
Наш 4-інструментальний стек + стратегія побудови корпоративних додатків на LLM - AI&YOU#53



Статистика/факт тижня: Прогнозується, що світовий ринок LLM зросте з $1,59 млрд у 2023 році до $259,8 млрд у 2030 році, що становить CAGR 79,8% протягом 2023-2030 років (Springs).
Великі мовні моделі (LLM) стали ключем до створення інтелектуальних корпоративних додатків. Однак, щоб використати можливості цих мовних моделей, потрібен надійний та ефективний стек LLM-додатків.
У Skim AI наш стек додатків LLM дозволяє створювати потужні програми з розширеними можливостями взаємодії з природною мовою. Наш стек складається з ретельно відібраних інструментів і фреймворків, таких як LLM API, LangChain і векторні бази даних.
У цьому випуску AI&YOU ми висвітлюємо наш стек з 4 інструментів та стратегію створення корпоративних LLM-додатків у наших блогах:
Як побудувати стек додатків для LLM за допомогою цих 4 інструментів та фреймворків
5 найкращих стратегій інтеграції LLM API для вашого підприємства
Наш 4-інструментальний стек та стратегія побудови корпоративних додатків на LLM - AI&YOU #53
Завдяки нашому корпоративному LLM-стеку розробники можуть безперешкодно інтегрувати специфічні для домену дані, налаштовувати моделі, створювати ефективні конвеєри даних для отримання контекстних даних та багато іншого.
Це дозволяє компаніям створювати додатки, які розуміють і реагують на запити користувачів з безпрецедентною точністю і урахуванням контексту.
У той же час, одним з основних методів роботи з цим стеком є використання існуючих інструментів і фреймворків, що надаються різними компонентами. Це дозволяє розробникам зосередитися на створенні додатків, а не на створенні інструментів з нуля, заощаджуючи цінний час і зусилля.
Інструмент 1: LLM API, як GPT, Claude, Llama або Mistral
В основі стеку ваших LLM-додатків має бути LLM API. LLM API надають можливість інтегрувати потужні мовні моделі у ваші додатки без необхідності самостійно навчати або розміщувати моделі. Вони слугують мостом між вашим програмним забезпеченням і складними алгоритмами, що лежать в основі мовних моделей, дозволяючи вам додавати розширені можливості обробки природної мови до ваших додатків з мінімальними зусиллями.
Однією з ключових переваг використання LLM API є можливість використовувати найсучасніші мовні моделі, які були навчені на величезних обсягах даних. Такі моделі, як GPT, Клод., Містральі Ламо!здатні розуміти і генерувати людський текст з дивовижною точністю і швидкістю.
Здійснюючи виклики API до цих моделей, ви можете швидко додати до своїх додатків широкий спектр можливостей, включаючи генерацію тексту, аналіз настроїв, відповіді на запитання та багато іншого.

Фактори, які слід враховувати при виборі LLM API
Вибираючи LLM API для свого стека, слід враховувати кілька факторів:
Продуктивність і точність: Переконайтеся, що API може впоратися з вашим навантаженням і надавати надійні результати.
Кастомізація та гнучкість: Подумайте, чи потрібно вам доопрацьовувати модель для конкретного випадку використання або інтегрувати її з іншими компонентами вашого стеку.
Масштабованість: Якщо ви очікуєте великих обсягів запитів, переконайтеся, що API може масштабуватися відповідно.
Підтримка та спільнота: Оцініть рівень підтримки та розмір спільноти навколо API, оскільки це може вплинути на довгострокову життєздатність вашого додатку.
В основі більшості LLM API лежать глибокі нейронні мережі, зазвичай засновані на трансформаторній архітектурі, які навчаються на величезних обсягах текстових даних. Доступ до цих моделей здійснюється через інтерфейс API, який виконує такі завдання, як автентифікація, маршрутизація запитів і форматування відповідей. LLM API також часто включають додаткові компоненти для обробки даних, такі як токенізація та нормалізація, а також інструменти для тонкого налаштування та кастомізації.
Інструмент 2: LangChain
Після вибору LLM API для вашого стека додатків LLM, наступним компонентом, який слід розглянути, є LangChain. LangChain - це потужний фреймворк, призначений для спрощення процесу створення додатків на основі великих мовних моделей. Він надає стандартизований інтерфейс для взаємодії з різними LLM API, що полегшує їх інтеграцію у ваш технологічний стек LLM.
Однією з ключових переваг використання LangChain є його модульна архітектура. LangChain складається з декількох компонентів, таких як підказки, ланцюжки, агенти та пам'ять, які можна комбінувати для створення складних робочих процесів. Ця модульність дозволяє створювати додатки, які можуть виконувати широкий спектр завдань, від простих відповідей на запитання до більш складних випадків використання, таких як генерація контенту та аналіз даних, забезпечуючи взаємодію природною мовою з даними, специфічними для вашого домену.
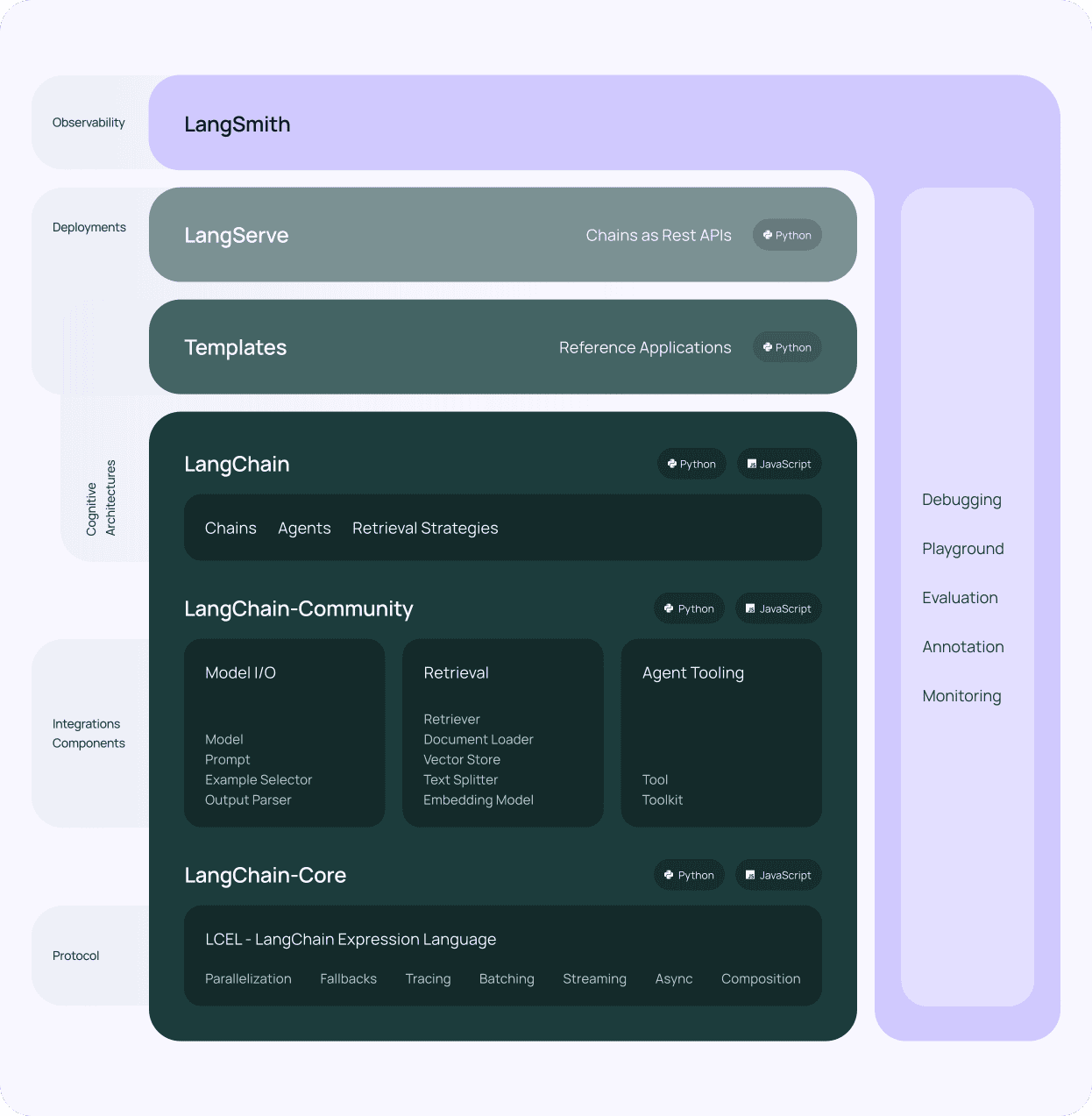
Різноманітні інструменти та підтримка LangChain
LangChain також надає різноманітні інструменти та утиліти, які спрощують роботу з LLM. Наприклад, він пропонує інструменти для роботи з вбудовуваннями, які є числовими представленнями тексту, що використовуються для таких завдань, як семантичний пошук і кластеризація. Крім того, LangChain містить утиліти для керування підказками, які є вхідними рядками, що використовуються для керування поведінкою мовних моделей.
Ще однією важливою особливістю LangChain є підтримка векторних баз даних. Інтегруючись з векторними базами даних, такими як Chroma (яку ми використовуємо), LangChain дозволяє створювати додатки, які можуть ефективно зберігати та отримувати великі обсяги даних. Ця інтеграція дозволяє створювати наукомісткі додатки, які можуть спиратися на широкий спектр джерел інформації, покращуючи пошук контекстних даних для вашого стеку LLM-додатків.
LangChain є життєво важливим компонентом будь-якої підприємницька діяльність LLM стек додатків. Модульний дизайн, потужні інструменти та активна спільнота роблять його незамінним інструментом для створення складних мовних додатків.
Інструмент 3: Векторна база даних на кшталт Chroma
На додаток до LLM API та LangChain, ще одним важливим компонентом вашого стеку додатків LLM є векторна база даних. Векторні бази даних - це спеціалізовані сховища даних, оптимізовані для зберігання та пошуку векторів високої розмірності, таких як вбудовування, згенеровані великими мовними моделями. Інтегрувавши векторну базу даних у свій стек технологій LLM, ви зможете забезпечити швидкий та ефективний пошук релевантних даних на основі семантичної схожості.
Chroma це популярний вибір з відкритим вихідним кодом для векторної бази даних у стеках LLM-додатків, і ми використовуємо його тут, у Skim AI. Вона розроблена для безперебійної роботи з LangChain та іншими компонентами вашого стеку, забезпечуючи надійне та масштабоване рішення для зберігання та пошуку вбудовувань.
Однією з ключових переваг використання Chroma є її здатність ефективно обробляти великі обсяги даних. Chroma використовує передові методи індексування для швидкого пошуку за схожістю навіть у великих масивах даних. Це робить його ідеальним вибором для додатків, які потребують зберігання та пошуку у великих обсягах текстових даних, таких як сховища документів, бази знань та системи управління контентом.
Chroma також пропонує розширені можливості, такі як фільтрація та підтримка метаданих. Ви можете зберігати додаткові метадані поряд із вбудовуваннями, наприклад, ідентифікатори документів, мітки часу або користувацькі атрибути. Ці метадані можна використовувати для фільтрації результатів пошуку, що дає змогу точніше і цілеспрямованіше отримувати контекстні дані.

Інтеграція Chroma у стек LLM на вашому підприємстві
Інтегрувати Chroma у стек LLM-додатків дуже просто завдяки його сумісності з LangChain та іншими популярними інструментами і фреймворками. LangChain надає вбудовану підтримку Chroma, що дозволяє легко зберігати та отримувати вбудовування, згенеровані вашими мовними моделями. Ця інтеграція дозволяє створювати потужні механізми пошуку, які можуть швидко виводити на поверхню релевантну інформацію на основі взаємодії з природною мовою.
Використання векторної бази даних, такої як Chroma, в поєднанні з LLM відкриває нові можливості для створення інтелектуальних, контекстно-орієнтованих додатків. Використовуючи можливості вбудовування і пошуку за схожістю, ви можете створювати додатки, які розуміють і реагують на запити користувачів з безпрецедентною точністю і релевантністю.
У поєднанні з LangChain і LLM API, Chroma створює потужну основу для створення інтелектуальних, керованих даними додатків, які можуть змінити спосіб нашої взаємодії з корпоративними даними і специфічною для домену інформацією.
Інструмент 4: crewAI для багатоагентних систем
У Skim AI ми знаємо, що майбутнє робочих процесів зі штучним інтелектом - за агентами, тому мультиагентна система сьогодні важлива для будь-якого підприємства.
crewAI ще один потужний інструмент, який ви можете додати до свого стеку додатків для LLM, щоб розширити можливості ваших додатків. crewAI - це фреймворк, який дозволяє створювати мультиагентні системи, де кілька агентів ШІ працюють разом для виконання складних завдань.
По суті, crewAI розроблений для полегшення співпраці між кількома агентами штучного інтелекту, кожен з яких має свою власну роль і досвід. Ці агенти можуть спілкуватися і координувати свої дії один з одним, щоб розбивати складні завдання на менші, більш керовані підзадачі.

Використання переваг спеціалізації
Однією з ключових переваг використання crewAI у вашому технологічному стеку LLM є його здатність використовувати переваги спеціалізації. Призначаючи конкретні ролі та завдання різним агентам, ви можете створити систему, яка буде більш ефективною та результативною, ніж єдина монолітна модель штучного інтелекту. Кожен агент може бути навчений і оптимізований для виконання конкретного завдання, що дозволить йому працювати на більш високому рівні, ніж модель загального призначення, і дасть змогу більш цілеспрямовано отримувати контекстні дані з ваших наборів даних, специфічних для конкретної галузі.
Використання crewAI у поєднанні з іншими компонентами вашого технологічного стеку допоможе вам відкрити нові можливості для побудови інтелектуальних мультиагентних систем, здатних вирішувати складні завдання реального світу. Використовуючи переваги спеціалізації та співпраці, ви можете створювати додатки, які є більш ефективними, результативними та зручними для користувача, ніж традиційні одномодельні підходи.
Розкриваючи можливості LLM за допомогою правильного стеку додатків
Цей стек дозволяє безперешкодно інтегрувати специфічні для домену дані, забезпечувати ефективний пошук контекстної інформації та будувати складні робочі процеси, здатні вирішувати складні реальні проблеми. Використовуючи можливості цих інструментів і фреймворків, ви можете розширити межі можливого за допомогою мовних програм штучного інтелекту і створити по-справжньому інтелектуальні системи, які трансформують спосіб взаємодії вашого підприємства з даними і технологіями.
5 найкращих стратегій інтеграції LLM API для вашого підприємства
Цього тижня ми також розглянули 5 найкращих стратегій інтеграції LLM API для вашого підприємства.
Від модульної інтеграції до постійного моніторингу та оптимізації - ці стратегії покликані забезпечити безперебійне впровадження, оптимальну продуктивність і довгостроковий успіх.
Модульна інтеграція передбачає розбиття процесу інтеграції LLM API на менші, керовані модулі, які можна впроваджувати поетапно. Такий підхід забезпечує поетапне впровадження, полегшує пошук і усунення несправностей, а також більш гнучке оновлення та вдосконалення.
An API-шлюз діє як єдина точка входу для всіх запитів API, керуючи автентифікацією, обмеженням швидкості та маршрутизацією запитів. Він забезпечує централізовану автентифікацію, обмеження швидкості та надає цінну інформацію про використання та продуктивність API.
Архітектура мікросервісів передбачає розбиття монолітного додатку на менші, слабко пов'язані між собою сервіси, які можна розробляти, розгортати та масштабувати незалежно. Це забезпечує незалежну розробку, гранульовану масштабованість та підвищену гнучкість і маневреність.
Налаштування та тонке налаштування LLM API передбачає їхню адаптацію до вимог конкретної галузі, предметної області або програми. Це підвищує точність, релевантність результатів і дозволяє узгодити їх з термінологією, стилями та форматами.
Постійний моніторинг та оптимізація включають відстеження показників ефективності, оцінку якості/релевантності вихідних даних та ітеративні покращення. Це дозволяє проактивно виявляти проблеми, адаптуватися до мінливих вимог і постійно підвищувати цінність інтеграції з LLM API.
Оскільки сфера технологій LLM продовжує розвиватися швидкими темпами, підприємства, які інвестують у надійні, масштабовані та адаптовані стратегії інтеграції, матимуть хороші можливості для розкриття повного потенціалу цих трансформаційних інструментів.
5 найкращих LLM з відкритим кодом для вашого підприємства
Великі мовні моделі з відкритим вихідним кодом (LLM) з'явилися як потужний інструмент для підприємств у 2024 році.
Однією з ключових переваг використання LLM з відкритим кодом є гнучкість і можливість кастомізації, які вони пропонують. Крім того, LLM з відкритим кодом є економічно вигідною альтернативою розробці та підтримці пропрієтарних моделей. Використовуючи колективні зусилля спільноти розробників ШІ, підприємства можуть отримати доступ до найсучасніших мовних моделей без необхідності значних інвестицій у дослідження та розробку.
Llama 3 від Meta: Llama 3 - це передова велика мовна модель з відкритим вихідним кодом, що має два варіанти розміру (параметри 8B і 70B), кожен з яких пропонує моделі Base та Instruct. Вона чудово справляється з різними завданнями НЛП, зручна для розгортання та дотримується відповідальних практик ШІ.
Claude 3 від Anthropic: Claude 3 доступний у трьох варіантах (Haiku, Sonnet, Opus), оптимізованих для різних випадків використання. Він демонструє вражаючу продуктивність у таких когнітивних завданнях, як міркування, експертні знання та вільне володіння мовою, перевершуючи такі моделі, як GPT-4.
Grok by xAI: Grok, розроблений xAI Ілона Маска, спеціалізується на узагальненні та розумінні тексту. Його остання версія, Grok-1.5, впроваджує розуміння довгого контексту, розширені міркування та потужні можливості кодування/математики.
BERT від Google: BERT став піонером двонаправленого розуміння мови і чудово справляється з такими завданнями, як класифікація текстів, аналіз настроїв і відповіді на запитання. Його попереднє навчання дозволяє йому генерувати текст, схожий на людський, і надавати контекстно-релевантні відповіді.
Mistral Large від Mistral AI: Mistral Large, з параметрами 314B, чудово справляється зі складними міркуваннями та спеціалізованими програмами. Він пропонує багатомовну підтримку, можливість слідування інструкціям і виклику функцій, що підвищує його універсальність.
Оскільки спільнота розробників ШІ з відкритим вихідним кодом продовжує розширювати межі можливого за допомогою мовних моделей, підприємства, які використовують ці потужні інструменти, матимуть всі шанси випередити час і досягти довгострокового успіху.
Щоб отримати ще більше матеріалів про корпоративний ШІ, включаючи інфографіку, статистику, інструкції, статті та відео, підписуйтесь на канал Skim AI на LinkedIn
Ви засновник, генеральний директор, венчурний інвестор або інвестор, який шукає експертні консультації з питань АІ або юридичну експертизу? Отримайте рекомендації, необхідні для прийняття обґрунтованих рішень щодо продуктової стратегії або інвестиційних можливостей вашої компанії у сфері ШІ.
Ми створюємо індивідуальні AI-рішення для компаній, що підтримуються венчурним та приватним капіталом, у наступних галузях: Медичні технології, новини/контент-агрегація, кіно- та фото-виробництво, освітні технології, юридичні технології, фінтех та криптовалюта.


