
2024年、企業はLLMアプリケーションにベクターデータベースをどう使うべきか?



近年、大規模言語モデル(LLM)は、エンタープライズAIアプリケーションの展望に革命をもたらした。これらの強力な機械学習モデルは、自然言語処理、生成、理解において目覚ましい能力を発揮し、業界を問わずビジネスの可能性を広げている。しかし、LLMがより洗練され、要求が厳しくなるにつれて、企業はこれらのモデルの訓練と運用に必要な膨大な量のデータを効率的に保存・検索するという課題に直面している。ベクトル・データベースは、LLMの可能性を最大限に引き出す鍵です。 企業におけるLLM AIの応用。
ベクターデータベースを理解する
ベクトルデータベースは、高次元のベクトルデータを格納・管理するために設計された特殊なデータベースである。データを行と列として格納する従来のデータベースとは異なり、ベクトルデータベースはデータをベクトル空間の数値ベクトルとして表現します。テキスト文書や画像などの各データポイントはベクトル埋め込みに変換され、データのセマンティックな意味を捉える高密度で固定長の数値表現となります。
ベクターデータベースの仕組み
ベクトルデータベースの中核には、ベクトル埋め込みとベクトル空間の概念がある。ベクトル埋め込みは、word2vecやBERTのような機械学習モデルを用いて生成され、データ点を高次元ベクトル空間にマッピングすることを学習する。このベクトル空間では、類似のデータ点は互いに近いベクトルで表現され、非類似のデータ点は離れて表現されます。
ベクトルデータベースは、効率的な類似検索や最近傍検索を可能にする。クエリベクトルが提供されると、データベースはコサイン類似度やユークリッド距離のような距離メトリックを使用して、ベクトル空間内で最も類似したベクトルを素早く見つけることができる。これにより、キーワードの完全一致ではなく、意味的類似性に基づく関連データの高速かつ正確な検索が可能になります。
LLMアプリケーションにベクトルデータベースを使用する利点
ベクターデータベースは、LLMアプリケーションをサポートする上で、従来のデータベースと比較していくつかの重要な利点がある:
意味検索: ベクターデータベースはセマンティック検索を可能にし、LLMがキーワードの完全一致に頼るのではなく、クエリの意味と文脈に基づいて情報を検索できるようにする。これにより、より適切で正確な結果を得ることができる。
スケーラビリティ: ベクターデータベースは、大規模なベクターデータを効率的に扱うように設計されている。数百万から数十億の高次元ベクトルを格納し処理することができるため、LLMの訓練や運用に必要な膨大なデータセットに最適です。
クエリー時間の短縮 ベクトル・データベースで使用される特殊な索引付けと検索アルゴリズムは、大規模なデータセットであっても高速なクエリを可能にする。これは、関連情報への迅速なアクセスを必要とするリアルタイムのLLMアプリケーションにとって極めて重要である。
精度の向上: ベクトル埋め込みに取り込まれた意味情報を活用することで、ベクトルデータベースはLLMがユーザーのクエリに対してより正確で文脈に関連した応答を提供するのに役立つ。
LLMのパワーをAIアプリケーションに活用しようとする企業にとって、ベクトル・データベースは効率的なデータの保存と検索に不可欠なツールとして浮上している。

LLMとベクトル・データベース:エンタープライズAIに最適な組み合わせ
LLMの成功は、学習対象となるデータの質とアクセス性に大きく依存している。ベクターデータベースは、LLMが必要とする膨大な量のデータを保存・検索するための強力なソリューションを提供します。
LLMの訓練と微調整におけるデータの役割
LLMは何十億もの単語を含む膨大なデータセットで学習されるため、言語の複雑さを学習し、文脈と意味を深く理解することができます。一度事前訓練されたLLMは、特定のユースケースや業種に適応させるために、ドメイン固有のデータで微調整することができます。このデータの質と関連性は、エンタープライズAIアプリケーションにおけるLLMの性能と精度に直接影響します。
LLMデータの保存と検索に従来のデータベースを使用することの課題
リレーショナル・データベースのような従来のデータベースは、LLMが必要とする非構造化・高次元データの処理には適していない。これらのデータベースは、以下のような課題を抱えている:
スケーラビリティ: 従来のデータベースは、大規模なデータセットを扱う際に性能上の問題に直面することが多く、LLMの訓練や運用に必要な膨大な量のデータを保存・検索することが困難であった。
非効率的な検索:従来のデータベースにおけるキーワードベースの検索では、データの意味や文脈を捉えることができず、LLMがクエリを実行した場合、関連性のない、あるいは不完全な結果となってしまう。
柔軟性に欠ける: 従来のデータベースの硬直したスキーマは、LLMに関連する多様で進化するデータタイプや構造に対応することを困難にしている。
ベクターデータベースはどのようにこれらの課題を克服するか
ベクターデータベースは、LLMをサポートするという点で、従来のデータベースの限界に対処するために特別に設計されている:
コンテキストを考慮したデータ検索のための効率的な類似性検索: データを高次元空間のベクトルとして表現することで、ベクトルデータベースは高速かつ正確な類似性検索を可能にする。LLMはクエリの意味に基づいて関連情報を検索することができ、より文脈に適した応答を保証する。
大規模なデータセットを扱うためのスケーラビリティ: ベクターデータベースは、大量のベクターデータを効率的に扱うために構築されている。複数のマシンにまたがって水平方向に拡張できるため、LLMが必要とする何十億ものベクトル埋め込みデータの保存と処理が可能です。
ベクトルデータベースを活用したLLMの実例
いくつかの著名な企業向けAIアプリケーションは、LLMとベクトルデータベースの統合に成功し、パフォーマンスと効率を向上させている:
OpenAIのGPT-4とAnthropicのデータベース: OpenAIとAnthropicは、最先端のLLMを支える膨大な知識ベースを保存・検索するためにベクトルデータベースを使用しており、より文脈に即した正確な言語生成を可能にしている。
エンタープライズサーチとナレッジマネジメント: マイクロソフトやグーグルのような企業は、ベクターデータベースを企業内検索やナレッジマネジメントシステムの強化に利用しており、従業員は自然言語クエリを使って関連情報を素早く簡単に見つけることができる。
カスタマーサポートとチャットボット: 企業は、顧客データ、製品情報、会話履歴を保存・取得するためにベクターデータベースを採用し、LLMを搭載したチャットボットがよりパーソナライズされた効率的なカスタマーサポートを提供できるようにしている。
LLMアプリケーションにおけるベクトル・データベースの使用例を特定する
ベクターデータベースを実装する前に、エンタープライズAIアプリケーションに最も価値を提供できる特定のユースケースを特定することが極めて重要です。意味検索と情報検索は、ベクターデータベースが得意とする分野の1つで、ユーザーは自然言語クエリを使って関連情報を見つけることができます。文書、画像、その他のデータをベクトルとして表現することで、LLMは最も意味的に類似した結果を検索し、検索出力の精度と関連性を向上させることができます。
LLMはベクトルデータベースと統合することで、より正確で文脈に関連した応答を生成することができる。生成プロセス中、LLMは入力クエリに基づいてベクトル・データベースから関連情報を取得し、生成テキストの一貫性と事実の正確性を高めることができる。
パーソナライゼーションやレコメンデーションシステムも、ベクトルデータベースから大きな恩恵を受けることができる。ユーザーの嗜好、行動、アイテムの特徴をベクトルとして表現することで、LLMは高度にターゲット化されたレコメンデーション、コンテンツ提案、ユーザー固有のアウトプットを生成することができる。これは、ユーザーとアイテムのベクトル間の類似度を計算することで達成される。
最後に、ベクターデータベースはナレッジマネジメントやコンテンツ整理にも利用できる。企業はベクターデータベースを活用して、文書、レポート、マルチメディアコンテンツなどの大量の非構造化データを整理・管理することができる。似たようなベクトルをクラスタリングすることで、企業は自動的にコンテンツを分類し、タグ付けすることができ、発見やナビゲートが容易になります。
ニーズに合ったベクターデータベースの選択
エンタープライズAIアプリケーションの成功には、適切なベクターデータベースを選択することが重要です。さまざまなベクターデータベースのソリューションを評価する際には、オープンソースとプロプライエタリのオプションのトレードオフを考慮してください。オープンソースのベクターデータベースは、柔軟性、カスタマイズ性、コストパフォーマンスに優れています。また、活発なコミュニティ、定期的なアップデート、豊富なドキュメントがあります。一方、プロプライエタリなソリューションは、クラウドプラットフォームや専門ベンダーが提供することが多く、マネージドサービス、エンタープライズグレードのサポート、エコシステム内の他のツールとのシームレスな統合が可能です。しかし、より高いコストとベンダーロックインのリスクを伴う可能性がある。
スケーラビリティとパフォーマンスは、ベクターデータベースを選択する際に評価すべき重要な要素です。ストレージ容量とクエリ性能の両面から、データのスケールを処理するデータベースの能力を評価します。数百万から数十億の高次元ベクトルを効率的に処理できるソリューションを探しましょう。大規模データセットでの類似性検索を大幅に高速化できる近似最近傍(ANN)検索など、データベースのインデックス作成と検索アルゴリズムを検討する。さらに、データベースの水平方向および垂直方向のスケーラビリティオプションを評価し、データやユーザーベースとともに成長できることを確認する。
統合のしやすさも重要な検討事項です。ベクターデータベースが既存のテクノロジースタックとどの程度統合できるかを調べます、 LLMフレームワークを含むデータベース、データパイプライン、およびダウンストリーム・アプリケーションの統合を容易にします。一般的なプログラミング言語やフレームワーク用のAPI、SDK、コネクタを提供し、開発チームの統合や保守を容易にしているデータベースを探しましょう。
最後に、活発なコミュニティ、包括的なドキュメント、迅速なサポートチャネルを持つベクターデータベースを優先しましょう。強力なコミュニティがあれば、タイムリーなヘルプ、バグ修正、機能アップデートを確実に利用できます。豊富なエコシステムは、開発を加速し、追加機能を提供し、他の企業システムとの統合を容易にします。

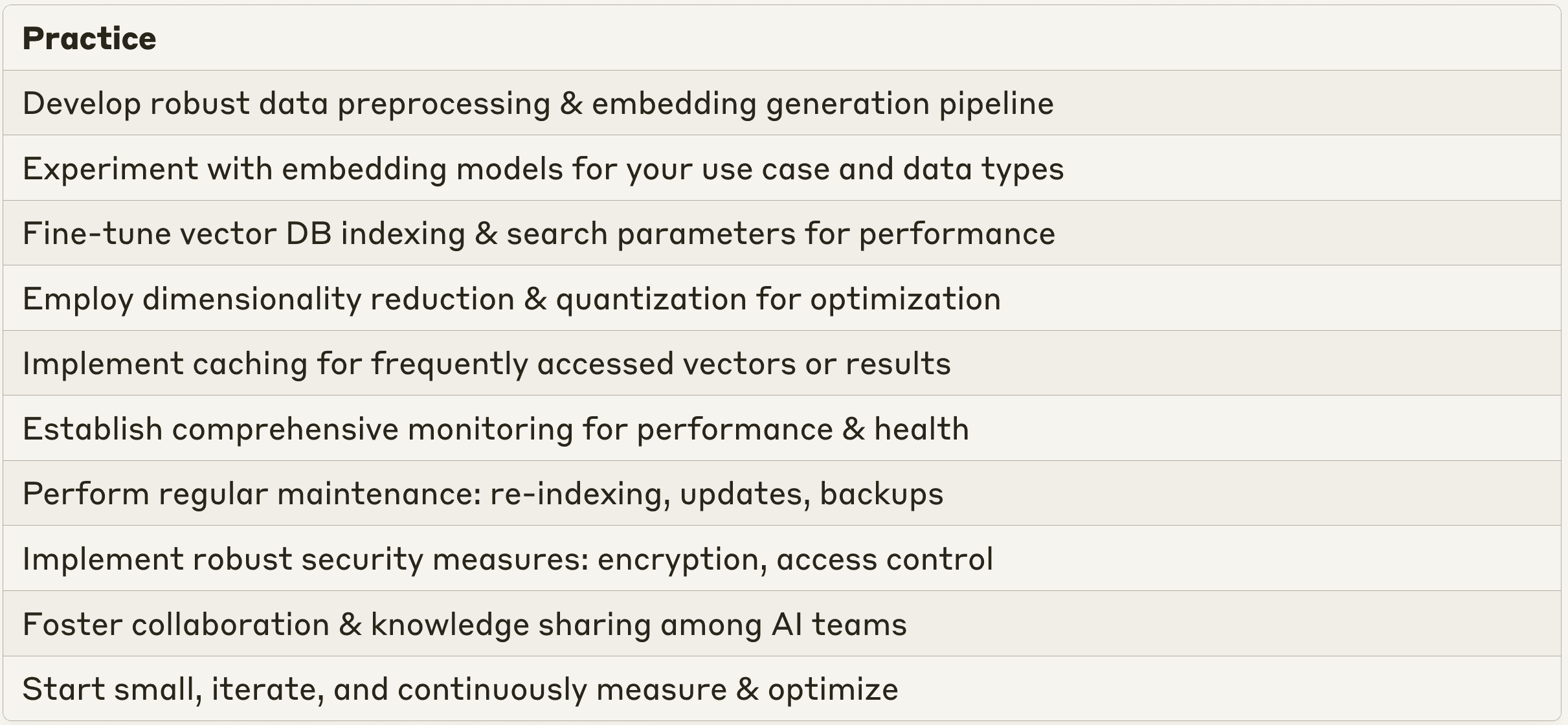
ベクターデータベースをLLMアプリケーションに統合するためのベストプラクティス
エンタープライズAIアプリケーションにベクターデータベースをスムーズかつ効果的に実装するためには、いくつかのベストプラクティスに従う必要があります。まず、生データをクリーン化、正規化し、ベクトル埋め込み生成に適した形式に変換する堅牢なデータ前処理パイプラインを開発する。様々なエンベッディング・モデルとテクニックを試して、特定のユースケースとデータタイプに最も適したアプローチを見つける。あらかじめ訓練されたエンベッディング・モデルをドメイン固有のデータで微調整し、企業のコンテキスト内のユニークなセマンティクスとリレーションシップをキャプチャします。ベクトル埋め込みデータの一貫性と信頼性を確保するために、データ品質チェックと検証ステップを実装します。
クエリの最適化とパフォーマンスチューニングは、ベクトルデータベースを効率的に使用するために不可欠です。クエリの速度と精度のバランスを取るために、最近傍の数、検索半径、クラスタリングアルゴリズムなど、ベクトルデータベースのインデックス作成および検索パラメータを微調整します。次元削減などのテクニックを使用して、意味情報を保持したままベクトルサイズを縮小し、ストレージ効率とクエリパフォーマンスを向上させます。積量子化やベクトル圧縮などの量子化手法を活用し、ベクトルの保存と検索をさらに最適化する。キャッシュ機構を実装して、頻繁にアクセスされるベクトルや検索結果をメモリに保存し、繰り返されるクエリの待ち時間を短縮します。
ベクターデータベースを円滑に運用するためには、モニタリングとメンテナンスが重要です。ベクターデータベースのパフォーマンス、可用性、健全性を追跡する包括的な監視システムを確立してください。クエリの待ち時間、スループット、エラー率などの主要メトリクスを監視します。アラートと通知を設定して、パフォーマンスのボトルネック、リソースの制約、または異常を事前に特定し、対処する。再インデックス作成、データ更新、バックアップなどのメンテナンスタスクを定期的に実行し、ベクトルデータの完全性と鮮度を確保します。実際の使用パターンやユーザーからのフィードバックに基づいて、ベクターデータベースのパフォーマンスを継続的に評価し、最適化します。必要に応じて、インデックス作成戦略、検索アルゴリズム、ハードウェアの設定を見直します。
機密性の高い企業データを扱う場合、セキュリティとアクセス制御が最も重要です。ベクターデータの機密性、完全性、可用性を保護するために、強固なセキュリティ対策を導入しましょう。機密情報を保護するために、暗号化、認証、アクセス制御の仕組みを適用します。きめ細かなアクセスポリシーとアクセス許可を定義し、許可されたユーザーとアプリケーションのみがベクターデータベースにアクセスし、操作できるようにします。定期的にアクセスログを監査およびレビューし、不正アクセスや疑わしい行為を検出および防止する。
最後に、ベクターデータベースの実装を成功させるためには、AIチーム間の協力と知識共有の文化を醸成することが不可欠です。ベクターデータベースとLLMアプリケーションに関するベストプラクティス、学んだ教訓、革新的なアイデアの交換を奨励する。社内にフォーラム、ワークショップ、ハッカソンを設置し、ベクターデータベース技術に関する実験、スキル開発、部門横断的なコラボレーションを促進する。外部コミュニティ、カンファレンス、業界イベントに参加し、ベクターデータベースとエンタープライズAIにおける最新の進歩、使用例、ベストプラクティスについて常に情報を得る。
これらのベストプラクティスに従い、企業独自の要件を考慮することで、ベクターデータベースの実装を成功させ、LLMアプリケーションの可能性を最大限に引き出すことができます。ベクターデータベースがビジネスに最大限の価値を提供できるように、小規模から始め、頻繁に反復し、継続的にベクターデータベースのパフォーマンスを測定して最適化することを忘れないでください。
エンタープライズAIにおけるベクターデータベースの未来
ベクターデータベース技術が進歩し続けるにつれて、エンタープライズAIに新しく革新的なアプリケーションが数多く登場することが予想される:
パーソナライズされたコンテンツ作成: ベクターデータベースを利用したLLMは、記事、レポート、マーケティング資料など、個々のユーザーの好みや状況に合わせた高度にパーソナライズされたコンテンツを生成することができる。
インテリジェントな文書処理: ベクトルデータベースは、大量の非構造化文書から重要な情報を自動的に分類、索引付け、抽出することができ、ワークフローを合理化し、意思決定プロセスを改善する。
多言語AIアシスタント: 複数の言語のベクトル埋め込みを組み込むことで、企業は母国語でユーザーを理解し対応できるAIアシスタントを開発することができ、言語の壁を取り払い、グローバルなコラボレーションを向上させることができる。
予知保全と異常検知: ベクトル・データベースは、センサー・データや機器のログからパターンや異常を特定するのに役立ち、産業環境における事前のメンテナンスとダウンタイムの削減を可能にする。
エンタープライズAIが急速なペースで進化を続ける中、ベクターデータベース技術とLLMの最新の進歩について常に情報を得ることは、企業にとって極めて重要です。新しい技術、ツール、ベストプラクティスを常に把握することで、企業はAIアプリケーションの競争力を維持し、ユーザーに最大限の価値を提供することができます。
ベクトル・データベースとLLMの未来を受け入れることで、企業はAIアプリケーションにおいて新たなレベルの効率性、正確性、洞察力を引き出すことができ、最終的に今後のビジネスの成長と成功を促進することができる。


