
Навчальний посібник: Як налаштувати BERT для екстрактивного узагальнення



Навчальний посібник: Як налаштувати BERT для екстрактивного узагальнення
Вперше опубліковано дослідником машинного навчання Skim AI, Крісом Траном![]()
1. Вступ
Підсумовування вже давно є складним завданням в обробці природної мови. Щоб створити коротку версію документа, зберігаючи його найважливішу інформацію, нам потрібна модель, здатна точно виокремити ключові моменти, уникаючи повторюваної інформації. На щастя, нещодавні роботи в галузі НЛП, такі як моделі-трансформери та попереднє навчання мовних моделей, просунули вперед сучасні технології в галузі узагальнення.
У цій статті ми розглянемо BERTSUM, простий варіант BERT, для екстрактивного підсумовування з Підсумовування тексту за допомогою попередньо навчених кодерів (Лю та ін., 2019). Потім, прагнучи зробити екстрактивне узагальнення ще швидшим і меншим для пристроїв з низькими ресурсами, ми доопрацюємо DistilBERT (Sanh та ін., 2019) та MobileBERT (Sun та ін., 2019), дві нещодавні полегшені версії BERT та обговорити наші результати.
2. Екстрактне підбиття підсумків
Існує два типи узагальнення: абстрактний і екстрактивне узагальнення. Абстрактне реферування в основному означає переписування ключових моментів, тоді як екстрактивне реферування створює резюме шляхом прямого копіювання найважливіших фрагментів/речень з документа.
Абстрактне узагальнення є більш складним для людини, а також більш дорогим для машин. Однак, який вид узагальнення є кращим, залежить від мети кінцевого користувача. Якщо ви пишете есе, абстрактне узагальнення може бути кращим вибором. З іншого боку, якщо ви проводите дослідження і вам потрібно отримати швидкий підсумок того, що ви прочитали, то для цього завдання більше підійде екстрактивне конспектування.
У цьому розділі ми розглянемо архітектуру нашої моделі екстрактивного узагальнення. BERT-підсумовувач складається з 2 частин: BERT-кодер та класифікатор підсумовування.
Кодер BERT

Загальна архітектура BERTSUM
Наш BERT-кодер є попередньо навченим BERT-базовим кодером із задачі моделювання маскованої мови (Девлін та ін., 2018). Задача екстрактивного узагальнення - це задача бінарної класифікації на рівні речень. Ми хочемо присвоїти кожному реченню мітку $y_i \in {0, 1}$, яка вказує на те, чи слід включати це речення в остаточний підсумок. Тому нам потрібно додати токен [CLS] перед кожним реченням. Після того, як ми виконаємо прямий прохід через кодер, останній прихований шар цих [CLS] будуть використовуватися як представлення для наших речень.
Класифікатор узагальнень
Отримавши векторне представлення кожного речення, ми можемо використовувати простий шар прямого поширення як наш класифікатор, щоб повернути оцінку для кожного речення. У статті автор експериментував з простим лінійним класифікатором, рекурентною нейронною мережею та невеликою трансформаторною моделлю з 3-ма шарами. Класифікатор Transformer дає найкращі результати, показуючи, що взаємодія між реченнями через механізм самоуваги важлива для вибору найбільш важливих речень.
Отже, в кодувальнику ми вивчаємо взаємодію між токенами в нашому документі, тоді як в класифікаторі узагальнення ми вивчаємо взаємодію між реченнями.
3. Зробіть підбиття підсумків ще швидшим
Трансформаторні моделі демонструють найкращі результати в більшості тестів НЛП, проте навчання та прогнозування на їх основі є дорогими з точки зору обчислень. Намагаючись зробити узагальнення легшим і швидшим для розгортання на пристроях з низькими ресурсами, я модифікував вихідні коди надано авторами BERTSUM для заміни кодера BERT на DistilBERT та MobileBERT. Підсумкові шари залишено без змін.
Ось тренувальні втрати для цих 3 варіантів: TensorBoard

Незважаючи на те, що DistilBERT на 40% менший за BERT-base, він має такі ж втрати при навчанні, як і BERT-base, тоді як MobileBERT працює трохи гірше. У таблиці нижче показано їхню продуктивність на наборі даних CNN/DailyMail, розмір і час виконання прямої передачі:
| Моделі | РУЖИЦЯ-1 | РУЖИЦЯ-2 | ROUGE-L | Час висновків*. | Розмір | Параметри |
|---|---|---|---|---|---|---|
| bert-base | 43.23 | 20.24 | 39.63 | 1.65 s | 475 МБ | 120.5 M |
| Дистильберт | 42.84 | 20.04 | 39.31 | 925 мс | 310 МБ | 77.4 M |
| mobilebert | 40.59 | 17.98 | 36.99 | 609 мс | 128 МБ | 30.8 M |
*Середній час виконання пасу вперед на одному графічному процесорі на стандартному ноутбуці Google Colab
Будучи на 45% швидшим, DistilBERT має майже таку ж продуктивність, як і BERT-base. MobileBERT зберігає 94% продуктивність BERT-base, будучи в 4 рази меншим за BERT-base і в 2.5 рази меншим за DistilBERT. У статті про MobileBERT показано, що MobileBERT значно перевершує DistilBERT на SquAD v1.1. Однак це не стосується екстрактивного підсумовування. Але це все одно вражаючий результат для MobileBERT з розміром диска всього 128 МБ.
4. Підіб'ємо підсумки
Всі попередньо підготовлені контрольно-пропускні пункти, деталі тренінгу та інструкцію з налаштування можна знайти в цей репозиторій GitHub. Крім того, я розгорнув демонстраційну версію BERTSUM з кодувальником MobileBERT.
Веб-додаток: https://extractive-summarization.herokuapp.com/
![]()
Код:
![]()
import torch
from models.model_builder import ExtSummarizer
from ext_sum import summarize
# Завантажити модель
model_type = 'mobilebert' #@param ['bertbase', 'distilbert', 'mobilebert'].
checkpoint = torch.load(f'checkpoints/{type_моделі}_ext.pt', map_location='cpu')
model = ExtSummarizer(checkpoint=checkpoint, bert_type=model_type, device='cpu')
# Підсумок виконання
input_fp = 'raw_data/input.txt'
result_fp = 'results/summary.txt'
summary = summarize(input_fp, result_fp, model, max_length=3)
print(summary)
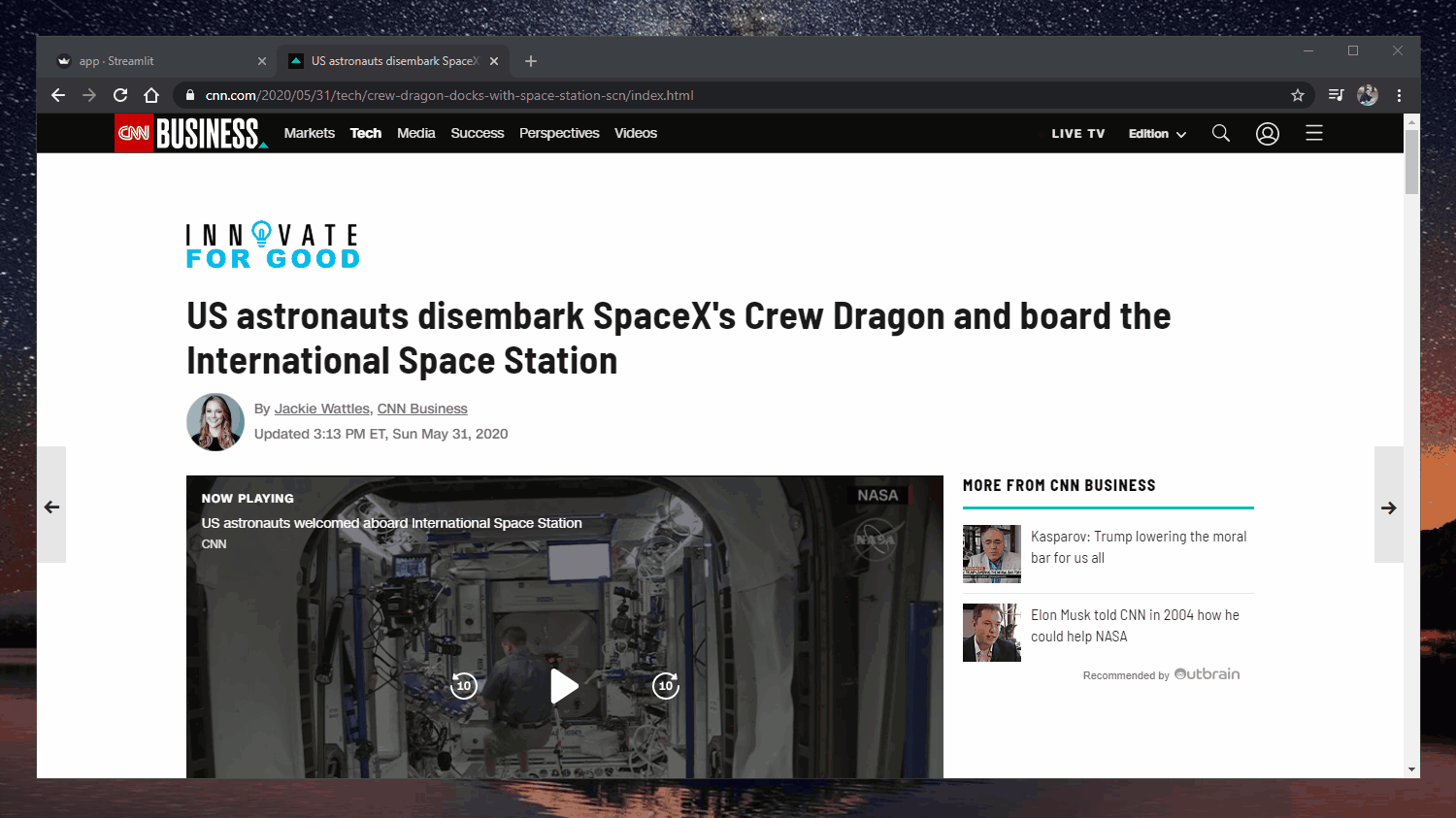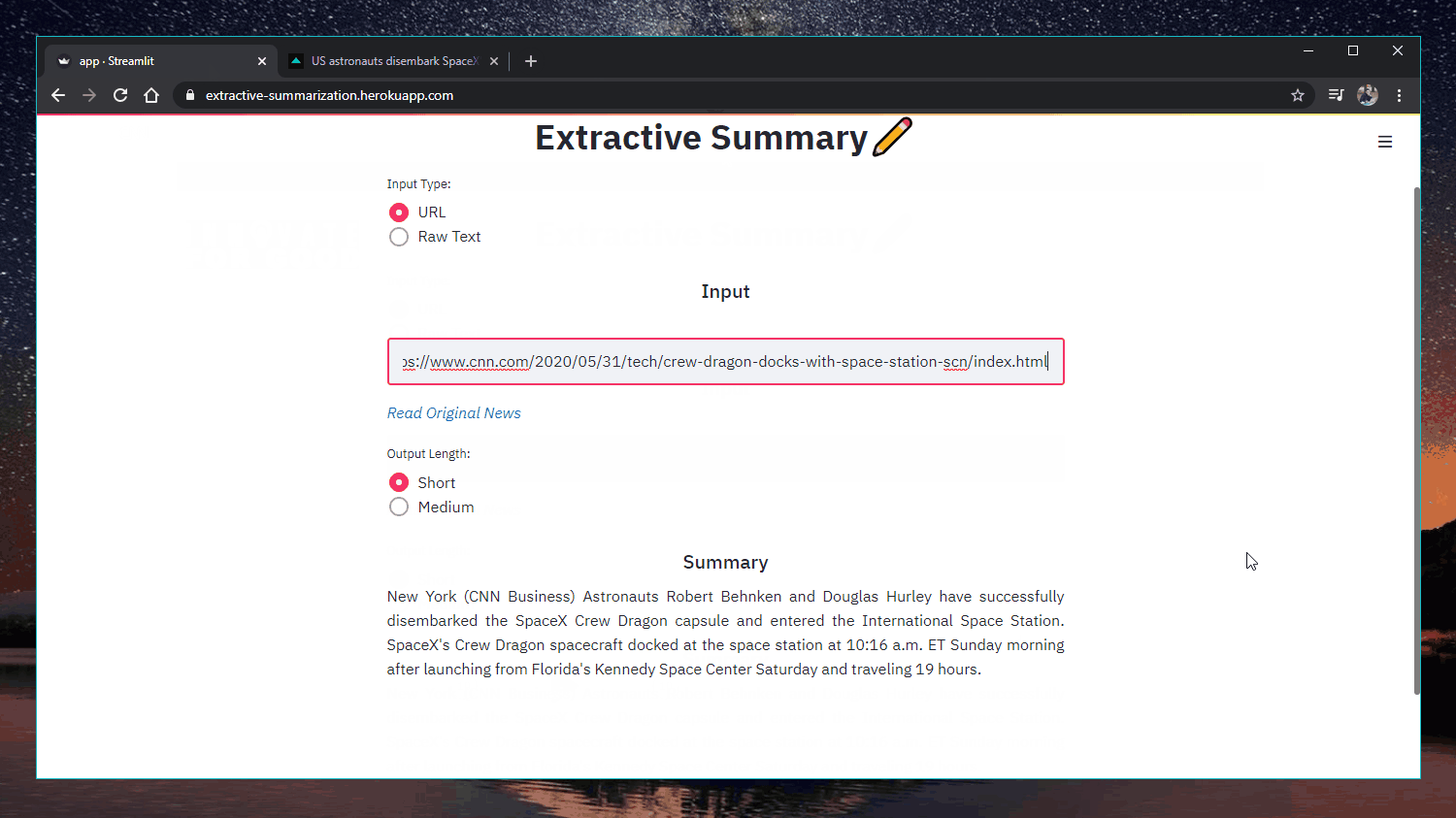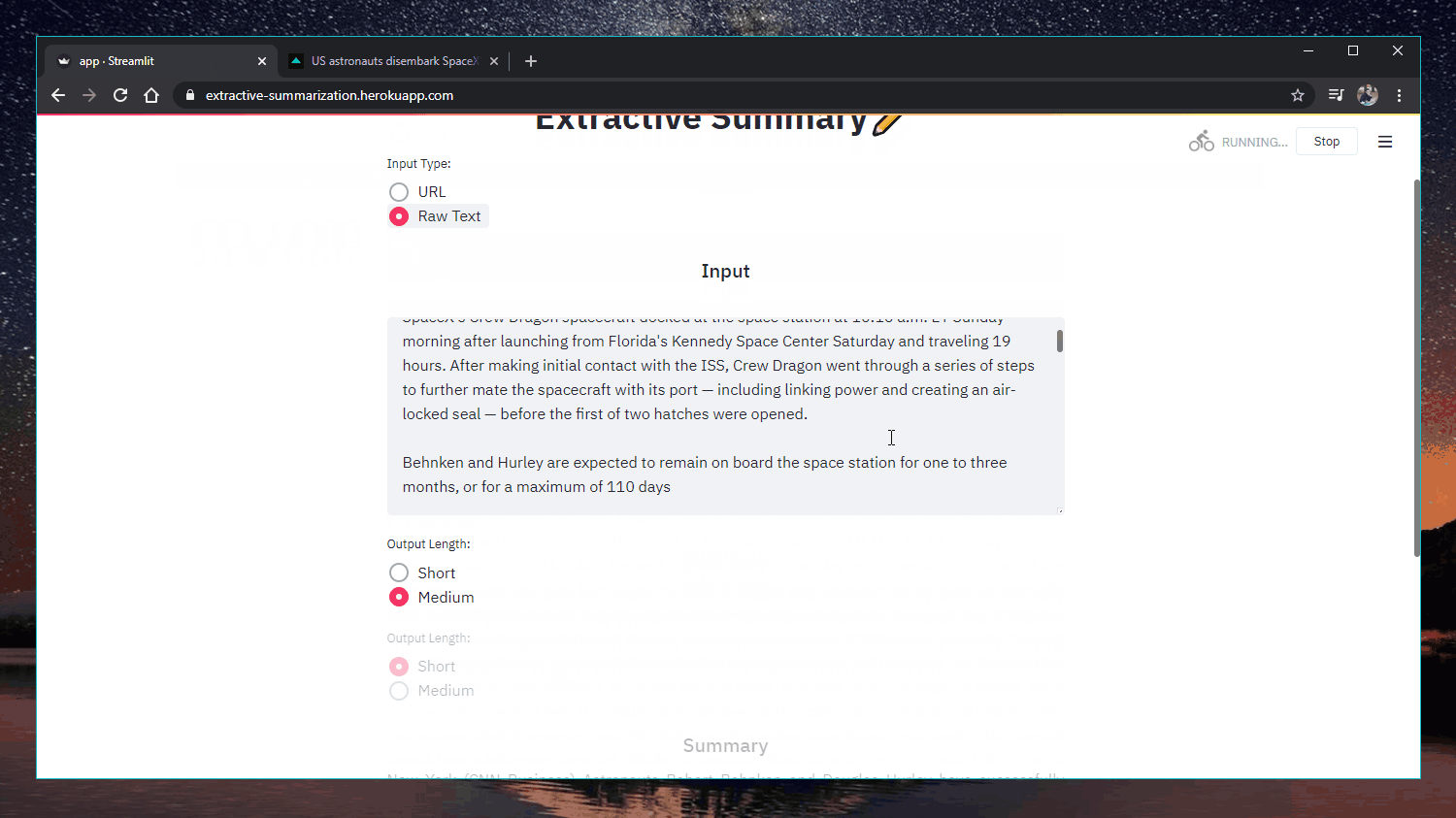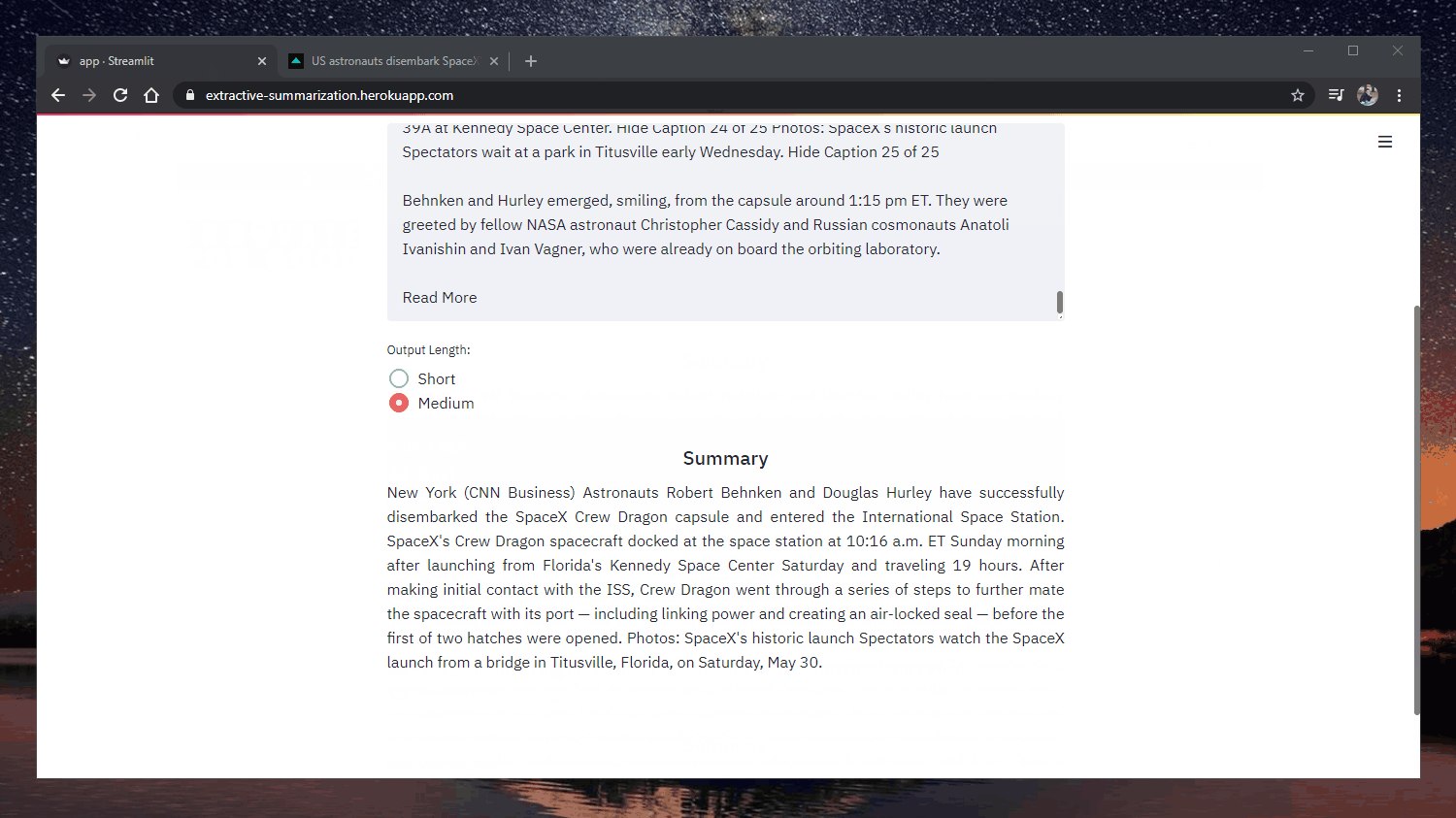
Зразок резюме
Оригінально: https://www.cnn.com/2020/05/22/business/hertz-bankruptcy/index.html
Оголошуючи про банкрутство, Hertz заявляє, що має намір залишитися в бізнесі, реструктуризувавши свої борги і ставши
фінансово здоровішою компанією. Компанія займається прокатом автомобілів з 1918 року, коли вона відкрила магазин з дюжиною
Ford Model Ts, і пережила Велику депресію, фактичну зупинку виробництва автомобілів у США під час Другої світової війни
та численні шоки цін на нафту. "Вплив Covid-19 на попит на подорожі був раптовим і драматичним, спричинивши
різке падіння доходів компанії та майбутніх замовлень", - йдеться у заяві компанії.
5. Висновок
У цій статті ми розглянули BERTSUM, простий варіант BERT, для вилучення резюме з документа Підсумовування тексту за допомогою попередньо навчених кодерів (Лю та ін., 2019). Потім, прагнучи зробити екстрактивне узагальнення ще швидшим і меншим для пристроїв з низькими ресурсами, ми допрацювали DistilBERT (Sanh та ін., 2019) і MobileBERT (Sun та ін., 2019) на наборах даних CNN/DailyMail.
DistilBERT зберігає продуктивність BERT-base в екстрактивному підсумовуванні, будучи меншим на 45%. MobileBERT в 4 рази менший і в 2,7 рази швидший за BERT-base, але зберігає його продуктивність на рівні 94%.
Нарешті, ми розгорнули демонстраційну версію веб-додатку MobileBERT для екстрактивного узагальнення за адресою https://extractive-summarization.herokuapp.com/.


