
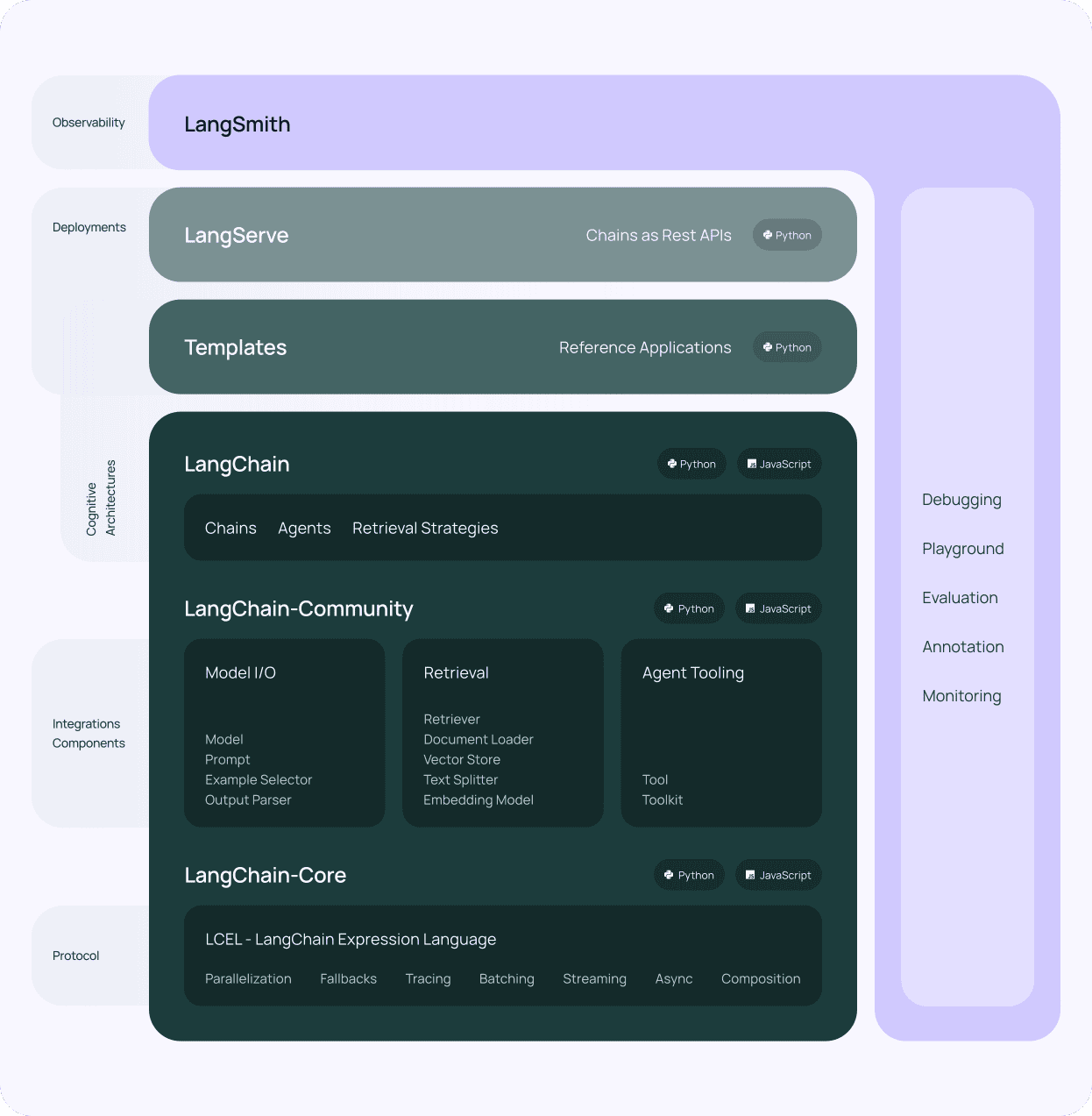
Топ-5 помилок та викликів при впровадженні LangChain



LangChainпопулярний фреймворк для створення додатків на основі мовних моделей, набуває все більшої популярності у спільноті ШІ. Його обіцянка спростити створення складних систем обробки природної мови приваблює як розробників, так і підприємства. Однак, як і у випадку з будь-якою новою технологією, існують типові помилки та проблеми, які можуть стати на заваді успішному впровадженню та використанню LangChain.
У цій статті ми розглянемо 5 найпоширеніших помилок і проблем, пов'язаних з LangChain, і надамо інформацію, яка допоможе вам уникнути цих пасток і отримати максимум від цього потужного фреймворку.
Помилка #1: Надмірне ускладнення архітектури
Однією з найпоширеніших помилок при роботі з LangChain є надмірне ускладнення архітектури. Дизайн LangChain побудований на фундаменті абстракцій, таких як Ланцюжок, Агенте.і Інструмент інтерфейси. Хоча ці абстракції спрямовані на забезпечення гнучкості та багаторазового використання, вони також можуть призвести до непотрібної складності, якщо їх не використовувати розумно.
Наприклад, ієрархія класів LangChain може бути досить глибокою, з декількома рівнями успадкування. Ієрархія класів Agent, наприклад, включає Агенте., АгентВиконавець, ZeroShotAgentі ConversationalAgentсеред інших. Такий рівень абстракції може ускладнити розробникам розуміння того, як правильно ініціалізувати агента або які методи перевизначити для кастомізації.
Іншим прикладом потенційного ускладнення є використання інтерфейсу зворотного виклику для підключення до життєвого циклу ланцюжків та агентів. У документації часто не вистачає чіткого пояснення різних методів зворотного виклику, таких як on_chain_start, on_tool_start, і on_agent_actionі коли вони застосовуються. Відсутність ясності може призвести до плутанини та труднощів у впровадженні користувацьких журналів, моніторингу або управління державою.
Вплив надто складної архітектури є значним. Вона може перешкоджати кастомізації, оскільки розробники намагаються зрозуміти, як модифікувати фреймворк відповідно до їхніх конкретних потреб. Налагодження стає складнішим, оскільки відстеження проблем через численні рівні абстракції може забирати багато часу і розчаровувати. Крім того, страждає супроводжуваність, оскільки складний код важче розуміти, оновлювати та розширювати з часом.
Помилка #2: Нехтування документацією та прикладами
Ще однією поширеною помилкою при роботі з LangChain є нехтування важливістю чіткої та вичерпної документації. Документація LangChain, хоча і обширна, часто не має достатньої чіткості та глибини, необхідної для того, щоб розробники могли повністю зрозуміти можливості фреймворку та найкращі практики.
Одним з недоліків документації LangChain є відсутність детальних пояснень ключових понять, параметрів за замовчуванням та очікуваних входів/виходів різних компонентів. Розробникам часто доводиться переглядати вихідний код або покладатися на метод спроб і помилок, щоб зрозуміти, як ефективно використовувати певні функції.
Крім того, приклади, наведені в документації, часто занадто спрощені і не відображають реальні випадки використання. Хоча ці приклади можуть допомогти користувачам розпочати роботу, вони не готують їх належним чином до складнощів і нюансів, що виникають у практичному застосуванні.
Наслідки нехтування документацією та прикладами є значними. Розробники, які тільки починають працювати з LangChain, можуть намагатися зрозуміти, як ефективно використовувати фреймворк, що призводить до розчарування і марної трати часу. Навіть досвідчені користувачі можуть витрачати надмірну кількість часу на з'ясування того, як реалізувати певні функціональні можливості або усунути проблеми, які можна було б легко вирішити за допомогою більш чіткої документації.
Без різноманітних прикладів з реального світу розробники можуть втратити цінні ідеї та найкращі практики, які могли б покращити їхні LangChain-проекти. Вони можуть ненавмисно винайти велосипед або прийняти неоптимальні проектні рішення просто тому, що не знають про існуючі патерни або підходи.
Помилка #3: Ігнорування невідповідностей та прихованої поведінки
Третя помилка, якої часто припускаються розробники, працюючи з LangChain, - це ігнорування невідповідностей та прихованої поведінки всередині фреймворку. Компоненти LangChain іноді можуть демонструвати неочікувану або непослідовну поведінку, яка не є чітко задокументованою, що призводить до плутанини та потенційних помилок.
Наприклад, поведінка ConversationBufferMemory може відрізнятися залежно від того, чи використовується він з компонентом ConversationChain або АгентВиконавець. У випадку ланцюжка діалогів ConversationChain, ConversationBufferMemory автоматично додає відповіді ШІ до пам'яті, тоді як у випадку AgentExecutor цього не відбувається. Такі невідповідності, якщо вони явно не задокументовані, можуть призвести до неправильних припущень і помилкових реалізацій.
Іншим прикладом прихованої поведінки є те, як певні ланцюги, такі як LLMMathChainвикористовують інший формат вхідних параметрів порівняно з іншими ланцюжками. Замість того, щоб очікувати словник вхідних даних, LLMMathChain очікує один параметр "питання". Ці розбіжності у форматах вхідних даних можуть ускладнити складання та інтегрувати різні ланцюги без проблем.
Вплив ігнорування невідповідностей та прихованої поведінки є значним. Розробники можуть витрачати години на налагодження проблем, які виникають через неправильні припущення про поведінку компонентів. Відсутність узгодженості у поведінці та форматах вхідних даних у різних частинах фреймворку може ускладнити міркування про потік даних та створення надійних додатків.
Більше того, прихована поведінка може призвести до непомітних помилок, які можуть залишитися непоміченими під час розробки, але спливти на поверхню у виробничому середовищі, спричиняючи несподівані збої або некоректні результати. Виявлення та виправлення таких проблем може зайняти багато часу і вимагати глибоких знань внутрішньої будови фреймворку.
Помилка #4: Недооцінка викликів інтеграції
Ще однією поширеною помилкою при роботі з LangChain є недооцінка проблем, пов'язаних з інтеграцією фреймворку з існуючими кодовими базами, інструментами та робочими процесами. Самостійний дизайн LangChain та залежність від специфічних патернів, таких як ланцюжок методів та зворотні виклики, можуть створювати тертя при спробі інтегрувати його у вже існуюче середовище розробки.
Наприклад, інтеграція LangChain з такими веб-фреймворками, як FastAPI може вимагати перекладу між різними типами запитів, відповідей та винятків. Розробники повинні ретельно зіставити вхідні та вихідні дані LangChain з конвенціями веб-фреймворку, що може додати складності та потенційних помилок.
Аналогічно, при інтеграції LangChain з базами даних або чергами повідомлень розробникам може знадобитися серіалізація та десеріалізація об'єктів LangChain, що може бути громіздким і схильним до помилок. Залежність фреймворку від певних шаблонів проектування може не завжди відповідати кращим практикам або вимогам існуючої інфраструктури.
Використання глобального стану та синглетонів у LangChain також може створювати проблеми у паралельних або розподілених середовищах. Належне визначення масштабу та ін'єкція залежностей може вимагати обхідних шляхів або модифікації поведінки фреймворку за замовчуванням, що додає складнощів у процесі інтеграції.
Наслідки недооцінки проблем інтеграції є значними. Розробники можуть витрачати на інтеграцію більше часу, ніж очікувалося, що призведе до затягування термінів виконання проекту та збільшення витрат на розробку. Додаткова складність інтеграції також може призвести до появи помилок і проблем з підтримкою, оскільки кодову базу з часом стає важче зрозуміти і модифікувати.
Крім того, тертя, викликані проблемами інтеграції, можуть призвести до того, що деякі розробники взагалі відмовляться від LangChain, обираючи альтернативні рішення, які є більш сумісними з їхніми існуючими технологічними стеками та робочими процесами. Це може призвести до втрачених можливостей використання потужних можливостей LangChain і потенційно призвести до неоптимальних реалізацій.
Помилка #5: ігнорування міркувань продуктивності та надійності
П'ята помилка, якої часто припускаються розробники при роботі з LangChain - ігнорування міркувань продуктивності та надійності. Хоча LangChain надає потужний набір інструментів для створення додатків на основі мовної моделі, оптимізація цих додатків для виробничих сценаріїв використання вимагає ретельної уваги до факторів продуктивності та надійності.
Однією з проблем оптимізації додатків LangChain є складність архітектури фреймворку. З багатьма рівнями абстракції та численними компонентами, що беруть участь в обробці вхідних та вихідних даних мови, виявлення вузьких місць та неефективності може бути складним. Розробникам може знадобитися глибоке розуміння внутрішньої будови фреймворку, щоб ефективно профілювати та оптимізувати свої додатки.
Інша проблема полягає в тому, що налаштування LangChain за замовчуванням не завжди підходять для виробничих середовищ. Конфігурація фреймворку за замовчуванням може надавати перевагу простоті використання та гнучкості перед продуктивністю та економічністю. Наприклад, налаштування за замовчуванням для кешування, використання токенів і викликів API можуть бути не оптимізовані з точки зору затримок або вартості, що призводить до неоптимальної продуктивності в реальних сценаріях.
Ігнорування міркувань продуктивності та надійності може мати значні наслідки. Додатки, побудовані за допомогою LangChain, можуть страждати від повільного часу відгуку, високої латентності та підвищених операційних витрат. У критично важливих або орієнтованих на користувача додатках низька продуктивність може призвести до погіршення користувацького досвіду і втрати довіри користувачів.
Крім того, проблеми з надійністю можуть виникнути, якщо додатки LangChain не будуть належним чином протестовані та відстежені у виробничому середовищі. Неочікувані збої, тайм-аути або обмеження ресурсів можуть призвести до того, що додатки не реагуватимуть або видаватимуть некоректні результати. Налагодження та усунення таких проблем може бути складним завданням, що вимагає глибоких знань фреймворку та базової інфраструктури.
Щоб зменшити ці ризики, розробники повинні проактивно враховувати фактори продуктивності та надійності при створенні додатків LangChain. Це включає в себе ретельну оцінку впливу різних варіантів конфігурації на продуктивність, проведення ретельного тестування продуктивності та моніторинг додатків у виробництві для виявлення та оперативного вирішення будь-яких проблем.
Подолання помилок і викликів LangChain за допомогою Skim AI
У цій статті ми розглянули 5 найпоширеніших помилок та проблем, з якими розробники та підприємства часто стикаються під час роботи з цим потужним фреймворком LangChain. Від надмірного ускладнення архітектури та нехтування документацією до ігнорування невідповідностей та недооцінки проблем інтеграції - ці помилки можуть суттєво перешкоджати успіху впровадження LangChain. Більше того, ігнорування міркувань продуктивності та надійності може призвести до неоптимальних результатів і навіть збоїв у виробничих середовищах.
Важливо визнати, що ці проблеми не є нездоланними. Активно вирішуючи ці питання та звертаючись за порадою до експертів, підприємства можуть подолати перешкоди, пов'язані з LangChain, і розкрити весь потенціал цієї платформи для своїх додатків. За допомогою LangChain ваше підприємство може створювати високопродуктивні, зручні та надійні рішення, які сприятимуть підвищенню цінності та впровадженню інновацій у сфері штучного інтелекту.


