
Llama 3.1 проти пропрієтарних LLM: Аналіз витрат і вигод для підприємств



Ландшафт великих мовних моделей (LLM) став полем битви між такими моделями з відкритою вагою, як Meta's Llama 3.1 та власні пропозиції від технологічних гігантів, таких як OpenAI. Оскільки підприємства орієнтуються в цьому складному середовищі, рішення про вибір між відкритою моделлю та інвестиціями в рішення з закритим кодом має значні наслідки для інновацій, витрат і довгострокової стратегії ШІ.
Llama 3.1, особливо його грізний варіант з параметрами 405B, став сильним конкурентом провідним моделям з закритим вихідним кодом, таким як GPT-4o і Claude 3.5. Цей зсув змусив підприємства переглянути свій підхід до впровадження ШІ, враховуючи фактори, що виходять за рамки простих показників продуктивності.
У цьому аналізі ми зануримося в компроміси між вартістю та вигодами між Llama 3.1 і власними LLM, надаючи керівникам підприємств всебічну основу для прийняття обґрунтованого рішення щодо інвестицій у ШІ.
Порівняння витрат
Ліцензійні платежі: Пропрієтарні та відкриті моделі
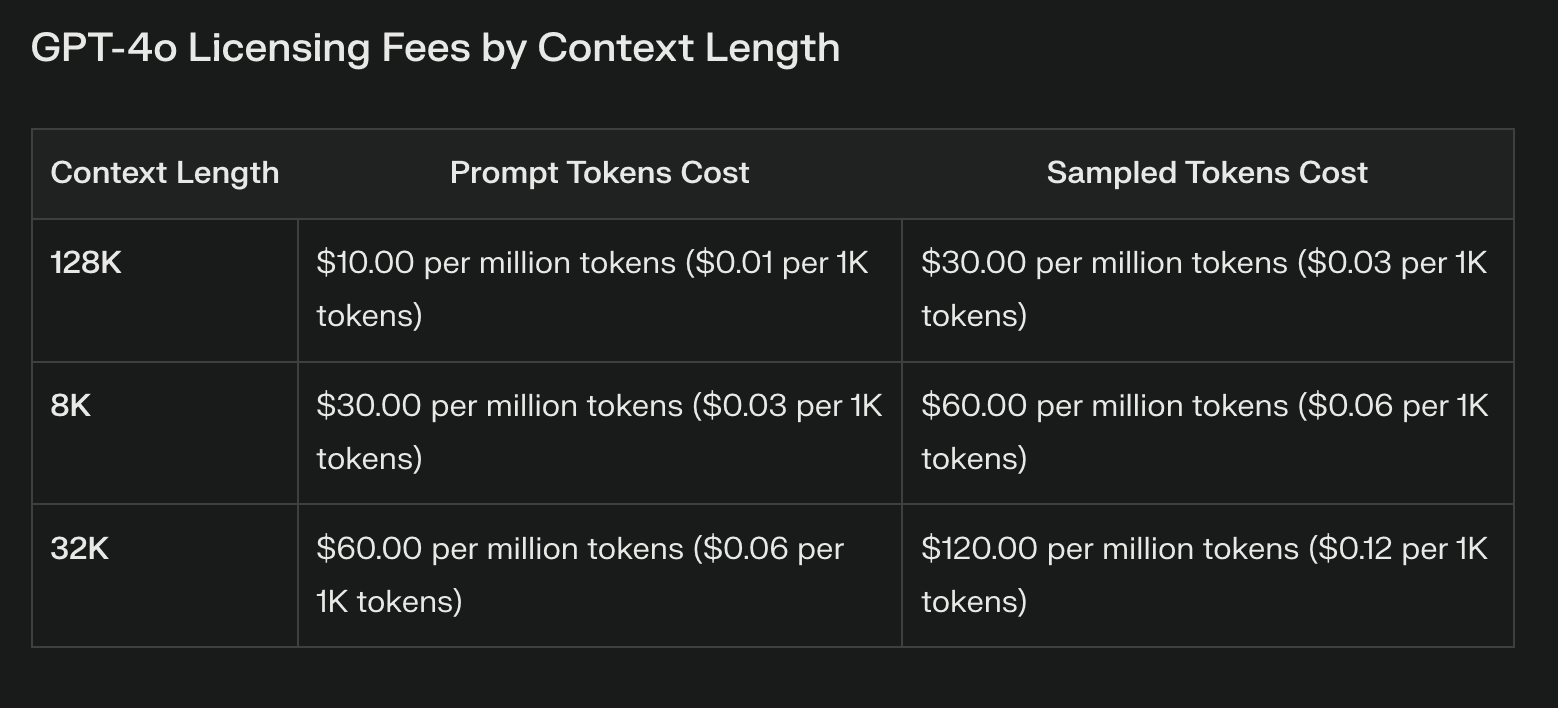
Найбільш очевидна різниця у вартості між Llama 3.1 та пропрієтарними моделями полягає у ліцензійних платежах. Пропрієтарні LLM часто пов'язані зі значними поточними витратами, які можуть значно зростати з використанням. Ці платежі, хоча й надають доступ до передових технологій, можуть обтяжувати бюджет і обмежувати експерименти.
Llama 3.1 з відкритими вагами повністю скасовує ліцензійні платежі. Така економія може бути суттєвою, особливо для підприємств, які планують масштабне розгортання ШІ. Однак важливо зазначити, що відсутність ліцензійних платежів не дорівнює нульовим витратам.
Витрати на інфраструктуру та розгортання
Хоча Llama 3.1 може заощадити на ліцензуванні, вона вимагає значних обчислювальних ресурсів, особливо для моделі параметрів 405B. Підприємства повинні інвестувати в надійну апаратну інфраструктуру, яка часто включає кластери GPU високого класу або ресурси хмарних обчислень. Наприклад, для ефективного запуску повної моделі 405B може знадобитися декілька графічних процесорів NVIDIA H100, що є значними капітальними витратами.
Власні моделі, доступ до яких зазвичай здійснюється через API, перекладають ці інфраструктурні витрати на плечі провайдера. Це може бути вигідним для компаній, яким не вистачає ресурсів або досвіду для управління складною інфраструктурою штучного інтелекту. Однак великі обсяги викликів API також можуть швидко накопичувати витрати, що потенційно переважують початкову економію на інфраструктурі.

Постійне обслуговування та оновлення
Підтримка моделі з відкритою вагою, такої як Llama 3.1, вимагає постійних інвестицій в експертизу та ресурси. Підприємства повинні виділяти на це бюджет:
Регулярне оновлення та доопрацювання моделі
Виправлення безпеки та управління вразливостями
Оптимізація продуктивності та підвищення ефективності
Пропрієтарні моделі часто включають ці оновлення як частину свого сервісу, що потенційно зменшує навантаження на внутрішні команди. Однак ця зручність досягається за рахунок зниження контролю над процесом оновлення та потенційних збоїв у роботі тонко налаштованих моделей.
Порівняння продуктивності
Порівняйте результати різних завдань
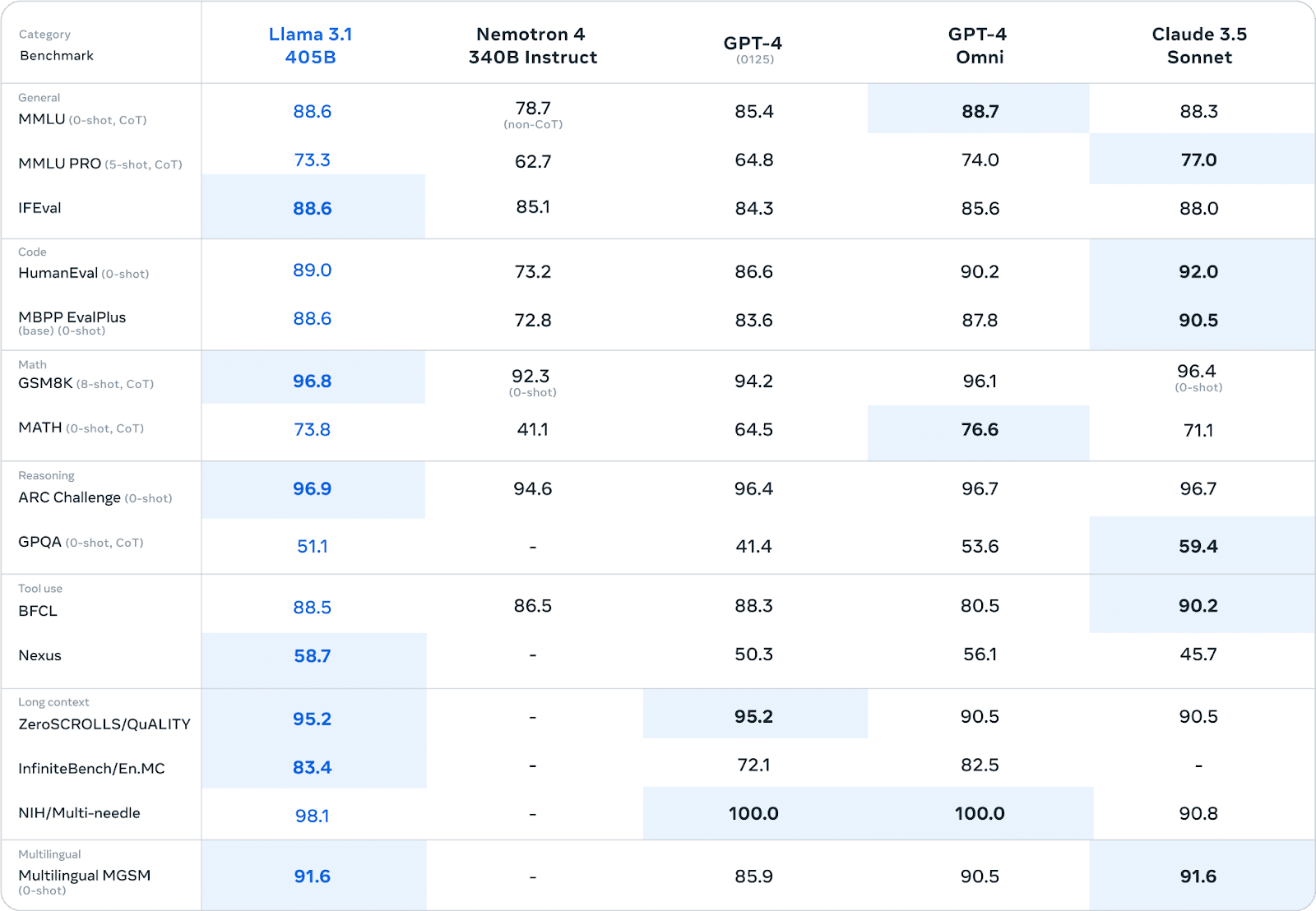
Llama 3.1 продемонстрував вражаючу продуктивність у різних тестах, часто конкуруючи або перевершуючи пропрієтарні моделі. В обширних людських оцінках і автоматизованих тестах версія з параметрами 405B показала продуктивність, порівнянну з провідними моделями з закритим вихідним кодом в таких областях, як
Загальні знання та міркування
Генерація та налагодження коду
Розв'язання математичних задач
Володіння кількома мовами
Наприклад, у тесті MMLU (Massive Multitask Language Understanding) Llama 3.1 405B отримав результат 86,4%, що ставить його в пряму конкуренцію з такими моделями, як GPT-4.
Реальна продуктивність в корпоративних умовах
Хоча бенчмарки дають цінну інформацію, реальні результати роботи в корпоративному середовищі є справжнім випробуванням здібностей LLM.
Тут картина стає більш нюансованою:
Перевага кастомізації: Підприємства, що використовують Llama 3.1, повідомляють про значні переваги від точного налаштування моделі на даних конкретної галузі. Така кастомізація часто призводить до продуктивності, яка перевершує готові пропрієтарні моделі для спеціалізованих завдань.
Синтетична генерація даних: Здатність Llama 3.1 генерувати синтетичні дані виявилася цінною для підприємств, які хочуть розширити свої навчальні бази даних або змоделювати складні сценарії.
Компроміси щодо ефективності: Деякі підприємства виявили, що хоча пропрієтарні моделі можуть мати невелику перевагу в продуктивності, можливість створювати спеціалізовані, ефективні моделі за допомогою таких методів, як дистиляція моделей за допомогою Llama 3.1, призводить до кращих загальних результатів у виробничому середовищі.
Міркування про затримку: Пропрієтарні моделі, доступ до яких здійснюється через API, можуть пропонувати меншу затримку для одиночних запитів, що може мати вирішальне значення для додатків у реальному часі. Однак підприємства, які використовують Llama 3.1 на спеціальному обладнанні, повідомляють про стабільнішу продуктивність під високими навантаженнями.
Варто зазначити, що порівняння продуктивності сильно залежить від конкретних сценаріїв використання та деталей реалізації. Підприємства повинні проводити ретельне тестування у своїх унікальних середовищах, щоб зробити точну оцінку продуктивності.
Довгострокові міркування
Майбутній розвиток LLM є критичним фактором у прийнятті рішень. Llama 3.1 виграє від швидкої ітерації, керованої глобальною дослідницькою спільнотою, що потенційно може призвести до проривних покращень. Власні моделі, підтримувані добре фінансованими компаніями, пропонують постійні оновлення та можливість інтеграції власних технологій.
У "The Ринок LLM схильна до збоїв. Оскільки відкриті моделі, такі як Llama 3.1, наближаються до пропрієтарних альтернатив або перевершують їх, ми можемо побачити тенденцію до комерціалізації базових моделей і поглиблення спеціалізації. Нові правила у сфері ШІ також можуть вплинути на життєздатність різних підходів LLM.
Узгодження з ширшими стратегіями ШІ на підприємстві має вирішальне значення. Впровадження Llama 3.1 може сприяти розвитку власної експертизи в галузі ШІ, тоді як прихильність до пропрієтарних моделей може призвести до стратегічного партнерства з технологічними гігантами.
Система прийняття рішень
Сценарії, що надають перевагу Llama 3.1, включають
Вузькоспеціалізовані галузеві програми, що потребують значної кастомізації
Підприємства з сильними внутрішніми командами ШІ, здатними керувати моделями
Компанії, які надають перевагу суверенітету даних і повному контролю над процесами ШІ
Сценарії, що надають перевагу власним моделям, включають:
Необхідність негайного розгортання з мінімальним налаштуванням інфраструктури
Вимога до широкої підтримки постачальника та гарантованих SLA
Інтеграція з наявними власними екосистемами штучного інтелекту
Підсумок
Вибір між Llama 3.1 і власними LLM є критичним моментом для підприємств, які орієнтуються в ландшафті штучного інтелекту. Хоча Llama 3.1 пропонує безпрецедентну гнучкість, потенціал для кастомізації та економію на ліцензійних платежах, вона вимагає значних інвестицій в інфраструктуру та експертизу. Пропрієтарні моделі забезпечують простоту використання, надійну підтримку та постійні оновлення, але ціною зниження контролю та потенційної прив'язки до одного постачальника. Зрештою, рішення залежить від конкретних потреб, ресурсів і довгострокової стратегії підприємства у сфері ШІ. Ретельно зваживши фактори, викладені в цьому аналізі, особи, які приймають рішення, можуть намітити курс, який найкраще відповідає цілям і можливостям їхньої організації.


