
LLM з кількома підказками та точним налаштуванням для генеративних рішень у сфері штучного інтелекту



Справжній потенціал великих мовних моделей (ВММ) полягає не лише в їхній величезній базі знань, а й у здатності адаптуватися до конкретних завдань і сфер з мінімальним додатковим навчанням. Саме тут у гру вступають концепції підказок і точного налаштування, які покращують те, як ми використовуємо можливості БММ у реальних сценаріях.
Хоча LLM навчаються на величезних масивах даних, що охоплюють широкий спектр знань, вони часто стикаються з вузькоспеціалізованими завданнями або специфічним жаргоном. Традиційні підходи керованого навчання вимагають великих обсягів маркованих даних для адаптації цих моделей, що часто є непрактичним або неможливим у багатьох реальних ситуаціях. Ця проблема спонукала дослідників і практиків досліджувати більш ефективні методи адаптації LLM до конкретних випадків використання, використовуючи лише невелику кількість прикладів.
Короткий огляд підказок і тонких налаштувань для малої кількості пострілів
Існує два потужних методи вирішення цієї проблеми: підказки з кількох спроб і точне налаштування. Підказки з кількох спроб передбачають створення розумних підказок, що містять невелику кількість прикладів, які спрямовують модель на виконання конкретного завдання без додаткового навчання. Точне налаштування, з іншого боку, передбачає оновлення параметрів моделі з використанням обмеженої кількості даних для конкретного завдання, що дозволяє їй адаптувати свої величезні знання до конкретної області або програми.
Обидва підходи підпадають під парасольку навчання з кількох спроб - парадигми, яка дозволяє моделям вивчати нові завдання або адаптуватися до нових сфер, використовуючи лише кілька прикладів. Використовуючи ці методи, ми можемо значно підвищити продуктивність і універсальність LLM, зробивши їх більш практичними та ефективними інструментами для широкого спектру застосувань в обробці природної мови та за її межами.
Підказки з кількох пострілів: Розкриття потенціалу LLM
Підказки з кількох пострілів - це потужна методика, яка дозволяє нам спрямовувати LLM на виконання конкретних завдань або сфер діяльності без необхідності додаткового навчання. Цей метод використовує вроджену здатність моделі розуміти і виконувати інструкції, ефективно "програмуючи" LLM за допомогою ретельно продуманих підказок.
По суті, підказки з кількома пострілами передбачають надання LLM невеликої кількості прикладів (зазвичай 1-5), які демонструють потрібне завдання, після чого вводиться новий вхідний сигнал, на який модель повинна згенерувати відповідь. Цей підхід використовує здатність моделі розпізнавати закономірності та адаптувати свою поведінку на основі наведених прикладів, дозволяючи їй виконувати завдання, для яких вона не була явно навчена.
Ключовий принцип підказок полягає в тому, що, представивши модель з чіткою схемою входів і виходів, ми можемо спрямувати її на застосування аналогічних міркувань до нових, небачених вхідних даних. Ця методика використовує здатність LLM до навчання в контексті, дозволяючи швидко адаптуватися до нових завдань без зміни параметрів моделі.
Типи підказок з кількома пострілами (з нульовим пострілом, з одним пострілом, з кількома пострілами)
Підказки з кількома пострілами охоплюють цілий спектр підходів, кожен з яких визначається кількістю наведених прикладів:
Ніяких підказок: У цьому сценарії приклади не наводяться. Натомість моделі дається чітка інструкція або опис завдання. Наприклад, "Перекладіть наступний англійський текст французькою мовою: [введіть текст]".
Одноразова підказка: Тут наведено один приклад перед фактичними вхідними даними. Це дає моделі конкретний приклад очікуваного зв'язку між вхідними та вихідними даними. Наприклад: "Класифікуйте враження від наступного відгуку як позитивне чи негативне. Приклад: "Цей фільм був фантастичним!" - Позитивний вхід: "Я не витримав сюжету". - [модель генерує відповідь]"
Кілька пострілів підказки: Цей підхід передбачає кілька прикладів (зазвичай 2-5) перед введенням даних. Це дозволяє моделі розпізнавати більш складні патерни та нюанси в задачі. Наприклад: "Класифікуйте наступні речення як питання або твердження: "Небо блакитне". - Твердження "Котра година?" - Питання "Я люблю морозиво". - Вхідне твердження: "Де я можу знайти найближчий ресторан?" - [модель генерує відповідь]".
Створення ефективних коротких підказок
Створення ефективних коротких підказок - це і мистецтво, і наука. Ось кілька ключових принципів, які слід враховувати:
Чіткість і послідовність: Переконайтеся, що ваші приклади та інструкції зрозумілі та відповідають єдиному формату. Це допоможе моделі легше розпізнати шаблон.
Різноманітність: Використовуючи кілька прикладів, намагайтеся охопити діапазон можливих входів і виходів, щоб дати моделі ширше розуміння завдання.
Доречність: Вибирайте приклади, які тісно пов'язані з конкретною задачею або сферою, на яку ви орієнтуєтесь. Це допоможе моделі зосередитися на найбільш релевантних аспектах її знань.
Лаконічність: Хоча важливо надати достатньо контексту, уникайте надто довгих або складних підказок, які можуть заплутати модель або розмити ключову інформацію.
Експеримент: Не бійтеся ітерацій та експериментів з різними підказка структури та приклади, щоб знайти те, що найкраще підходить для вашого конкретного випадку використання.
Оволодівши мистецтвом підказок, ми можемо розкрити весь потенціал LLMs, даючи їм змогу вирішувати широкий спектр завдань з мінімальними додатковими зусиллями чи навчанням.
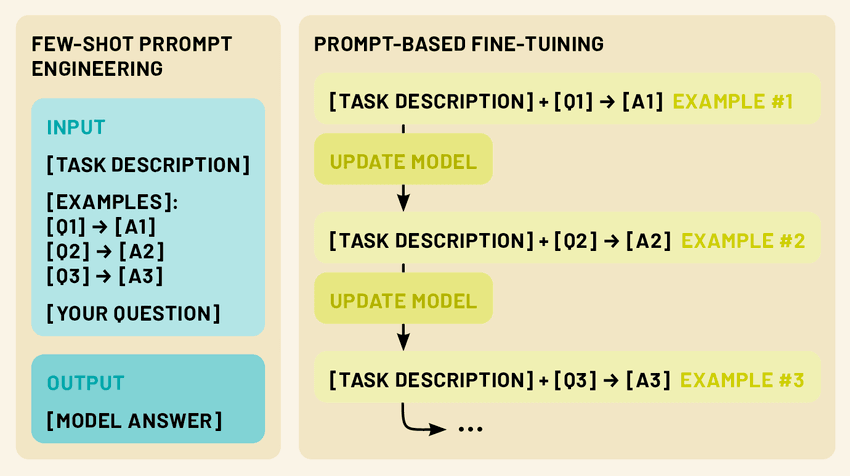
Тонке налаштування LLM: Пристосування моделей з обмеженими даними
У той час як підказки з кількох пострілів є потужним методом адаптації LLM до нових завдань без зміни самої моделі, точне налаштування пропонує спосіб оновити параметри моделі для ще кращої продуктивності на конкретних завданнях або в конкретних сферах. Тонке налаштування дозволяє нам використовувати величезні знання, закодовані в попередньо навчених LLM, пристосовуючи їх до наших конкретних потреб, використовуючи лише невелику кількість специфічних даних про завдання.
Розуміння тонкого налаштування в контексті магістерських програм
Точне налаштування LLM передбачає використання попередньо навченої моделі та подальше її навчання на меншому наборі даних для конкретної задачі. Цей процес дозволяє моделі адаптувати свої вивчені уявлення до нюансів цільової задачі або предметної області. Ключова перевага тонкого налаштування полягає в тому, що воно ґрунтується на багатих знаннях і розумінні мови, вже наявних у попередньо навченій моделі, вимагаючи набагато менше даних і обчислювальних ресурсів, ніж навчання моделі з нуля.
У контексті LLM точне налаштування зазвичай зосереджується на коригуванні вагових коефіцієнтів верхніх шарів мережі, які відповідають за більш специфічні особливості завдання, залишаючи нижні шари (які відображають більш загальні мовні патерни) практично незмінними. Цей підхід, який часто називають "трансферним навчанням", дозволяє моделі зберігати широке розуміння мови, водночас розвиваючи спеціалізовані можливості для виконання цільового завдання.
Кілька методів точного налаштування
Малопострільна точна настройка просуває концепцію точної настройки на крок далі, намагаючись адаптувати модель, використовуючи лише дуже невелику кількість прикладів - зазвичай в діапазоні від 10 до 100 прикладів на клас або задачу. Цей підхід є особливо цінним, коли мічених даних для цільової задачі не вистачає або їх отримання є дорогим. Деякі ключові методи тонкого налаштування з невеликою кількістю прикладів включають
Оперативне доопрацювання: Цей метод поєднує в собі ідеї підказок з оновленням параметрів. Модель налаштовується на невеликому наборі даних, де кожен приклад відформатовано у вигляді пари "підказка - завершення", подібно до підказок з кількома пострілами.
Підходи до метанавчання: Такі техніки, як Модельно-агностичне метанавчання (MAML) можуть бути адаптовані для тонкого налаштування МНК за кілька пострілів. Ці методи спрямовані на пошук гарної точки ініціалізації, яка дозволяє моделі швидко адаптуватися до нових завдань з мінімальними даними.
Тонке налаштування на основі адаптера: Замість того, щоб оновлювати всі параметри моделі, цей підхід вводить невеликі модулі-адаптери між шарами попередньо навченої моделі. Тільки ці адаптери навчаються на новому завданні, зменшуючи кількість параметрів, що підлягають навчанню, і ризик катастрофічного забування.
Контекстне навчання: Деякі нещодавні підходи намагаються доопрацювати LLM для кращого навчання в контексті, підвищуючи їхню здатність адаптуватися до нових завдань за допомогою одних лише підказок.
Кілька пострілів проти точного налаштування: Вибір правильного підходу
При адаптації LLM до конкретних завдань ефективними рішеннями можуть бути як підказки, так і точне налаштування. Однак кожен метод має свої сильні та слабкі сторони, і вибір правильного підходу залежить від різних факторів.
Сильні та слабкі сторони кожного методу
Невелика кількість пострілів: Сильні сторони:
Не потребує оновлення параметрів моделі, зберігаючи оригінальну модель
Висока гнучкість і можливість адаптації на льоту
Не потребує додаткового часу на навчання або обчислювальних ресурсів
Корисно для швидкого створення прототипів та експериментів
Обмеження:
Продуктивність може бути менш стабільною, особливо для складних завдань
Обмежені початковими можливостями та знаннями моделі
Можуть виникати проблеми з вузькоспеціалізованими доменами або завданнями
Доопрацювання: Сильні сторони:
Часто досягає кращих результатів у виконанні конкретних завдань
Може адаптувати модель до нових доменів та спеціалізованої лексики
Більш узгоджені результати за однакових вхідних даних
Потенціал для постійного навчання та вдосконалення
Обмеження:
Потребує додаткового навчального часу та обчислювальних ресурсів
Ризик катастрофічного забування, якщо ним не керувати
Можливе перевантаження на невеликих наборах даних
Менш гнучкий; вимагає перенавчання при значних змінах завдань
Фактори, які слід враховувати при виборі методу
Існує кілька факторів, які слід враховувати при виборі методу:
Доступність даних: Якщо у вас є невелика кількість високоякісних, специфічних для завдання даних, то краще скористатися тонким налаштуванням. Для завдань з дуже обмеженою кількістю специфічних даних або взагалі без них, кращим вибором може бути підказка з кількома знімками.
Складність завдання: Прості завдання, близькі до області попереднього навчання моделі, можуть добре працювати з невеликою кількістю підказок. Більш складні або спеціалізовані завдання часто виграють від точного налаштування.
Обмеженість ресурсів: Враховуйте доступні обчислювальні ресурси та часові обмеження. Підказки з кількома кадрами, як правило, швидші та менш ресурсомісткі.
Вимоги до гнучкості: Якщо вам потрібно швидко адаптуватися до різних завдань або часто змінювати свій підхід, підказки з кількома кадрами забезпечують більшу гнучкість.
Вимоги до виконання: Для додатків, що вимагають високої точності та узгодженості, точне налаштування часто дає кращі результати, особливо за наявності достатньої кількості даних для конкретної задачі.
Конфіденційність і безпека: Якщо ви працюєте з чутливими даними, краще використовувати підказки з кількома пострілами, оскільки вони не вимагають обміну даними для оновлення моделі.
Практичне застосування методів малої кількості кадрів для магістрів права
Малопоширені методи навчання відкрили широкий спектр застосувань для LLM у різних галузях, дозволяючи цим моделям швидко адаптуватися до конкретних завдань за допомогою мінімальної кількості прикладів.
Завдання з обробки природної мови:
Класифікація текстів: Методи з кількома прикладами дозволяють LLM класифікувати текст на заздалегідь визначені класи з кількома прикладами на кожну категорію. Це корисно для тегування контенту, виявлення спаму та моделювання тем.
Аналіз настроїв: Магістри можуть швидко адаптуватися до завдань аналізу настроїв у конкретній галузі, розуміючи нюанси вираження настроїв у різних контекстах.
Розпізнавання іменованих об'єктів (NER): Навчання з кількох пострілів дозволяє магістрам права ідентифікувати та класифікувати іменовані об'єкти у спеціалізованих галузях, наприклад, ідентифікувати хімічні сполуки в науковій літературі.
Відповідаю на питання: Магістрів права можна адаптувати для відповідей на питання в певних сферах або форматах, що підвищує їхню корисність в обслуговуванні клієнтів та інформаційно-пошукових системах.
Адаптації для конкретних доменів:
Легально: Нескладні методики дозволяють магістрам права розуміти та створювати юридичні документи, класифікувати юридичні справи та витягувати відповідну інформацію з контрактів з мінімальною підготовкою в конкретній галузі.
Медичний: LLM можна адаптувати до таких завдань, як узагальнення медичних звітів, класифікація хвороб за симптомами та прогнозування взаємодії лікарських засобів, використовуючи лише невелику кількість медичних прикладів.
Технічний: У таких галузях, як інженерія чи комп'ютерні науки, навчання з кількома пострілами дозволяє магістрам розуміти і створювати спеціалізований технічний контент, налагоджувати код або пояснювати складні концепції, використовуючи специфічну термінологію галузі.
Багатомовні та міжмовні додатки:
Переклад з малоресурсних мов: Малопоширені методи можуть допомогти магістрам іноземних мов виконувати перекладацькі завдання для мов з обмеженим обсягом даних.
Міжмовний переклад: Моделі, навчені на мовах з високим рівнем ресурсів, можуть бути адаптовані для виконання завдань на мовах з низьким рівнем ресурсів за допомогою навчання з кількох пострілів.
Багатомовна адаптація завдань: Магістри можуть швидко адаптуватися до виконання одного й того ж завдання кількома мовами, маючи лише кілька прикладів на кожній мові.
Виклики та обмеження малопотужних методів зйомки
Хоча малопоширені методи для LLM пропонують величезний потенціал, вони також мають ряд проблем і обмежень, які необхідно вирішити.
Проблеми узгодженості та надійності:
Варіативність продуктивності: Методи з кількома пострілами іноді можуть давати непослідовні результати, особливо в складних завданнях або крайніх випадках.
Швидка чутливість: Невеликі зміни у формулюванні підказок або виборі прикладів можуть призвести до значних відмінностей у якості результатів.
Обмеження, пов'язані з конкретними завданнями: Деякі завдання можуть бути складними за своєю суттю, і їх важко вивчити на кількох прикладах, що призводить до неоптимальної продуктивності.
Етичні міркування та упередження:
Посилення упереджень: Навчання з кількох спроб може посилити упередження, наявні в обмежених прикладах, що потенційно може призвести до несправедливих або дискримінаційних результатів.
Відсутність надійності: Моделі, адаптовані за допомогою методів з кількома пострілами, можуть бути більш сприйнятливими до атак супротивника або несподіваних вхідних даних.
Прозорість і зрозумілість: Зрозуміти і пояснити, як модель приходить до своїх висновків у сценаріях з кількома пострілами, може бути складно.
Обчислювальні ресурси та ефективність:
Обмеження на розмір моделі: Оскільки LLM стають більшими, обчислювальні вимоги для точного налаштування стають дедалі складнішими, що потенційно обмежує їхню доступність.
Час для висновків: Складні підказки з кількома кадрами можуть збільшити час виведення, що потенційно може вплинути на роботу додатків у реальному часі.
Споживання енергії: Обчислювальні ресурси, необхідні для широкомасштабного розгортання малопотужних технологій, викликають занепокоєння щодо енергоефективності та впливу на навколишнє середовище.
Подолання цих викликів і обмежень має вирішальне значення для подальшого розвитку і відповідального застосування методів навчання з невеликою кількістю пострілів на магістерських програмах. З розвитком досліджень ми можемо очікувати на появу інноваційних рішень, які підвищать надійність, справедливість та ефективність цих потужних методів.
Підсумок
Підказки та точне налаштування є революційними підходами, що дозволяють LLM швидко адаптуватися до спеціалізованих завдань з мінімальним обсягом даних. Як ми дослідили, ці методи пропонують безпрецедентну гнучкість і ефективність у пристосуванні LLM до різноманітних застосувань у різних галузях, від покращення завдань з обробки природної мови до адаптації до специфічних доменів у таких сферах, як охорона здоров'я, право та технології.
Незважаючи на те, що проблеми залишаються, особливо щодо послідовності, етичних міркувань та обчислювальної ефективності, потенціал навчання з кількох спроб на магістерських рівнях не викликає сумнівів. Оскільки дослідження продовжують розвиватися, усуваючи поточні обмеження та відкриваючи нові стратегії оптимізації, ми можемо очікувати ще більш потужного та універсального застосування цих методів. Майбутнє штучного інтелекту полягає не лише у великих моделях, але й у розумніших, більш адаптивних моделях - і навчання з кількох спроб прокладає шлях до нової ери інтелектуальних, ефективних і вузькоспеціалізованих мовних моделей, які можуть по-справжньому розуміти і відповідати нашим потребам, що постійно змінюються.


