
LLMの幻覚をなくす方法トップ10



大規模言語モデル(LLM)がほぼすべての分野や産業を破壊し続ける中、LLMは幻覚というユニークな課題をもたらしている。このようなAIが生成する不正確さは、LLM出力の信頼性と信用性に重大なリスクをもたらす。
LLM幻覚とは何か?
LLMの幻覚は、これらの強力な言語モデルが、事実に反していたり、無意味であったり、入力データと無関係であったりするテキストを生成するときに発生する。一貫性があり自信に満ちているように見えるにもかかわらず、幻覚のようなコンテンツは、誤った情報、誤った意思決定、AIを搭載したアプリケーションに対する信頼の喪失につながる可能性がある。
AIシステムはますます進化している。 統合 顧客サービスのチャットボットから、私たちの生活のさまざまな側面にまで。 コンテンツ作成ツールそのため、幻覚を軽減する必要性が最も重要になる。幻覚をチェックしないと、風評被害、法的問題、AIが生成した情報に依存しているユーザーへの潜在的な危害をもたらす可能性がある。
データ中心のアプローチからモデル中心の手法、プロセス指向の手法まで、LLMの幻覚を軽減するための戦略トップ10をまとめた。これらの戦略は、企業や開発者がAIシステムの事実の正確さと信頼性を向上させるのに役立つように設計されています。
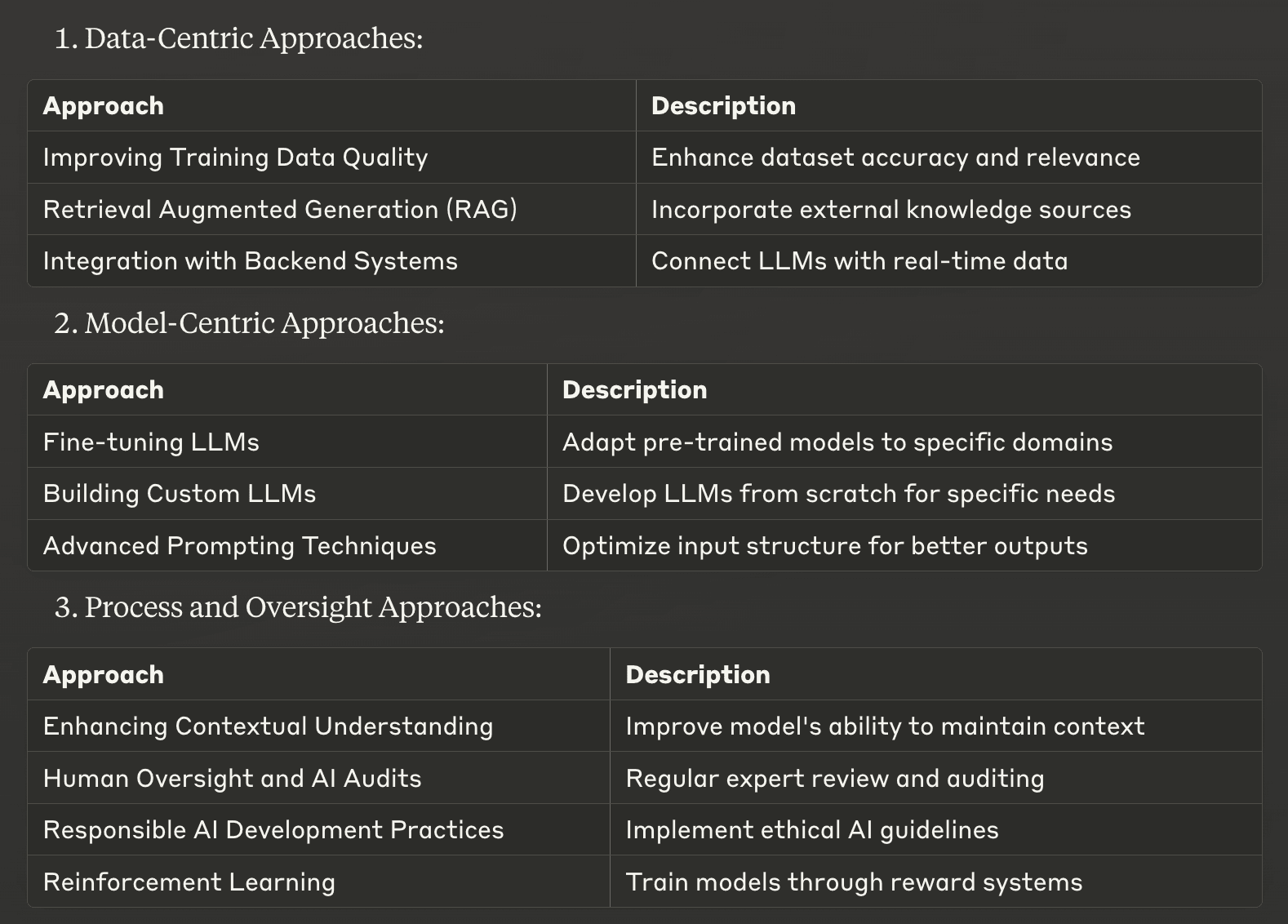
データ中心のアプローチ
1.トレーニングデータの質の向上
幻覚を軽減する最も基本的な方法の一つは、大規模言語モデルの開発に使用する学習データの質を高めることである。質が高く、多様で、よくキュレーションされたデータセットは、LLMが不正確な情報を学習し、再現する可能性を大幅に減らすことができる。
この戦略を実行するためには、次のことに集中する:
データソースの正確性と関連性を慎重に吟味する。
トピックと視点のバランスの取れた表現の確保
データセットを定期的に更新し、最新の情報を含める
重複または矛盾するデータポイントの削除
優れたトレーニングデータに投資することで、より信頼性が高く正確なLLM出力のための強固な基盤を築くことができます。
2.検索拡張世代 (RAG)
リトリーバル・オーグメンテッド・ジェネレーション(RAG) は、検索ベースのアプローチと生成ベースのアプローチの長所を組み合わせた強力な手法である。この手法により、LLMはテキスト生成プロセス中に外部の知識ソースから関連情報にアクセスし、取り込むことができる。
RAGの作品
キュレーションされた知識ベースから関連情報を取り出す
この情報をLLMに提供された文脈に組み込む
事実に基づいた最新の情報に基づいた回答を作成する。
RAGを実装することにより、企業はLLM応答を信頼できる外部情報源に固定することで幻覚を大幅に減らすことができる。このアプローチは、法律や医療AIシステムなど、正確さが重要な領域固有のアプリケーションに特に効果的である。
3.バックエンドシステムとの統合
LLMを企業の既存のバックエンドシステムと統合することで、AIが生成するコンテンツの精度と関連性を劇的に向上させることができる。このアプローチにより、LLMは企業のデータベースやAPIから直接、リアルタイムの状況に応じたデータにアクセスできるようになる。
バックエンド統合の主な利点は以下の通り:
回答が最新の情報に基づいていることの確認
パーソナライズされた、コンテキストに関連したアウトプットの提供
古い可能性のあるトレーニングデータへの依存を減らす
例えば、企業の在庫システムと統合されたeコマースチャットボットは、製品の在庫状況に関する正確でリアルタイムの情報を提供することができ、在庫レベルや価格に関する幻覚応答のリスクを低減することができます。
こうしたデータ中心のアプローチを導入することで、企業はLLM出力の信頼性を大幅に高め、幻覚のリスクを軽減し、AIシステム全体のパフォーマンスを向上させることができる。
モデル中心のアプローチ
4.LLMの微調整
ファインチューニングは、事前に訓練された大規模な言語モデルを特定のドメインやタスクに適応させるための強力なテクニックである。このプロセスでは、ターゲットとするアプリケーションに関連する、より小さな、注意深くキュレートされたデータセットでLLMをさらにトレーニングする。ファインチューニングは、モデルの出力をドメイン固有の知識や用語に合わせることで、幻覚を大幅に減らすことができる。
微調整の主な利点は以下の通り:
専門分野での精度向上
業界特有の専門用語の理解を深める
無関係な情報や誤った情報が生成される可能性の低減
例えば、法律文書や判例法のコーパスで微調整されたリーガルAIアシスタントは、法的クエリに答える際に幻覚を見る可能性が低くなり、法的領域における信頼性と有用性が向上する。
5.カスタムLLMの構築
膨大なリソースと特定のニーズを持つ組織にとって、カスタム大規模言語モデルをゼロから構築することは、幻覚を軽減する効果的な方法となり得る。このアプローチでは、学習データ、モデル・アーキテクチャ、学習プロセスを完全に制御することができます。
の利点 カスタムLLM を含む:
ビジネスニーズに合わせた知識ベース
無関係または不正確な情報を取り込むリスクの低減
モデルの動作と出力の制御を拡大
このアプローチには多大な計算資源と専門知識が必要とされるが、その結果、意図した運用領域内では高精度で信頼性の高いAIシステムを実現することができる。
6.高度なプロンプティング・テクニック
洗練されたプロンプト技術は、言語モデルを誘導して、より正確で一貫性のあるテキストを生成し、幻覚を効果的に減らすことができる。これらの方法は、AIシステムからより信頼性の高い出力を引き出す方法で入力を構造化するのに役立つ。
効果的なプロンプティングのテクニックには、次のようなものがある:
思考の連鎖を促す: 段階的な推論を促す
数少ないシュート学習: モデルの対応を導く例を提供する。
プロンプトを注意深く作成することで、開発者はLLMが生成するコンテンツの事実の正確さと関連性を大幅に向上させ、幻覚の発生を最小限に抑えることができる。
プロセスと監督アプローチ
7.文脈理解の強化
LLMが対話を通じて文脈を維持する能力を向上させれば、幻覚を大幅に減らすことができる。これには、長時間の会話や複雑なタスクにおいて、モデルが関連する情報を追跡し、活用できるようにするテクニックを実装することが含まれる。
主な戦略は以下の通り:
共参照の解決: モデルによる関連エンティティの識別とリンクの支援
会話履歴の追跡 過去の交流への配慮の徹底
高度なコンテキストモデリング: モデルが関連情報に集中できるようにする
これらのテクニックは、LLMが一貫性と一貫性を維持し、矛盾した情報や無関係な情報を生み出す可能性を減らすのに役立つ。
8.人的監視とAI監査
LLM出力における幻覚を特定し、対処するためには、人間による監視を実施し、定期的なAI監査を実施することが極めて重要である。このアプローチは、人間の専門知識とAIの能力を組み合わせることで、最高レベルの精度と信頼性を保証する。
効果的な監督実務には以下が含まれる:
AIが生成したコンテンツを専門家が定期的にレビュー
モデルのパフォーマンスを向上させるためのフィードバックループの導入
幻覚のパターンを特定するための徹底的な監査
AIプロセスへの人間の関与を維持することで、組織は、他の方法では気づかれないかもしれない幻覚を発見し、修正することができ、AIシステムの全体的な信頼性を高めることができる。
9.責任あるAI開発の実践
幻覚を起こしにくいLLMを作るには、責任あるAI開発手法を採用することが不可欠である。このアプローチでは、AI開発のライフサイクルを通じて、倫理的配慮、透明性、説明責任を重視する。
責任あるAI開発の主要な側面には、以下のようなものがある:
公平で偏りのないトレーニングデータを優先する
堅牢なテストと検証プロセスの導入
AIの意思決定プロセスにおける透明性の確保
これらの原則に従うことで、組織は、より信頼性が高く、信用でき、有害な出力や誤解を招く出力を生成する可能性が低いAIシステムを開発することができる。
10.強化学習
強化学習は、LLMの幻覚を軽減する有望なアプローチである。この手法では、報酬と罰則のシステムを通じてモデルを訓練し、望ましい行動を奨励し、望ましくない行動を抑制する。
幻覚軽減における強化学習の利点:
モデル出力を特定の精度目標に合わせる
モデルの自己修正能力の向上
生成テキストの全体的な品質と信頼性の向上
強化学習技術を導入することで、開発者は幻覚を回避し、事実に基づいて正確なコンテンツを生成することに長けたLLMを作成することができる。
これらのモデル中心およびプロセス指向のアプローチは、大規模な言語モデルにおける幻覚を軽減するための強力なツールを提供する。これらの戦略を前述のデータ中心アプローチと組み合わせることで、企業はAIシステムの信頼性と精度を大幅に向上させ、より信頼性の高い効果的なAIアプリケーションへの道を開くことができる。
効果的な幻覚軽減策の実施
大規模な言語モデルにおける幻覚を軽減するトップ10の方法を探ってきたが、この課題に対処することが、信頼性の高いAIシステムを開発する上で極めて重要であることは明らかだ。成功の鍵は、特定のニーズとリソースに合わせて、これらの戦略を思慮深く実行することにあります。適切なアプローチを選択する際には、貴社固有の要件と遭遇している幻覚の種類を考慮してください。トレーニング・データの質を向上させるような戦略の中には、簡単に採用できるものもあれば、カスタムLLMの構築のように多額の投資を必要とするものもある。
有効性と必要なリソースのバランスをとることは不可欠である。多くの場合、戦略の組み合わせが最適なソリューションを提供し、制約を管理しながら複数のアプローチを活用することができます。例えば、RAGと高度なプロンプト技術を組み合わせることで、大規模なモデルの再トレーニングを行うことなく、大幅な改善をもたらすことができます。
人工知能が進化し続けるにつれて、幻覚を軽減する方法も進化していきます。最新の開発情報を常に入手し、アプローチを継続的に改善することで、AIシステムが精度と信頼性の最前線であり続けることを保証できます。目標は単にテキストを生成することではなく、ユーザーが信頼できるLLMアウトプットを作成することであることを忘れないでください。
LLMの幻覚を軽減するためのサポートが必要な場合は、遠慮なくSkim AIまでご連絡ください。


