoptimierung zur Verbesserung bestimmter Fähigkeiten.
Quantisierungsverfahren: Reduzierung des Modells von 16-Bit- auf 8-Bit-Zahlen für eine effizientere Inferenz, die den Einsatz auf einzelnen Serverknoten ermöglicht.
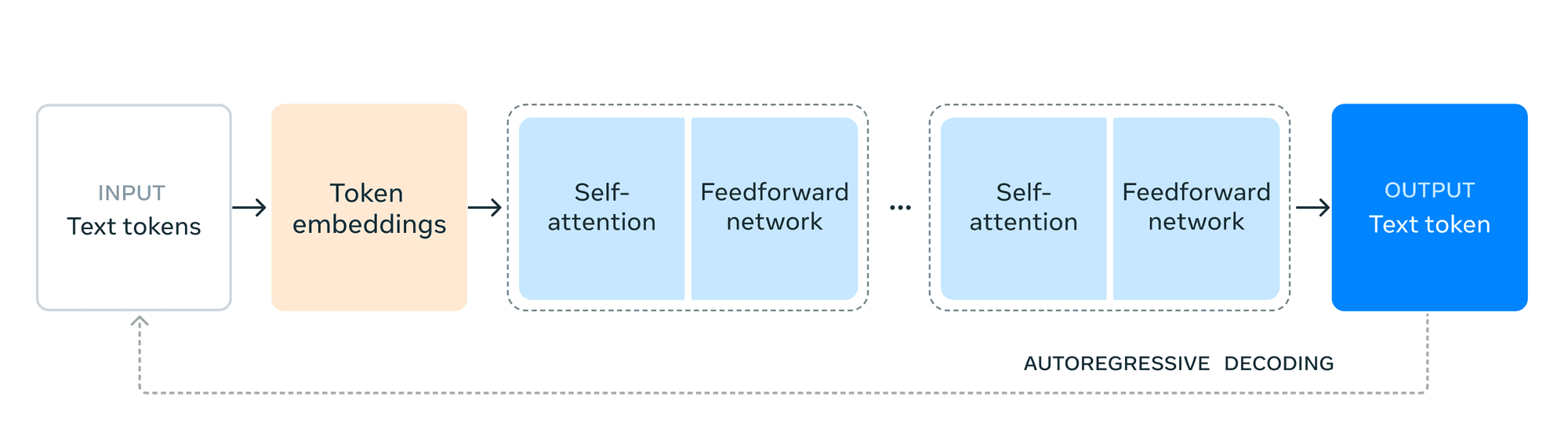
Bahnbrechende Fähigkeiten
Llama 3.1 führt mehrere bahnbrechende Funktionen ein, die es in der KI-Landschaft hervorheben:
Expanded Context Länge: Der Sprung zu einem 128K Token-Kontextfenster ist ein entscheidender Fortschritt. Diese erweiterte Kapazität ermöglicht es Llama 3.1, viel längere Textstücke zu verarbeiten und zu verstehen, wodurch:
Mehrsprachige Unterstützung: Mit der Unterstützung von acht Sprachen erweitert Llama 3.1 seine globale Anwendbarkeit erheblich.
Fortgeschrittenes logisches Denken und Werkzeuggebrauch: Das Modell zeigt ausgefeilte Argumentationsfähigkeiten und die Fähigkeit, externe Tools effektiv zu nutzen.
Codegenerierung und mathematische Fähigkeiten: Llama 3.1 zeigt bemerkenswerte Fähigkeiten in technischen Bereichen:
Generierung von hochwertigem, funktionalem Code in mehreren Programmiersprachen
Komplexe mathematische Probleme mit Genauigkeit lösen
Unterstützung bei der Entwicklung und Optimierung von Algorithmen
Versprechen und Potenzial von Llama 3.1
Metas Veröffentlichung von Llama 3.1 markiert einen entscheidenden Moment in der KI-Landschaft, da es den Zugang zu KI-Fähigkeiten auf Spitzenniveau demokratisiert. Durch das Angebot eines 405B-Parameter-Modells mit hochmoderner Leistung, mehrsprachiger Unterstützung und erweiterter Kontextlänge, alles in einem Open-Source-Framework, hat Meta einen neuen Standard für zugängliche, leistungsstarke KI gesetzt. Dieser Schritt stellt nicht nur die Dominanz von Closed-Source-Modellen in Frage, sondern ebnet auch den Weg für beispiellose Innovation und Zusammenarbeit in der KI-Community.
Danke, dass Sie sich die Zeit genommen haben, AI & YOU zu lesen!
Für noch mehr Inhalte zum Thema KI für Unternehmen, einschließlich Infografiken, Statistiken, Anleitungen, Artikeln und Videos, folgen Sie Skim AI auf LinkedIn
Sie sind Gründer, CEO, Risikokapitalgeber oder Investor und suchen KI-Beratung, fraktionierte KI-Entwicklung oder Due-Diligence-Dienstleistungen? Holen Sie sich die Beratung, die Sie brauchen, um fundierte Entscheidungen über die KI-Produktstrategie Ihres Unternehmens und Investitionsmöglichkeiten zu treffen.
Wir entwickeln maßgeschneiderte KI-Lösungen für von Venture Capital und Private Equity unterstützte Unternehmen in den folgenden Branchen: Medizintechnik, Nachrichten/Content-Aggregation, Film- und Fotoproduktion, Bildungstechnologie, Rechtstechnologie, Fintech und Kryptowährungen.


