
Нам потрібно переосмислити ланцюжок думок (CoT), що підказує AI&YOU #68



Статистика тижня: Продуктивність CoT при нульовому пострілі становила лише 5,55% для GPT-4-Turbo, 8,51% для Claude-3-Opus і 4,44% для GPT-4. ("Ланцюг бездумності?", стаття)
Підказки "ланцюжок думок" (Chain-of-Thought, CoT) були визнані проривом у розкритті можливостей міркування за допомогою великих мовних моделей (ВММ). Однак нещодавні дослідження поставили під сумнів ці твердження і спонукали нас переглянути цю техніку.
У цьому випуску AI&YOU ми ділимося думками з трьох блогів, які ми опублікували на цю тему:
Нам потрібно переосмислити ланцюжок думок (CoT), що підказує AI&YOU #68
LLM демонструють чудові можливості в обробці та генерації природної мови (NLP). Однак, коли ці моделі стикаються зі складними завданнями міркування, вони можуть не давати точних і надійних результатів. Саме тут у гру вступає підказка "ланцюжок думок" (Chain-of-Thought, CoT) - техніка, яка має на меті покращити здатність LLMs вирішувати проблеми.
Просунутий оперативний інжиніринг Він призначений для того, щоб допомогти студентам LLM пройти через покроковий процес міркувань. На відміну від стандартних методів підказок, які спрямовані на отримання прямих відповідей, підказки CoT заохочують модель генерувати проміжні кроки міркувань, перш ніж прийти до остаточної відповіді.
По суті, підказки CoT передбачають структурування підказок таким чином, щоб викликати логічну послідовність думок у моделі. Розбиваючи складні проблеми на менші, керовані кроки, CoT намагається допомогти магістрам права більш ефективно рухатися складними шляхами міркувань.
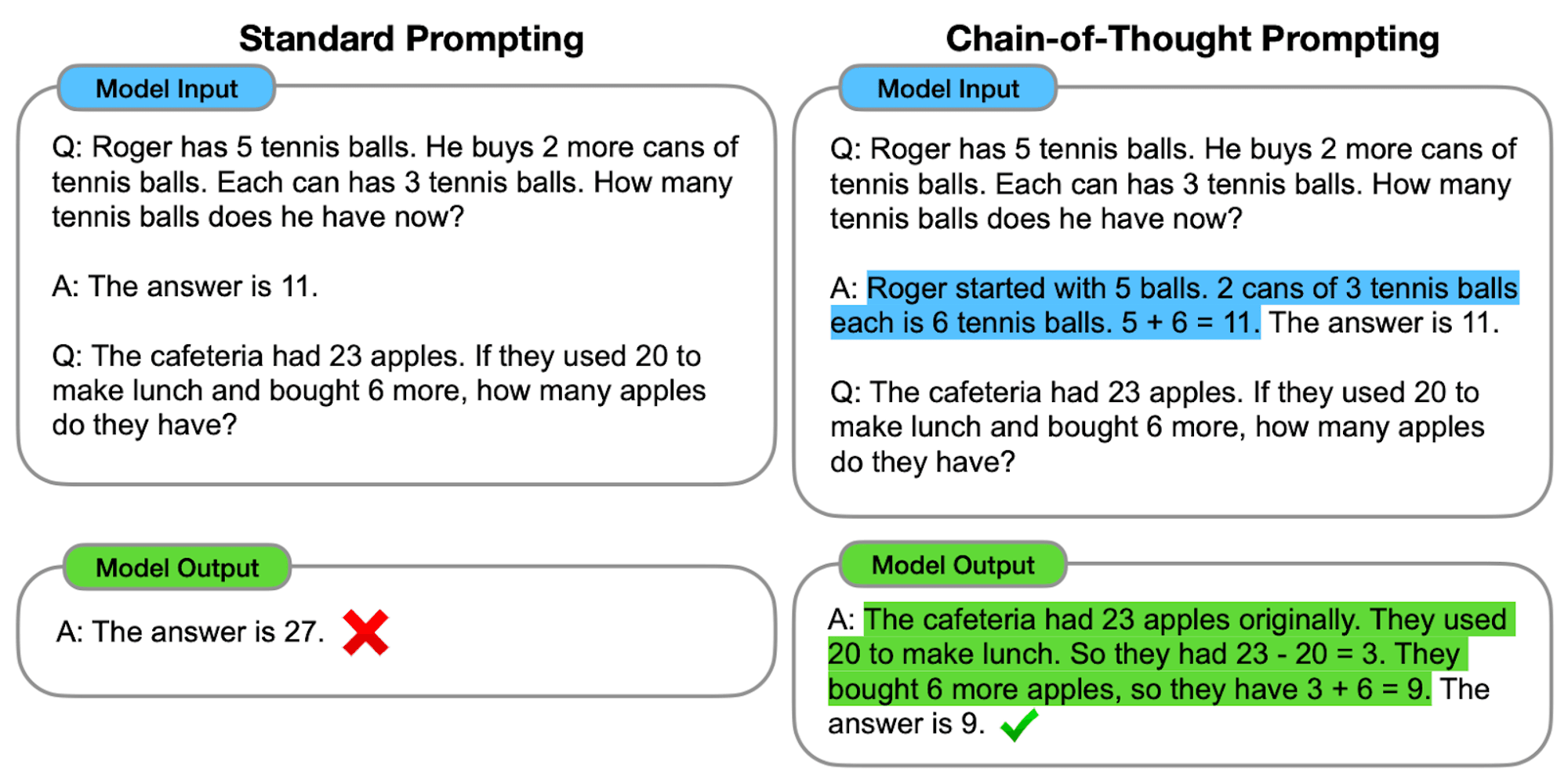
Як працює CoT
По суті, підказка CoT спрямовує мовні моделі через низку проміжних кроків міркувань до отримання остаточної відповіді. Цей процес зазвичай включає в себе
Декомпозиція проблеми: Складне завдання розбивається на менші, керовані кроки.
Покрокові міркування: Модель спонукає чітко продумувати кожен крок.
Логічний розвиток: Кожен крок спирається на попередній, створюючи ланцюжок думок.
Висновки: Остаточна відповідь виводиться з накопичених кроків міркувань.
Типи підказок CoT
Підказка "ланцюжок думок" може бути реалізована різними способами, серед яких можна виділити два основних типи:
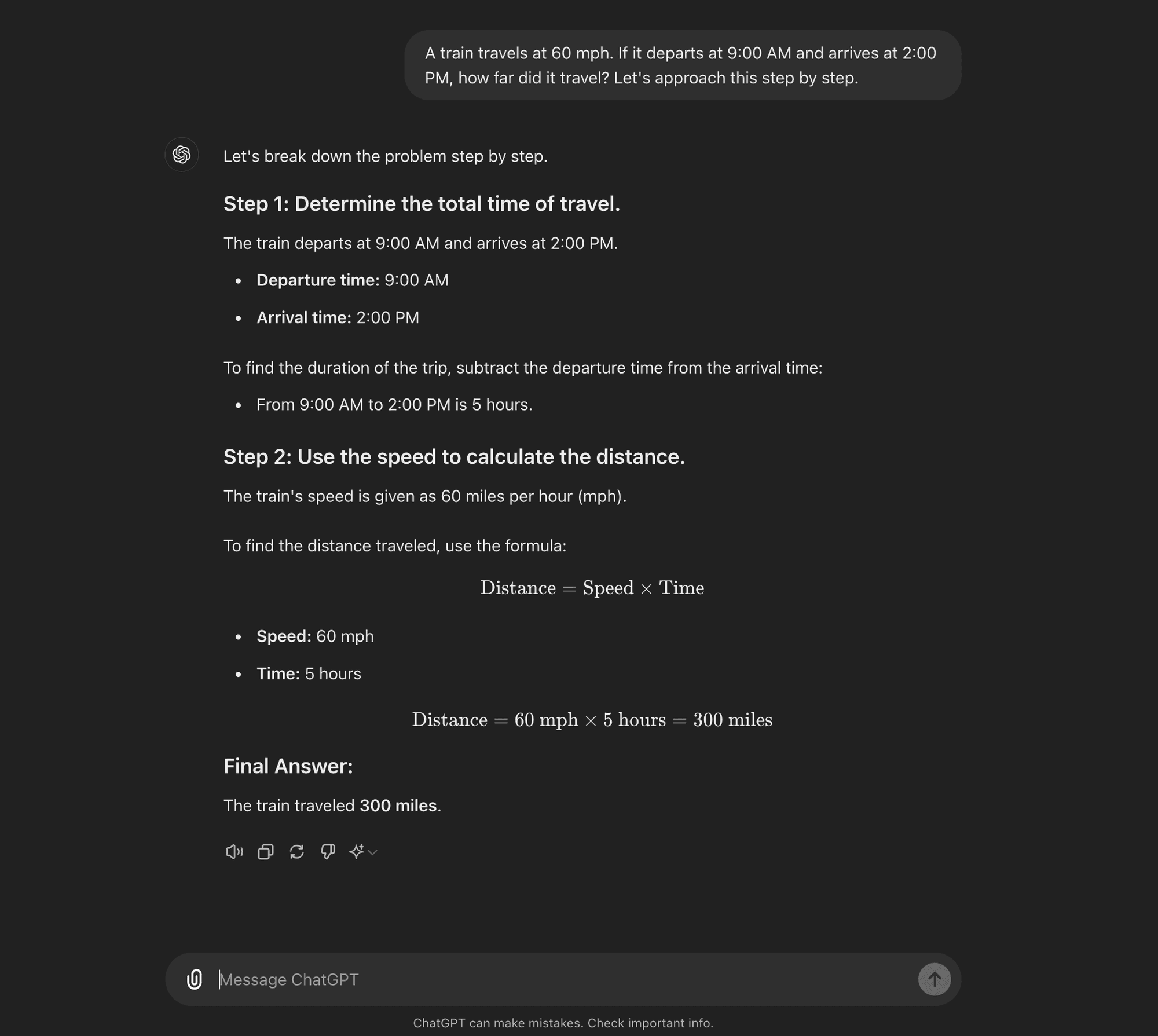
Нульовий постріл: Метод "нульового пострілу" не вимагає прикладів для конкретних завдань. Замість цього він використовує просту підказку на кшталт "Давайте розглянемо це крок за кроком", щоб заохотити модель розбити процес міркувань на частини.****
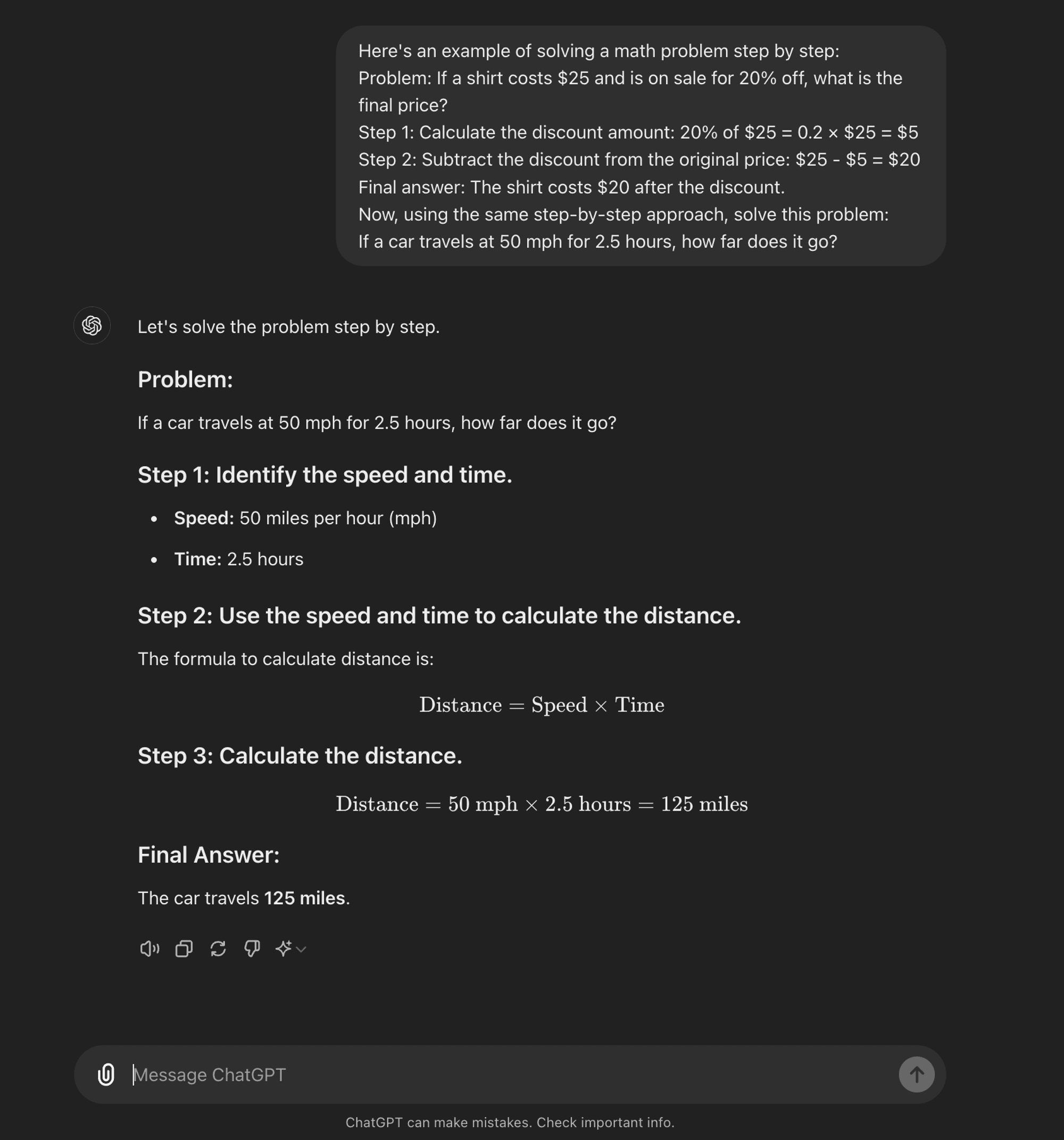
Кілька пострілів з ПТРК: Малопоширений метод передбачає надання моделі невеликої кількості прикладів, які демонструють бажаний процес міркувань. Ці приклади слугують шаблоном для моделі, якому вона має слідувати при вирішенні нових, непередбачуваних проблем.
CoT з нульовим пострілом
Кілька пострілів CoT
Розбивка дослідницьких робіт зі штучного інтелекту: "Ланцюг бездумності?"
Тепер, коли ви знаєте, що таке КПТ, ми можемо зануритися в деякі нещодавні дослідження, які ставлять під сумнів деякі її переваги і дають певне уявлення про те, коли вона насправді корисна.
Дослідницька робота під назвою "Ланцюг бездумності? Аналіз CoT у плануванні," містить критичний аналіз ефективності та узагальнюваності підказок CoT. Для практиків ШІ дуже важливо розуміти ці висновки та їхні наслідки для розробки додатків ШІ, які потребують складних міркувань.

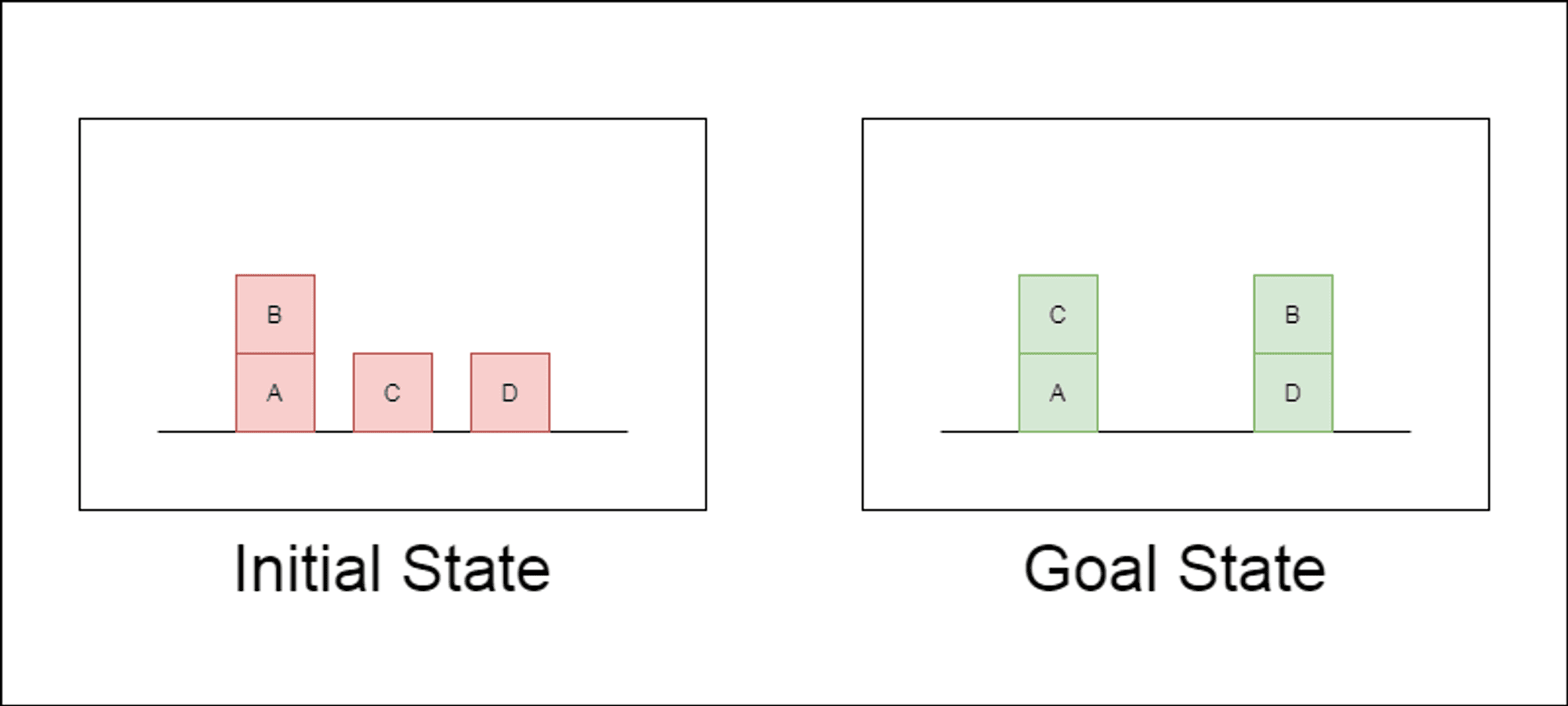
Дослідники обрали класичний домен планування під назвою Blocksworld як основний полігон для тестування. У Blocksworld завдання полягає в тому, щоб переставити набір блоків з початкової конфігурації в цільову за допомогою серії дій переміщення. Цей домен ідеально підходить для тестування міркувань та можливостей планування, тому що:
Дозволяє генерувати завдання різної складності
Вона має чіткі, алгоритмічно верифіковані рішення
Навряд чи він буде широко представлений у навчальних даних LLM
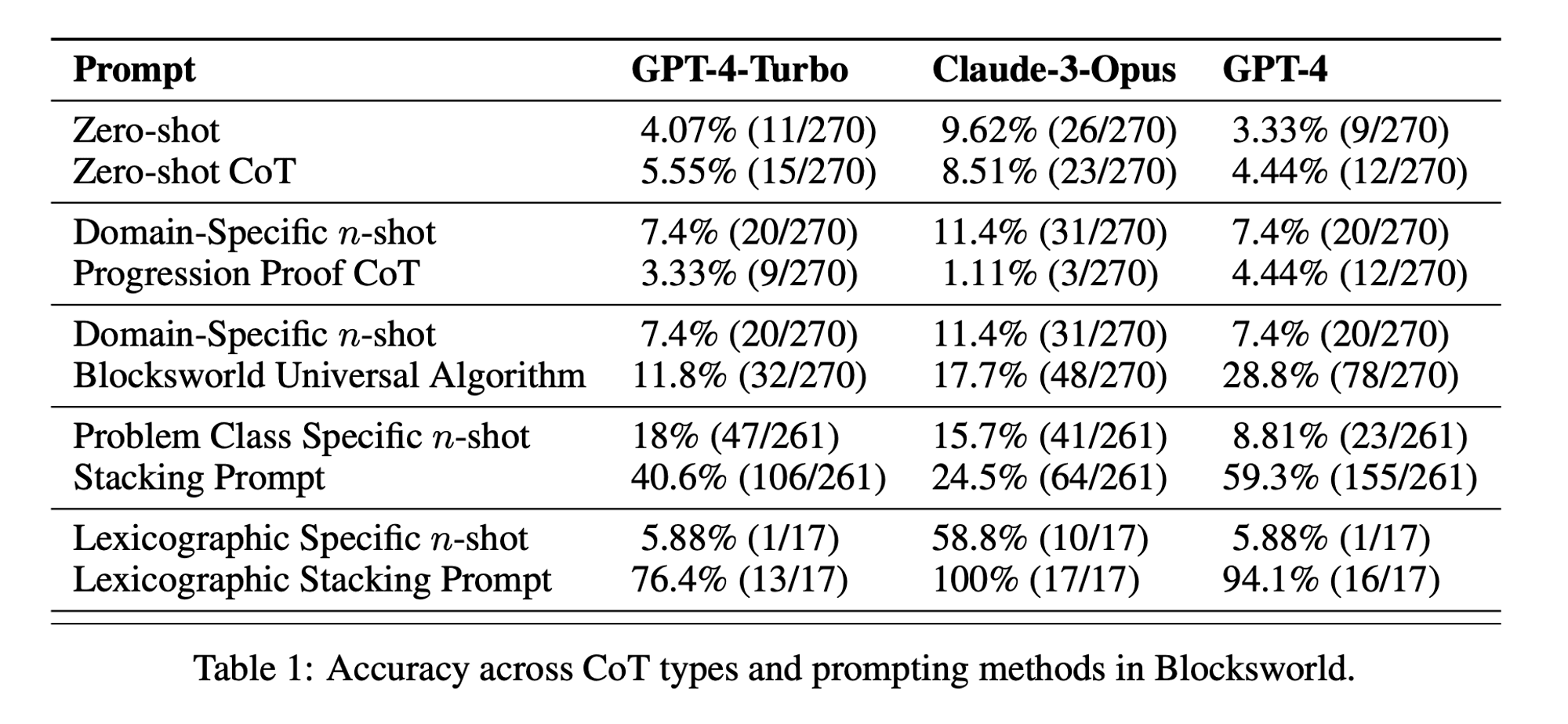
У дослідженні розглядалися три найсучасніші LLM: GPT-4, Claude-3-Opus та GPT-4-Turbo. Ці моделі були протестовані з використанням підказок різної специфічності:
Ланцюг думок з нульовим пострілом (універсальний): Просто додайте до підказки "давайте поміркуємо крок за кроком".
Доказ прогресування (специфічний для PDDL): Надання загального пояснення правильності плану з прикладами.
Універсальний алгоритм Blocksworld: Демонстрація загального алгоритму розв'язання будь-якої задачі на Blocksworld.
Підказка по укладанню: Зосередження на конкретному підкласі проблем Blocksworld (table-to-stack).
Лексикографічне укладання: Подальше звуження до конкретної синтаксичної форми стану мети.
Тестуючи ці підказки на проблемах зростаючої складності, дослідники мали на меті оцінити, наскільки добре магістри права можуть узагальнювати міркування, продемонстровані в прикладах.
Оприлюднено ключові висновки
Результати цього дослідження ставлять під сумнів багато поширених припущень щодо спонукання до застосування ЗПТ:
Обмежена ефективність ЗПТ: Всупереч попереднім заявам, підказки CoT показали значне покращення продуктивності лише тоді, коли наведені приклади були надзвичайно схожими на проблему запиту. Як тільки проблеми відхилялися від точного формату, показаного в прикладах, продуктивність різко падала.
Швидка деградація продуктивності: Зі збільшенням складності завдань (вимірюваної кількістю задіяних блоків) точність усіх моделей різко знижувалася, незалежно від використовуваної підказки CoT. Це свідчить про те, що LLMs намагаються поширити міркування, продемонстровані в простих прикладах, на більш складні сценарії.
Неефективність загальних підказок: Дивно, але більш загальні підказки CoT часто показували гірші результати, ніж стандартні підказки без прикладів міркувань. Це суперечить ідеї, що CoT допомагає магістрам вивчити узагальнені стратегії розв'язання проблем.
Компроміс специфічності: Дослідження показало, що вузькоспецифічні підказки можуть забезпечити високу точність, але лише для дуже вузької підгрупи проблем. Це підкреслює гострий компроміс між підвищенням продуктивності та застосовністю підказки.
Відсутність справжнього алгоритмічного навчання: Результати переконливо свідчать про те, що LLMs не вчаться застосовувати загальні алгоритмічні процедури на прикладах CoT. Замість цього вони, здається, покладаються на зіставлення шаблонів, яке швидко ламається, коли стикаються з новими або більш складними проблемами.
Ці висновки мають важливе значення для фахівців у галузі ШІ та підприємств, які прагнуть використовувати підказки CoT у своїх додатках. Вони свідчать про те, що хоча CoT може підвищити продуктивність у певних вузьких сценаріях, він не може бути панацеєю для складних завдань, пов'язаних з міркуваннями, на яку багато хто сподівався.
Наслідки для розвитку штучного інтелекту
Висновки цього дослідження мають важливе значення для розвитку ШІ, особливо для підприємств, які працюють над додатками, що вимагають складних міркувань або можливостей планування:
Переоцінка ефективності CoT: Розробникам ШІ слід з обережністю покладатися на CoT для завдань, які вимагають справжнього алгоритмічного мислення або узагальнення нових сценаріїв.
Обмеження нинішніх магістерських програм: Альтернативні підходи можуть знадобитися для додатків, що вимагають надійного планування або багатокрокового вирішення проблем.
Вартість оперативного інжинірингу: Хоча вузькоспецифічні підказки CoT можуть давати хороші результати для вузького кола проблем, людські зусилля, необхідні для створення цих підказок, можуть переважати переваги, особливо з огляду на їхню обмежену узагальнюваність.
Переосмислення оціночних показників: Покладаючись виключно на статичні набори тестів, можна переоцінити справжні можливості моделі.
Розрив між сприйняттям і реальністю: Існує значна розбіжність між уявленнями про розумові здібності магістрів права (які часто антропоморфізуються в популярному дискурсі) та їхніми реальними можливостями, як продемонстровано в цьому дослідженні.
Рекомендації для практиків штучного інтелекту:
Оцінка: Впроваджуйте різноманітні фреймворки тестування, щоб оцінити справжнє узагальнення складності проблеми.
Використання CoT: Застосовуйте підказку "Ланцюжок думок" розумно, визнаючи її обмеженість в узагальненні.
Гібридні рішення: Подумайте про поєднання LLM з традиційними алгоритмами для складних завдань на міркування.
Прозорість: Чітко повідомляйте про обмеження системи штучного інтелекту, особливо для завдань міркування або планування.
R&D Focus: Інвестуйте в дослідження, щоб покращити здатність систем штучного інтелекту до справжнього мислення.
Налагоджую: Розгляньте можливість точного налаштування для конкретного домену, але пам'ятайте про потенційні межі узагальнення.
Для практиків і підприємств, що займаються ШІ, ці висновки підкреслюють важливість поєднання сильних сторін LLM зі спеціалізованими підходами до міркувань, інвестування в рішення для конкретних доменів, де це необхідно, і збереження прозорості щодо обмежень систем ШІ. У міру того, як ми рухаємося вперед, спільнота ШІ повинна зосередитися на розробці нових архітектур і методів навчання, які можуть подолати розрив між зіставленням шаблонів і справжнім алгоритмічним мисленням.
10 найкращих технік підказки для магістрів права
Цього тижня ми також розглянемо десять найпотужніших і найпоширеніших технік спонукання, пропонуючи інформацію про їхнє застосування та найкращі практики.

Добре продумані підказки можуть значно підвищити ефективність роботи LLM, забезпечуючи більш точні, релевантні та креативні результати. Незалежно від того, чи є ви досвідченим розробником ШІ, чи тільки починаєте вивчати магістерську програму, ці методи допоможуть вам розкрити весь потенціал ШІ-моделей.
Обов'язково перегляньте повний текст блогу, щоб дізнатися більше про кожну з них.
Дякуємо, що знайшли час прочитати AI & YOU!
Щоб отримати ще більше матеріалів про корпоративний ШІ, включаючи інфографіку, статистику, інструкції, статті та відео, підписуйтесь на канал Skim AI на LinkedIn
Ви засновник, генеральний директор, венчурний інвестор або інвестор, який шукає консультації з питань ШІ, фракційної розробки ШІ або послуги Due Diligence? Отримайте рекомендації, необхідні для прийняття обґрунтованих рішень щодо продуктової стратегії та інвестиційних можливостей вашої компанії у сфері ШІ.
Ми створюємо індивідуальні AI-рішення для компаній, що підтримуються венчурним та приватним капіталом, у наступних галузях: Медичні технології, новини/контент-агрегація, кіно- та фото-виробництво, освітні технології, юридичні технології, фінтех та криптовалюта.


