
Нам потрібно переосмислити ланцюжок думок (CoT), що підказує AI&YOU #68



Статистика тижня: Zero-shot CoT performance was only 5.55% for GPT-4-Turbo, 8.51% for Claude-3-Opus, and 4.44% for GPT-4. (“Chain of Thoughtlessness?” paper)
Chain-of-Thought (CoT) prompting has been hailed as a breakthrough in unlocking the reasoning capabilities of large language models (LLMs). However, recent research has challenged these claims and prompted us to revisit the technique.
У цьому випуску AI&YOU ми ділимося думками з трьох блогів, які ми опублікували на цю тему:
We need to rethink chain-of-thought (CoT) prompting AI&YOU #68
LLMs demonstrate remarkable capabilities in natural language processing (NLP) and generation. However, when faced with complex reasoning tasks, these models can struggle to produce accurate and reliable results. This is where Chain-of-Thought (CoT) prompting comes into play, a technique that aims to enhance the problem-solving abilities of LLMs.
An advanced оперативний інжиніринг technique, it is designed to guide LLMs through a step-by-step reasoning process. Unlike standard prompting methods that aim for direct answers, CoT prompting encourages the model to generate intermediate reasoning steps before arriving at a final answer.
At its core, CoT prompting involves structuring input prompts in a way that elicits a logical sequence of thoughts from the model. By breaking down complex problems into smaller, manageable steps, CoT attempts to enable LLMs to navigate through intricate reasoning paths more effectively.
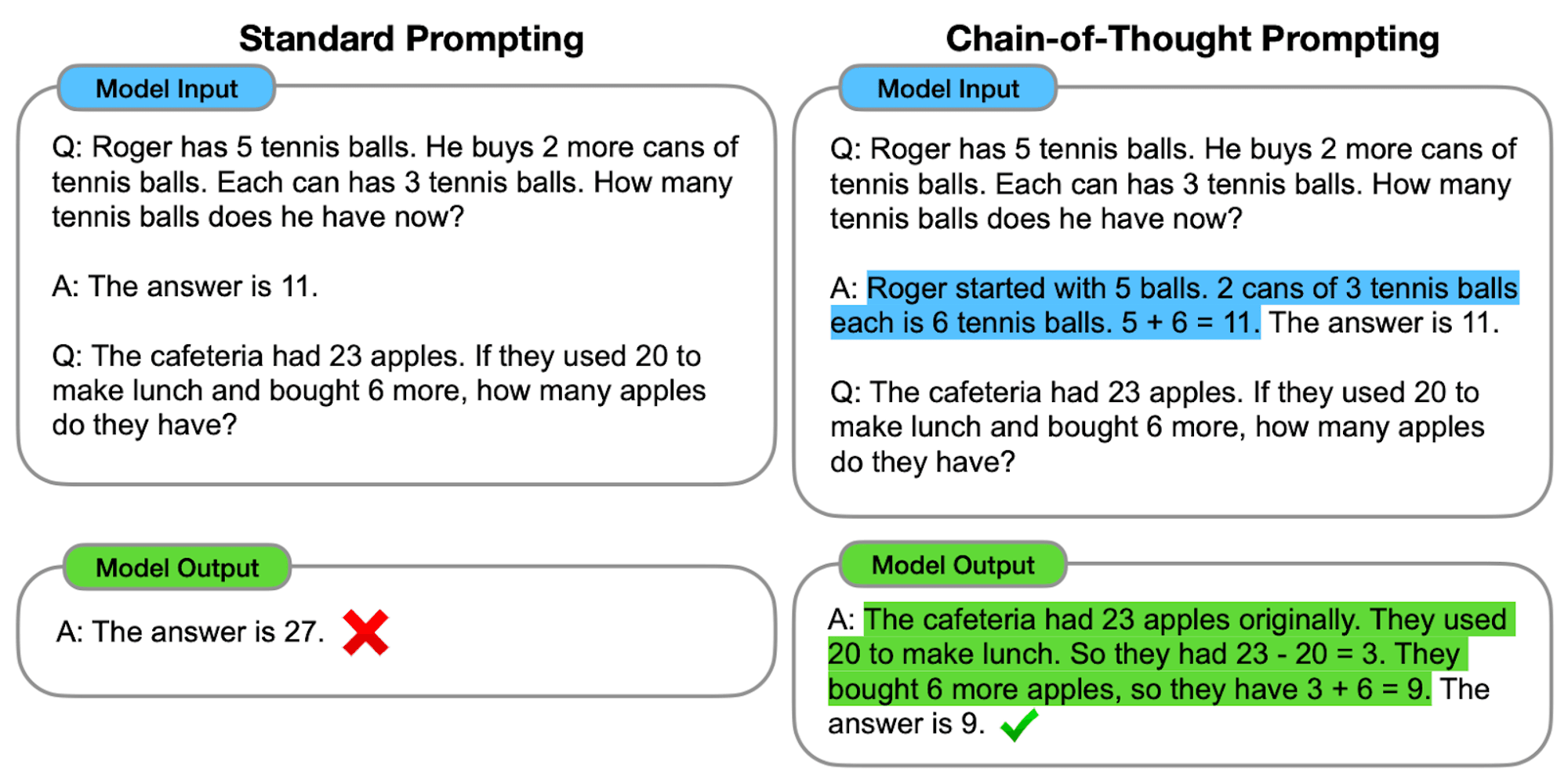
Як працює CoT
По суті, підказка CoT спрямовує мовні моделі через низку проміжних кроків міркувань до отримання остаточної відповіді. Цей процес зазвичай включає в себе
Декомпозиція проблеми: Складне завдання розбивається на менші, керовані кроки.
Покрокові міркування: Модель спонукає чітко продумувати кожен крок.
Логічний розвиток: Кожен крок спирається на попередній, створюючи ланцюжок думок.
Висновки: Остаточна відповідь виводиться з накопичених кроків міркувань.
Типи підказок CoT
Підказка "ланцюжок думок" може бути реалізована різними способами, серед яких можна виділити два основних типи:
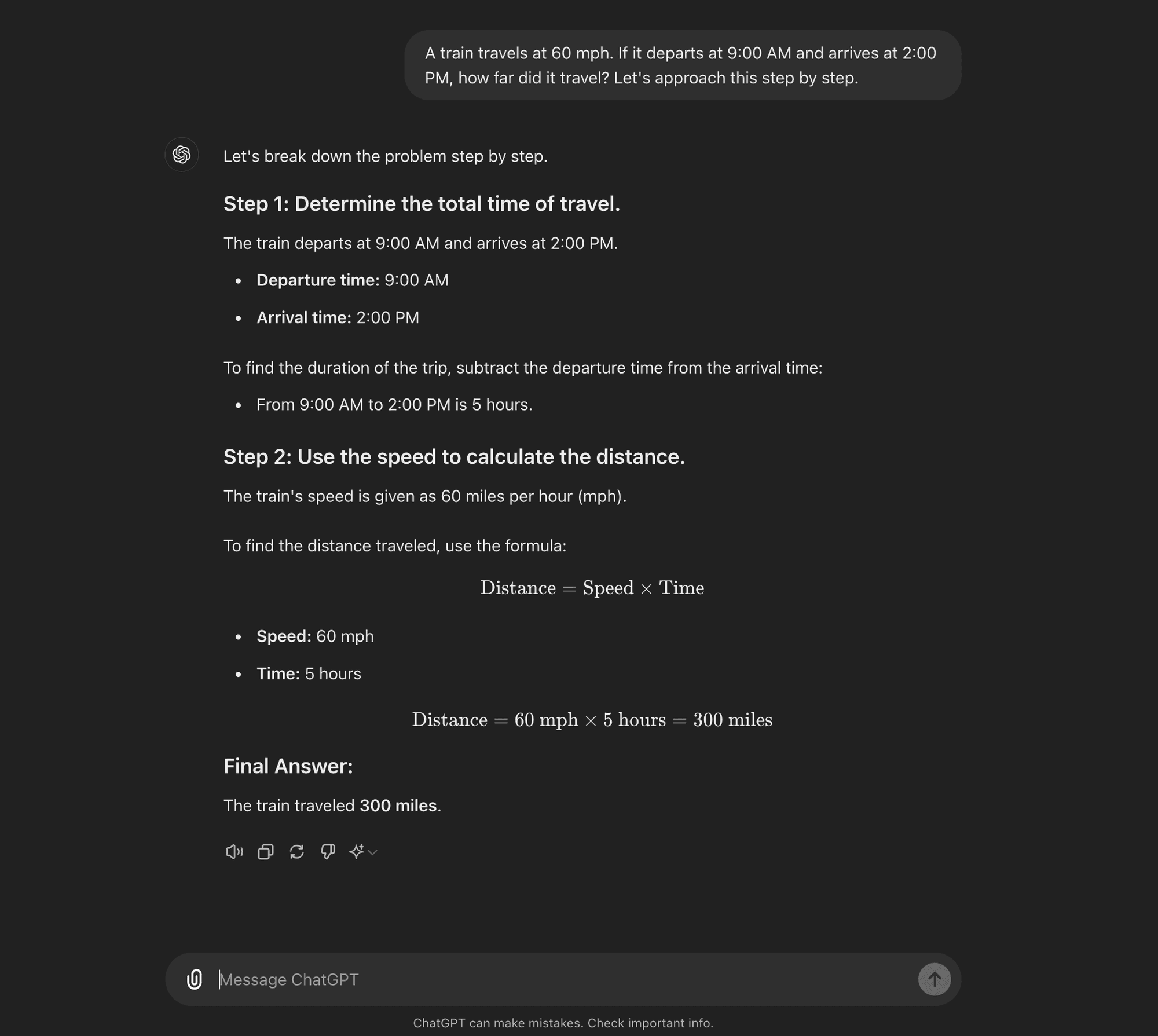
Zero-shot CoT: Zero-shot CoT doesn’t require task-specific examples. Instead, it uses a simple prompt like “Let’s approach this step by step” to encourage the model to break down its reasoning process.****
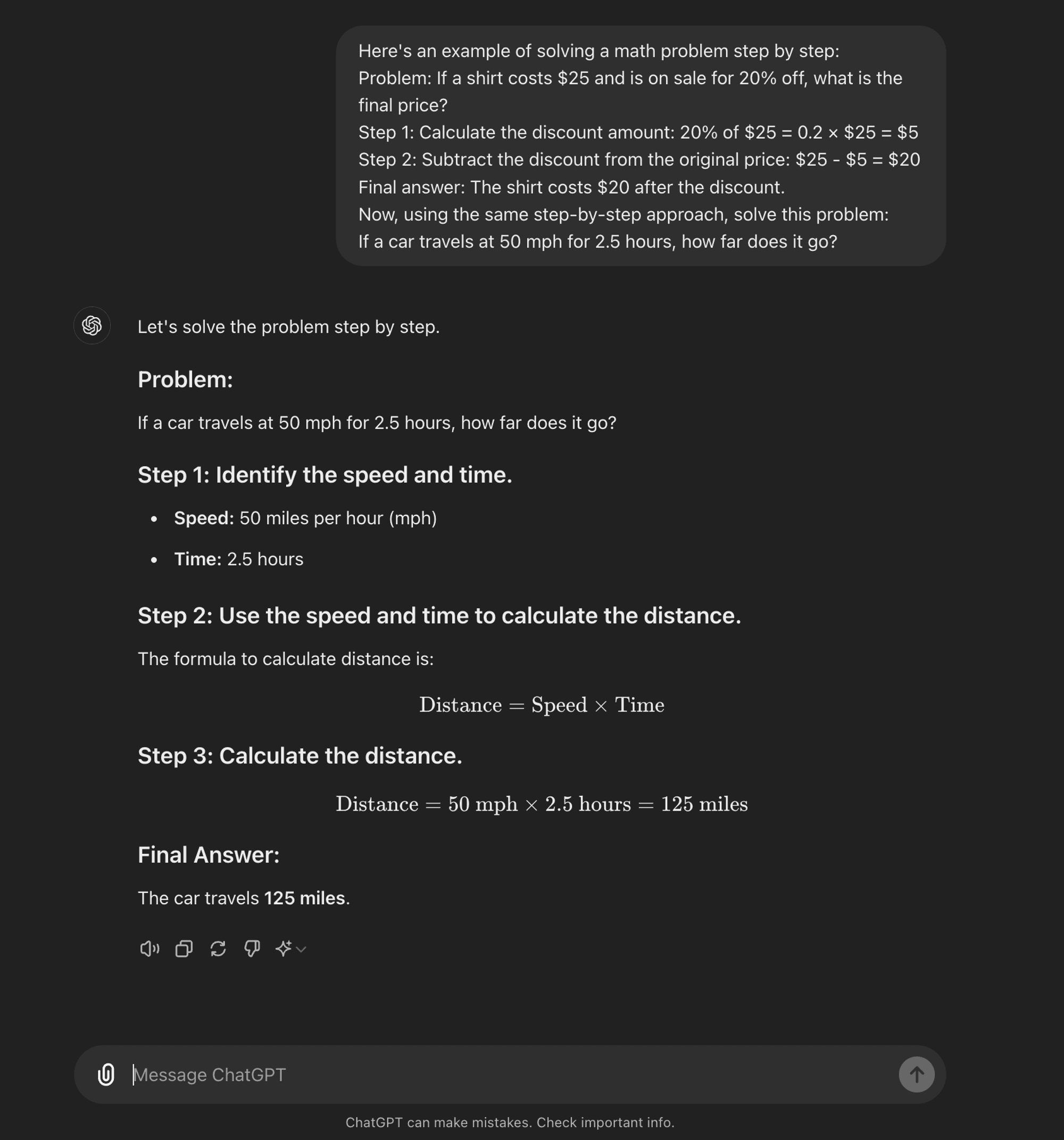
Few-shot CoT: Малопоширений метод передбачає надання моделі невеликої кількості прикладів, які демонструють бажаний процес міркувань. Ці приклади слугують шаблоном для моделі, якому вона має слідувати при вирішенні нових, непередбачуваних проблем.
Zero-shot CoT
Few-shot CoT
AI Research Paper Breakdown: “Chain of Thoughtlessness?”
Now that you know what CoT prompting is, we can dive into some recent research that challenges some of its benefits and offers some insight into when it is actually useful.
The research paper, titled “Chain of Thoughtlessness? An Analysis of CoT in Planning,” provides a critical examination of CoT prompting’s effectiveness and generalizability. As AI practitioners, it’s crucial to understand these findings and their implications for developing AI applications that require sophisticated reasoning capabilities.

Дослідники обрали класичний домен планування під назвою Blocksworld як основний полігон для тестування. У Blocksworld завдання полягає в тому, щоб переставити набір блоків з початкової конфігурації в цільову за допомогою серії дій переміщення. Цей домен ідеально підходить для тестування міркувань та можливостей планування, тому що:
Дозволяє генерувати завдання різної складності
Вона має чіткі, алгоритмічно верифіковані рішення
Навряд чи він буде широко представлений у навчальних даних LLM
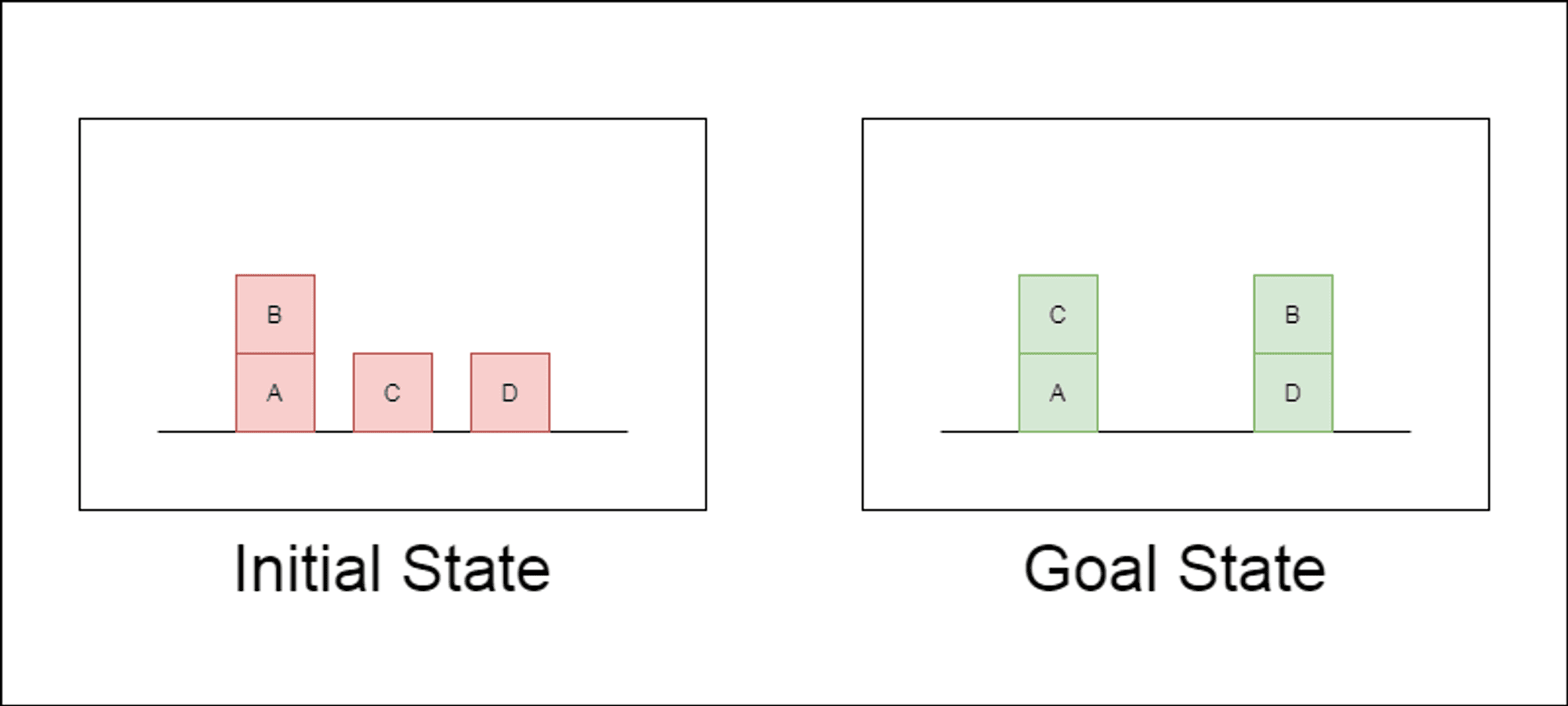
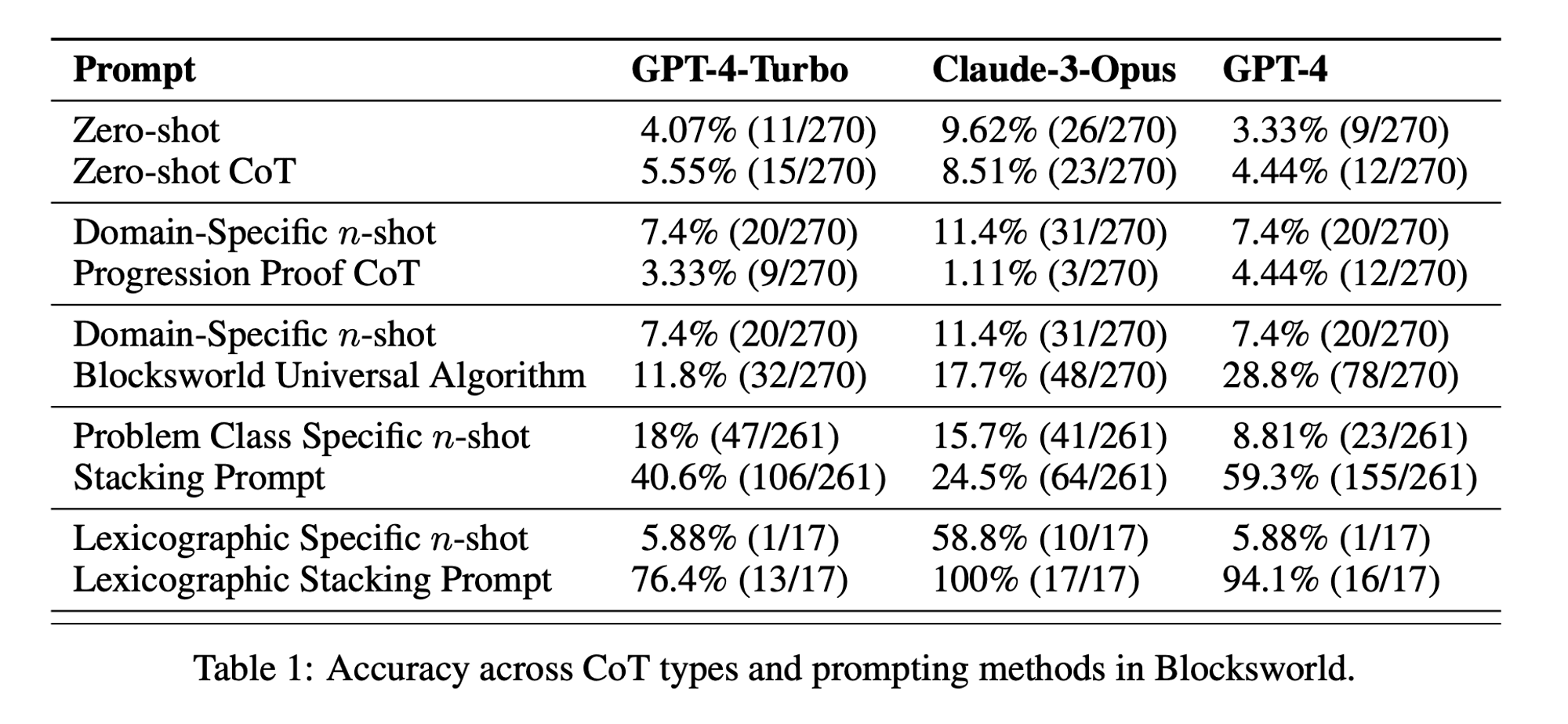
У дослідженні розглядалися три найсучасніші LLM: GPT-4, Claude-3-Opus та GPT-4-Turbo. Ці моделі були протестовані з використанням підказок різної специфічності:
Ланцюг думок з нульовим пострілом (універсальний): Просто додайте до підказки "давайте поміркуємо крок за кроком".
Доказ прогресування (специфічний для PDDL): Надання загального пояснення правильності плану з прикладами.
Універсальний алгоритм Blocksworld: Демонстрація загального алгоритму розв'язання будь-якої задачі на Blocksworld.
Підказка по укладанню: Зосередження на конкретному підкласі проблем Blocksworld (table-to-stack).
Лексикографічне укладання: Подальше звуження до конкретної синтаксичної форми стану мети.
Тестуючи ці підказки на проблемах зростаючої складності, дослідники мали на меті оцінити, наскільки добре магістри права можуть узагальнювати міркування, продемонстровані в прикладах.
Оприлюднено ключові висновки
Результати цього дослідження ставлять під сумнів багато поширених припущень щодо спонукання до застосування ЗПТ:
Обмежена ефективність ЗПТ: Всупереч попереднім заявам, підказки CoT показали значне покращення продуктивності лише тоді, коли наведені приклади були надзвичайно схожими на проблему запиту. Як тільки проблеми відхилялися від точного формату, показаного в прикладах, продуктивність різко падала.
Швидка деградація продуктивності: Зі збільшенням складності завдань (вимірюваної кількістю задіяних блоків) точність усіх моделей різко знижувалася, незалежно від використовуваної підказки CoT. Це свідчить про те, що LLMs намагаються поширити міркування, продемонстровані в простих прикладах, на більш складні сценарії.
Неефективність загальних підказок: Дивно, але більш загальні підказки CoT часто показували гірші результати, ніж стандартні підказки без прикладів міркувань. Це суперечить ідеї, що CoT допомагає магістрам вивчити узагальнені стратегії розв'язання проблем.
Компроміс специфічності: Дослідження показало, що вузькоспецифічні підказки можуть забезпечити високу точність, але лише для дуже вузької підгрупи проблем. Це підкреслює гострий компроміс між підвищенням продуктивності та застосовністю підказки.
Відсутність справжнього алгоритмічного навчання: Результати переконливо свідчать про те, що LLMs не вчаться застосовувати загальні алгоритмічні процедури на прикладах CoT. Замість цього вони, здається, покладаються на зіставлення шаблонів, яке швидко ламається, коли стикаються з новими або більш складними проблемами.
Ці висновки мають важливе значення для фахівців у галузі ШІ та підприємств, які прагнуть використовувати підказки CoT у своїх додатках. Вони свідчать про те, що хоча CoT може підвищити продуктивність у певних вузьких сценаріях, він не може бути панацеєю для складних завдань, пов'язаних з міркуваннями, на яку багато хто сподівався.
Наслідки для розвитку штучного інтелекту
Висновки цього дослідження мають важливе значення для розвитку ШІ, особливо для підприємств, які працюють над додатками, що вимагають складних міркувань або можливостей планування:
Переоцінка ефективності CoT: AI developers should be cautious about relying on CoT for tasks that require true algorithmic thinking or generalization to novel scenarios.
Обмеження нинішніх магістерських програм: Alternative approaches may be necessary for applications requiring robust planning or multi-step problem-solving.
Вартість оперативного інжинірингу: Хоча вузькоспецифічні підказки CoT можуть давати хороші результати для вузького кола проблем, людські зусилля, необхідні для створення цих підказок, можуть переважати переваги, особливо з огляду на їхню обмежену узагальнюваність.
Переосмислення оціночних показників: Relying solely on static test sets may overestimate a model’s true reasoning capabilities.
Розрив між сприйняттям і реальністю: Існує значна розбіжність між уявленнями про розумові здібності магістрів права (які часто антропоморфізуються в популярному дискурсі) та їхніми реальними можливостями, як продемонстровано в цьому дослідженні.
Recommendations for AI Practitioners:
Оцінка: Implement diverse testing frameworks to assess true generalization across problem complexities.
CoT Usage: Apply Chain-of-Thought prompting judiciously, recognizing its limitations in generalization.
Hybrid Solutions: Consider combining LLMs with traditional algorithms for complex reasoning tasks.
Transparency: Clearly communicate AI system limitations, especially for reasoning or planning tasks.
R&D Focus: Invest in research to enhance true reasoning capabilities of AI systems.
Налагоджую: Consider domain-specific fine-tuning, but be aware of potential generalization limits.
For AI practitioners and enterprises, these findings highlight the importance of combining LLM strengths with specialized reasoning approaches, investing in domain-specific solutions where necessary, and maintaining transparency about AI system limitations. As we move forward, the AI community must focus on developing new architectures and training methods that can bridge the gap between pattern matching and true algorithmic reasoning.
10 Best Prompting Techniques for LLMs
This week, we also explore ten of the most powerful and common prompting techniques, offering insights into their applications and best practices.

Well-designed prompts can significantly enhance an LLM’s performance, enabling more accurate, relevant, and creative outputs. Whether you’re a seasoned AI developer or just starting with LLMs, these techniques will help you unlock the full potential of AI models.
Make sure to check out the full blog to learn more about each one.
Дякуємо, що знайшли час прочитати AI & YOU!
Щоб отримати ще більше матеріалів про корпоративний ШІ, включаючи інфографіку, статистику, інструкції, статті та відео, підписуйтесь на канал Skim AI на LinkedIn
Ви засновник, генеральний директор, венчурний інвестор або інвестор, який шукає консультації з питань ШІ, фракційної розробки ШІ або послуги Due Diligence? Отримайте рекомендації, необхідні для прийняття обґрунтованих рішень щодо продуктової стратегії та інвестиційних можливостей вашої компанії у сфері ШІ.
Ми створюємо індивідуальні AI-рішення для компаній, що підтримуються венчурним та приватним капіталом, у наступних галузях: Медичні технології, новини/контент-агрегація, кіно- та фото-виробництво, освітні технології, юридичні технології, фінтех та криптовалюта.


