
Топ-10 способів усунення галюцинацій на рівні LLM



Оскільки великі мовні моделі (БММ) продовжують проникати майже в кожну сферу та галузь, вони приносять із собою унікальну проблему: галюцинації. Ці неточності, спричинені штучним інтелектом, становлять значний ризик для надійності та достовірності результатів роботи з БММ.
Що таке галюцинації LLM?
Галюцинації LLM виникають, коли ці потужні мовні моделі генерують текст, який є фактично неправильним, безглуздим або не пов'язаним із вхідними даними. Незважаючи на те, що він виглядає зв'язним і впевненим, галюцинації можуть призвести до дезінформації, прийняття помилкових рішень і втрати довіри до додатків зі штучним інтелектом.
Оскільки системи штучного інтелекту все частіше інтегрувати у різні аспекти нашого життя - від чат-ботів для обслуговування клієнтів до інструменти для створення контентунеобхідність зменшити кількість галюцинацій стає першочерговою. Неконтрольовані галюцинації можуть призвести до репутаційних втрат, юридичних проблем і потенційної шкоди для користувачів, які покладаються на інформацію, згенеровану ШІ.
Ми склали список з 10 найкращих стратегій для зменшення галюцинацій LLM, починаючи від підходів, орієнтованих на дані, і закінчуючи методами, орієнтованими на моделі, та методами, орієнтованими на процес. Ці стратегії покликані допомогти компаніям і розробникам підвищити фактичну точність і надійність їхніх систем ШІ.
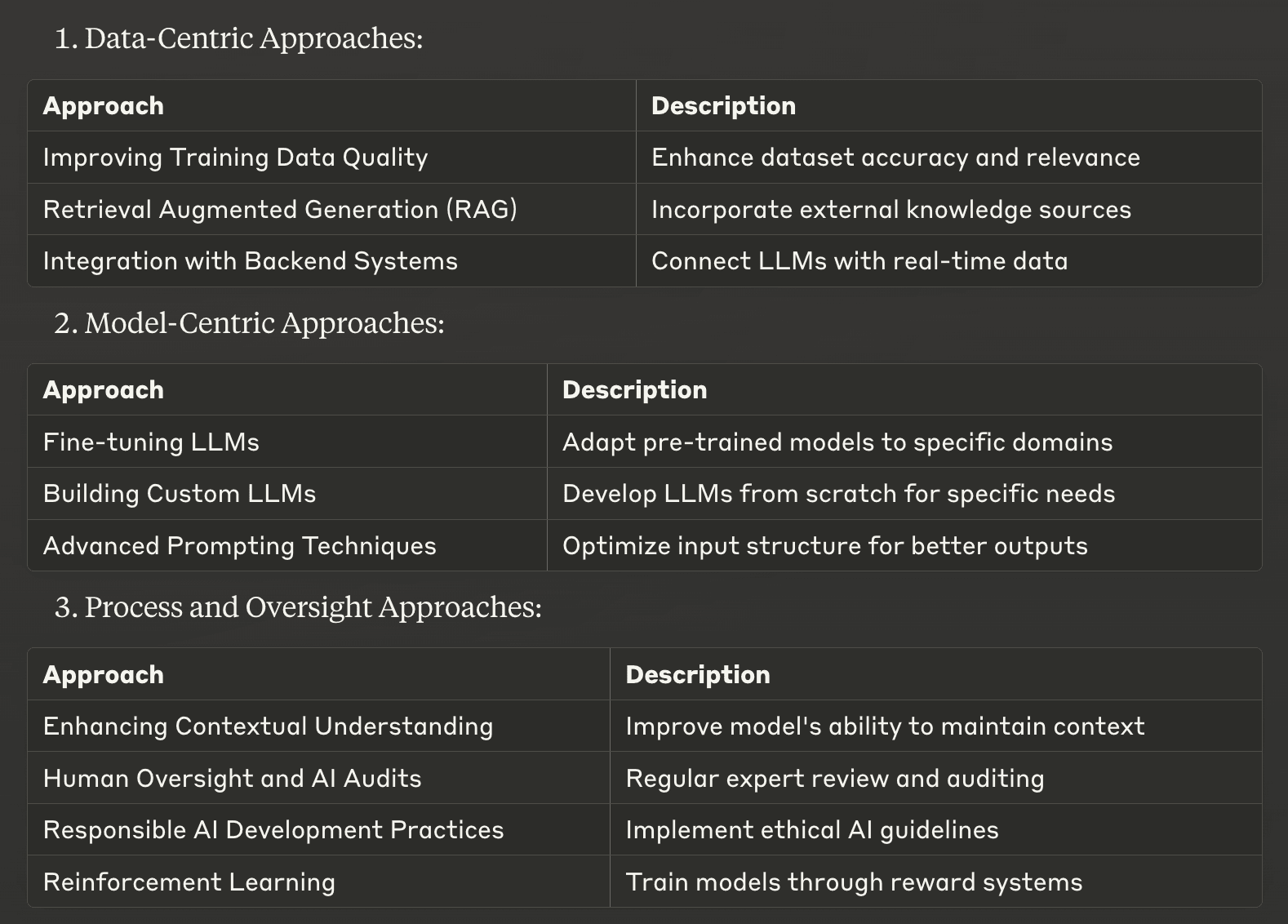
Підходи, орієнтовані на дані
1. Покращення якості навчальних даних
Один із найфундаментальніших способів зменшити галюцинації - підвищити якість навчальних даних, які використовуються для розробки великих мовних моделей. Високоякісні, різноманітні та добре контрольовані набори даних можуть значно зменшити ймовірність того, що ШНМ засвоять і відтворять неточну інформацію.
Щоб реалізувати цю стратегію, зосередьтеся на:
Ретельна перевірка джерел даних на точність та релевантність
Забезпечення збалансованого представлення тем і перспектив
Регулярне оновлення наборів даних для включення актуальної інформації
Видалення дубльованих або суперечливих даних
Інвестуючи в чудові навчальні дані, ви закладаєте міцний фундамент для більш надійних і точних результатів LLM.
2. Розширене покоління пошуку (RAG)
Розширене покоління пошуку (RAG) це потужний метод, який поєднує в собі сильні сторони підходів, заснованих на пошуку та генерації. Цей метод дозволяє магістрам отримати доступ до релевантної інформації із зовнішніх джерел знань і включити її в процес генерації тексту.
RAG працює за принципом:
Отримання відповідної інформації з кураторської бази знань
Включення цієї інформації в контекст, що надається LLM
Створення відповідей, які ґрунтуються на фактичній, актуальній інформації
Впроваджуючи RAG, компанії можуть значно зменшити кількість галюцинацій, прив'язуючи відповіді LLM до надійних зовнішніх джерел інформації. Цей підхід особливо ефективний для галузевих застосунків, де точність має вирішальне значення, наприклад, у юридичних або медичних системах штучного інтелекту.
3. Інтеграція з внутрішніми системами
Інтеграція LLM з існуючими внутрішніми системами компанії може значно підвищити точність і релевантність контенту, створеного штучним інтелектом. Такий підхід дозволяє LLM отримувати доступ до контекстно-залежних даних у реальному часі безпосередньо з баз даних або API компанії.
Основні переваги інтеграції бекенда включають в себе наступні:
Забезпечення надання відповідей на основі найактуальнішої інформації
Надання персоналізованих та контекстуально релевантних результатів
Зменшення залежності від потенційно застарілих навчальних даних
Наприклад, чат-бот для електронної комерції, інтегрований із системою інвентаризації компанії, може надавати точну інформацію в режимі реального часу про наявність товару, знижуючи ризик галюцинацій щодо рівня запасів або цін.
Впроваджуючи ці підходи, орієнтовані на дані, компанії можуть значно підвищити надійність результатів LLM, зменшити ризик галюцинацій і поліпшити загальну продуктивність системи ШІ.
Модельно-орієнтовані підходи
4. Тонке налаштування LLM
Тонке налаштування - це потужний метод адаптації попередньо навчених великих мовних моделей до конкретних доменів або завдань. Цей процес передбачає подальше навчання ШНМ на меншому, ретельно відібраному наборі даних, що має відношення до цільової програми. Точне налаштування може значно зменшити галюцинації, узгоджуючи вихідні дані моделі зі специфічними знаннями та термінологією предметної області.
Основні переваги тонкого налаштування включають в себе наступні:
Підвищена точність у спеціалізованих галузях
Краще розуміння галузевого жаргону
Зменшення ймовірності генерування нерелевантної або некоректної інформації
Наприклад, юридичний ШІ-помічник, налаштований на корпус юридичних документів і прецедентного права, буде менш схильний до галюцинацій при відповідях на юридичні запити, що підвищить його надійність і корисність в юридичній сфері.
5. Створення індивідуальних магістерських програм
Для організацій зі значними ресурсами та специфічними потребами створення власних великих мовних моделей з нуля може бути ефективним способом пом'якшення галюцинацій. Такий підхід дозволяє повністю контролювати навчальні дані, архітектуру моделі та процес навчання.
Переваги індивідуальні магістерські програми в тому числі:
Адаптована база знань, що відповідає потребам бізнесу
Зменшення ризику включення неактуальної або неточної інформації
Більший контроль над поведінкою та результатами моделі
Хоча цей підхід вимагає значних обчислювальних ресурсів і досвіду, він може призвести до створення високоточних і надійних систем штучного інтелекту в передбачуваній сфері застосування.
6. Просунуті техніки підказок
Складні методи підказок можуть спрямовувати мовні моделі на генерування більш точного та зв'язного тексту, ефективно зменшуючи галюцинації. Ці методи допомагають структурувати вхідні дані таким чином, щоб отримати більш надійні результати від системи ШІ.
Деякі ефективні методи спонукання включають в себе наступні:
Спонукання до роздумів: Заохочує до поетапних міркувань
Навчання з кількох пострілів: Наводить приклади, щоб спрямувати відповіді моделі
Ретельно продумуючи підказки, розробники можуть значно підвищити фактичну точність і релевантність контенту, створеного LLM, мінімізуючи появу галюцинацій.
Підходи до процесу та нагляду
7. Поглиблення контекстуального розуміння
Покращення здатності LLM підтримувати контекст під час взаємодії може значно зменшити кількість галюцинацій. Це передбачає впровадження технік, які допомагають моделі відстежувати і використовувати відповідну інформацію під час тривалих розмов або складних завдань.
Ключові стратегії включають:
Роздільна здатність конференції: Допомагає моделі ідентифікувати та пов'язувати пов'язані об'єкти
Відстеження історії розмов: Забезпечення врахування попередніх обмінів
Розширене контекстне моделювання: Дозволяє моделі зосередитися на релевантній інформації
Ці методи допомагають LLM підтримувати узгодженість і послідовність, зменшуючи ймовірність генерування суперечливої або нерелевантної інформації.
8. Людський нагляд та аудит ШІ
Впровадження людського нагляду та проведення регулярних аудитів ШІ мають вирішальне значення для виявлення та усунення галюцинацій у результатах LLM. Цей підхід поєднує людський досвід і можливості ШІ для забезпечення найвищого рівня точності та надійності.
Ефективні практики нагляду включають
Регулярна перевірка контенту, створеного штучним інтелектом, експертами галузі
Впровадження циклів зворотного зв'язку для покращення продуктивності моделі
Проведення ретельного аудиту для виявлення патернів галюцинацій
Підтримуючи участь людини в процесі ШІ, організації можуть виявляти і виправляти галюцинації, які в іншому випадку можуть залишитися непоміченими, підвищуючи загальну надійність своїх систем ШІ.
9. Відповідальні практики розробки ШІ
Прийняття відповідальних практик розробки ШІ має важливе значення для створення LLM, які менш схильні до галюцинацій. Цей підхід наголошує на етичних міркуваннях, прозорості та підзвітності протягом усього життєвого циклу розробки ШІ.
Ключові аспекти відповідальної розробки ШІ включають
Пріоритет справедливості та неупередженості навчальних даних
Впровадження надійних процесів тестування та валідації
Забезпечення прозорості процесів прийняття рішень у сфері ШІ
Дотримуючись цих принципів, організації можуть розробляти системи штучного інтелекту, які є більш надійними, заслуговують на довіру і з меншою ймовірністю дають шкідливі або оманливі результати.
10. Навчання з підкріпленням
Навчання з підкріпленням пропонує багатообіцяючий підхід до зменшення галюцинацій у LLMs. Ця методика передбачає навчання моделей за допомогою системи заохочень і покарань, заохочуючи бажану поведінку і перешкоджаючи небажаній.
Переваги навчання з підкріпленням у зменшенні галюцинацій:
Узгодження результатів моделі з конкретними цілями щодо точності
Покращення здатності моделі до самокорекції
Підвищення загальної якості та надійності згенерованого тексту
Впроваджуючи методи навчання з підкріпленням, розробники можуть створювати LLM, які краще уникають галюцинацій і створюють фактично точний контент.
Ці модельно-орієнтовані та процесно-орієнтовані підходи надають потужні інструменти для зменшення галюцинацій у великих мовних моделях. Поєднуючи ці стратегії з підходами, орієнтованими на дані, про які йшлося раніше, організації можуть значно підвищити надійність і точність своїх систем ШІ, прокладаючи шлях до більш надійних і ефективних додатків ШІ.
Впровадження ефективних стратегій зменшення галюцинацій
Ми розглянули 10 найкращих способів зменшити галюцинації у великих мовних моделях, і тепер зрозуміло, що вирішення цієї проблеми має вирішальне значення для розробки надійних систем штучного інтелекту. Ключ до успіху - вдумливе впровадження цих стратегій, адаптованих до ваших конкретних потреб і ресурсів. Обираючи правильний підхід, враховуйте свої унікальні вимоги та типи галюцинацій, з якими ви стикаєтесь. Деякі стратегії, як-от покращення якості навчальних даних, можуть бути простими у впровадженні, тоді як інші, як-от створення індивідуальних LLM, можуть вимагати значних інвестицій.
Баланс між ефективністю та потребами в ресурсах є дуже важливим. Часто оптимальним рішенням є комбінація стратегій, що дозволяє використовувати кілька підходів, одночасно керуючи обмеженнями. Наприклад, поєднання RAG з передовими методами підказок може дати значні покращення без необхідності значного перенавчання моделей.
Оскільки штучний інтелект продовжує розвиватися, методи боротьби з галюцинаціями також будуть вдосконалюватися. Залишаючись в курсі останніх розробок і постійно вдосконалюючи свій підхід, ви зможете гарантувати, що ваші системи штучного інтелекту залишатимуться на передовій точності та надійності. Пам'ятайте, що мета - не просто генерувати текст, а створювати результати LLM, яким користувачі можуть довіряти і на які можна покластися, прокладаючи шлях до більш ефективного і відповідального застосування ШІ в різних галузях.
Якщо вам потрібна допомога в боротьбі з галюцинаціями LLM, не соромтеся звертатися до нас в Skim AI.


