
Як створювати потужні LLM-додатки з векторними базами даних + RAG - AI&YOU#55



Статистика/факт тижня: 30% підприємств використовуватимуть векторні бази даних для обґрунтування своїх генеративних моделей ШІ до 2026 року, порівняно з 2% у 2023 році. (Gartner)
Такі LLM, як GPT-4, Claude і Llama 3, стали потужними інструментами для підприємств, що впроваджують НЛП, демонструючи чудові можливості в розумінні та створенні тексту, схожого на людський. Однак вони часто мають проблеми з усвідомленням контексту та точністю, особливо коли мають справу з інформацією, специфічною для певної галузі.
Ось чому в цьому випуску AI&YOU ми досліджуємо, як вирішуються ці проблеми в трьох блогах, які ми опублікували цього тижня:
Поєднання векторних баз даних та RAG для потужних програм для LLM
Топ-10 переваг використання векторної бази даних з відкритим кодом
Поєднання векторних баз даних та RAG для потужних LLM-додатків - AI&YOU #55
Щоб вирішити ці проблеми, дослідники та розробники звернулися до інноваційних методів, таких як Retrieval Augmented Generation (ГАНЧІР'Я) та векторні бази даних. RAG розширює можливості LLM, дозволяючи їм отримувати доступ до релевантної інформації із зовнішніх баз знань, тоді як векторні бази даних забезпечують ефективне і масштабоване рішення для зберігання і запитів до високорозмірних представлень даних.
Синергія між векторними базами даних та RAG
Векторні бази даних і RAG утворюють потужну синергію, яка розширює можливості великих мовних моделей. В основі цієї синергії лежить ефективне зберігання та пошук вбудовувань баз знань. Векторні бази даних призначені для роботи з високорозмірними векторними представленнями даних. Вони забезпечують швидкий і точний пошук за схожістю, дозволяючи LLM швидко отримувати релевантну інформацію з великих баз знань.
Інтегруючи векторні бази даних з RAG, ми можемо створити безперебійний конвеєр для доповнення відповідей LLM зовнішніми знаннями. Коли LLM отримує запит, RAG може ефективно шукати у векторній базі даних найбільш релевантну інформацію на основі вкладеного запиту. Ця знайдена інформація потім використовується для збагачення контексту LLM, що дозволяє йому генерувати більш точні та інформативні відповіді в режимі реального часу.
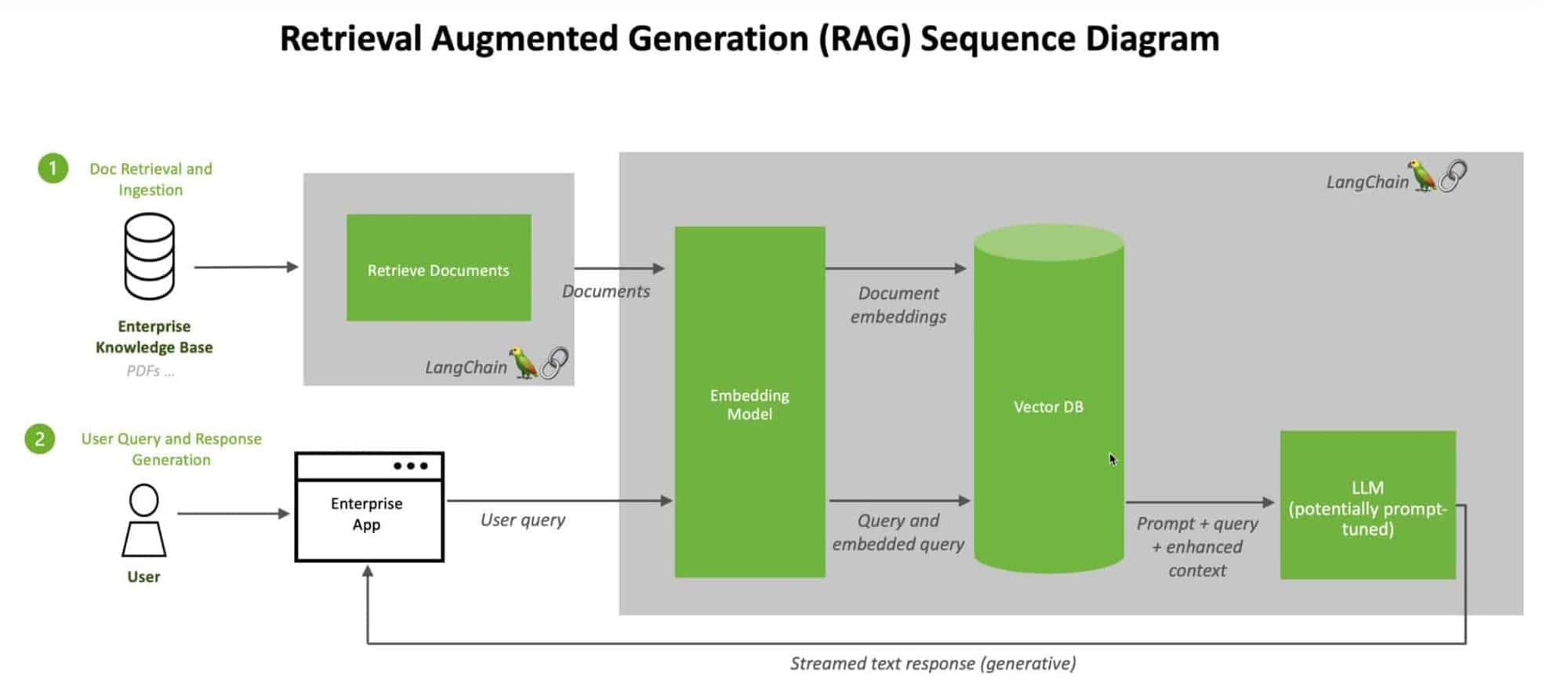
Переваги поєднання векторних баз даних та RAG
Поєднання векторних баз даних і RAG дає кілька значних переваг для додатків з великими мовними моделями:
Покращена точність та зменшення галюцинацій
Однією з основних переваг поєднання векторних баз даних і RAG є значне підвищення точності відповідей LLM. Надаючи LLM доступ до релевантних зовнішніх знань, RAG допомагає зменшити кількість "галюцинацій" - випадків, коли модель генерує непослідовну або фактично неправильну інформацію. Маючи можливість отримувати та включати специфічну для домену інформацію з надійних джерел, LLMs можуть створювати більш точні та достовірні результати.
Масштабованість і продуктивність
Векторні бази даних розроблені для ефективного масштабування, що дозволяє їм обробляти великі обсяги даних високої розмірності. Така масштабованість має вирішальне значення при роботі з великими базами знань, які потрібно шукати і отримувати в режимі реального часу. Використовуючи можливості векторних баз даних, RAG може виконувати швидкий і ефективний пошук за схожістю, дозволяючи LLM швидко генерувати відповіді без шкоди для якості отриманої інформації.
Увімкнення специфічних для домену додатків
Поєднання векторних баз даних і RAG відкриває нові можливості для створення галузевих LLM-додатків. Завдяки кураторству над базами знань, специфічними для різних доменів, LLM можна адаптувати для надання точної та релевантної інформації в цих контекстах. Це уможливлює розробку спеціалізованих помічників зі штучним інтелектом, чат-ботів і систем управління знаннями, які можуть задовольнити унікальні потреби різних галузей і сфер використання.

Реалізація RAG з векторними базами даних
Щоб скористатися перевагами поєднання векторних баз даних і RAG, важливо розуміти процес реалізації.
Давайте розглянемо ключові кроки, пов'язані з налаштуванням RAG-системи з векторною базою даних:
Індексування та зберігання вбудовувань бази знань: Першим кроком є перетворення текстових даних з бази знань у високорозмірні вектори за допомогою моделей вбудовування, таких як BERT, а потім індексування та зберігання цих вбудовувань у векторній базі даних для ефективного пошуку та вилучення за схожістю.
Запит до векторної бази даних для отримання відповідної інформації: Коли LLM отримує запит, система RAG перетворює запит у векторне представлення, використовуючи ту саму модель вбудовування, а векторна база даних виконує пошук подібності, щоб отримати найбільш релевантні вбудовування бази знань на основі обраної метрики подібності.
Інтеграція знайденої інформації у відповіді LLM: Відповідна інформація, отримана з векторної бази даних, інтегрується в процес генерації відповідей LLM або шляхом об'єднання її з оригінальним запитом, або з використанням таких методів, як механізми уваги, що дозволяє LLM генерувати більш точні та інформативні відповіді на основі розширеного контексту.
Вибір правильної векторної бази даних для вашої програми: Вибір відповідної векторної бази даних має вирішальне значення, враховуючи такі фактори, як масштабованість, продуктивність, простота використання і сумісність з існуючим стеком технологій, а також ваші конкретні вимоги, такі як розмір бази знань, обсяг запитів і бажана затримка відповіді.
Найкращі практики та міркування
Щоб забезпечити успішне впровадження RAG з векторними базами даних, слід пам'ятати про декілька найкращих практик і міркувань.
Оптимізація вбудовування бази знань для пошуку:
Якість вбудовування бази знань має вирішальне значення, що вимагає експериментів з різними моделями і методами вбудовування, точного налаштування на специфічні для домену дані, а також регулярного оновлення і розширення вбудовування в міру надходження нової інформації для підтримки актуальності і точності.
Баланс між швидкістю та точністю пошуку:
Існує компроміс між швидкістю і точністю пошуку, що вимагає застосування таких методів, як приблизний пошук найближчого сусіда для прискорення пошуку при збереженні прийнятної точності, а також кешування вбудовувань, до яких часто звертаються, і впровадження стратегій балансування навантаження для оптимізації продуктивності.
Забезпечення безпеки та конфіденційності даних:
Налагодження безпечного зберігання даних, контролю доступу та методів шифрування, таких як гомоморфне шифрування, має важливе значення для запобігання несанкціонованому доступу та захисту конфіденційних даних у вбудовуваних базах знань, дотримуючись при цьому відповідних правил захисту даних.
Моніторинг та обслуговування системи:
Постійний моніторинг таких показників, як затримка запитів, точність пошуку та використання ресурсів, впровадження автоматизованих механізмів моніторингу та оповіщення, а також створення надійного графіка технічного обслуговування, включаючи резервне копіювання, оновлення та налаштування продуктивності, є життєво важливими для забезпечення довгострокової продуктивності та надійності системи RAG.
Використання можливостей векторних баз даних та RAG на вашому підприємстві
Оскільки штучний інтелект продовжує формувати наше майбутнє, для вашого підприємства вкрай важливо залишатися в авангарді цього технологічного прогресу. Вивчаючи та впроваджуючи передові технології, такі як векторні бази даних і RAG, ви зможете розкрити весь потенціал великих мовних моделей і створити системи штучного інтелекту, які будуть більш інтелектуальними, адаптивними та забезпечать більшу рентабельність інвестицій.
Топ-10 переваг використання векторної бази даних з відкритим кодом
Серед рішень для векторних баз даних векторні бази даних з відкритим кодом пропонують переконливе поєднання гнучкості, масштабованості та економічної ефективності. Використовуючи колективну силу спільноти розробників відкритого коду, ці спеціалізовані векторні бази даних переосмислюють підхід організацій до управління та аналізу даних.
Цього тижня в нашому блозі ми також розглянули 10 переваг використання векторних баз даних з відкритим кодом:
Масштабованість та економічна ефективність забезпечують безперебійне зростання без високих витрат, усуваючи прив'язку до постачальника та забезпечуючи бюджетне рішення.
Гнучкість і кастомізація дозволяють адаптувати базу даних до конкретних потреб, змінювати функціональність та інтегрувати з існуючими системами.
🔸 Ефективна обробка неструктурованих даних використовує такі методи, як НЛП та векторні вбудовування для ефективного зберігання, пошуку та аналізу.
Потужний векторний пошук за схожістю полегшує точний пошук на основі семантичної схожості, що дозволяє використовувати такі додатки, як персоналізовані рекомендації та інтелектуальний пошук контенту.
Інтеграція з екосистемами з відкритим вихідним кодом забезпечує сумісність з додатковими інструментами та фреймворками, підвищуючи продуктивність та сприяючи співпраці.
🔸 Надійні заходи безпеки та захисту даних надають пріоритет прозорості, шифруванню, контролю доступу та дотриманню стандартів комплаєнсу.
Високопродуктивне та ефективне управління даними забезпечує блискавичне виконання запитів та універсальність для різноманітних робочих навантажень.
Сумісність з передовою аналітикою та машинним навчанням дозволяє безперешкодно інтегруватися з найсучаснішими технологіями та фреймворками.
Перспективна та масштабована архітектура забезпечує безперешкодне зростання та адаптацію до нових технологій та вимог до даних, що змінюються.
🔸 Інновації та підтримка з боку громади сприяють постійному вдосконаленню, обміну знаннями та безцінним ресурсам для використання цих потужних інструментів.
5 найкращих векторних баз даних для вашого підприємства
Окрім основних переваг, цього тижня ми також опублікували блог про 5 найкращих векторних баз даних для вашого підприємства:
1. Chroma
Chroma розроблений для безперешкодної інтеграції з моделями та фреймворками машинного навчання, що спрощує процес створення додатків на основі ШІ. Він пропонує ефективне зберігання векторів, пошук, пошук за схожістю, індексування в реальному часі та зберігання метаданих. Підтримує різні метрики відстані та алгоритми індексування для оптимальної продуктивності в різних сценаріях використання, таких як семантичний пошук, рекомендації та виявлення аномалій.

2. Шишка
Pinecone - це повністю керована, безсерверна векторна база даних, пріоритетами якої є висока продуктивність і простота використання. Вона поєднує в собі передові алгоритми векторного пошуку з фільтрацією та розподіленою інфраструктурою для швидкого, надійного векторного пошуку в масштабах. Легко інтегрується з фреймворками машинного навчання та джерелами даних для таких додатків, як семантичний пошук, рекомендації, виявлення аномалій та відповіді на запитання.
3. Квадрант
Qdrant - це високошвидкісна та масштабована векторна пошукова система подібності з відкритим вихідним кодом, написана на Rust. Вона надає зручний API для зберігання, пошуку та управління векторами з метаданими, що дозволяє створювати готові до використання програми для зіставлення, пошуку, рекомендацій тощо. Функції включають оновлення в реальному часі, розширену фільтрацію, розподілені індекси та хмарні варіанти розгортання.
4. Вигравати.
Weaviate - це векторна база даних з відкритим вихідним кодом, пріоритетами якої є швидкість, масштабованість і простота використання. Вона дозволяє зберігати як об'єкти, так і вектори, поєднуючи векторний пошук зі структурованою фільтрацією. Пропонує API на основі GraphQL, CRUD-операції, горизонтальне масштабування та хмарне розгортання. Містить модулі для завдань NLP, автоматичної конфігурації схем та кастомної векторизації.
5. Мільвус
Milvus - це векторна база даних з відкритим вихідним кодом, призначена для вбудовування управління, пошуку схожості та масштабованих додатків ШІ. Вона пропонує підтримку гетерогенних обчислень, надійність зберігання, комплексні метрики та хмарну архітектуру. Надає гнучкий API для індексів, метрик відстані та типів запитів і може масштабуватися до мільярдів векторів за допомогою спеціальних плагінів.
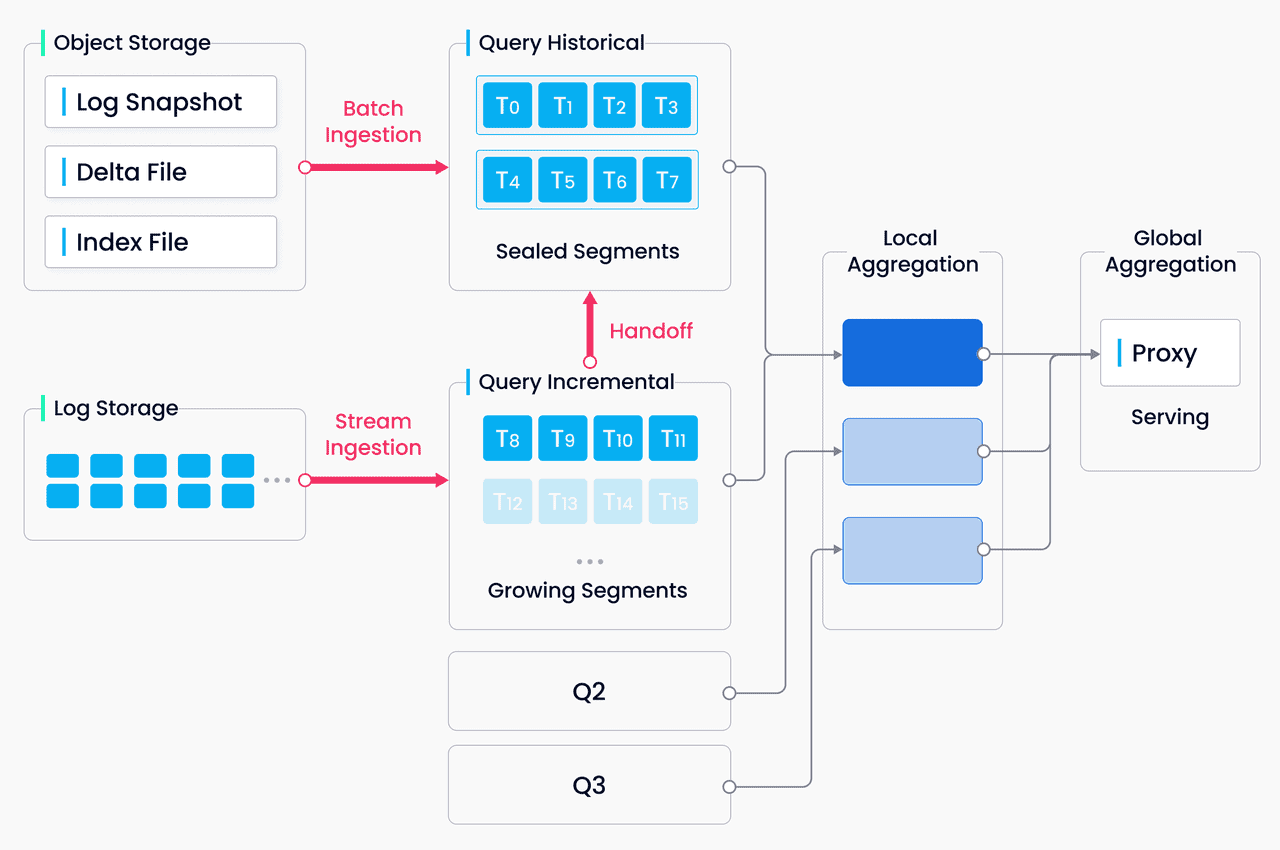
Вибір правильної бази даних Vector для вашого підприємства
Незалежно від того, чи створюєте ви семантичну пошукову систему, систему рекомендацій або будь-яку іншу програму на основі штучного інтелекту, векторні бази даних є основою для розкриття повного потенціалу моделей машинного навчання. Завдяки швидкому пошуку за схожістю, розширеній фільтрації та безшовній інтеграції з популярними фреймворками, ці бази даних дають розробникам можливість зосередитися на створенні інноваційних рішень, не турбуючись про складнощі, пов'язані з управлінням векторними даними.
Щоб отримати ще більше матеріалів про корпоративний ШІ, включаючи інфографіку, статистику, інструкції, статті та відео, підписуйтесь на канал Skim AI на LinkedIn
Ви засновник, генеральний директор, венчурний інвестор або інвестор, який шукає експертні консультації з питань АІ або юридичну експертизу? Отримайте рекомендації, необхідні для прийняття обґрунтованих рішень щодо продуктової стратегії або інвестиційних можливостей вашої компанії у сфері ШІ.
Ми створюємо кастомні Рішення для штучного інтелекту для компаній, що підтримуються венчурним та приватним капіталом у наступних галузях: Медичні технології, новини/контент-агрегація, кіно- та фото-виробництво, освітні технології, юридичні технології, фінтех та криптовалюта.


