
Résumé d'un document de recherche sur l'IA : "Chaîne de pensée" ? Incitation



L'incitation à la chaîne de pensée (CoT) a été saluée comme une percée dans le déblocage des capacités de raisonnement des grands modèles de langage (LLM). Cette technique, qui consiste à fournir des exemples de raisonnement étape par étape pour guider les LLM, a suscité une grande attention dans la communauté de l'IA. De nombreux chercheurs et praticiens ont affirmé que l'incitation CoT permet aux LLM de s'attaquer à des tâches de raisonnement complexes de manière plus efficace, ce qui pourrait combler le fossé entre l'informatique et la résolution de problèmes à l'échelle humaine.
Cependant, un article récent intitulé "La chaîne de l'irréflexion ? Une analyse de l'approche de la coopération en matière de planification"remet en question ces affirmations optimistes. Ce document de recherche, qui se concentre sur les tâches de planification, fournit un examen critique de l'efficacité et de la généralisabilité de l'incitation CoT. En tant que praticiens de l'IA, il est essentiel de comprendre ces résultats et leurs implications pour le développement d'applications d'IA nécessitant des capacités de raisonnement sophistiquées.
Comprendre l'étude
Les chercheurs ont choisi un domaine de planification classique appelé Blocksworld comme principal terrain d'essai. Dans Blocksworld, la tâche consiste à réorganiser un ensemble de blocs d'une configuration initiale à une configuration cible à l'aide d'une série d'actions de déplacement. Ce domaine est idéal pour tester les capacités de raisonnement et de planification pour les raisons suivantes :
Il permet de générer des problèmes de complexité variable
Il propose des solutions claires et vérifiables sur le plan algorithmique.
Il est peu probable qu'il soit fortement représenté dans les données de formation du LLM.
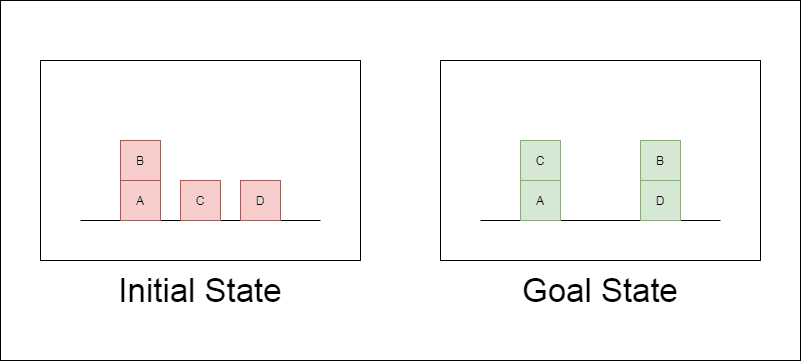
L'étude a examiné trois LLM de pointe : GPT-4, Claude-3-Opus et GPT-4-Turbo. Ces modèles ont été testés à l'aide d'invites de spécificité variable :
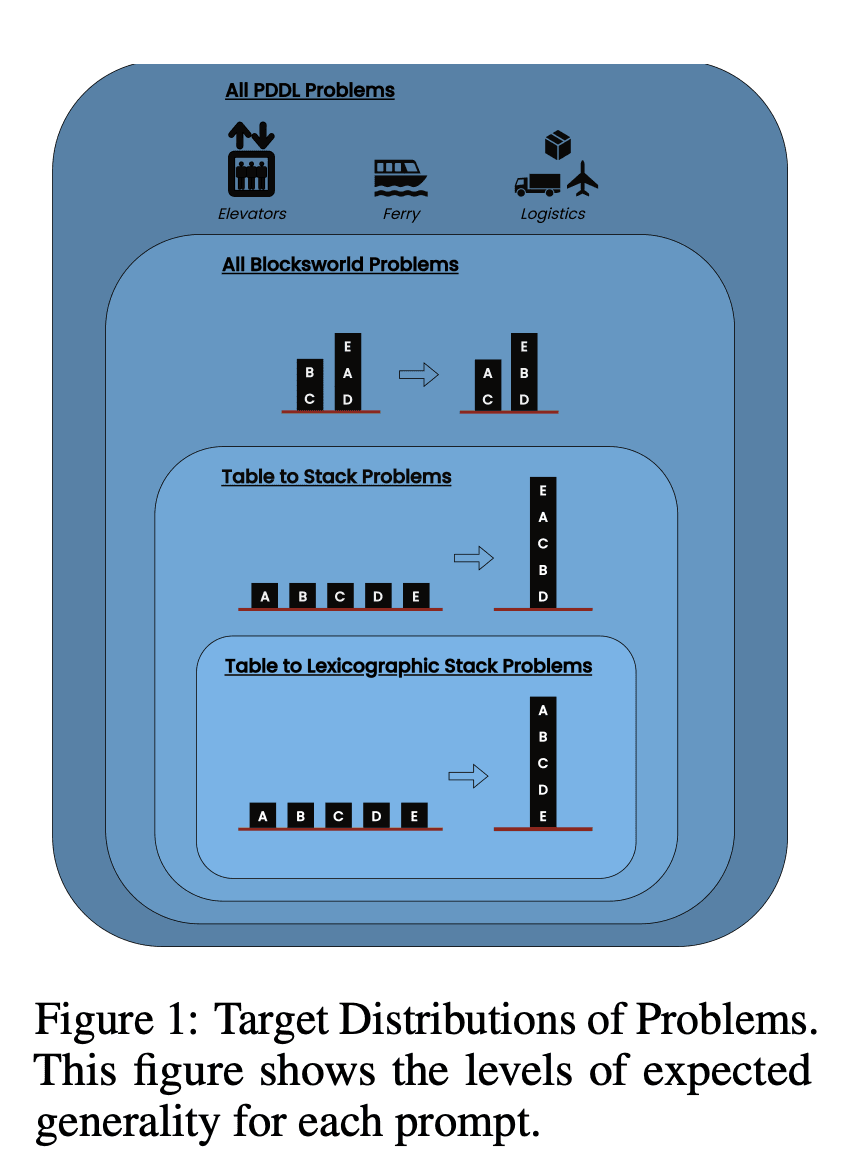
Chaîne de pensée à zéro coup (universelle) : Il suffit d'ajouter "réfléchissons étape par étape" à l'invite.
Preuve de progression (spécifique à la PDDL) : Fournir une explication générale de l'exactitude du plan avec des exemples.
Algorithme universel Blocksworld : Démonstration d'un algorithme général permettant de résoudre n'importe quel problème du monde des blocs.
Promesse d'empilage : Se concentrer sur une sous-classe spécifique des problèmes de Blocksworld (table à pile).
Empilement lexicographique : Réduction supplémentaire à une forme syntaxique particulière de l'état d'objectif.
En testant ces invites sur des problèmes de complexité croissante, les chercheurs ont voulu évaluer dans quelle mesure les LLM pouvaient généraliser le raisonnement démontré dans les exemples.
Les principaux résultats sont dévoilés
Les résultats de cette étude remettent en question de nombreuses idées reçues sur les messages de la CdT :
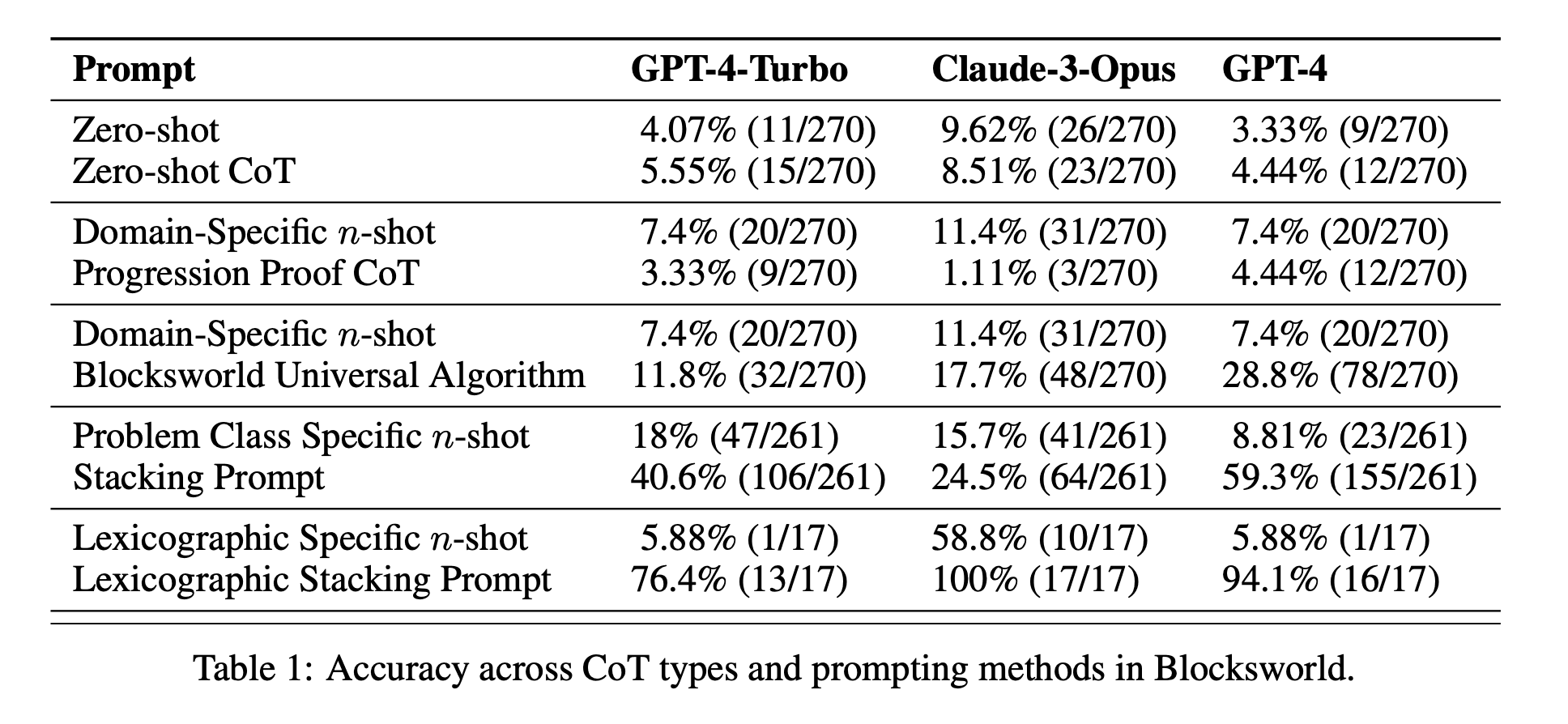
Efficacité limitée du CoT : Contrairement aux affirmations précédentes, l'invite CoT n'a montré une amélioration significative des performances que lorsque les exemples fournis étaient extrêmement similaires au problème de la requête. Dès que les problèmes s'écartent du format exact des exemples, les performances chutent brutalement.
Dégradation rapide des performances : Au fur et à mesure que la complexité des problèmes augmentait (mesurée par le nombre de blocs impliqués), la précision de tous les modèles diminuait considérablement, quelle que soit l'invite CoT utilisée. Cela suggère que les LLM ont du mal à étendre le raisonnement démontré dans des exemples simples à des scénarios plus complexes.
Inefficacité des messages d'incitation générale : Il est surprenant de constater que les messages plus généraux de la CoT sont souvent moins performants que les messages standard sans exemples de raisonnement. Cela contredit l'idée selon laquelle la CoT aide les LLM à apprendre des stratégies généralisables de résolution de problèmes.
Compromis de spécificité : L'étude a révélé que les messages guides très spécifiques pouvaient atteindre un niveau de précision élevé, mais seulement pour un sous-ensemble très étroit de problèmes. Cela met en évidence un compromis important entre les gains de performance et l'applicabilité de l'invite.
Absence de véritable apprentissage algorithmique : Les résultats suggèrent fortement que les LLM n'apprennent pas à appliquer des procédures algorithmiques générales à partir des exemples CoT. Au lieu de cela, ils semblent s'appuyer sur l'appariement de modèles, qui s'effondre rapidement lorsqu'ils sont confrontés à des problèmes nouveaux ou plus complexes.
Ces résultats ont des implications importantes pour les praticiens de l'IA et les entreprises qui cherchent à tirer parti de l'incitation CoT dans leurs applications. Ils suggèrent que si le CoT peut améliorer les performances dans certains scénarios étroits, il n'est peut-être pas la panacée pour les tâches de raisonnement complexes que beaucoup espéraient.
Au-delà de Blocksworld : Prolonger l'enquête
Pour s'assurer que leurs conclusions ne se limitaient pas au domaine Blocksworld, les chercheurs ont étendu leur enquête à plusieurs domaines de problèmes synthétiques couramment utilisés dans les études CoT précédentes :
CoinFlip : Tâche consistant à prédire l'état d'une pièce de monnaie après une série de lancers.
LastLetterConcatenation (concaténation de la dernière lettre) : Une tâche de traitement de texte nécessitant la concaténation des dernières lettres de mots donnés.
Arithmétique à plusieurs étapes : Problèmes impliquant la simplification d'expressions arithmétiques complexes.
Ces domaines ont été choisis parce qu'ils permettent de générer des problèmes de complexité croissante, à l'instar de Blocksworld. Les résultats de ces expériences supplémentaires sont étonnamment cohérents avec ceux de Blocksworld :
Manque de généralisation : Les messages-guides CoT n'ont apporté des améliorations que pour des problèmes très similaires aux exemples fournis. Au fur et à mesure que la complexité des problèmes augmentait, les performances se dégradaient rapidement pour atteindre des niveaux comparables ou inférieurs à ceux des messages-guides standard.
Correspondance de motifs syntaxiques : Dans la tâche "LastLetterConcatenation", l'incitation par le CoT a amélioré certains aspects syntaxiques des réponses (comme l'utilisation des lettres correctes) mais n'a pas réussi à maintenir la précision à mesure que le nombre de mots augmentait.
Échec malgré des étapes intermédiaires parfaites : Dans les tâches arithmétiques, même lorsque les modèles pouvaient parfaitement résoudre toutes les opérations possibles à un chiffre, ils ne parvenaient pas à généraliser les séquences d'opérations plus longues.
Ces résultats renforcent la conclusion selon laquelle les LLM actuels n'apprennent pas vraiment de stratégies de raisonnement généralisables à partir d'exemples de CoT. Au lieu de cela, ils semblent s'appuyer fortement sur une correspondance superficielle des modèles, qui s'effondre lorsqu'ils sont confrontés à des problèmes qui s'écartent des exemples démontrés.
Implications pour le développement de l'IA
Les résultats de cette étude ont des implications importantes pour le développement de l'IA, en particulier pour les entreprises qui travaillent sur des applications nécessitant des capacités de raisonnement ou de planification complexes :
Réévaluation de l'efficacité de la formation continue : L'étude remet en question l'idée selon laquelle l'incitation par le CoT "débloque" les capacités de raisonnement général chez les LLM. Les développeurs d'IA devraient être prudents et ne pas se fier au CoT pour les tâches qui nécessitent une véritable pensée algorithmique ou une généralisation à de nouveaux scénarios.
Limites des programmes d'éducation et de formation tout au long de la vie actuels : Malgré leurs capacités impressionnantes dans de nombreux domaines, les LLM de pointe ont encore du mal à raisonner de manière cohérente et généralisable. Cela suggère que d'autres approches peuvent être nécessaires pour les applications nécessitant une planification robuste ou la résolution de problèmes en plusieurs étapes.
Le coût de l'ingénierie rapide : Si les messages guides très spécifiques peuvent donner de bons résultats pour des ensembles de problèmes restreints, l'effort humain nécessaire pour élaborer ces messages guides peut l'emporter sur les avantages, surtout si l'on tient compte de leur faible capacité de généralisation.
Repenser les mesures d'évaluation : L'étude souligne l'importance de tester les modèles d'IA sur des problèmes de complexité et de structure variables. S'appuyer uniquement sur des ensembles de tests statiques peut conduire à surestimer les véritables capacités de raisonnement d'un modèle.
Le fossé entre la perception et la réalité : Il existe un écart important entre la perception des capacités de raisonnement des MFR (souvent anthropomorphisées dans le discours populaire) et leurs capacités réelles, comme le démontre cette étude.
Recommandations pour les praticiens de l'IA
Compte tenu de ces éléments, voici quelques recommandations clés à l'intention des praticiens de l'IA et des entreprises qui travaillent avec des MLD :
Pratiques d'évaluation rigoureuses :
Mettre en œuvre des cadres de test qui peuvent générer des problèmes de complexité variable.
Ne vous fiez pas uniquement aux ensembles de tests statiques ou aux critères de référence qui peuvent être représentés dans les données d'apprentissage.
Évaluer les performances à travers un spectre de variations de problèmes afin d'évaluer une véritable généralisation.
Des attentes réalistes pour le CdT :
Utiliser judicieusement les messages-guides du CoT, en comprenant leurs limites en matière de généralisation.
Sachez que les améliorations de performances apportées par le CoT peuvent être limitées à des ensembles de problèmes restreints.
Examinez le compromis entre l'effort d'ingénierie rapide et les gains de performance potentiels.
Approches hybrides :
Pour les tâches de raisonnement complexes, il faut envisager de combiner les LLM avec des approches algorithmiques traditionnelles ou des modules de raisonnement spécialisés.
Explorer les méthodes qui peuvent exploiter les forces des LLM (par exemple, la compréhension du langage naturel) tout en compensant leurs faiblesses en matière de raisonnement algorithmique.
Transparence dans les applications de l'IA :
Communiquer clairement les limites des systèmes d'IA, en particulier lorsqu'ils impliquent des tâches de raisonnement ou de planification.
Éviter de surestimer les capacités des LLM, en particulier dans les applications critiques pour la sécurité ou à fort enjeu.
Poursuite de la recherche et du développement :
Investir dans la recherche visant à améliorer les véritables capacités de raisonnement des systèmes d'IA.
Explorer d'autres architectures ou méthodes de formation susceptibles d'aboutir à une généralisation plus robuste dans des tâches complexes.
Mise au point spécifique à un domaine :
Pour les domaines de problèmes étroits et bien définis, il faut envisager d'affiner les modèles sur des données et des modèles de raisonnement spécifiques au domaine.
Il faut savoir qu'une telle mise au point peut améliorer les performances dans le domaine, mais ne peut pas être généralisée au-delà.
En suivant ces recommandations, les praticiens de l'IA peuvent développer des applications d'IA plus robustes et plus fiables, en évitant les pièges potentiels associés à la surestimation des capacités de raisonnement des LLM actuels. Les résultats de cette étude nous rappellent l'importance d'une évaluation critique et réaliste dans le domaine de l'IA, qui évolue rapidement.
Le bilan
Cette étude novatrice sur l'incitation à la chaîne de pensée dans les tâches de planification remet en question notre compréhension des capacités de la gestion du cycle de vie et incite à réévaluer les pratiques actuelles de développement de l'intelligence artificielle. En révélant les limites de la chaîne de pensée dans sa généralisation à des problèmes complexes, elle souligne la nécessité de tests plus rigoureux et d'attentes réalistes dans les applications de l'IA.
Pour les praticiens et les entreprises de l'IA, ces résultats soulignent l'importance de combiner les forces du LLM avec des approches de raisonnement spécialisées, d'investir dans des solutions spécifiques au domaine si nécessaire, et de maintenir la transparence sur les limites des systèmes d'IA. À mesure que nous avançons, la communauté de l'IA doit se concentrer sur le développement de nouvelles architectures et méthodes de formation qui peuvent combler le fossé entre l'appariement de modèles et le véritable raisonnement algorithmique. Cette étude rappelle de manière cruciale que si les LLM ont fait des progrès remarquables, l'obtention de capacités de raisonnement semblables à celles de l'homme reste un défi permanent pour la recherche et le développement en matière d'IA.


