
ベクターデータベース+RAGで強力なLLMアプリケーションを構築する方法 - AI&YOU#55



今週のスタッツ/ファクト 2023年の2%から、2026年までに30%の企業が生成AIモデルの基盤としてベクターデータベースを使用する。(ガートナー)
GPT-4、Claude、Llama 3のようなLLMは、人間のようなテキストを理解し、生成する顕著な能力を示し、企業がNLPを導入するための強力なツールとして登場した。しかし、これらのLLMは、特にドメイン固有の情報を扱う場合、文脈の認識と精度でしばしば苦労する。
そこで今週のAI&YOUでは、私たちが公開した3つのブログを通して、こうした課題にどのように取り組んでいるかを探ってみたい:
ベクターデータベースとRAGを組み合わせた強力なLLMアプリ - AI&YOU #55
このような課題に対処するため、研究者や開発者は、検索拡張世代(Retrieval Augmented Generation)のような革新的な技術に目を向けてきた。ラグ)とベクトル・データベースがある。RAGはLLMが外部の知識ベースから関連情報にアクセスし検索できるようにすることでLLMを強化し、ベクトルデータベースは高次元のデータ表現を保存しクエリするための効率的でスケーラブルなソリューションを提供する。
ベクター・データベースとRAGの相乗効果
ベクターデータベースとRAGは、大規模言語モデルの能力を向上させる強力な相乗効果を形成する。この相乗効果の中核には、知識ベース埋め込みデータの効率的な保存と検索があります。ベクトルデータベースは、データの高次元ベクトル表現を扱うように設計されています。このデータベースは高速かつ正確な類似検索を可能にし、LLMが膨大な知識ベースから関連情報を素早く取り出すことを可能にします。
ベクトルデータベースとRAGを統合することで、LLMの応答を外部の知識で補強するためのシームレスなパイプラインを構築することができる。LLMがクエリを受け取ると、RAGはクエリの埋め込みに基づく最も関連性の高い情報を見つけるためにベクトルデータベースを効率的に検索することができる。この検索された情報は、LLMのコンテキストを豊かにするために使用され、より正確で有益な応答をリアルタイムで生成することを可能にする。
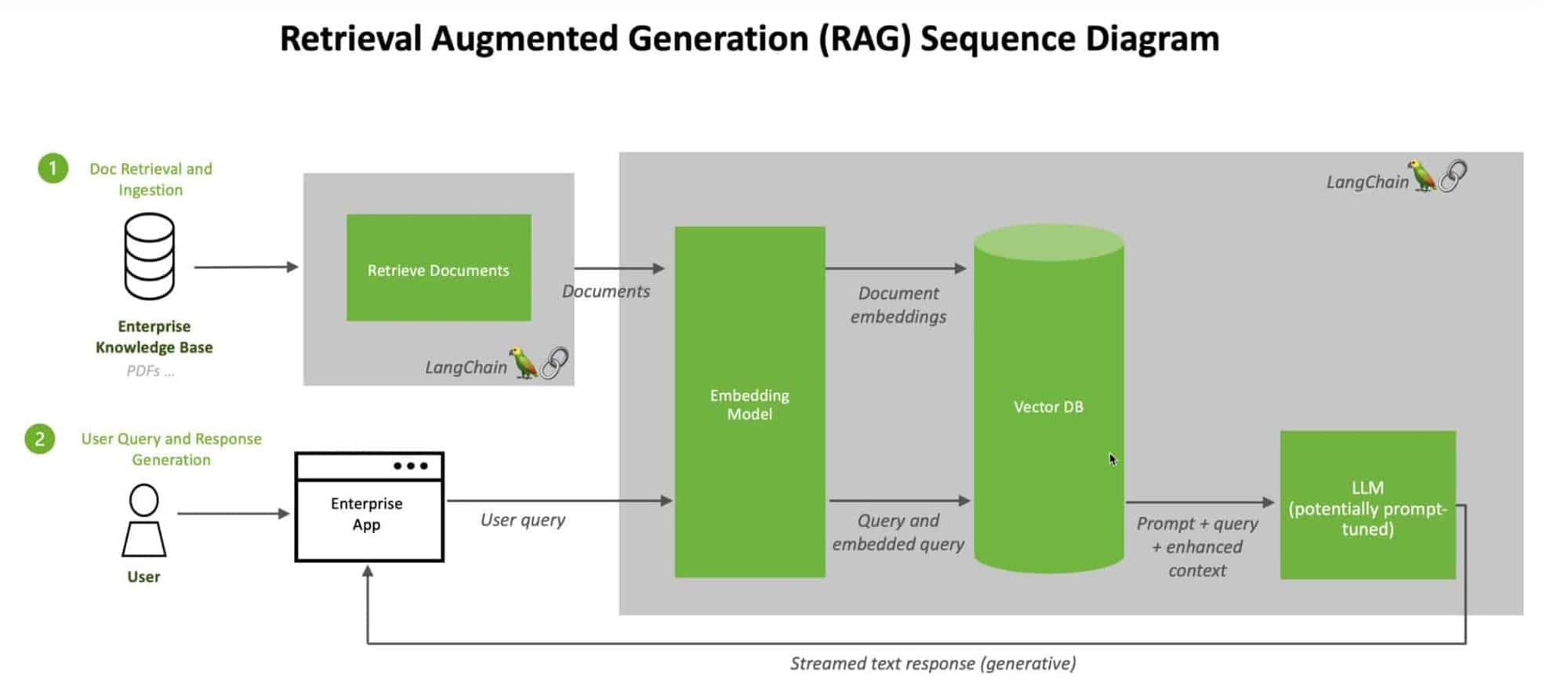
ベクターデータベースとRAGを組み合わせる利点
ベクトル・データベースとRAGを組み合わせることで、大規模な言語モデル・アプリケーションにいくつかの大きなメリットがもたらされる:
精度の向上と幻覚の減少
ベクトル・データベースとRAGを組み合わせる主な利点の一つは、LLMの回答の精度が大幅に向上することである。LLMに関連する外部知識へのアクセスを提供することで、RAGは「幻覚」(モデルが一貫性のない情報や事実と異なる情報を生成するケース)の発生を減らすのに役立ちます。信頼できる情報源からドメイン固有の情報を取得し、取り入れる能力により、LLMはより正確で信頼できる出力を生成することができます。
スケーラビリティとパフォーマンス
ベクターデータベースは効率的に拡張できるように設計されており、大量の高次元データを扱うことができる。このスケーラビリティは、リアルタイムで検索・取得する必要がある広範な知識ベースを扱う際には極めて重要である。ベクトルデータベースのパワーを活用することで、RAGは高速で効率的な類似検索を行うことができ、LLMは検索された情報の質を落とすことなく、迅速に回答を生成することができます。
ドメイン固有のアプリケーションを可能にする
ベクトルデータベースとRAGの組み合わせは、ドメインに特化したLLMアプリケーションを構築する新たな可能性を開く。様々なドメインに特化した知識ベースをキュレーションすることで、LLMはそのコンテクストの中で正確で関連性の高い情報を提供するように調整することができる。これにより、さまざまな業界やユースケースのユニークなニーズに対応できる、特化したAIアシスタント、チャットボット、知識管理システムの開発が可能になる。

ベクターデータベースによるRAGの実装
ベクターデータベースとRAGの組み合わせの力を活用するためには、導入プロセスを理解することが不可欠である。
ベクターデータベースを使用したRAGシステムのセットアップに関わる重要なステップを探ってみよう:
知識ベースの埋め込みをインデックス化し、保存する: 最初のステップは、知識ベースからのテキストデータを、BERTのような埋め込みモデルを使って高次元ベクトルに変換し、効率的な類似検索と検索のために、これらの埋め込みにインデックスを付けてベクトルデータベースに格納することである。
ベクターデータベースに関連情報を問い合わせる:LLMがクエリを受け取ると、RAGシステムは同じ埋め込みモデルを用いてクエリをベクトル表現に変換し、ベクトルデータベースは選択された類似度メトリックに基づいて、最も関連性の高い知識ベース埋め込みを検索する類似度検索を実行する。
検索された情報をLLMの回答に統合する: ベクトルデータベースから取得された関連情報は、元のクエリと連結するか、アテンションメカニズムのような技術を用いて、LLMの応答生成プロセスに統合され、LLMは拡張されたコンテキストに基づいて、より正確で有益な応答を生成することができる。
アプリケーションに適したベクトルデータベースの選択 適切なベクターデータベースを選択することは非常に重要であり、スケーラビリティ、パフォーマンス、使いやすさ、既存のテクノロジースタックとの互換性などの要素に加え、ナレッジベースのサイズ、クエリ量、希望する応答レイテンシなどの具体的な要件も考慮する必要があります。
ベストプラクティスと考察
ベクターデータベースを使用したRAGの導入を成功させるためには、いくつかのベストプラクティスと留意点があります。
検索のための知識ベースの埋め込みを最適化する:
知識ベースの埋め込み品質は非常に重要であり、様々な埋め込みモデルやテクニックを使って実験し、ドメイン固有のデータで微調整し、関連性と精度を維持するために、新しい情報が利用可能になると埋め込みを定期的に更新し、拡張する必要がある。
検索スピードと精度のバランス
検索速度と精度はトレードオフの関係にあり、許容できる精度を維持しながら検索を高速化するためには、近似最近傍探索のようなテクニックが必要であり、また、頻繁にアクセスされる埋め込みデータをキャッシュし、パフォーマンスを最適化するために負荷分散戦略を実装する必要がある。
データのセキュリティとプライバシーの確保
不正アクセスを防止し、知識ベース埋め込み内の機密データを保護するためには、関連するデータ保護規制を遵守しながら、安全なデータストレージ、アクセス制御、および同形暗号化などの暗号化技術を確立することが不可欠である。
システムの監視と保守
RAGシステムの長期的なパフォーマンスと信頼性を確保するためには、クエリーレイテンシー、検索精度、リソース使用率などのメトリクスを継続的に監視し、自動化された監視とアラートメカニズムを実装し、バックアップ、アップデート、パフォーマンスチューニングを含む強固なメンテナンススケジュールを確立することが不可欠です。
ベクターデータベースとRAGのパワーを企業で活用する
AIが私たちの未来を形成し続ける中、このような技術的進歩の最前線に立ち続けることは、企業にとって極めて重要です。ベクトル・データベースやRAGのような最先端のテクニックを探求し実装することで、大規模な言語モデルの可能性を最大限に引き出し、よりインテリジェントで適応性が高く、ROIの高いAIシステムを構築することができます。
オープンソースのベクターデータベースを使用する10のメリット
ベクターデータベースソリューションの中でも、オープンソースのベクターデータベースは、柔軟性、拡張性、費用対効果という魅力的な組み合わせを提供します。オープンソースコミュニティの総合力を活用することで、これらの特化型ベクターデータベースは、組織がデータ管理と分析に取り組む方法を再定義しています。
今週のブログでは、オープンソースのベクターデータベースを使用する利点トップ10を紹介した:
拡張性と費用対効果により、高いコストをかけずにシームレスな成長を実現し、ベンダーの囲い込みをなくし、予算に見合ったソリューションを提供します。
柔軟性とカスタマイズ性により、データベースを特定のニーズに合わせたり、機能を変更したり、既存のシステムと統合したりすることができる。
非構造化データを効率的に扱うには、NLPやベクトル埋め込みなどの技術を活用して、効率的な保存、検索、分析を行う。
強力なベクトル類似検索は、意味的類似性に基づく正確な検索を容易にし、パーソナライズされたレコメンデーションやインテリジェントなコンテンツ発見などのアプリケーションを可能にします。
オープンソースのエコシステムとの統合により、補完的なツールやフレームワークとの相互運用性が確保され、生産性が向上し、コラボレーションが促進される。
強固なセキュリティとデータプライバシー対策は、透明性、暗号化、アクセス制御、コンプライアンス基準の遵守を優先する。
高いパフォーマンスと効率的なデータ管理により、高速なクエリ実行と多様なワークロードに対応する汎用性を実現します。
高度なアナリティクスや機械学習との互換性により、最先端の技術やフレームワークとのシームレスな統合が可能になります。
将来を見据えたスケーラブルなアーキテクチャにより、シームレスな成長と、新たなテクノロジーや進化するデータ要件への適応が可能になります。
コミュニティ主導のイノベーションとサポートにより、継続的な改善、知識の共有、そしてこれらの強力なツールを活用するための貴重なリソースが育まれる。
企業向けベクターデータベース トップ5
今週は、トップ・ベネフィットの他に、企業向けベクター・データベース・トップ5についてのブログも公開した:
1.彩度
Chromaは、機械学習モデルやフレームワークとシームレスに統合できるように設計されており、AIを活用したアプリケーションの構築プロセスを簡素化します。効率的なベクトルストレージ、検索、類似検索、リアルタイムインデックス、メタデータストレージを提供します。セマンティック検索、レコメンデーション、異常検知などのユースケースで最適なパフォーマンスを実現するために、さまざまな距離メトリクスとインデックス作成アルゴリズムをサポートしています。

2.松ぼっくり
Pineconeは、高いパフォーマンスと使いやすさを優先した、フルマネージドのサーバーレスベクターデータベースです。高度なベクトル検索アルゴリズムとフィルタリング、分散インフラストラクチャを組み合わせ、高速で信頼性の高いベクトル検索を大規模に実現します。機械学習フレームワークやデータソースとシームレスに統合し、セマンティック検索、レコメンデーション、異常検知、質問応答などのアプリケーションに対応します。
3.Qdrant
Qdrant は、Rust で書かれたオープンソースの高速でスケーラブルなベクトル類似検索エンジンです。ベクターをメタデータとともに保存、検索、管理するための便利な API を提供し、マッチング、検索、レコメンデーションなどのためのプロダクションレディのアプリケーションを可能にします。リアルタイム更新、高度なフィルタリング、分散インデックス、クラウドネイティブなデプロイオプションなどの機能を備えています。
4.ウィービエイト
Weaviateは、スピード、スケーラビリティ、使いやすさを優先したオープンソースのベクトルデータベースです。オブジェクトとベクトルの両方を保存でき、ベクトル検索と構造化フィルタリングを組み合わせることができる。GraphQLベースのAPI、CRUD操作、水平スケーリング、クラウドネイティブなデプロイメントを提供する。NLPタスク、自動スキーマ構成、カスタムベクタ化のためのモジュールを組み込む。
5.ミルバス
Milvusは、埋め込み管理、類似検索、スケーラブルなAIアプリケーション向けに設計されたオープンソースのベクトルデータベースです。ヘテロジニアス計算のサポート、ストレージの信頼性、包括的なメトリクス、クラウドネイティブなアーキテクチャを提供する。インデックス、距離メトリクス、クエリタイプのための柔軟なAPIを提供し、カスタムプラグインで数十億ベクトルまで拡張可能です。
企業に適したベクターデータベースの選択
セマンティック検索エンジン、レコメンデーションシステム、その他AIを活用したアプリケーションのいずれを構築する場合でも、ベクトルデータベースは機械学習モデルの可能性を最大限に引き出すための基盤を提供します。これらのデータベースは、高速な類似検索、高度なフィルタリング、一般的なフレームワークとのシームレスな統合を可能にすることで、開発者がベクトルデータ管理の根本的な複雑さを心配することなく、革新的なソリューションの構築に集中できるようにします。
インフォグラフィックス、統計、ハウツーガイド、記事、ビデオなど、エンタープライズAIに関するその他のコンテンツについては、Skim AIをフォローしてください。 LinkedIn
創業者、CEO、ベンチャーキャピタリスト、投資家の皆様は、専門的なAIアドバイザリーまたはデューデリジェンスサービスをお探しですか?貴社のAI製品戦略や投資機会について、十分な情報に基づいた意思決定を行うために必要なガイダンスを得ることができます。
企業向けAIソリューションの立ち上げにお困りですか?当社のAIワークフォースマネジメント・プラットフォームを使用して独自のAI労働者を構築することをお考えですか?ご相談ください
カスタムメイドの AIソリューション ベンチャーキャピタルやプライベート・エクイティが支援する以下の業界の企業を対象としています:医療テクノロジー、ニュース/コンテンツアグリゲーション、映画/写真制作、教育テクノロジー、リーガルテクノロジー、フィンテック/暗号通貨。


