
Розуміння структури ціноутворення на магістерські програми: Вхідні дані, вихідні дані та контекстні вікна



Для корпоративних стратегій ШІ розуміння структур ціноутворення на великі мовні моделі (LLM) має вирішальне значення для ефективного управління витратами. Операційні витрати, пов'язані з LLM, можуть швидко зростати без належного контролю, що потенційно може призвести до неочікуваних стрибків витрат, які можуть зірвати бюджет і перешкодити широкому впровадженню. T
його блог заглиблюється в ключові компоненти структури ціноутворення LLM, надаючи інформацію, яка допоможе вам оптимізувати використання LLM та контролювати витрати.
Ціноутворення на LLM зазвичай складається з трьох основних компонентів: токени введення, токени виведення та контекстні вікна. Кожен з цих елементів відіграє важливу роль у визначенні загальної вартості використання LLM у ваших додатках. Отримавши глибоке розуміння цих компонентів, ви будете краще підготовлені до прийняття обґрунтованих рішень щодо вибору моделі, схем використання та стратегій оптимізації.
Основні компоненти ціноутворення на LLM
Вхідні маркери
Вхідні маркери представляють текст, що подається в LLM для обробки. Сюди входять ваші підказки, інструкції та будь-який додатковий контекст, наданий моделі. Кількість вхідних маркерів безпосередньо впливає на вартість кожного виклику API, оскільки більша кількість маркерів вимагає більше обчислювальних ресурсів для обробки.
Вихідні токени
Вихідні маркери - це текст, згенерований LLM у відповідь на ваше введення. Ціни на вихідні маркери часто відрізняються від цін на вхідні маркери, що відображає додаткові обчислювальні зусилля, необхідні для генерації тексту. Управління використанням вихідних маркерів має вирішальне значення для контролю витрат, особливо в додатках, які генерують великі обсяги тексту.
Контекстні вікна
Контекстні вікна означають кількість попереднього тексту, яку модель може врахувати під час генерування відповідей. Більші контекстні вікна забезпечують більш повне розуміння, але коштують дорожче через збільшення використання токенів та обчислювальних вимог.
Вхідні токени: Що це таке і як вони стягуються
Вхідні лексеми є основними одиницями тексту, які обробляє LLM. Вони, як правило, відповідають частинам слів, причому поширені слова часто представлені одним токеном, а менш поширені слова розбиваються на кілька токенів. Наприклад, речення "The quick brown fox" можна представити як ["The", "quick", "bro", "wn", "fox"], що дає 5 вхідних токенів.
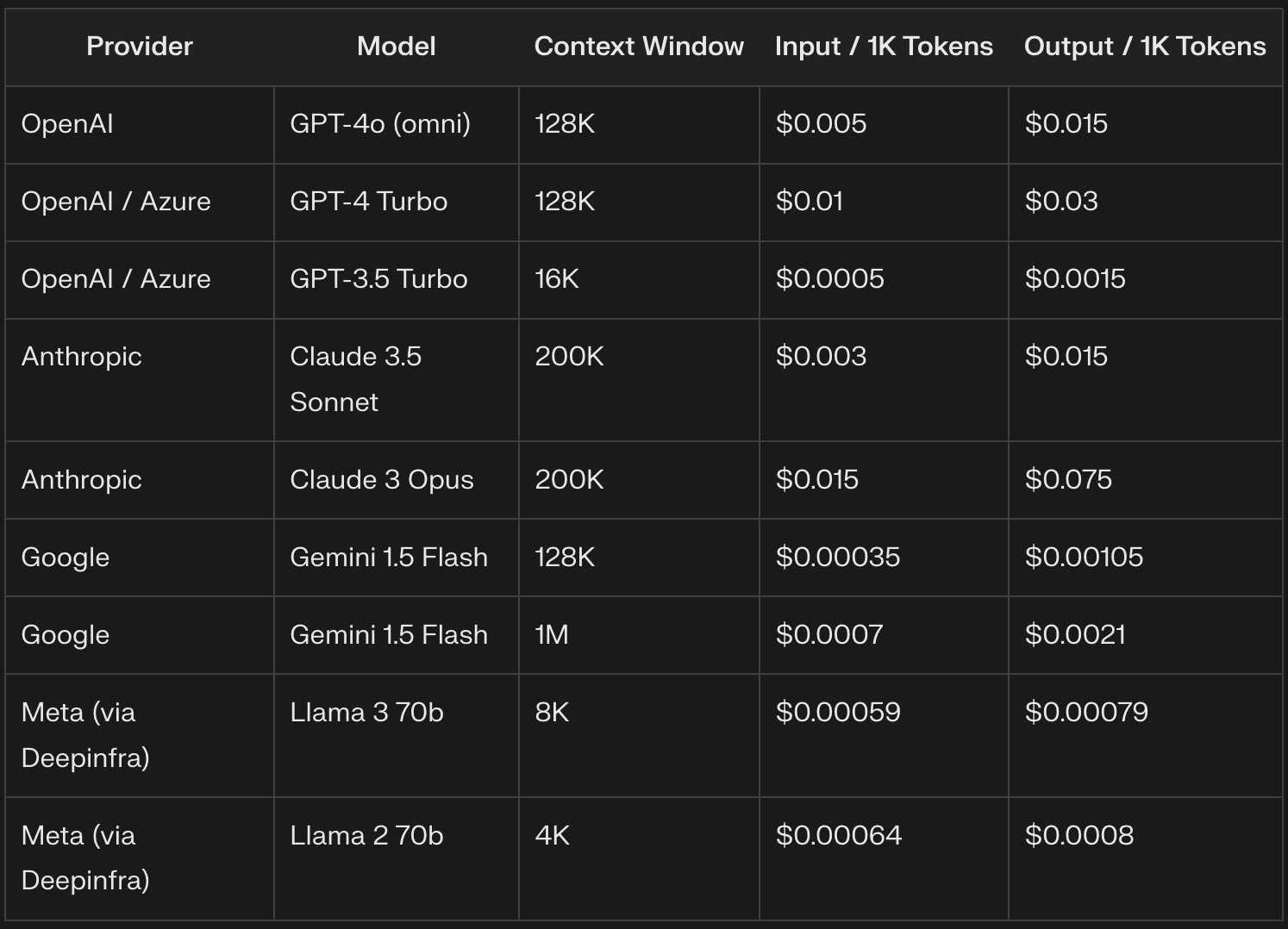
Провайдери LLM часто стягують плату за вхідні токени на основі тарифу за тисячу токенів. Наприклад, GPT-4o стягує $5 за 1 мільйон вхідних токенів, що дорівнює $0,005 за 1 000 вхідних токенів. Точна ціна може суттєво відрізнятися залежно від постачальника та версії моделі, причому більш просунуті моделі, як правило, мають вищі тарифи.
Щоб ефективно управляти витратами на LLM, розгляньте ці стратегії оптимізації використання вхідних токенів:
Створюйте лаконічні підказки: Виключіть зайві слова і зосередьтеся на чітких, прямих інструкціях.
Використовуйте ефективне кодування: Виберіть метод кодування, який представляє ваш текст з меншою кількістю токенів.
Впроваджуйте шаблони підказок: Розробляйте та повторно використовуйте оптимізовані структури підказок для спільних завдань.
Ретельно керуючи вхідними токенами, ви можете значно скоротити витрати, пов'язані з використанням LLM, зберігаючи при цьому якість і ефективність ваших додатків зі штучним інтелектом.
Вихідні токени: Розуміння вартості
Вихідні маркери представляють текст, згенерований LLM у відповідь на ваше введення. Подібно до вхідних токенів, вихідні токени обчислюються на основі процесу токенізації моделі. Однак кількість вихідних токенів може суттєво відрізнятися залежно від завдання та конфігурації моделі. Наприклад, просте запитання може згенерувати коротку відповідь з невеликою кількістю токенів, тоді як запит на детальне пояснення може призвести до появи сотень токенів.
Провайдери LLM часто встановлюють ціну на вихідні токени інакше, ніж на вхідні, як правило, за вищою ставкою через обчислювальну складність генерації тексту. Наприклад, OpenAI стягує $15 за 1 мільйон токенів ($0.015 за 1 000 токенів) за GPT-4o.
Оптимізувати використання вихідних токенів і контролювати витрати:
Встановіть чіткі обмеження на довжину виводу у підказках або викликах API.
Використовуйте такі методи, як "навчання з кількох пострілів", щоб спрямувати модель до більш стислих відповідей.
Впровадити постобробку для видалення непотрібного контенту з результатів LLM.
Розгляньте можливість кешування часто запитуваної інформації, щоб зменшити кількість дзвінків до LLM.
Контекстні вікна: Драйвер прихованих витрат
Контекстні вікна визначають, скільки попереднього тексту LLM може врахувати, генеруючи відповідь. Ця функція має вирішальне значення для підтримання зв'язності в діалогах і дозволяє моделі посилатися на попередню інформацію. Розмір контекстного вікна може суттєво вплинути на продуктивність моделі, особливо для завдань, що вимагають довготривалої пам'яті або складних міркувань.
Більші контекстні вікна безпосередньо збільшують кількість вхідних лексем, які обробляються моделлю, що призводить до збільшення витрат. Наприклад:
Модель з контекстним вікном на 4 000 токенів, що обробляє розмову на 3 000 токенів, стягуватиме плату за всі 3 000 токенів.
Та сама розмова з контекстним вікном на 8 000 токенів може коштувати 7 000 токенів, включаючи попередні частини розмови.
Таке масштабування може призвести до значного збільшення витрат, особливо для додатків, що обробляють довгі діалоги або аналіз документів.
Оптимізувати використання контекстного вікна:
Реалізуйте динамічне визначення розміру контексту на основі вимог завдання.
Використовуйте методи узагальнення, щоб сконденсувати важливу інформацію з довгих розмов.
Використовуйте метод "ковзного вікна" для обробки довгих документів, зосереджуючись на найбільш важливих розділах.
Розгляньте можливість використання менших, спеціалізованих моделей для завдань, які не потребують великого контексту.
Ретельно керуючи контекстними вікнами, ви можете досягти балансу між підтримкою високої якості результатів і контролем витрат на LLM. Пам'ятайте, що мета полягає в тому, щоб забезпечити достатній контекст для виконання поставленого завдання без надмірного роздування використання токенів і пов'язаних з цим витрат.
Майбутні тенденції в ціноутворенні на LLM
У міру того, як ландшафт LLM розвивається, ми можемо побачити зміни в структурі цін:
Ціноутворення на основі завдань: Моделі стягують плату на основі складності завдання, а не кількості токенів.
Моделі підписки: Фіксований доступ до LLM з лімітами використання або багаторівневою тарифікацією.
Ціноутворення на основі ефективності: Витрати, пов'язані з якістю або точністю результатів, а не лише з кількістю.
Вплив технологічного прогресу на витрати
Постійні дослідження та розробки в галузі ШІ можуть призвести до того, що
Більш ефективні моделі: Зменшення обчислювальних вимог, що призводить до зниження операційних витрат.
Покращена техніка стиснення: Вдосконалено методи зменшення кількості вхідних та вихідних токенів.
Інтеграція периферійних обчислень: Локальна обробка завдань LLM, що потенційно зменшує витрати на хмарні обчислення.
Підсумок
Розуміння структури ціноутворення LLM має важливе значення для ефективного управління витратами на корпоративні програми штучного інтелекту. Розуміючи нюанси вхідних токенів, вихідних токенів і контекстних вікон, організації можуть приймати обґрунтовані рішення щодо вибору моделі та моделей використання. Впровадження стратегічних методів управління витратами, таких як оптимізація використання токенів і використання кешування, може призвести до значної економії.
Оскільки технологія LLM продовжує розвиватися, постійне інформування про цінові тенденції та нові стратегії оптимізації матиме вирішальне значення для підтримки рентабельності операцій зі штучним інтелектом. Пам'ятайте, що успішне управління витратами на LLM - це безперервний процес, який вимагає постійного моніторингу, аналізу та адаптації, щоб забезпечити максимальну віддачу від ваших інвестицій у ШІ.
Якщо ви хочете дізнатися про те, як ваше підприємство може ефективніше використовувати цінові структури LLM, не соромтеся звертатися до нас!


