
10 перевірених стратегій, щоб скоротити витрати на LLM - AI&YOU #65



Статистика тижня: Використання менших LLM, таких як GPT-J, в каскаді може знизити загальну вартість на 80% при одночасному підвищенні точності на 1,5% порівняно з GPT-4. (Dataiku)
Оскільки організації все більше покладаються на великі мовні моделі (LLM) для різних додатків, операційні витрати, пов'язані з їх розгортанням і підтримкою, можуть швидко вийти з-під контролю без належного нагляду та стратегій оптимізації.
Meta також випустила Llama 3.1, про яку останнім часом багато говорять як про найдосконалішу LLM з відкритим вихідним кодом на сьогоднішній день.
У цьому випуску AI&YOU ми знайомимося з думками з трьох блогів, які ми опублікували на цю тему:
10 перевірених стратегій, як скоротити витрати на навчання на магістерській програмі
Meta's Llama 3.1: Розширення меж ШІ з відкритим вихідним кодом
10 перевірених стратегій, щоб скоротити витрати на LLM - AI&YOU #65
У цій статті блогу ми розглянемо десять перевірених стратегій, які допоможуть вашому підприємству ефективно управляти витратами на навчання за програмою LLM, гарантуючи, що ви зможете використати весь потенціал цих моделей, зберігаючи при цьому економічну ефективність і контроль над витратами.
1. Розумний вибір моделі
Оптимізуйте витрати на LLM, ретельно підбираючи складність моделі відповідно до вимог завдання. Не кожна програма потребує найновішої, найбільшої моделі. Для простіших завдань, таких як базова класифікація або прості запитання-відповіді, можна використовувати менші та ефективніші попередньо навчені моделі. Такий підхід може призвести до значної економії без шкоди для продуктивності.
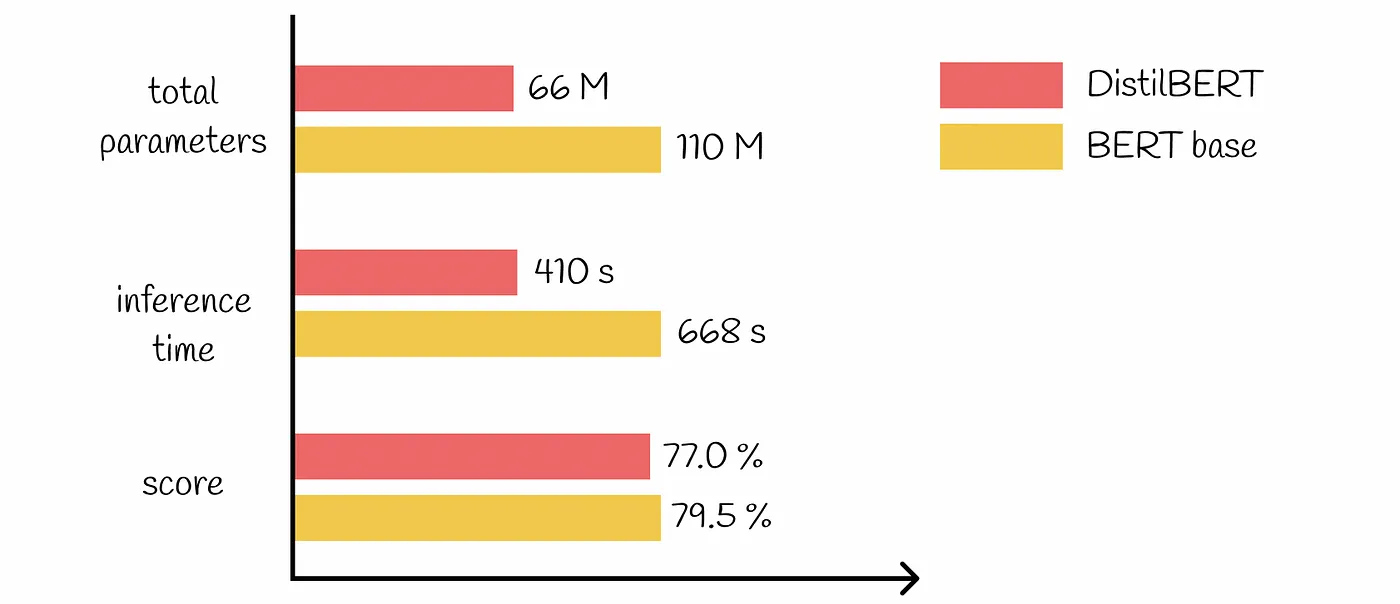
Наприклад, використання DistilBERT для аналізу настроїв замість BERT-Large може значно зменшити обчислювальні накладні витрати і пов'язані з ними витрати, зберігаючи при цьому високу точність для конкретної задачі, що стоїть перед вами.
2. Впровадити надійне відстеження використання
Отримайте комплексне уявлення про ваш Використання LLM впроваджуючи багаторівневі механізми відстеження. Відстежуйте використання токенів, час відгуку та моделюйте дзвінки на рівні розмови, користувача та компанії. Використовуйте вбудовані аналітичні панелі від постачальників LLM або впроваджуйте власні рішення для відстеження, інтегровані з вашою інфраструктурою.
Таке детальне розуміння дозволяє виявити неефективність, наприклад, відділи, які надмірно використовують дорогі моделі для простих завдань, або шаблони надлишкових запитів. Аналізуючи ці дані, ви можете виявити цінні стратегії скорочення витрат і оптимізувати загальне споживання LLM.
3. Оптимізація оперативного інжинірингу
Вдосконалюйте свої методи розробки підказок, щоб значно зменшити використання токенів та підвищити ефективність LLM. Створюйте чіткі, стислі інструкції у підказках, впроваджуйте обробку помилок, щоб вирішувати типові проблеми без додаткових запитів, і використовуйте перевірені шаблони підказок для конкретних завдань. Ефективно структуруйте свої підказки, уникаючи непотрібного контексту, використовуючи методи форматування, такі як маркери, і використовуючи вбудовані функції для контролю довжини виводу.
Ці оптимізації можуть суттєво зменшити споживання токенів та пов'язані з цим витрати, зберігаючи або навіть покращуючи якість результатів вашого LLM.
4. Використовуйте тонке налаштування важелів для спеціалізації
Використовуйте можливості точного налаштування для створення менших, ефективніших моделей, пристосованих до ваших конкретних потреб. Попри те, що такий підхід вимагає початкових інвестицій, він може призвести до значної довгострокової економії. Точно налаштовані моделі часто потребують меншої кількості токенів для досягнення рівних або кращих результатів, що зменшує витрати на висновок і необхідність повторних спроб або виправлень.
Почніть з меншої за розміром попередньо навченої моделі, використовуйте високоякісні дані, специфічні для домену, для точного налаштування і регулярно оцінюйте продуктивність та економічну ефективність. Така постійна оптимізація гарантує, що ваші моделі продовжуватимуть приносити користь, а операційні витрати залишатимуться під контролем.
5. Вивчіть безкоштовні та недорогі варіанти
Використовуйте безкоштовні або недорогі варіанти LLM, особливо на етапах розробки та тестування, щоб значно скоротити витрати без шкоди для якості. Ці альтернативи особливо цінні для створення прототипів, навчання розробників та некритичних або внутрішніх сервісів.
Однак ретельно оцінюйте компроміси, враховуючи конфіденційність даних, наслідки для безпеки та потенційні обмеження в можливостях або кастомізації. Оцініть довгострокову масштабованість і шляхи міграції, щоб переконатися, що ваші заходи з економії коштів відповідають майбутнім планам зростання і не стануть перешкодою в майбутньому.
6. Оптимізація керування контекстними вікнами
Ефективно керуйте контекстними вікнами, щоб контролювати витрати, зберігаючи при цьому якість вихідних даних. Впроваджуйте динамічний розмір контексту залежно від складності завдання, використовуйте методи узагальнення для стиснення релевантної інформації та застосовуйте підходи з ковзаючим вікном для довгих документів або розмов. Регулярно аналізуйте взаємозв'язок між розміром контексту та якістю вихідних даних, налаштовуючи вікна відповідно до конкретних вимог завдання.
Розгляньте багаторівневий підхід, використовуючи більші контексти лише за необхідності. Таке стратегічне управління контекстними вікнами може значно зменшити використання токенів і пов'язані з цим витрати, не жертвуючи при цьому можливостями розуміння ваших LLM-додатків.
7. Впровадження мультиагентних систем
Підвищуйте ефективність і рентабельність, впроваджуючи мультиагентні архітектури LLM. Цей підхід передбачає співпрацю декількох агентів ШІ для вирішення складних завдань, що дозволяє оптимізувати розподіл ресурсів і зменшити залежність від дорогих великомасштабних моделей.
Мультиагентні системи дозволяють цілеспрямовано розгортати моделі, підвищуючи загальну ефективність системи та час відгуку, зменшуючи при цьому використання токенів. Щоб підтримувати економічну ефективність, впроваджуйте надійні механізми налагодження, включаючи ведення журналів міжагентських комунікацій та аналіз шаблонів використання токенів.
Оптимізуючи розподіл праці між агентами, ви можете мінімізувати непотрібне споживання токенів і максимізувати переваги розподіленої обробки завдань.
8. Використання інструментів форматування виводу
Використовуйте інструменти форматування вихідних даних, щоб забезпечити ефективне використання токенів та мінімізувати потреби в додатковій обробці. Впроваджуйте примусові виходи функцій, щоб визначити точні формати відповідей, зменшуючи варіативність та марнотратство токенів. Такий підхід зменшує ймовірність неправильного виведення даних і необхідність уточнюючих викликів API.
Подумайте про використання вихідних даних у форматі JSON, оскільки вони компактно представляють структуровані дані, легко піддаються синтаксичному аналізу та зменшують використання токенів порівняно з відповідями природною мовою. Оптимізувавши робочі процеси LLM за допомогою цих інструментів форматування, ви зможете значно оптимізувати використання токенів і знизити операційні витрати, зберігаючи при цьому високу якість вихідних даних.
9. Інтеграція інструментів, що не належать до LLM
Доповнюйте свої LLM-додатки інструментами, що не належать до LLM, щоб оптимізувати витрати та ефективність. Використовуйте скрипти Python або традиційні підходи до програмування для завдань, які не потребують повних можливостей LLM, таких як проста обробка даних або прийняття рішень на основі правил.
Розробляючи робочі процеси, ретельно збалансуйте LLM і традиційні інструменти, виходячи зі складності завдання, необхідної точності та потенційної економії коштів. Проводьте ретельний аналіз витрат і вигод, враховуючи такі фактори, як витрати на розробку, час обробки, точність і довгострокова масштабованість. Такий гібридний підхід часто дає найкращі результати як з точки зору продуктивності, так і з точки зору економічної ефективності.
10. Регулярний аудит та оптимізація
Впровадьте надійну систему регулярного аудиту та оптимізації, щоб забезпечити постійне управління витратами на LLM. Постійно відстежуйте та аналізуйте використання LLM, щоб виявити неефективні моменти, такі як надлишкові запити або надмірна кількість контекстних вікон. Використовуйте інструменти відстеження та аналізу для вдосконалення стратегій LLM та усунення непотрібного споживання токенів.
Сприяйте розвитку культури усвідомлення витрат у вашій організації, заохочуючи команди активно розглядати фінансові наслідки використання LLM і шукати можливості для оптимізації. Зробивши економічну ефективність спільною відповідальністю, ви зможете максимізувати цінність ваших інвестицій у ШІ, тримаючи витрати під контролем у довгостроковій перспективі.
Розуміння структури ціноутворення на магістерські програми: Вхідні дані, вихідні дані та контекстні вікна
Для корпоративних стратегій ШІ розуміння структури ціноутворення на LLM має вирішальне значення для ефективного управління витратами. Операційні витрати, пов'язані з LLM, можуть швидко зростати без належного контролю, що потенційно може призвести до неочікуваних стрибків витрат, які можуть зірвати бюджет і перешкодити широкому впровадженню.
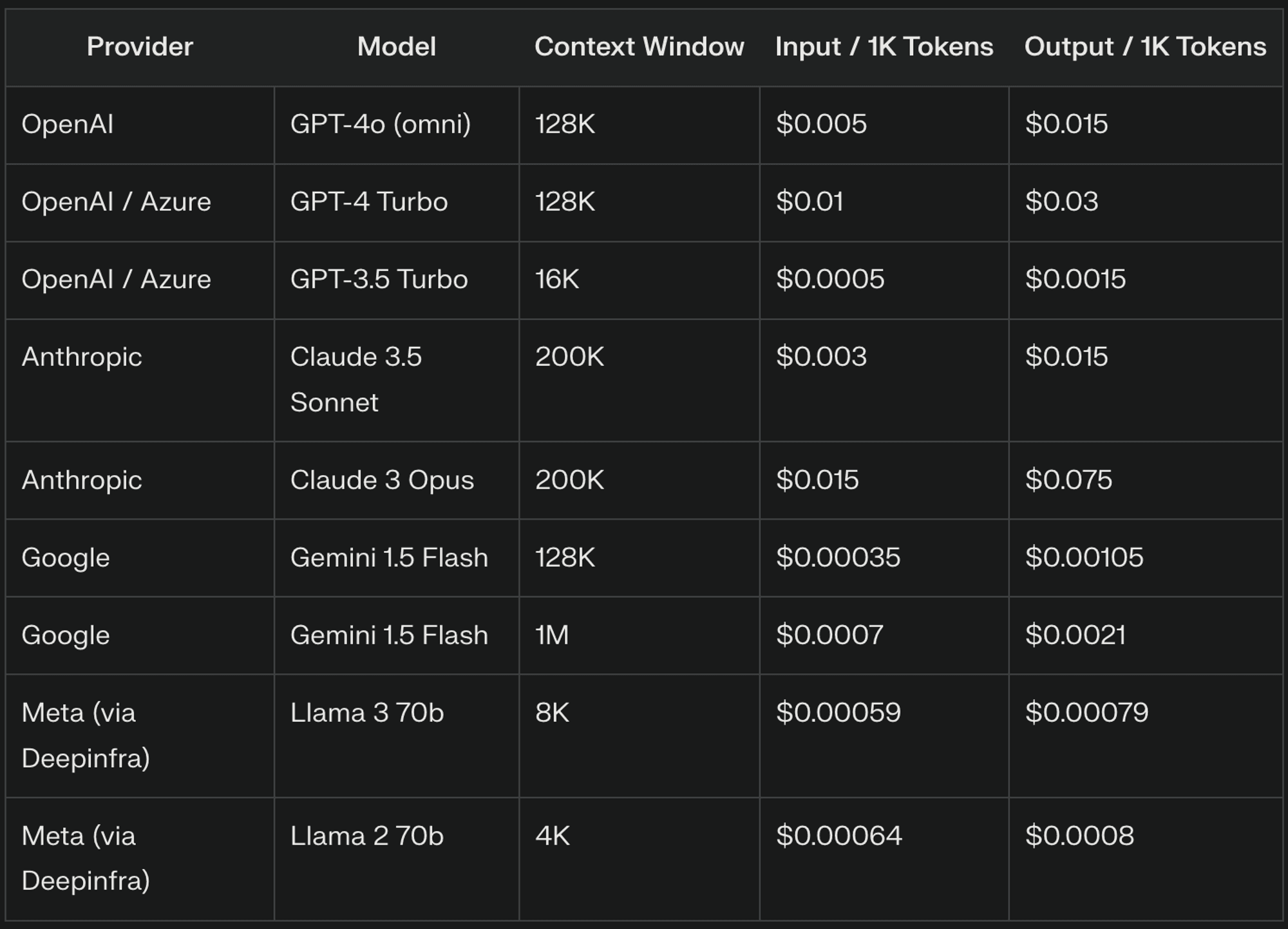
Ціноутворення на LLM зазвичай складається з трьох основних компонентів: лексеми введення, лексеми виведення та контекстні вікна. Кожен з цих елементів відіграє важливу роль у визначенні загальної вартості використання LLM у ваших програмах
Вхідні токени: Що це таке і як вони стягуються
Вхідні лексеми є основними одиницями тексту, що обробляються LLM, які, як правило, відповідають частинам слів. Наприклад, "The quick brown fox" може бути записано як ["The", "quick", "bro", "wn", "fox"], що дає 5 вхідних токенів. Провайдери LLM зазвичай стягують плату за вхідні токени на основі ставки за тисячу токенів, причому ціни суттєво відрізняються між провайдерами та версіями моделей.
Щоб оптимізувати використання вхідних токенів і зменшити витрати, розгляньте ці стратегії:
Створюйте лаконічні підказки: Зосередьтеся на чітких, прямих інструкціях.
Використовуйте ефективне кодування: Вибирайте методи, які представляють текст з меншою кількістю токенів.
Впроваджуйте шаблони підказок: Розробляйте оптимізовані структури для типових задач.
Використовуйте методи стиснення важелів: Зменшуйте розмір вхідних даних без втрати важливої інформації.
Вихідні токени: Розуміння вартості
Вихідні лексеми представляють текст, згенерований LLM у відповідь на ваше введення. Кількість вихідних маркерів може суттєво відрізнятися залежно від завдання та конфігурації моделі. Провайдери LLM часто встановлюють вищу ціну на вихідні маркери, ніж на вхідні, через обчислювальну складність генерації тексту.
Оптимізувати використання вихідних токенів і контролювати витрати:
Встановіть чіткі обмеження на довжину виводу у підказках або викликах API.
Використовуйте "навчання кількома пострілами", щоб спрямувати модель на стислі відповіді.
Впровадьте постобробку, щоб прибрати непотрібний контент.
Подумайте про кешування часто запитуваної інформації.
Використовуйте інструменти форматування виводу, щоб забезпечити ефективне використання токенів.
Контекстні вікна: Драйвер прихованих витрат
Контекстні вікна визначають, скільки попереднього тексту LLM враховує під час генерування відповіді, що має вирішальне значення для підтримання послідовності та посилань на попередню інформацію. Більші контекстні вікна збільшують кількість оброблюваних лексем, що призводить до збільшення витрат. Наприклад, контекстне вікно на 8 000 токенів може коштувати 7 000 токенів у розмові, тоді як вікно на 4 000 токенів може коштувати лише 3 000.
Оптимізувати використання контекстного вікна:
Реалізуйте динамічне визначення розміру контексту на основі вимог завдання.
Використовуйте методи узагальнення, щоб сконденсувати відповідну інформацію.
Використовуйте підходи ковзних вікон для довгих документів.
Розгляньте менші, спеціалізовані моделі для завдань з обмеженими контекстними потребами.
Регулярно аналізуйте зв'язок між розміром контексту та якістю видачі.
Ретельно керуючи цими компонентами цінової структури LLM, підприємства можуть знизити операційні витрати, зберігаючи при цьому якість своїх програм штучного інтелекту.
Підсумок
Розуміння структури ціноутворення LLM має важливе значення для ефективного управління витратами на корпоративні програми штучного інтелекту. Розуміючи нюанси вхідних токенів, вихідних токенів і контекстних вікон, організації можуть приймати обґрунтовані рішення щодо вибору моделі та моделей використання. Впровадження стратегічних методів управління витратами, таких як оптимізація використання токенів і використання кешування, може призвести до значної економії.
Meta's Llama 3.1: Розширення меж ШІ з відкритим вихідним кодом
У деяких нещодавніх важливих новинах Мета оголосила Лама 3.1найдосконалішої на сьогоднішній день великої мовної моделі з відкритим вихідним кодом. Цей реліз знаменує собою важливу віху в демократизації технології штучного інтелекту, потенційно долаючи розрив між моделями з відкритим кодом і пропрієтарними моделями.
Llama 3.1 ґрунтується на своїх попередниках з кількома ключовими покращеннями:
Збільшений розмір моделі: Впровадження моделі параметрів 405B розширює межі можливого в ШІ з відкритим вихідним кодом.
Збільшена довжина контексту: Від 4K токенів у Llama 2 до 128K у Llama 3.1, що дає змогу розуміти більш складні та нюансовані довгі тексти.
Багатомовні можливості: Розширена мовна підтримка дає змогу використовувати програму в різних регіонах і для різних сценаріїв використання.
Покращена аргументація та спеціалізовані завдання: Підвищена продуктивність у таких сферах, як математичні міркування та генерація коду.
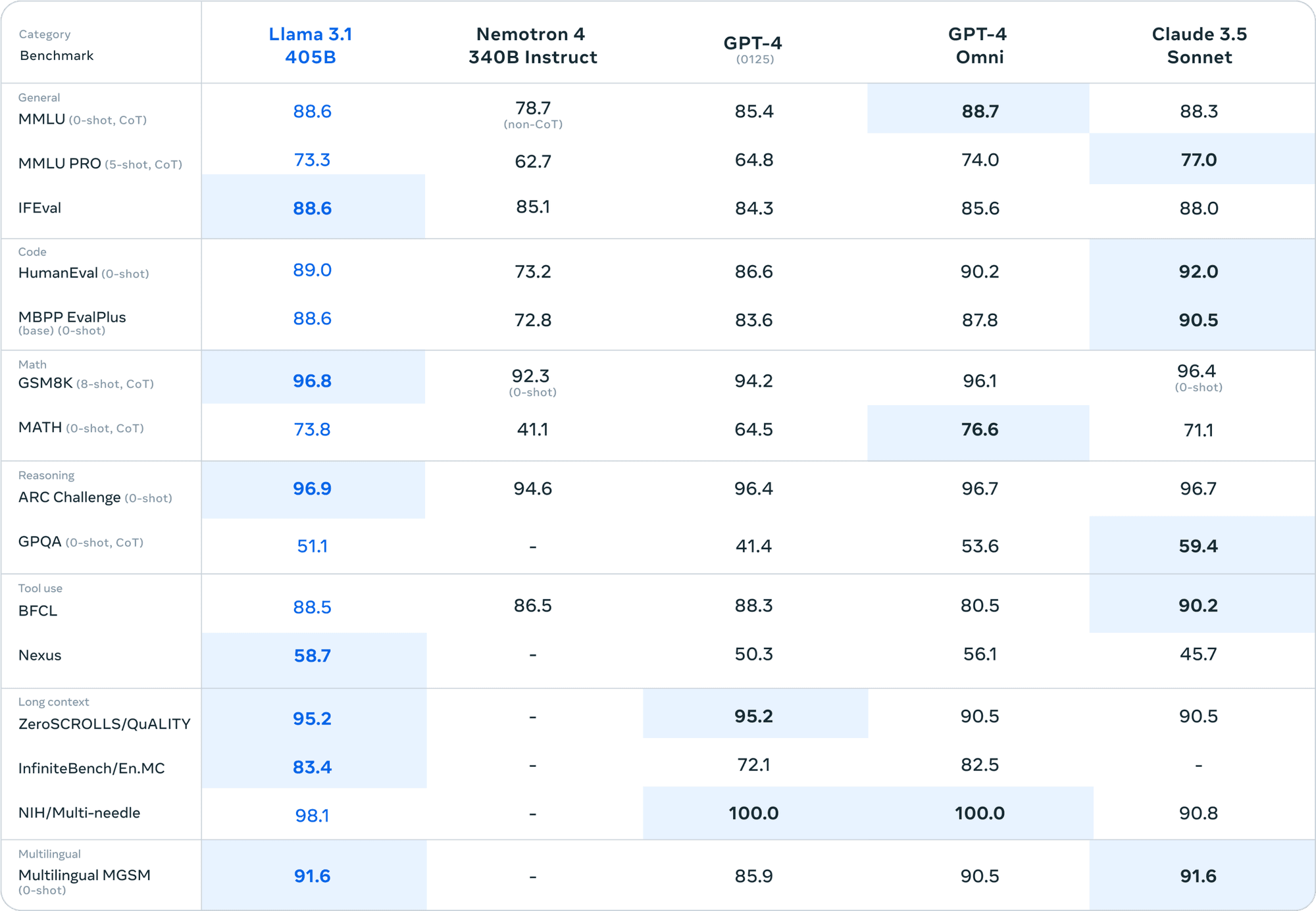
У порівнянні з моделями з закритим кодом, такими як GPT-4 і Claude 3.5 Sonnet, Llama 3.1 405B не поступається в різних тестах. Такий рівень продуктивності у моделі з відкритим вихідним кодом є безпрецедентним.
Технічні характеристики Llama 3.1
Занурюючись у технічні деталі, Llama 3.1 пропонує ряд розмірів моделей для задоволення різних потреб та обчислювальних ресурсів:
Параметрична модель 8B: Підходить для легких додатків і периферійних пристроїв.
Модель з параметрами 70B: Баланс між продуктивністю та вимогами до ресурсів.
Модель параметрів 405B: Флагманська модель, що розширює межі можливостей ШІ з відкритим вихідним кодом.
Методологія навчання для Llama 3.1 включала масивний набір даних з понад 15 трильйонів токенів, що значно більше, ніж у попередніх версіях.
Архітектурно Llama 3.1 підтримує трансформаторну модель, яка використовує лише декодер, надаючи перевагу стабільності навчання над більш експериментальними підходами, такими як суміш експертів.
Однак Meta впровадила кілька оптимізацій, щоб забезпечити ефективне навчання та висновок у такому безпрецедентному масштабі:
Масштабована навчальна інфраструктура: Використання понад 16 000 графічних процесорів H100 для навчання моделі 405B.
Ітеративна процедура після тренінгу: Використовуючи контрольоване точне налаштування та пряму оптимізацію налаштувань для покращення конкретних можливостей.
Методи квантифікації: Зменшення моделі з 16-бітних до 8-бітних чисел для більш ефективного виведення, що дозволяє розгортання на окремих серверних вузлах.
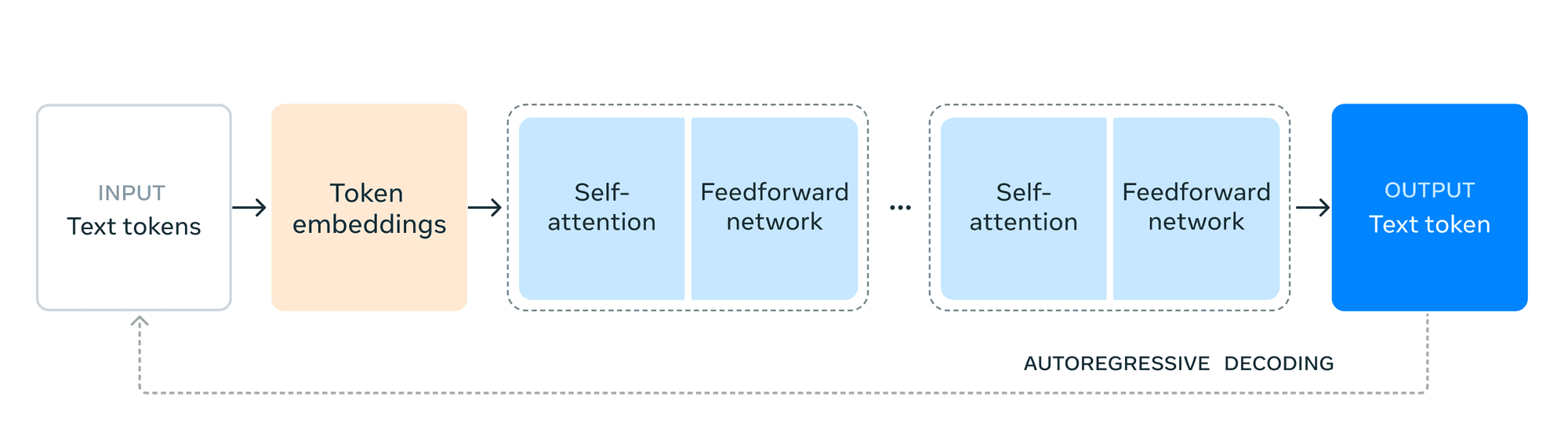
Проривні можливості
Llama 3.1 представляє кілька революційних можливостей, які виділяють його на тлі інших ШІ-технологій:
Розширена довжина контексту: Перехід до контекстного вікна на 128K токенів - це зміна правил гри. Ця розширена потужність дозволяє Llama 3.1 обробляти і розуміти набагато довші фрагменти тексту, що дає змогу:
Багатомовна підтримка: Підтримка Llama 3.1 вісьмома мовами значно розширює можливості його глобального застосування.
Поглиблене міркування та використання інструментів: Модель демонструє складні міркування та вміння ефективно використовувати зовнішні інструменти.
Генерація коду та математичні здібності: Llama 3.1 демонструє неабиякі здібності в технічних галузях:
Створення високоякісного, функціонального коду на різних мовах програмування
Розв'язування складних математичних задач з точністю
Допомога в розробці та оптимізації алгоритмів
Обіцянки та потенціал Llama 3.1
Випуск Llama 3.1 від Meta знаменує собою переломний момент у світі штучного інтелекту, демократизуючи доступ до передових можливостей штучного інтелекту. Пропонуючи модель параметрів 405B з найсучаснішою продуктивністю, багатомовною підтримкою та збільшеною довжиною контексту, і все це в рамках відкритого вихідного коду, компанія Meta встановила новий стандарт для доступного та потужного ШІ. Цей крок не тільки кидає виклик домінуванню моделей із закритим кодом, але й прокладає шлях до безпрецедентних інновацій та співпраці у спільноті ШІ.
Дякуємо, що знайшли час прочитати AI & YOU!
Щоб отримати ще більше матеріалів про корпоративний ШІ, включаючи інфографіку, статистику, інструкції, статті та відео, підписуйтесь на канал Skim AI на LinkedIn
Ви засновник, генеральний директор, венчурний інвестор або інвестор, який шукає консультації з питань ШІ, фракційної розробки ШІ або послуги Due Diligence? Отримайте рекомендації, необхідні для прийняття обґрунтованих рішень щодо продуктової стратегії та інвестиційних можливостей вашої компанії у сфері ШІ.
Ми створюємо індивідуальні AI-рішення для компаній, що підтримуються венчурним та приватним капіталом, у наступних галузях: Медичні технології, новини/контент-агрегація, кіно- та фото-виробництво, освітні технології, юридичні технології, фінтех та криптовалюта.


