
Розбивка дослідницьких робіт ШІ для ChainPoll: високоефективний метод виявлення галюцинацій LLM



У цій статті ми розповімо про важливу дослідницьку роботу, яка розглядає одну з найактуальніших проблем, що стоять перед великими мовними моделями (ВММ): галюцинації. Стаття під назвою "ChainPoll: високоефективний метод для виявлення галюцинацій при НСД" представляє новий підхід до виявлення та пом'якшення цих неточностей, спричинених штучним інтелектом.
У статті ChainPoll, авторами якої є дослідники з Galileo Technologies Inc., представлено нову методологію виявлення галюцинацій у вихідних даних LLM. Цей метод, названий ChainPoll, перевершує існуючі альтернативи як за точністю, так і за ефективністю. Крім того, в статті представлено RealHall, ретельно підібраний набір тестових наборів даних, розроблений для оцінки метрик виявлення галюцинацій більш ефективно, ніж попередні бенчмарки.
Галюцинації в ШНМ - це випадки, коли ці моделі ШІ генерують текст, який є фактично неправильним, безглуздим або не пов'язаним із вхідними даними. Оскільки ШНМ дедалі більше інтегруються в різні додатки, від чат-ботів до інструментів для створення контенту, ризик поширення дезінформації через ці галюцинації зростає в геометричній прогресії. Ця проблема становить значний виклик надійності та достовірності контенту, створеного штучним інтелектом.
Здатність точно виявляти та пом'якшувати галюцинації має вирішальне значення для відповідального розгортання систем штучного інтелекту. Це дослідження пропонує більш надійний метод виявлення цих помилок, що може призвести до підвищення надійності контенту, створеного штучним інтелектом, зміцнення довіри користувачів до додатків ШІ та зниження ризику поширення дезінформації через системи ШІ. Вирішуючи проблему галюцинацій, це дослідження прокладає шлях до більш надійних і достовірних додатків ШІ в різних галузях.

Передумови та постановка проблеми
Виявлення галюцинацій у вихідних даних LLM є складним завданням через кілька факторів. Великий обсяг тексту, який можуть генерувати LLM, у поєднанні з часто малопомітною природою галюцинацій робить їх важко відрізнити від достовірної інформації. Крім того, контекстно-залежний характер багатьох галюцинацій і відсутність всеосяжної "базової істини", з якою можна було б звіряти весь згенерований контент, ще більше ускладнюють процес виявлення.
До роботи ChainPoll існуючі методи виявлення галюцинацій стикалися з кількома обмеженнями. Багатьом з них не вистачало ефективності в різних завданнях і сферах, а інші були занадто дорогими в обчислювальному плані для застосування в реальному часі. Деякі методи залежали від конкретних архітектур моделей або навчальних даних, а більшість з них намагалися відрізнити різні типи галюцинацій, наприклад, фактичні помилки від контекстних.
Крім того, критерії, які використовувалися для оцінки цих методів, часто не відображали справжніх викликів, що постають перед найсучаснішими LLM у реальних умовах застосування. Багато з них базувалися на старих, слабших моделях або були зосереджені на вузьких, специфічних завданнях, які не відображали повний спектр можливостей і потенційних галюцинацій LLM.
Щоб вирішити ці питання, дослідники, які працювали над документом ChainPoll, застосували двосторонній підхід:
Розробка нового, більш ефективного методу виявлення галюцинацій (ChainPoll)
Створення більш релевантного та складного набору тестів (RealHall)
Цей комплексний підхід мав на меті не лише покращити виявлення галюцинацій, але й створити більш надійну основу для оцінки та порівняння різних методів виявлення.
Основний внесок роботи
Стаття ChainPoll робить три основні внески в сферу досліджень і розробок ШІ, кожен з яких стосується критично важливого аспекту проблеми виявлення галюцинацій.
По-перше, у статті представлено ChainPollнова методологія виявлення галюцинацій. ChainPoll використовує можливості самих LLM для виявлення галюцинацій, використовуючи ретельно розроблену техніку підказок і метод агрегування для підвищення точності та надійності. Він використовує ланцюжок підказок для отримання більш детальних і систематичних пояснень, запускає кілька ітерацій процесу виявлення для підвищення надійності і адаптується як до відкритих, так і до закритих сценаріїв виявлення галюцинацій.
По-друге, визнаючи обмеження існуючих бенчмарків, автори розробили RealHallновий набір еталонних наборів даних. RealHall призначений для більш реалістичної та складної оцінки методів виявлення галюцинацій. Він складається з чотирьох ретельно відібраних наборів даних, які є складними навіть для найсучасніших LLM, фокусується на завданнях, що мають відношення до реальних застосувань LLM, і охоплює як відкриті, так і закриті сценарії галюцинацій.
Нарешті, в статті представлено ретельне порівняння ChainPoll з широким спектром існуючих методів виявлення галюцинацій. Ця комплексна оцінка використовує нещодавно розроблений набір бенчмарків RealHall, включає як усталені метрики, так і останні інновації в цій галузі, а також враховує такі фактори, як точність, ефективність та економічність. Завдяки цій оцінці документ демонструє чудову продуктивність ChainPoll для різних завдань і типів галюцинацій.
Пропонуючи ці три ключові внески, стаття ChainPoll не тільки просуває сучасні технології виявлення галюцинацій, але й забезпечує більш надійну основу для майбутніх досліджень і розробок у цій критично важливій сфері безпеки та надійності ШІ.
Погляд на методологію ChainPoll
По суті, ChainPoll використовує можливості самих великих мовних моделей для виявлення галюцинацій у тексті, згенерованому штучним інтелектом. Цей підхід вирізняється простотою, ефективністю та адаптивністю до різних типів галюцинацій.
Як працює ChainPoll
Метод ChainPoll працює за простим, але потужним принципом. Він використовує LLM (зокрема, GPT-3.5-turbo в експериментах цієї статті), щоб оцінити, чи містить певне завершення тексту галюцинації.
Процес складається з трьох ключових етапів:
По-перше, система пропонує LLM оцінити наявність галюцинацій у цільовому тексті, використовуючи ретельно розроблений підказка.
Потім цей процес повторюється кілька разів, зазвичай п'ять, щоб забезпечити надійність.
Нарешті, система підраховує бал шляхом ділення кількості відповідей "так" (що свідчить про наявність галюцинацій) на загальну кількість відповідей.
Такий підхід дозволяє ChainPoll використовувати можливості розуміння мови магістрами, одночасно зменшуючи індивідуальні помилки оцінювання за рахунок агрегування.
Роль підказки ланцюжка думок
Важливим нововведенням у ChainPoll є використання підказок у вигляді ланцюжка думок (CoT). Ця методика заохочує LLM надавати покрокове пояснення своїх міркувань при визначенні того, чи містить текст галюцинації. Автори виявили, що ретельно розроблена "детальна підказка ланцюжка думок" послідовно викликала більш систематичні та надійні пояснення від моделі.
Завдяки використанню CoT, ChainPoll не лише підвищує точність виявлення галюцинацій, але й надає цінну інформацію про процес прийняття рішень моделлю. Ця прозорість може мати вирішальне значення для розуміння того, чому певні тексти позначені як такі, що містять галюцинації, що потенційно може допомогти в розробці більш надійних LLM у майбутньому.
Розрізнення галюцинацій відкритого та закритого типу
Однією з сильних сторін ChainPoll є його здатність працювати як з відкритими, так і з закритими галюцинаціями. Відкриті галюцинації стосуються неправдивих тверджень про світ загалом, тоді як закриті галюцинації пов'язані з невідповідністю конкретному довідковому тексту або контексту.
Щоб впоратися з цими різними типами галюцинацій, автори розробили два варіанти ChainPoll: ChainPoll-Коректність для галюцинацій з відкритим доменом і ChainPoll-Adherence для галюцинацій із закритим доменом. Ці варіанти відрізняються насамперед стратегією підказок, що дозволяє системі адаптуватися до різних контекстів оцінювання, зберігаючи при цьому основну методологію ChainPoll.
RealHall Benchmark Suite
Усвідомлюючи обмеженість існуючих бенчмарків, автори також розробили RealHall, новий набір бенчмарків, покликаний забезпечити більш реалістичну і складну оцінку методів виявлення галюцинацій.
Критерії відбору наборів даних (виклик, реалістичність, різноманітність завдань)
При створенні RealHall керувалися трьома ключовими принципами:
Виклик: Набори даних повинні створювати значні труднощі навіть для найсучасніших LLM, гарантуючи, що еталон залишатиметься актуальним у міру вдосконалення моделей.
Реалізм: Завдання повинні відображати реальні сфери застосування LLM, що зробить результати тестування більш застосовними до практичних сценаріїв.
Різноманітність завдань: Пакет повинен охоплювати широкий спектр можливостей LLM, забезпечуючи комплексну оцінку методів виявлення галюцинацій.
За цими критеріями було обрано чотири набори даних, які в сукупності пропонують надійний полігон для тестування методів виявлення галюцинацій.
Огляд чотирьох наборів даних у RealHall
RealHall складається з двох пар наборів даних, кожен з яких присвячений різним аспектам виявлення галюцинацій:
РеалХол закрито: Ця пара включає COVID-QA з набором даних для пошуку та набір даних DROP. Вони зосереджені на галюцинаціях у закритих доменах, перевіряючи здатність моделі залишатися послідовною з наданими еталонними текстами.
РеалХолл відкрито: Ця пара складається з набору даних підказок Open Assistant та набору даних TriviaQA. Вони націлені на галюцинації у відкритому домені, оцінюючи здатність моделі уникати неправдивих тверджень про світ.
Кожен набір даних у RealHall був обраний за його унікальні завдання та відповідність реальним завданням LLM. Наприклад, набір даних COVID-QA імітує сценарії генерації, доповнені пошуком, в той час як DROP тестує здібності до дискретного мислення.
Як RealHall усуває обмеження попередніх бенчмарків
RealHall є значним покращенням порівняно з попередніми бенчмарками в кількох аспектах. По-перше, він використовує новіші та потужніші LLM для генерування відповідей, гарантуючи, що виявлені галюцинації є репрезентативними для тих, що створюються сучасними моделями. Це вирішує загальну проблему попередніх тестів, які використовували застарілі моделі, що створювали галюцинації, які легко виявлялися.
По-друге, зосередженість RealHall на різноманітності та реалістичності завдань означає, що він надає більш комплексну і практично релевантну оцінку методів виявлення галюцинацій. Це контрастує з багатьма попередніми бенчмарками, які фокусувалися на вузьких, специфічних завданнях або штучних сценаріях.
Нарешті, включаючи як відкриті, так і закриті завдання, RealHall дозволяє більш тонко оцінювати методи виявлення галюцинацій. Це особливо важливо, оскільки багато реальних LLM-задач вимагають обох типів виявлення галюцинацій.
Завдяки цим вдосконаленням RealHall забезпечує більш суворий і релевантний еталон для оцінки методів виявлення галюцинацій, встановлюючи новий стандарт в цій галузі.
Експериментальні результати та аналіз
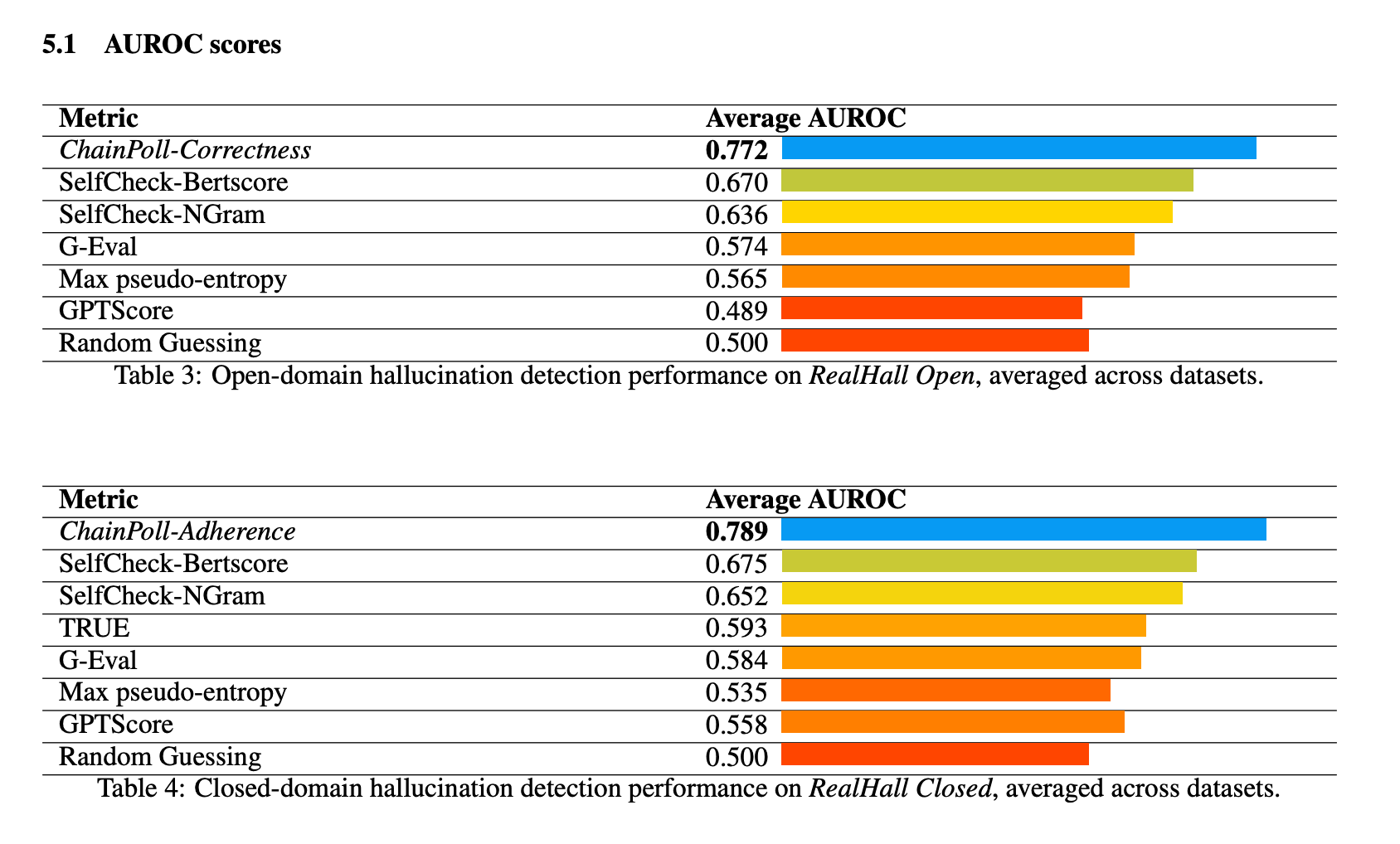
ChainPoll продемонстрував чудову продуктивність за всіма тестами набору RealHall. Він досяг сукупного показника AUROC (площа під кривою робочої характеристики приймача) 0,781, значно перевершивши наступний найкращий метод, SelfCheck-BertScore, який набрав 0,673. Таке суттєве покращення порівняно з 10% є значним стрибком у можливостях виявлення галюцинацій.
Серед інших протестованих методів були SelfCheck-NGram, G-Eval та GPTScore, які показали значно гірші результати, ніж ChainPoll. Цікаво, що деякі методи, які показали себе багатообіцяючими в попередніх дослідженнях, такі як GPTScore, показали погані результати на більш складних і різноманітних тестах RealHall.

Ефективність ChainPoll була стабільно високою як у відкритих, так і в закритих задачах виявлення галюцинацій. Для відкритих задач (з використанням ChainPoll-Correctness) середній показник AUROC склав 0,772, а для закритих задач (з використанням ChainPoll-Adherence) - 0,789.
Метод показав особливу ефективність у складних наборах даних, таких як DROP, які вимагають дискретних міркувань.
Окрім вищої точності, ChainPoll також виявився більш ефективним та економічно вигідним, ніж багато конкуруючих методів. Він досягає своїх результатів, використовуючи лише на 1/4 менше LLM-висновків, ніж наступний найкращий метод, SelfCheck-BertScore. Крім того, ChainPoll не вимагає використання додаткових моделей, таких як BERT, що ще більше зменшує обчислювальні витрати.
Ця ефективність має вирішальне значення для практичного застосування, оскільки дозволяє виявляти галюцинації в реальному часі у виробничих умовах без надмірних витрат і затримок.
Висновки та подальша робота
ChainPoll - це значний прогрес у сфері виявлення галюцинацій для LLM. Його успіх демонструє потенціал використання самих LLM як інструментів для підвищення безпеки та надійності ШІ. Такий підхід відкриває нові шляхи для дослідження систем ШІ, що самовдосконалюються та самоперевіряються.
Ефективність і точність ChainPoll роблять його придатним для інтеграції в широкий спектр додатків зі штучним інтелектом. Його можна використовувати для підвищення надійності чат-ботів, точності контенту, створеного штучним інтелектом, у таких галузях, як журналістика чи технічне письмо, а також для підвищення довіри до асистентів штучного інтелекту в таких важливих сферах, як охорона здоров'я чи фінанси.
Хоча ChainPoll показує вражаючі результати, все ще є місце для подальших досліджень та вдосконалення. Майбутня робота може це дослідити:
Адаптація ChainPoll для роботи з ширшим спектром магістерських програм та мовних завдань
Вивчення шляхів подальшого підвищення ефективності без шкоди для точності
Вивчення потенціалу ChainPoll для інших типів контенту, створеного штучним інтелектом, окрім тексту
Розробка методів не лише виявлення, але й корекції або запобігання галюцинаціям у режимі реального часу
Стаття ChainPoll робить значний внесок у сферу безпеки та надійності ШІ завдяки впровадженню нового методу виявлення галюцинацій і більш надійного критерію оцінки. Демонструючи чудову продуктивність у виявленні як відкритих, так і закритих галюцинацій, ChainPoll прокладає шлях до більш надійних систем ШІ. Оскільки LLM продовжують відігравати все більш важливу роль у різних сферах застосування, здатність точно виявляти і зменшувати галюцинації стає критично важливою. Це дослідження не тільки розширює наші поточні можливості, але й відкриває нові шляхи для майбутніх досліджень і розробок у критично важливій сфері виявлення галюцинацій ШІ.


