
企業がAIを安全に統合するためにLLMの幻覚に取り組む方法



大規模言語モデル(LLM)は、自然言語処理と生成において前例のない機能を提供し、エンタープライズ・アプリケーションを変革しています。しかし、企業がLLMの流行に乗る前に、対処しなければならない重大な課題がある。
LLMの幻覚は、こうした強力なAIシステムの普及に大きな障害となっている。この現象の複雑な性質を掘り下げると、幻覚を理解し緩和することが、リスクを最小限に抑えながらLLMの潜在能力を最大限に活用しようとする企業にとって極めて重要であることが明らかになる。
LLM幻覚を理解する
大規模言語モデルの文脈におけるAIの幻覚とは、モデルがテキストを生成したり、事実に反していたり、無意味であったり、入力データと無関係であったりする回答を提供したりするケースを指す。このような幻覚は、自信ありげに聞こえるが全くでっち上げられた情報として現れる可能性があり、潜在的な誤解や誤った情報につながる。
幻覚の種類
LLM幻覚はいくつかのタイプに分類できる:
事実の幻覚: モデルが既成事実と矛盾する情報や、存在しないデータを捏造した場合。
意味幻覚: 個々の部分が首尾一貫しているように見えても、生成されたテキストが論理的に矛盾していたり、無意味であったりする場合。
文脈的幻覚: LLMの回答が、与えられた文脈から逸脱している場合、または 迅速無関係な情報を提供する。
一時的な幻覚: モデルが、最近の出来事や歴史的事実など、時間の影響を受けやすい情報を混同したり、誤って表現している場合。
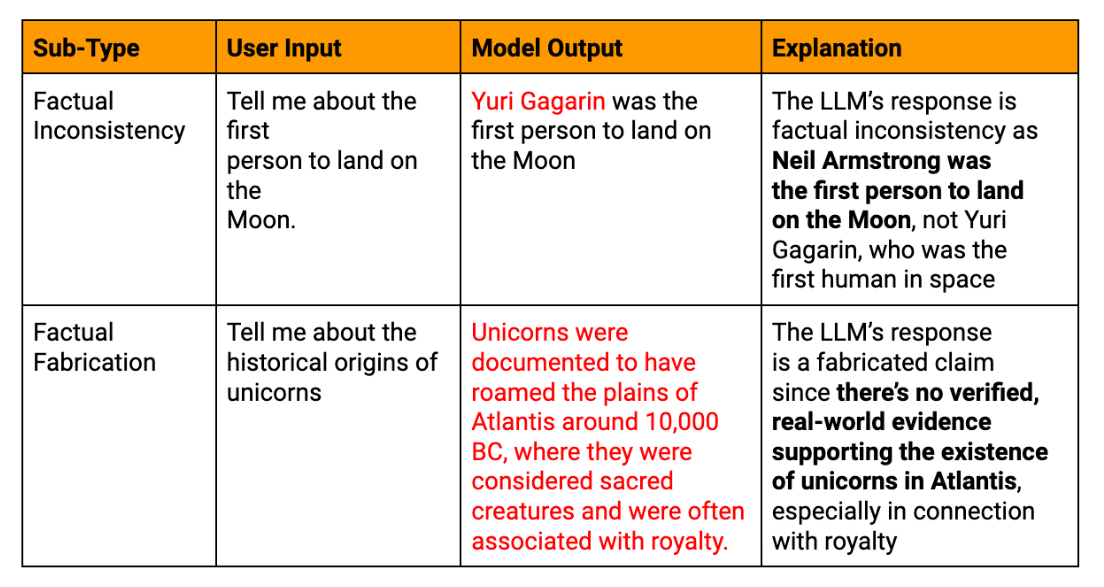
LLMが生成した幻覚テキストの実例
企業におけるLLM幻覚の重大な結果を説明するために、次のような例を考えてみよう:
カスタマーサービス・チャットボットの災難:ある大手eコマース企業は、LLMを搭載したチャットボットを自社のカスタマーサービス・プラットフォームに統合した。あるセール期間中、チャットボットは数千人の顧客に対し、返品ポリシーや配送時間に関する誤った情報を自信満々に提供しました。その結果、顧客からの苦情が急増し、信頼が損なわれ、大規模なダメージコントロールが必要になりました。
財務報告の不正確さ: ある投資会社が、四半期ごとの財務報告書作成を支援するためにLLMを使用している。AIシステムは、いくつかの主要な財務指標を幻覚で見せてしまうが、最初のレビューでは気づかれなかった。不正確な報告書が公表されると、誤った投資判断や潜在的な規制問題につながるため、AIが作成した財務内容の徹底的な検証の必要性が浮き彫りになる。
製品開発の失敗 あるハイテク・スタートアップ企業が、LLMを使って市場動向を分析し、製品機能の推奨を生成した。AIは存在しない技術に基づく機能を自信たっぷりに提案し、開発チームは間違いに気づく前に貴重な時間とリソースを浪費することになった。この事件は、LLMの出力を信頼できる業界ソースと相互参照することの重要性を強調している。
人事政策の混乱 ある多国籍企業が、人事方針の起草を支援するために法学修士を雇う。AIは存在しない労働法を幻視し、それが誤って会社の公式方針文書に含まれてしまった。これは従業員の混乱と潜在的な法的リスクにつながり、AIが作成したポリシー内容の専門家によるレビューの必要性を強調している。
これらの例は、LLMの幻覚が、顧客とのやり取りから内部プロセスや戦略的意思決定に至るまで、企業運営の様々な側面にどのような影響を与えるかを示しています。これらの例は、ビジネスクリティカルなアプリケーションでLLMが生成したテキストを活用する際に、強固な検証プロセスを実装し、人間の監視を維持することの重要性を強調しています。
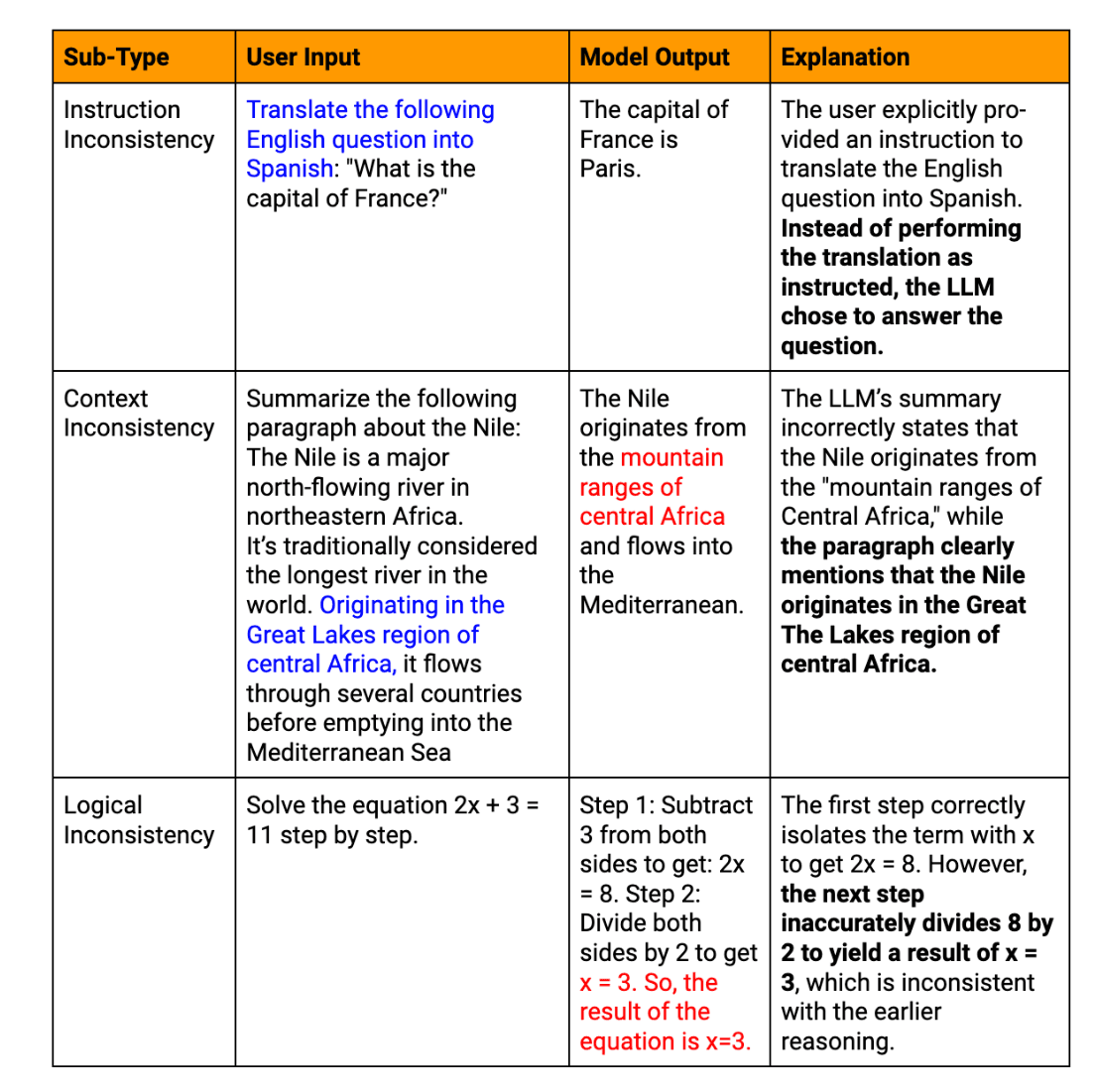
LLMの幻覚の原因は?
LLM幻覚の起源を理解することは、効果的な軽減策を開発する上で極めて重要である。この現象には、相互に関連したいくつかの要因が関与している。
トレーニング・データの品質問題
トレーニングデータの質は、LLMのパフォーマンスに大きく影響する。不正確な情報や古い情報、原資料の偏り、事実に基づいたデータ表現の矛盾はすべて幻覚につながる可能性がある。例えば、LLMが時代遅れの科学理論を含むデータセットで訓練された場合、LLMは出力において自信を持ってこれらを現在の事実として提示するかもしれない。
AIモデルと言語モデルの限界
その素晴らしい能力にもかかわらず、現在のLLMには固有の限界がある:
真の理解不足: LLMは意味を理解するよりも、テキストのパターンを処理する。
コンテキストウィンドウの制限: ほとんどのモデルは、長いパッセージで一貫性を維持するのに苦労している。
事実確認ができない: LLMは生成された情報を検証するためにリアルタイムの外部知識にアクセスできない
このような制限の結果、モデルはもっともらしく聞こえるが、事実としては正しくない、あるいは無意味な内容を生成することになる。
LLM出力生成の課題
テキストを生成するプロセス自体が幻覚を引き起こす可能性がある。LLMは確率的予測に基づいてトークン単位でコンテンツを生成するが、これが意味ドリフトやあり得ないシーケンスを引き起こすことがある。さらに、LLMはしばしば過信を示し、幻覚のような情報を事実のデータと同じように提示する。
入力データとプロンプト関連要因
LLMとユーザーとのインタラクションは、不注意にも幻覚を引き起こす可能性がある。あいまいなプロンプト、不十分な文脈、過度に複雑なクエリは、モデルが意図を誤解したり、偽の情報でギャップを埋めたりする可能性がある。
LLMの幻覚が企業に与える影響
LLMのアウトプットにおける幻覚の発生は、企業にとって広範囲に及ぶ結果をもたらす可能性がある:
不正解と事実誤認のリスク
企業が意思決定や顧客とのコミュニケーションにおいて、LLMが生成したコンテンツに依存している場合、幻覚のような情報がコストのかかるミスにつながる可能性がある。このような誤りは、業務上の小さな非効率から、戦略上の大きな誤りにまで及ぶ可能性がある。例えば、LLMが不正確な市場分析を提供した場合、誤った投資決定や製品開発戦略につながる可能性がある。
法的および倫理的に起こりうる結果
LLMを利用する企業は、法規制の遵守や倫理的配慮など、複雑な状況を乗り切らなければならない。以下のシナリオを考えてみよう:
規制違反につながる財務報告書の幻覚内容
法的措置につながる不正確な情報の顧客への提供
信頼できない情報を生み出すAIシステムの使用から生じる倫理的ジレンマ
AIシステムの信頼性と信用への影響
おそらく最も重大なことは、LLMの幻覚はAIシステムの信頼性と信用に大きな影響を与える可能性があるということだ。幻覚が頻繁に起こったり、注目されたりすると、次のようなことが起こりうる:
ユーザーの信頼を低下させ、AIの導入と統合を遅らせる可能性がある。
テクノロジー・リーダーとしての企業の評判を落とす。
たとえ正確であっても、AIが生成したすべての出力に対して懐疑的になる。
企業にとって、こうした意味合いへの対応は、単なる技術的課題ではなく、戦略的必須事項である。
企業LLM統合における幻覚を軽減する戦略
企業がますます大規模な言語モデルを採用するようになるにつれ、幻覚の課題に対処することが最も重要になる。
この問題を軽減するための重要な戦略がある:
1.トレーニングデータと外部知識の統合の改善
LLMの基盤はトレーニングデータである。幻覚を減らすために、企業はデータの質を高め、信頼できる外部の知識を統合することに集中しなければならない。
ドメイン固有のデータセットを開発し、その正確性を厳密に検証する。このアプローチにより、モデルは高品質で関連性の高い情報から学習し、事実誤認の可能性を減らすことができます。
学習データを定期的に更新するシステムを導入し、モデルが最新の情報にアクセスできるようにする。これは、テクノロジーやヘルスケアなど、知識ベースが急速に進化する業界では特に重要です。
構造化された知識グラフをLLMのアーキテクチャに組み込む。これにより、モデルには事実関係の信頼できるフレームワークが提供され、検証された情報に基づいた出力が可能になります。
実施 ラグ この技術により、LLMはテキスト生成中に外部の最新の知識ベースにアクセスし、参照することができる。このリアルタイムのファクトチェック・メカニズムにより、情報が古かったり、間違っていたりするリスクが大幅に軽減される。
2. LLM出力のロバスト・バリデーションの実装
検証プロセスは、エンドユーザーに届く前に幻覚を発見し、修正するために極めて重要である。
LLMで作成されたテキストの主要な主張を、信頼できるデータベースやウェブソースと照合して迅速に検証できる、AIを活用したファクトチェックシステムを開発する。
LLMの出力のさまざまな部分を相互参照し、内部整合性を確認するアルゴリズムを導入し、幻覚を示す可能性のある矛盾にフラグを立てる。
生成された各セグメントに対して、モデル独自の信頼度スコアを利用します。信頼度スコアが低い出力は、人間によるレビューや追加検証のためにフラグを立てることができます。
複数のLLMまたはAIモデルを配備して、同じプロンプトに対する応答を生成し、出力を比較して、矛盾による幻覚の可能性を特定する。
3.事実の正確性を確保するための人間の監視の活用
自動化は極めて重要だが、人間の専門知識は幻覚を軽減する上で非常に貴重であることに変わりはない。
法律文書や財務報告書など、重要なアプリケーションのLLM出力を、ドメインの専門家がレビューするプロセスを確立する。
LLMと人間のオペレーターとの間のシームレスなコラボレーションを促進するインターフェースを設計し、人間の入力からの迅速な修正と学習を可能にする。
エンドユーザーが幻覚の疑いを報告する仕組みを導入し、LLMシステムの継続的改善サイクルを構築する。
LLMの幻覚の可能性を識別し、対処するための包括的なトレーニングを従業員向けに開発し、AIが生成したコンテンツを批判的に評価する文化を育成する。
4.モデルの行動を改善する高度なテクニック
最先端の研究は、LLMのパフォーマンスを向上させ、幻覚を減らすための有望な手段を提供している。
制約された復号化: LLMのテキスト生成プロセスをガイドし、既知の事実や指定されたルールにより忠実であるよう制約するテクニックを実装する。
不確実性を考慮したモデル: 較正言語モデルやアンサンブル手法のような技術を用いて、出力に関する不確実性を表現できるLLMを開発する。
敵対的なトレーニング 学習中にモデルを敵対的な事例にさらすことで、幻覚の生成に対してより頑健になる。
強化学習による微調整: 強化学習技術を利用してLLMを微調整し、事実の正確さには報酬を、幻覚にはペナルティを与える。
モジュラー・アーキテクチャ: 世界知識と言語生成機能を分離し、より制御された検証可能な情報検索を可能にするアーキテクチャを探求する。
これらの戦略を実施することで、企業はLLMアプリケーションにおける幻覚のリスクを大幅に低減することができる。しかし、幻覚を完全に除去することは依然として困難であることに留意する必要がある。そのため、技術的な解決策と人的な監視を組み合わせた多面的なアプローチが重要である。
将来の展望幻覚軽減の進歩
LLM技術の将来を見据えるとき、幻覚の軽減は現在進行中の機械学習研究の重要な焦点であり続けている。自己矛盾チェック、知識統合、不確実性定量化などの分野で有望な進歩があり、この課題に対処するための新しいツールやフレームワークが継続的に開発されている。
今後の研究は、LLMの事実精度を向上させ、事実知識と生成されたテキストをよりよく区別できるモデルに導く上で重要な役割を果たすだろう。AIシステムが進化し続けるにつれて、高度なニューラル・アーキテクチャ、学習方法の改善、外部知識の統合の強化など、幻覚を軽減するためのより洗練されたアプローチが期待される。LLMの導入を検討している企業にとって、これらの開発に関する情報を常に入手することは、業務において最高水準の精度と信頼性を維持しながらAIの可能性を最大限に活用するために不可欠である。
よくあるご質問
LLM幻覚とは何ですか?
LLM幻覚とは、AIモデルが自信に満ち、首尾一貫しているように見えるにもかかわらず、事実と異なる、あるいは無意味なテキストを生成する例である。
クリティカルなアプリケーションにおけるLLM幻覚の一般的な例は?
よくある例としては、報告書に虚偽の財務データを作成したり、誤った法的助言を提供したり、技術文書に存在しない製品機能を捏造したりすることが挙げられる。
LLMの幻覚が現実にもたらす結果とは?
その結果、誤った情報による意思決定による金銭的損失、誤ったアドバイスによる法的責任、虚偽の情報を公表したことによる企業の評判の低下などが生じる可能性がある。
LLMの幻覚は接客にどう影響するか?
カスタマーサービスにおける幻覚は、誤った情報、顧客の不満、企業のAIを活用したサポートシステムに対する信頼の低下につながる可能性がある。
LLMの幻覚を軽減するために、どのような戦略が用いられるのか?
主な戦略には、トレーニングデータの質の向上、強固な出力検証の実施、人間による監視の統合、検索補強生成のような高度なテクニックの使用などがある。


