
Nous devons repenser la chaîne de pensée (CoT) qui incite l'IA&YOU #68



La statistique de la semaine : Zero-shot CoT performance was only 5.55% for GPT-4-Turbo, 8.51% for Claude-3-Opus, and 4.44% for GPT-4. (“Chain of Thoughtlessness?” paper)
Chain-of-Thought (CoT) prompting has been hailed as a breakthrough in unlocking the reasoning capabilities of large language models (LLMs). However, recent research has challenged these claims and prompted us to revisit the technique.
Dans l'édition de cette semaine de AI&YOU, nous explorons les perspectives de trois blogs que nous avons publiés sur le sujet :
We need to rethink chain-of-thought (CoT) prompting AI&YOU #68
LLMs demonstrate remarkable capabilities in natural language processing (NLP) and generation. However, when faced with complex reasoning tasks, these models can struggle to produce accurate and reliable results. This is where Chain-of-Thought (CoT) prompting comes into play, a technique that aims to enhance the problem-solving abilities of LLMs.
An advanced ingénierie rapide technique, it is designed to guide LLMs through a step-by-step reasoning process. Unlike standard prompting methods that aim for direct answers, CoT prompting encourages the model to generate intermediate reasoning steps before arriving at a final answer.
At its core, CoT prompting involves structuring input prompts in a way that elicits a logical sequence of thoughts from the model. By breaking down complex problems into smaller, manageable steps, CoT attempts to enable LLMs to navigate through intricate reasoning paths more effectively.
Comment fonctionne le CdT
À la base, l'invite CoT guide les modèles linguistiques à travers une série d'étapes de raisonnement intermédiaires avant d'aboutir à une réponse finale. Ce processus implique généralement
Décomposition du problème : La tâche complexe est décomposée en étapes plus petites et plus faciles à gérer.
Raisonnement pas à pas : Le modèle est invité à réfléchir à chaque étape de manière explicite.
Progression logique : Chaque étape s'appuie sur la précédente, créant ainsi une chaîne de pensées.
Dessin de conclusion : La réponse finale est dérivée des étapes de raisonnement accumulées.
Types de messages-guides du CdT
L'incitation à la chaîne de pensée peut être mise en œuvre de différentes manières, deux types principaux se distinguant :
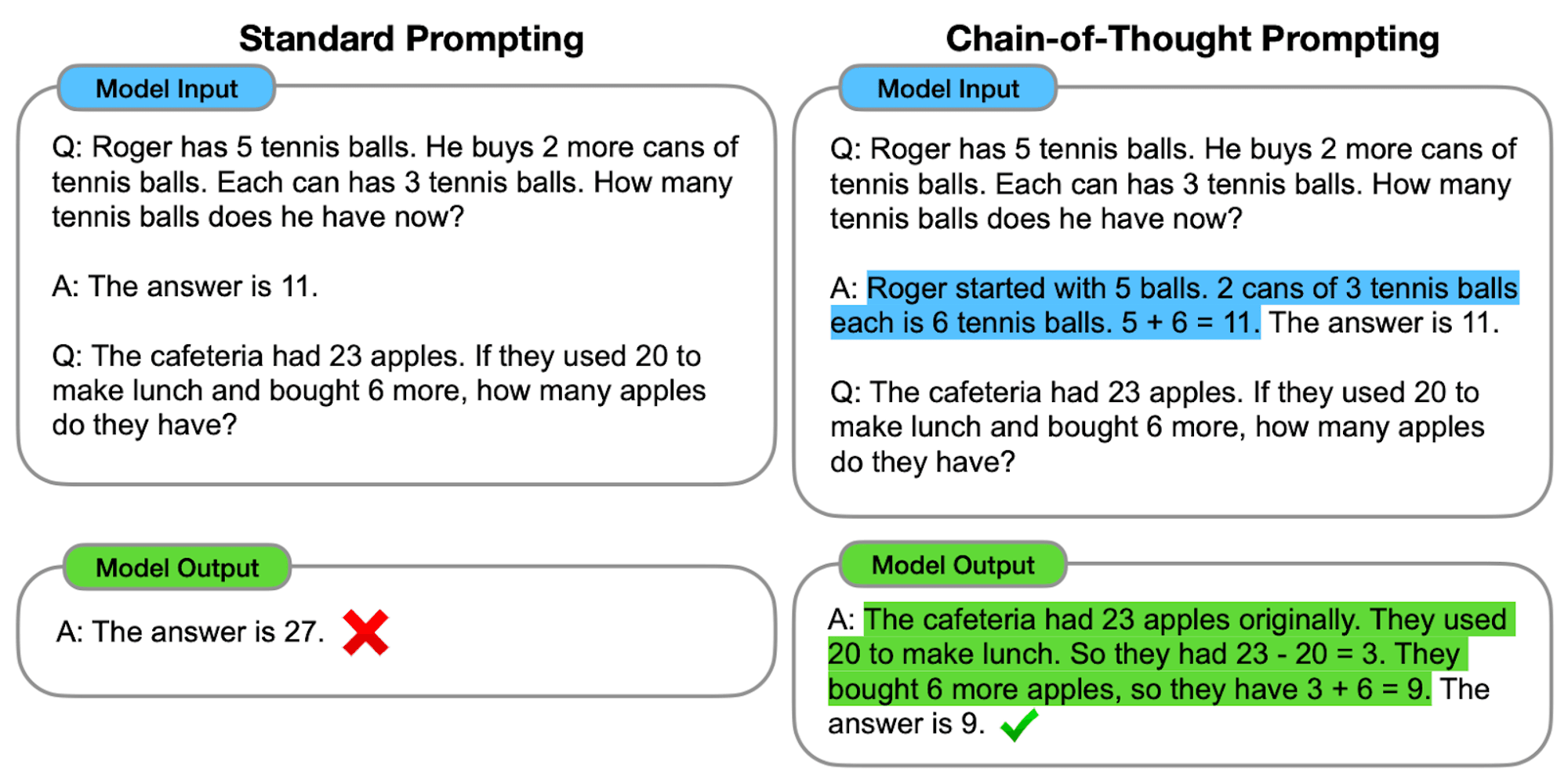
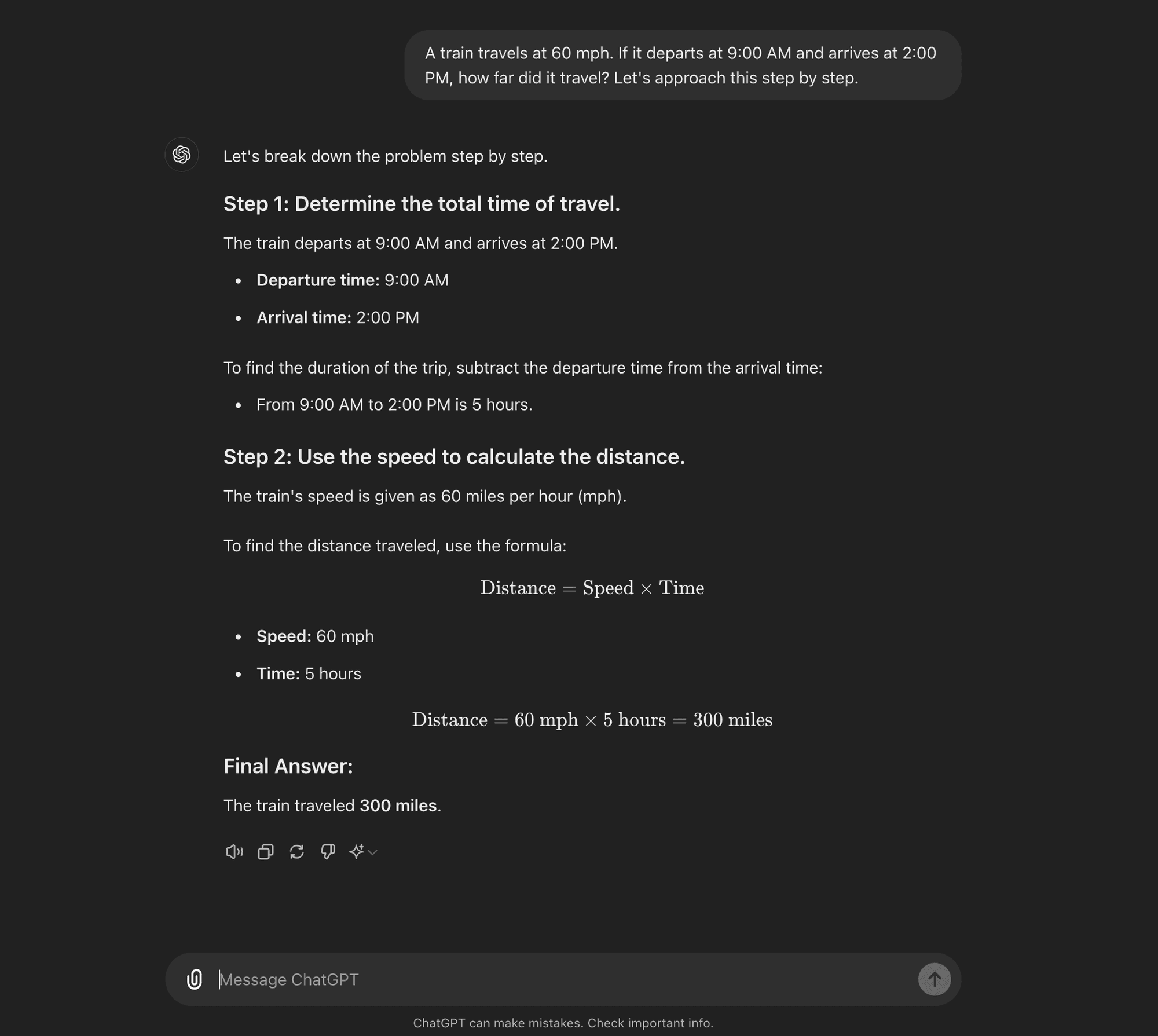
Zero-shot CoT: Zero-shot CoT doesn’t require task-specific examples. Instead, it uses a simple prompt like “Let’s approach this step by step” to encourage the model to break down its reasoning process.****
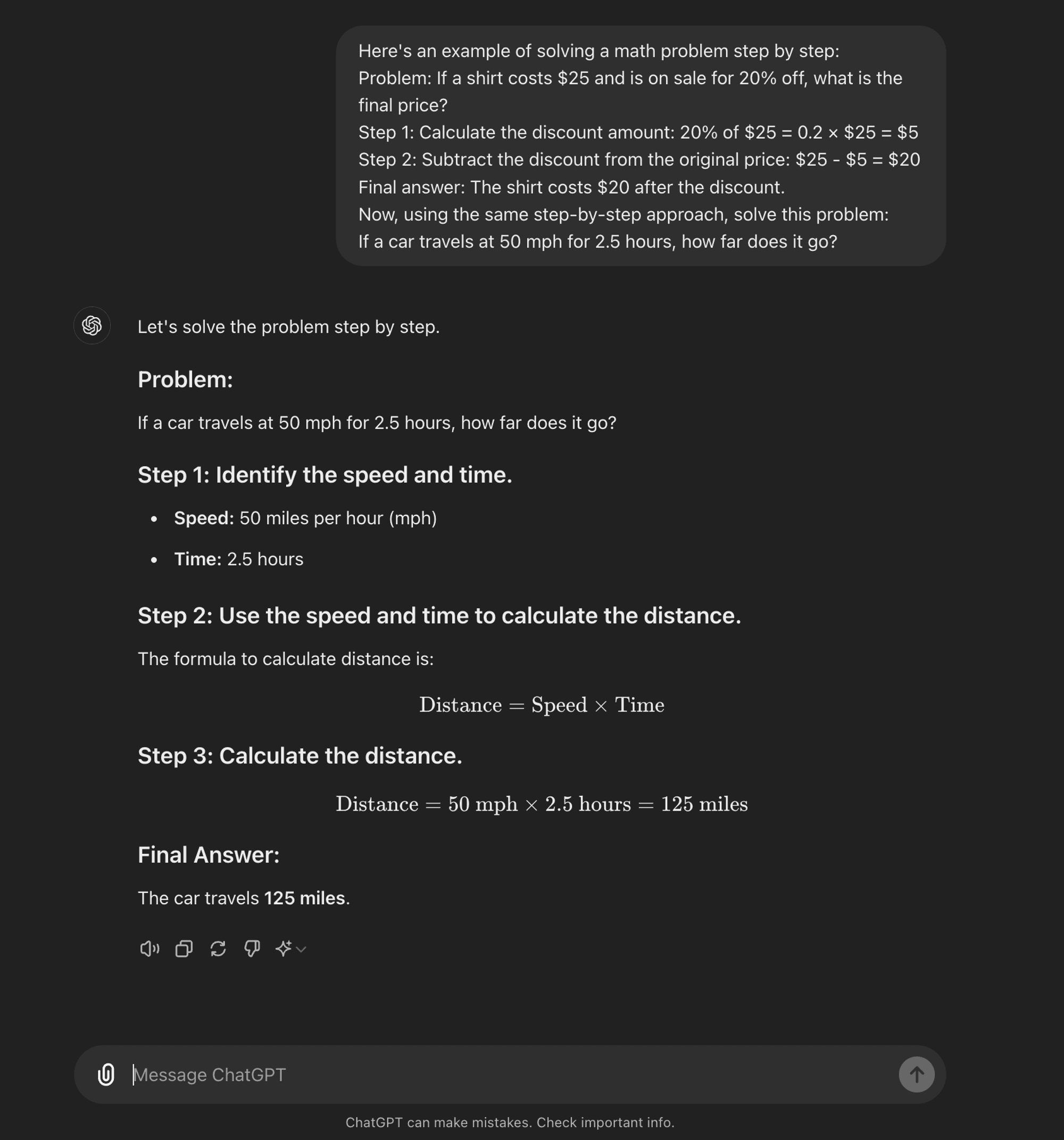
Few-shot CoT: Le CoT à quelques reprises consiste à fournir au modèle un petit nombre d'exemples qui illustrent le processus de raisonnement souhaité. Ces exemples servent de modèle au modèle lorsqu'il s'attaque à de nouveaux problèmes inédits.
Zero-shot CoT
Few-shot CoT
AI Research Paper Breakdown: “Chain of Thoughtlessness?”
Now that you know what CoT prompting is, we can dive into some recent research that challenges some of its benefits and offers some insight into when it is actually useful.
The research paper, titled “Chain of Thoughtlessness? An Analysis of CoT in Planning,” provides a critical examination of CoT prompting’s effectiveness and generalizability. As AI practitioners, it’s crucial to understand these findings and their implications for developing AI applications that require sophisticated reasoning capabilities.

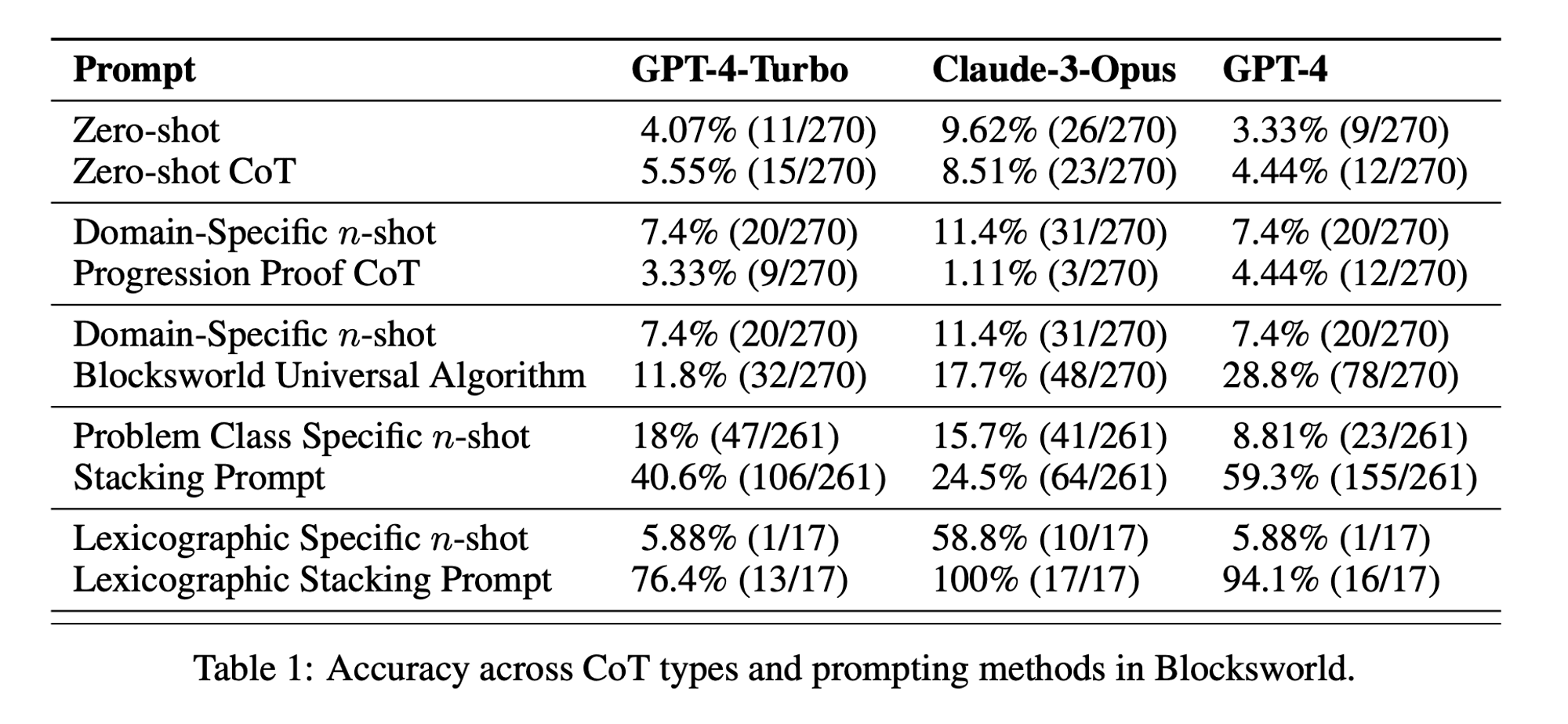
Les chercheurs ont choisi un domaine de planification classique appelé Blocksworld comme principal terrain d'essai. Dans Blocksworld, la tâche consiste à réorganiser un ensemble de blocs d'une configuration initiale à une configuration cible à l'aide d'une série d'actions de déplacement. Ce domaine est idéal pour tester les capacités de raisonnement et de planification pour les raisons suivantes :
Il permet de générer des problèmes de complexité variable
Il propose des solutions claires et vérifiables sur le plan algorithmique.
Il est peu probable qu'il soit fortement représenté dans les données de formation du LLM.
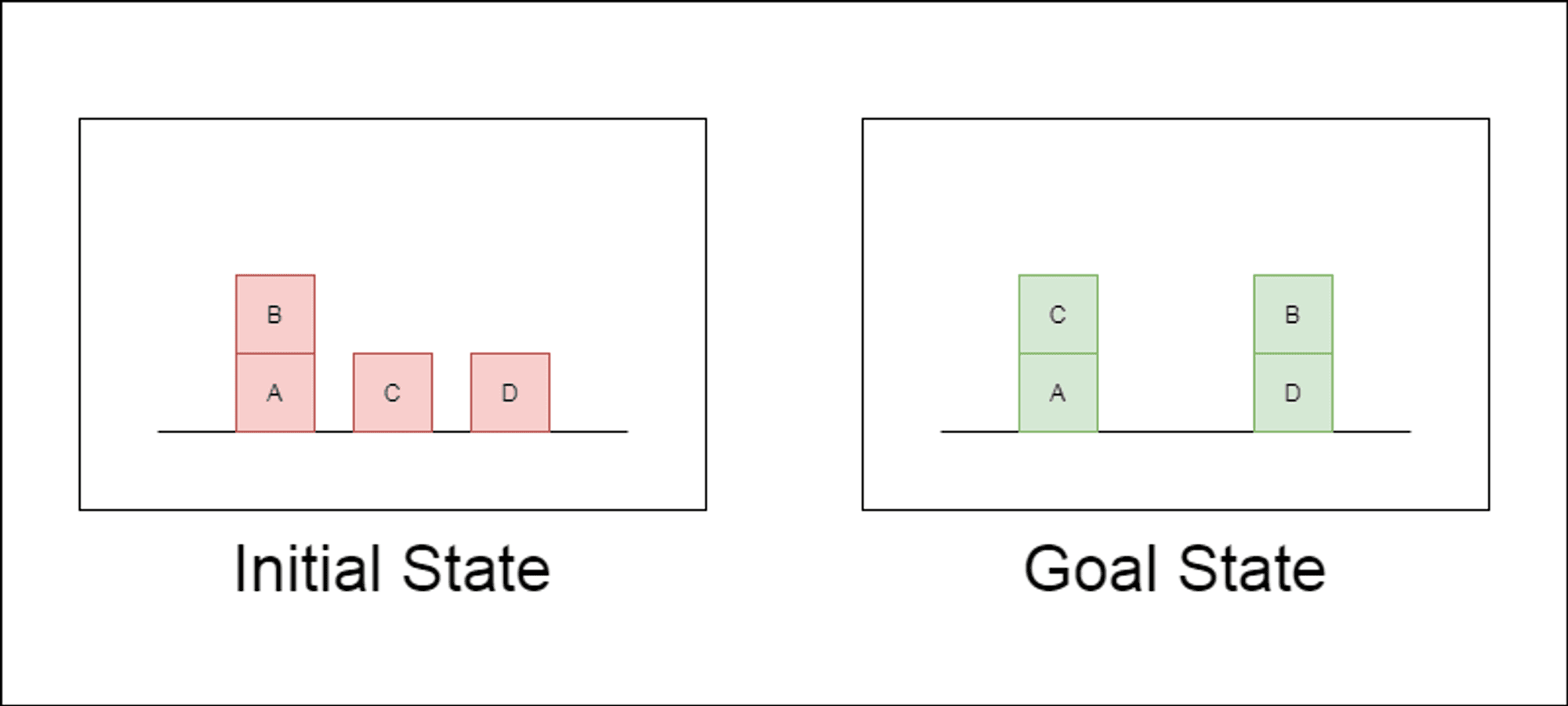
L'étude a examiné trois LLM de pointe : GPT-4, Claude-3-Opus et GPT-4-Turbo. Ces modèles ont été testés à l'aide d'invites de spécificité variable :
Chaîne de pensée à zéro coup (universelle) : Il suffit d'ajouter "réfléchissons étape par étape" à l'invite.
Preuve de progression (spécifique à la PDDL) : Fournir une explication générale de l'exactitude du plan avec des exemples.
Algorithme universel Blocksworld : Démonstration d'un algorithme général permettant de résoudre n'importe quel problème du monde des blocs.
Promesse d'empilage : Se concentrer sur une sous-classe spécifique des problèmes de Blocksworld (table à pile).
Empilement lexicographique : Réduction supplémentaire à une forme syntaxique particulière de l'état d'objectif.
En testant ces invites sur des problèmes de complexité croissante, les chercheurs ont voulu évaluer dans quelle mesure les LLM pouvaient généraliser le raisonnement démontré dans les exemples.
Les principaux résultats sont dévoilés
Les résultats de cette étude remettent en question de nombreuses idées reçues sur les messages de la CdT :
Efficacité limitée du CoT : Contrairement aux affirmations précédentes, l'invite CoT n'a montré une amélioration significative des performances que lorsque les exemples fournis étaient extrêmement similaires au problème de la requête. Dès que les problèmes s'écartent du format exact des exemples, les performances chutent brutalement.
Dégradation rapide des performances : Au fur et à mesure que la complexité des problèmes augmentait (mesurée par le nombre de blocs impliqués), la précision de tous les modèles diminuait considérablement, quelle que soit l'invite CoT utilisée. Cela suggère que les LLM ont du mal à étendre le raisonnement démontré dans des exemples simples à des scénarios plus complexes.
Inefficacité des messages d'incitation générale : Il est surprenant de constater que les messages plus généraux de la CoT sont souvent moins performants que les messages standard sans exemples de raisonnement. Cela contredit l'idée selon laquelle la CoT aide les LLM à apprendre des stratégies généralisables de résolution de problèmes.
Compromis de spécificité : L'étude a révélé que les messages guides très spécifiques pouvaient atteindre un niveau de précision élevé, mais seulement pour un sous-ensemble très étroit de problèmes. Cela met en évidence un compromis important entre les gains de performance et l'applicabilité de l'invite.
Absence de véritable apprentissage algorithmique : Les résultats suggèrent fortement que les LLM n'apprennent pas à appliquer des procédures algorithmiques générales à partir des exemples CoT. Au lieu de cela, ils semblent s'appuyer sur l'appariement de modèles, qui s'effondre rapidement lorsqu'ils sont confrontés à des problèmes nouveaux ou plus complexes.
Ces résultats ont des implications importantes pour les praticiens de l'IA et les entreprises qui cherchent à tirer parti de l'incitation CoT dans leurs applications. Ils suggèrent que si le CoT peut améliorer les performances dans certains scénarios étroits, il n'est peut-être pas la panacée pour les tâches de raisonnement complexes que beaucoup espéraient.
Implications pour le développement de l'IA
Les résultats de cette étude ont des implications importantes pour le développement de l'IA, en particulier pour les entreprises qui travaillent sur des applications nécessitant des capacités de raisonnement ou de planification complexes :
Réévaluation de l'efficacité de la formation continue : AI developers should be cautious about relying on CoT for tasks that require true algorithmic thinking or generalization to novel scenarios.
Limites des programmes d'éducation et de formation tout au long de la vie actuels : Alternative approaches may be necessary for applications requiring robust planning or multi-step problem-solving.
Le coût de l'ingénierie rapide : Si les messages guides très spécifiques peuvent donner de bons résultats pour des ensembles de problèmes restreints, l'effort humain nécessaire pour élaborer ces messages guides peut l'emporter sur les avantages, surtout si l'on tient compte de leur faible capacité de généralisation.
Repenser les mesures d'évaluation : Relying solely on static test sets may overestimate a model’s true reasoning capabilities.
Le fossé entre la perception et la réalité : Il existe un écart important entre la perception des capacités de raisonnement des MFR (souvent anthropomorphisées dans le discours populaire) et leurs capacités réelles, comme le démontre cette étude.
Recommendations for AI Practitioners:
Évaluation : Implement diverse testing frameworks to assess true generalization across problem complexities.
CoT Usage: Apply Chain-of-Thought prompting judiciously, recognizing its limitations in generalization.
Hybrid Solutions: Consider combining LLMs with traditional algorithms for complex reasoning tasks.
Transparency: Clearly communicate AI system limitations, especially for reasoning or planning tasks.
R&D Focus: Invest in research to enhance true reasoning capabilities of AI systems.
Ajustement minutieux : Consider domain-specific fine-tuning, but be aware of potential generalization limits.
For AI practitioners and enterprises, these findings highlight the importance of combining LLM strengths with specialized reasoning approaches, investing in domain-specific solutions where necessary, and maintaining transparency about AI system limitations. As we move forward, the AI community must focus on developing new architectures and training methods that can bridge the gap between pattern matching and true algorithmic reasoning.
10 Best Prompting Techniques for LLMs
This week, we also explore ten of the most powerful and common prompting techniques, offering insights into their applications and best practices.

Well-designed prompts can significantly enhance an LLM’s performance, enabling more accurate, relevant, and creative outputs. Whether you’re a seasoned AI developer or just starting with LLMs, these techniques will help you unlock the full potential of AI models.
Make sure to check out the full blog to learn more about each one.
Merci d'avoir pris le temps de lire AI & YOU !
Pour obtenir encore plus de contenu sur l'IA d'entreprise, y compris des infographies, des statistiques, des guides pratiques, des articles et des vidéos, suivez Skim AI sur LinkedIn
Vous êtes un fondateur, un PDG, un investisseur en capital-risque ou un investisseur à la recherche de services de conseil en IA, de développement d'IA fractionnée ou de due diligence ? Obtenez les conseils dont vous avez besoin pour prendre des décisions éclairées sur la stratégie des produits d'IA de votre entreprise et les opportunités d'investissement.
Nous construisons des solutions d'IA personnalisées pour les entreprises financées par le capital-risque et le capital-investissement dans les secteurs suivants : Technologie médicale, agrégation de nouvelles/contenu, production de films et de photos, technologie éducative, technologie juridique, Fintech & Cryptocurrency.


