
Як ваше підприємство має використовувати векторні бази даних для своїх LLM-додатків у 2024 році



В останні роки великі мовні моделі (ВММ) зробили революцію в галузі корпоративних програм штучного інтелекту. Ці потужні моделі машинного навчання продемонстрували неабиякі здібності в обробці, генеруванні та розумінні природної мови, відкривши світ можливостей для бізнесу в різних галузях. Однак у міру того, як LLM стають все більш складними і вимогливими, підприємства стикаються з проблемою ефективного зберігання і пошуку величезних обсягів даних, необхідних для навчання і роботи цих моделей. Введіть векторні бази даних - ключ до розкриття повного потенціалу Магістри в галузі підприємництва Застосування штучного інтелекту.
Розуміння векторних баз даних
Векторні бази даних - це спеціалізовані бази даних, призначені для зберігання та управління векторними даними високої розмірності. На відміну від традиційних баз даних, які зберігають дані у вигляді рядків і стовпців, векторні бази даних представляють дані у вигляді числових векторів у векторному просторі. Кожна точка даних, наприклад, текстовий документ або зображення, перетворюється на векторне вбудовування - щільне числове представлення фіксованої довжини, яке відображає семантичне значення даних.
Як працюють векторні бази даних
В основі векторних баз даних лежить концепція векторних включень і векторного простору. Векторні включення генеруються за допомогою моделей машинного навчання, таких як word2vec або BERT, які вчаться відображати точки даних у векторний простір високої розмірності. У цьому векторному просторі схожі точки даних представлені векторами, які знаходяться близько один до одного, тоді як несхожі точки даних віддалені один від одного.
Векторні бази даних дозволяють здійснювати ефективний пошук за схожістю та пошук найближчих сусідів. Коли надається вектор запиту, база даних може швидко знайти найбільш схожі вектори у векторному просторі, використовуючи метрики відстані, такі як косинусна схожість або евклідова відстань. Це дозволяє швидко і точно знаходити релевантні дані на основі семантичної схожості, а не точного збігу ключових слів.
Переваги використання векторних баз даних для LLM-додатків
Векторні бази даних мають кілька ключових переваг над традиційними базами даних, коли мова йде про підтримку додатків LLM:
Семантичний пошук: Векторні бази даних забезпечують семантичний пошук, дозволяючи LLM отримувати інформацію на основі значення і контексту запиту, а не покладатися на точний збіг ключових слів. Це призводить до більш релевантних і точних результатів.
Масштабованість: Векторні бази даних призначені для ефективної обробки великомасштабних векторних даних. Вони можуть зберігати та обробляти мільйони або навіть мільярди векторів високої розмірності, що робить їх ідеальними для роботи з великими масивами даних, необхідними для навчання та експлуатації LLM.
Швидший час виконання запитів: Спеціалізовані алгоритми індексування та пошуку, що використовуються у векторних базах даних, забезпечують блискавичну швидкість виконання запитів навіть для великих наборів даних. Це має вирішальне значення для додатків LLM в режимі реального часу, які вимагають швидкого доступу до релевантної інформації.
Покращена точність: Використовуючи семантичну інформацію, зафіксовану у векторних вбудовуваннях, векторні бази даних можуть допомогти LLM надавати більш точні та контекстно-релевантні відповіді на запити користувачів.
Оскільки підприємства прагнуть використати можливості LLM у своїх програмах штучного інтелекту, векторні бази даних стають важливим інструментом для ефективного зберігання та пошуку даних.

Магістерські програми та векторні бази даних: Ідеальне поєднання для корпоративного ШІ
Успіх LLM значною мірою залежить від якості та доступності даних, на яких вони навчаються. Саме тут у гру вступають векторні бази даних, що забезпечують потужне рішення для зберігання та пошуку величезних обсягів даних, необхідних для LLM.
Роль даних у підготовці та вдосконаленні LLMs
Магістри LLM навчаються на величезних масивах даних, що містять мільярди слів, що дозволяє їм вивчати тонкощі мови та розвивати глибоке розуміння контексту і значення. Після попередньої підготовки LLMs можуть бути точно налаштовані на специфічні для домену дані, щоб адаптуватися до конкретних випадків використання та галузей. Якість і релевантність цих даних безпосередньо впливають на продуктивність і точність роботи LLM в корпоративних додатках штучного інтелекту.
Проблеми використання традиційних баз даних для зберігання та пошуку даних про ОМР
Традиційні бази даних, такі як реляційні бази даних, не дуже добре підходять для обробки неструктурованих і багатовимірних даних, необхідних для LLM. Ці бази даних стикаються з наступними проблемами:
Масштабованість: Традиційні бази даних часто стикаються з проблемами продуктивності при роботі з великими наборами даних, що ускладнює зберігання та пошук величезних обсягів даних, необхідних для навчання та роботи LLM.
Неефективний пошук: Пошук за ключовими словами в традиційних базах даних не може охопити семантичне значення і контекст даних, що призводить до нерелевантних або неповних результатів при запитах LLM.
Відсутність гнучкості: Жорстка схема традиційних баз даних ускладнює роботу з різноманітними типами даних і структурами, пов'язаними з магістерськими програмами, що постійно розвиваються.
Як векторні бази даних долають ці виклики
Векторні бази даних спеціально розроблені для подолання обмежень традиційних баз даних, коли йдеться про підтримку LLM:
Ефективний пошук за схожістю для контекстно-залежного пошуку даних: Представляючи дані у вигляді векторів у високорозмірному просторі, векторні бази даних забезпечують швидкий і точний пошук за схожістю. LLM можуть отримувати релевантну інформацію на основі семантичного значення запиту, забезпечуючи більш контекстуально відповідні відповіді.
Масштабованість для роботи з великими наборами даних: Векторні бази даних створені для ефективної обробки величезних обсягів векторних даних. Вони можуть горизонтально масштабуватися на декількох машинах, що дозволяє зберігати і обробляти мільярди векторних вбудовувань, необхідних для LLM.
Реальні приклади використання векторних баз даних в LLM
Кілька відомих корпоративних програм штучного інтелекту успішно інтегрували LLM з векторними базами даних для підвищення продуктивності та ефективності:
Бази даних OpenAI GPT-4 та Anthropic: OpenAI та Anthropic використовують векторні бази даних для зберігання та вилучення величезних баз знань, що лежать в основі їхніх найсучасніших LLM, дозволяючи генерувати більш контекстно-релевантну та точну мову.
Корпоративний пошук та управління знаннями: Такі компанії, як Microsoft і Google, використовують векторні бази даних для вдосконалення своїх корпоративних систем пошуку та управління знаннями, дозволяючи співробітникам швидко і легко знаходити потрібну інформацію за допомогою запитів на природній мові.
Підтримка клієнтів і чат-боти: Компанії використовують векторні бази даних для зберігання та пошуку даних про клієнтів, інформації про продукти та історії розмов, що дозволяє чат-ботам на основі LLM надавати більш персоналізовану та ефективну підтримку клієнтам.
Визначення випадків використання векторних баз даних у ваших програмах LLM
Перш ніж впроваджувати векторну базу даних, важливо визначити конкретні випадки використання, в яких вона може принести найбільшу користь для ваших корпоративних додатків штучного інтелекту. Семантичний пошук і отримання інформації - це одна з областей, де векторні бази даних досягають успіху, дозволяючи користувачам знаходити релевантну інформацію за допомогою запитів на природній мові. Представляючи документи, зображення та інші дані у вигляді векторів, LLM можуть отримувати найбільш семантично схожі результати, підвищуючи точність і релевантність результатів пошуку.
Інший ключовий випадок використання - це розширена генерація пошукових запитів, де LLM можуть генерувати точніші та контекстно-релевантні відповіді, інтегруючись з векторними базами даних. Під час процесу генерації LLM може отримувати відповідну інформацію з векторної бази даних на основі вхідного запиту, підвищуючи зв'язність і фактичну правильність згенерованого тексту.
Системи персоналізації та рекомендацій також можуть отримати значну користь від векторних баз даних. Представляючи вподобання, поведінку та особливості користувача у вигляді векторів, LLM можуть генерувати вузькоспрямовані рекомендації, пропозиції контенту та результати, орієнтовані на конкретного користувача. Це досягається шляхом обчислення подібності між векторами користувача і товару.
Не в останню чергу векторні бази даних можна використовувати для управління знаннями та організації контенту. Підприємства можуть використовувати векторні бази даних для організації та управління великими обсягами неструктурованих даних, таких як документи, звіти та мультимедійний контент. Об'єднуючи схожі вектори разом, компанії можуть автоматично класифікувати і тегувати вміст, полегшуючи його пошук і навігацію.
Вибір правильної векторної бази даних для ваших потреб
Вибір відповідної векторної бази даних має вирішальне значення для успіху ваших корпоративних програм штучного інтелекту. Оцінюючи різні рішення для векторних баз даних, враховуйте компроміси між варіантами з відкритим вихідним кодом і пропрієтарними рішеннями. Векторні бази даних з відкритим кодом пропонують гнучкість, кастомізацію та економічну ефективність. Вони мають активні спільноти, регулярні оновлення та обширну документацію. З іншого боку, пропрієтарні рішення, які часто надаються хмарними платформами або спеціалізованими постачальниками, пропонують керовані послуги, підтримку корпоративного рівня та безперешкодну інтеграцію з іншими інструментами в їхній екосистемі. Однак вони можуть мати вищу вартість і ризики прив'язки до певного постачальника.
Масштабованість і продуктивність є критично важливими факторами при виборі векторної бази даних. Оцініть здатність бази даних впоратися з масштабом ваших даних, як з точки зору ємності сховища, так і з точки зору продуктивності запитів. Шукайте рішення, які можуть ефективно обробляти мільйони або мільярди векторів високої розмірності. Зверніть увагу на алгоритми індексування та пошуку в базі даних, такі як наближений пошук найближчого сусіда (ANN), який може значно прискорити пошук схожості у великих наборах даних. Крім того, оцініть можливості горизонтального та вертикального масштабування бази даних, щоб переконатися, що вона може зростати разом з вашими даними та базою користувачів.
Простота інтеграції - ще один важливий аспект. Вивчіть, наскільки добре векторна база даних інтегрується з вашим існуючим стеком технологій, в тому числі в рамках магістерської програмиконвеєрів даних та наступних додатків. Шукайте бази даних, які пропонують API, SDK і коннектори для популярних мов програмування та фреймворків, що полегшить вашій команді розробників інтеграцію та підтримку.
Нарешті, віддавайте перевагу базам даних векторів з активною спільнотою, вичерпною документацією та каналами підтримки, що швидко реагують на запити. Сильна спільнота забезпечує доступ до своєчасної допомоги, виправлення помилок та оновлення функцій. Оцініть екосистему інструментів, плагінів та інтеграцій бази даних, оскільки багата екосистема може прискорити розробку, забезпечити додаткову функціональність та полегшити інтеграцію з іншими корпоративними системами.

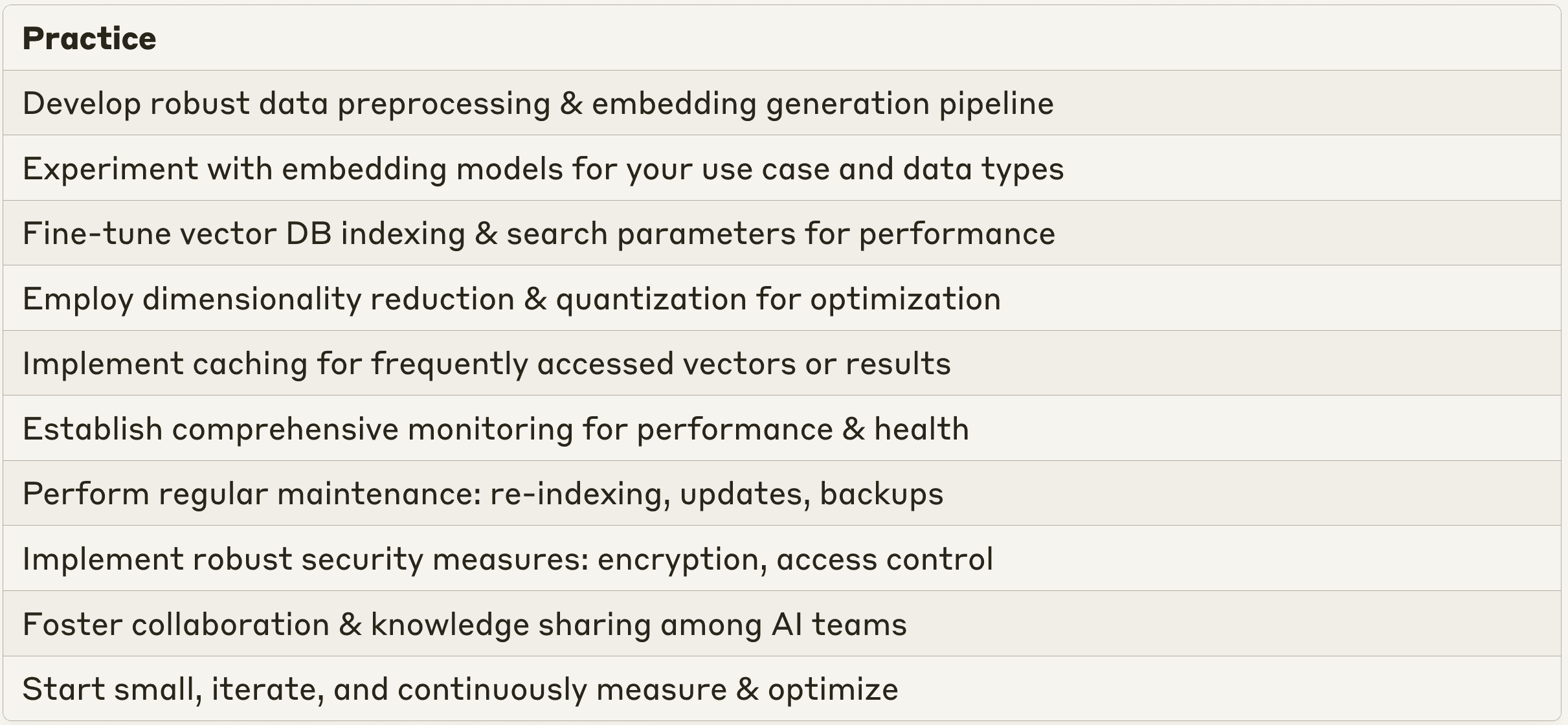
Найкращі практики інтеграції векторних баз даних з вашими програмами LLM
Щоб забезпечити плавне й ефективне впровадження векторних баз даних у ваші корпоративні програми штучного інтелекту, слід дотримуватися кількох найкращих практик. По-перше, розробіть надійний конвеєр попередньої обробки даних для очищення, нормалізації та перетворення ваших вихідних даних у формат, придатний для генерації векторних вбудовувань. Експериментуйте з різними моделями і методами вбудовування, щоб знайти найбільш підходящий підхід для вашого конкретного випадку використання і типів даних. Налаштовуйте попередньо навчені моделі вбудовування на даних конкретної галузі, щоб відобразити унікальну семантику та взаємозв'язки в контексті вашого підприємства. Впроваджуйте перевірки якості даних та етапи валідації, щоб забезпечити узгодженість і надійність ваших векторних вбудовувань.
Оптимізація запитів і налаштування продуктивності є важливими для ефективного використання векторної бази даних. Налаштуйте параметри індексування та пошуку у вашій векторній базі даних, такі як кількість найближчих сусідів, радіус пошуку або алгоритми кластеризації, щоб досягти балансу між швидкістю та точністю запитів. Використовуйте такі методи, як зменшення розмірності, щоб зменшити розмір ваших векторів, зберігаючи при цьому їхню семантичну інформацію, підвищуючи ефективність зберігання та продуктивність запитів. Використовуйте методи квантування, такі як квантування добутку або стиснення векторів, для подальшої оптимізації зберігання та пошуку векторів. Впроваджуйте механізми кешування для зберігання в пам'яті векторів або результатів пошуку, до яких часто звертаються, щоб зменшити затримку при повторних запитах.
Моніторинг та обслуговування мають вирішальне значення для забезпечення безперебійної роботи вашої бази даних векторів. Створіть комплексну систему моніторингу для відстеження продуктивності, доступності та стану вашої бази даних векторів. Відстежуйте ключові показники, такі як затримка запитів, пропускна здатність і рівень помилок. Налаштуйте оповіщення та сповіщення для проактивного виявлення та усунення будь-яких вузьких місць у роботі, обмежень ресурсів або аномалій. Регулярно виконуйте завдання з технічного обслуговування, включаючи переіндексацію, оновлення даних і резервне копіювання, щоб забезпечити цілісність і свіжість ваших векторних даних. Постійно оцінюйте та оптимізуйте продуктивність вашої векторної бази даних на основі реальних шаблонів використання та відгуків користувачів. За потреби змінюйте стратегії індексування, алгоритми пошуку та конфігурацію обладнання.
Безпека та контроль доступу мають першорядне значення при роботі з конфіденційними корпоративними даними. Впроваджуйте надійні заходи безпеки для захисту конфіденційності, цілісності та доступності ваших векторних даних. Застосовуйте механізми шифрування, автентифікації та контролю доступу для захисту конфіденційної інформації. Визначте детальну політику доступу та дозволи, щоб гарантувати, що лише авторизовані користувачі та програми можуть мати доступ до бази даних векторів та маніпулювати нею. Регулярно перевіряйте та переглядайте журнали доступу, щоб виявляти та запобігати спробам несанкціонованого доступу або підозрілим діям.
Нарешті, розвиток культури співпраці та обміну знаннями між вашими командами ШІ має важливе значення для успішного впровадження векторних баз даних. Заохочуйте обмін найкращими практиками, отриманими уроками та інноваційними ідеями, пов'язаними з базами даних векторів і програмами LLM. Створюйте внутрішні форуми, семінари або хакатони для заохочення експериментів, розвитку навичок і міжфункціональної співпраці навколо технологій векторних баз даних. Беріть участь у зовнішніх спільнотах, конференціях та галузевих заходах, щоб бути в курсі останніх досягнень, кейсів використання та найкращих практик у сфері векторних баз даних та корпоративного ШІ.
Дотримуючись цих найкращих практик і враховуючи унікальні вимоги вашого підприємства, ви зможете успішно впровадити векторні бази даних і розкрити весь потенціал ваших LLM-додатків. Не забувайте починати з малого, часто повторювати ітерації, постійно вимірювати та оптимізувати продуктивність вашої векторної бази даних, щоб вона приносила максимальну користь вашому бізнесу.
Майбутнє векторних баз даних у корпоративному ШІ
Оскільки технологія векторних баз даних продовжує розвиватися, можна очікувати, що ми побачимо безліч нових та інноваційних застосувань у корпоративному ШІ:
Створення персоналізованого контенту: LLM на основі векторних баз даних можуть генерувати високо персоналізований контент, наприклад, статті, звіти та маркетингові матеріали, пристосовані до вподобань та контексту окремих користувачів.
Інтелектуальна обробка документів: Векторні бази даних дозволяють автоматично класифікувати, індексувати та вилучати ключову інформацію з великих обсягів неструктурованих документів, оптимізуючи робочі процеси та вдосконалюючи процеси прийняття рішень.
Багатомовні асистенти зі штучним інтелектом: Використовуючи векторні вбудовування з різних мов, підприємства можуть розробляти асистентів зі штучним інтелектом, які розуміють і відповідають користувачам їхньою рідною мовою, долаючи мовні бар'єри і покращуючи глобальну співпрацю.
Прогнозне обслуговування та виявлення аномалій: Векторні бази даних можуть допомогти виявити закономірності та аномалії в даних датчиків і журналах обладнання, що дозволяє проводити проактивне технічне обслуговування і скоротити час простою в промислових умовах.
Оскільки ландшафт корпоративного штучного інтелекту продовжує розвиватися швидкими темпами, для бізнесу вкрай важливо бути в курсі останніх досягнень у сфері технологій векторних баз даних і LLM. Відстежуючи нові методи, інструменти та найкращі практики, підприємства можуть гарантувати, що їхні програми штучного інтелекту залишатимуться конкурентоспроможними та надаватимуть максимальну цінність своїм користувачам.
Використовуючи майбутнє векторних баз даних і LLM, підприємства можуть вийти на новий рівень ефективності, точності та розуміння своїх додатків ШІ, що в кінцевому підсумку сприятиме зростанню та успіху бізнесу в найближчі роки.


